Como as impressões digitais de TCP expõem o seu scraper


Markus_automation
Expert in data parsing and automation
Mover a automação de navegadores do Windows para o Linux frequentemente traz problemas inesperados, mesmo quando a lógica do script permanece exatamente a mesma. Um scraper pode iniciar com sucesso, abrir as páginas necessárias e, ainda assim, parar de coletar dados sem erros óbvios. O motivo geralmente não está oculto no código, nos proxies ou nas configurações do navegador, mas sim muito mais profundamente — no nível da pilha de rede do sistema operacional.
Os sistemas antifraude modernos analisam não apenas as impressões digitais do navegador baseadas em JavaScript, mas também as características de comunicação de rede de baixo nível. Como resultado, um navegador pode parecer estar rodando no Windows no nível da interface web e da API, enquanto revela o Linux por meio do TCP/IP, TLS e pacotes de rede. Essa incompatibilidade entre as camadas de aplicação e transporte torna-se mais um indicador de automação.
Neste artigo, examinaremos como essas inconsistências são criadas, por que elas afetam a estabilização do scraping e como os sistemas antifraude usam assinaturas de rede para identificar tráfego automatizado.
Índice
Mantenha o anonimato, aproveite o recurso multiconta e alcance seus objetivos com o melhor navegador antidetecção do mercado.
Você gostaria de experimentar o Octo Browser com desconto?
Use o código promocional OCTOSCRAPER para obter 30% de desconto em qualquer assinatura. Esta oferta é válida apenas para novos usuários.
Por que até mesmo um navegador antidetecção perfeito ainda não é suficiente
Para entender a real dimensão do problema, vamos primeiro relembrar como funciona uma configuração padrão antibloqueio.
Historicamente, a extração de dados (scraping) evoluiu como uma corrida armamentista nos níveis de HTTP e JavaScript. Quando os servidores começaram a bloquear cabeçalhos padrão, como os do python-requests, os desenvolvedores passaram a usar strings de User-Agent de navegadores reais. Quando os sistemas antifraude começaram a verificar as propriedades do objeto navigator, migramos para navegadores headless modificados através do Chrome DevTools Protocol (CDP) ou soluções prontas de navegador antidetecção.
Nós nos acostumamos a controlar a camada de aplicação (Camada 7). Esta é a camada onde o HTTP opera, os cookies e cabeçalhos são transmitidos e o JavaScript é executado.
O problema é que uma requisição HTTP não é enviada sozinha. Ela é encapsulada dentro de um protocolo de transporte (TCP — Camada 4), que por sua vez é encapsulado dentro de um protocolo de rede (IP — Camada 3). É aqui que reside a principal armadilha de arquitetura:
L7 (camada de aplicação) é totalmente controlada pela sua aplicação — seu script, Puppeteer ou navegador antidetecção.
L3 e L4 (camadas de rede e transporte) são controladas pelo kernel do sistema operacional no qual o código roda fisicamente (ou através do qual o tráfego é roteado). Uma chamada de socket
connect()simplesmente entrega o controle ao stack de rede do Linux ou Windows e, a partir desse ponto, o SO constrói os pacotes de acordo com suas próprias regras internas e codificadas rigidamente (hardcoded).
Os sistemas antifraude modernos sabem disso e usam técnicas de fingerprint passivo para analisar exatamente como uma conexão TCP é estabelecida antes mesmo de a primeira requisição HTTP ser enviada.
Se o seu User-Agent na L7 afirma ser o Chrome no Windows, mas o servidor vê uma estrutura de pacote TCP SYN característica do Linux na L4, o sistema antifraude considera isso uma óbvia anomalia. Do ponto de vista do servidor, uma máquina Windows real não pode fisicamente gerar tal pacote de rede. Portanto, trata-se de um robô rodando em um servidor Linux fingindo ser um usuário comum. O sistema antifraude então age de acordo com suas próprias políticas: o Google Maps, por exemplo, pode retornar uma página simplificada, exigir autenticação e exibir um CAPTCHA.
A anatomia de um pacote TCP SYN: como os servidores identificam seu sistema operacional real
Toda conexão HTTP(S) começa com o estabelecimento de uma conexão TCP — o chamado handshake de três vias (three-way handshake). O primeiríssimo pacote enviado ao recurso de destino é um pacote de rede com a flag SYN ativada. Este pequeno pacote contém tudo o que é necessário para a coleta passiva de fingerprint do sistema operacional. Os sistemas de segurança nem precisam esperar pelos seus cabeçalhos HTTP. Eles inspecionam os campos de serviço dentro do pacote SYN e determinam com notável precisão qual kernel de sistema operacional o criou.
Existem três marcadores principais:
1. Time To Live (TTL)
O TTL é um contador que diminui em uma unidade cada vez que um pacote passa por um roteador em seu caminho para o servidor. Diferentes sistemas operacionais utilizam diferentes valores padrão de partida:
Linux e macOS: o TTL padrão é 64.
Windows: o TTL padrão é 128.
Se o sistema antifraude do Google recebe um pacote com um TTL de 54, ele pode concluir com segurança que a origem é Linux ou macOS. Se recebe um valor de 115, o mais provável é Windows.
2. Tamanho da Janela TCP (TCP Window Size)
Trata-se essencialmente do tamanho do buffer de recepção. Ele indica quantos dados um dispositivo está preparado para aceitar de uma só vez.
Como os dados são transmitidos em fragmentos de aproximadamente 1.460 bytes, os sistemas operacionais geralmente alocam memória em múltiplos desse tamanho. Contudo, cada SO faz isso de forma diferente.
O Linux frequentemente aloca a janela inicial com base em um número fixo de pacotes:
5840 = 4 pacotes × 1460
14600 = 10 pacotes × 1460
29200 = 20 pacotes × 1460
Quando os sistemas antifraude veem 29200, eles reconhecem um padrão típico do kernel do Linux.
O Windows tende a usar potências de dois ou valores máximos:
8192 = 8 KB
65535 = o valor máximo que cabe em um campo Window Size de 16 bits
64240 = uma abordagem híbrida usada por versões modernas do Windows (44 pacotes × 1460)
Os sistemas antifraude comparam esses valores com o seu User-Agent. Se você afirma ser o Chrome no Windows, mas o tamanho da sua janela é 29200, a divergência é óbvia.
3. Ordem das opções do TCP (TCP Options order)
Este é o mecanismo de fingerprint mais poderoso.
Os pacotes SYN incluem parâmetros adicionais, como MSS, Window Scaling, SACK Permitted, Timestamps, entre outros. Os valores em si podem variar, mas a ordem em que aparecem é codificada de forma fixa (hardcoded) no kernel do sistema operacional.
Por exemplo:
Fingerprint típico do Windows:
MSS → NOP → Window Scaling → NOP → NOP → SACK Permitted
Fingerprint típico do Linux:
MSS → SACK Permitted → Timestamps → NOP → Window Scaling
Esses detalhes podem parecer insignificantes, mas qualquer sistema antifraude avançado identificará essas inconsistências, restringirá as sessões e impedirá uma extração de dados estável.
A armadilha do proxy de datacenter: por que seu sistema operacional local não importa mais
Se a coleta de fingerprint de TCP/IP é o problema, uma solução lógica pareceria ser executar o extrator (scraper) em um Windows Server.
Suponha que você inicie seu scraper em uma máquina Windows limpa. O sistema operacional gera pacotes TCP SYN com TTL=128, tamanhos de janela apropriados e a ordem correta de opções. Mesmo assim, CAPTCHAs e interrupções de sessão ainda aparecem. O motivo está na forma como os servidores proxy funcionam.
Operações sérias de scraping quase sempre dependem de proxies. Na maioria das configurações de automação, são usados proxies de datacenter porque são baratos, rápidos e estáveis. O problema é que a grande maioria desses servidores proxy roda distribuições Linux como Ubuntu, Debian ou CentOS.
Quando você usa um proxy, não há uma conexão de rede direta entre seu dispositivo e os servidores do Google. O processo é dividido em duas conexões independentes:
Conexão A (Seu computador → Servidor proxy)
Sua máquina Windows estabelece uma conexão TCP com o proxy.
Conexão B (Servidor proxy → Google)
Após receber sua requisição, o proxy cria uma conexão TCP totalmente nova com o servidor de destino em seu nome.
Como o servidor proxy roda Linux, o stack de rede do Linux gera o pacote SYN enviado ao Google.
Como resultado, o sistema antifraude do Google vê uma conexão TCP que foi claramente criada pelo Linux (TTL 64, tamanhos de janela padrão Linux, ordenação de opções TCP do Linux). Dentro dessa conexão (nível L7), porém, ele vê cabeçalhos HTTP alegando ser o Chrome no Windows.
Os proxies de datacenter expõem o fingerprint da sua camada de transporte local. Mesmo que você use uma fazenda cara de máquinas Windows reais, rotear o tráfego através de proxies de datacenter padrão baseados em Linux faz com que todo o seu tráfego apareça como Linux para o servidor de destino.
Este é um dos motivos pelos quais os proxies residenciais são melhores para scraping.
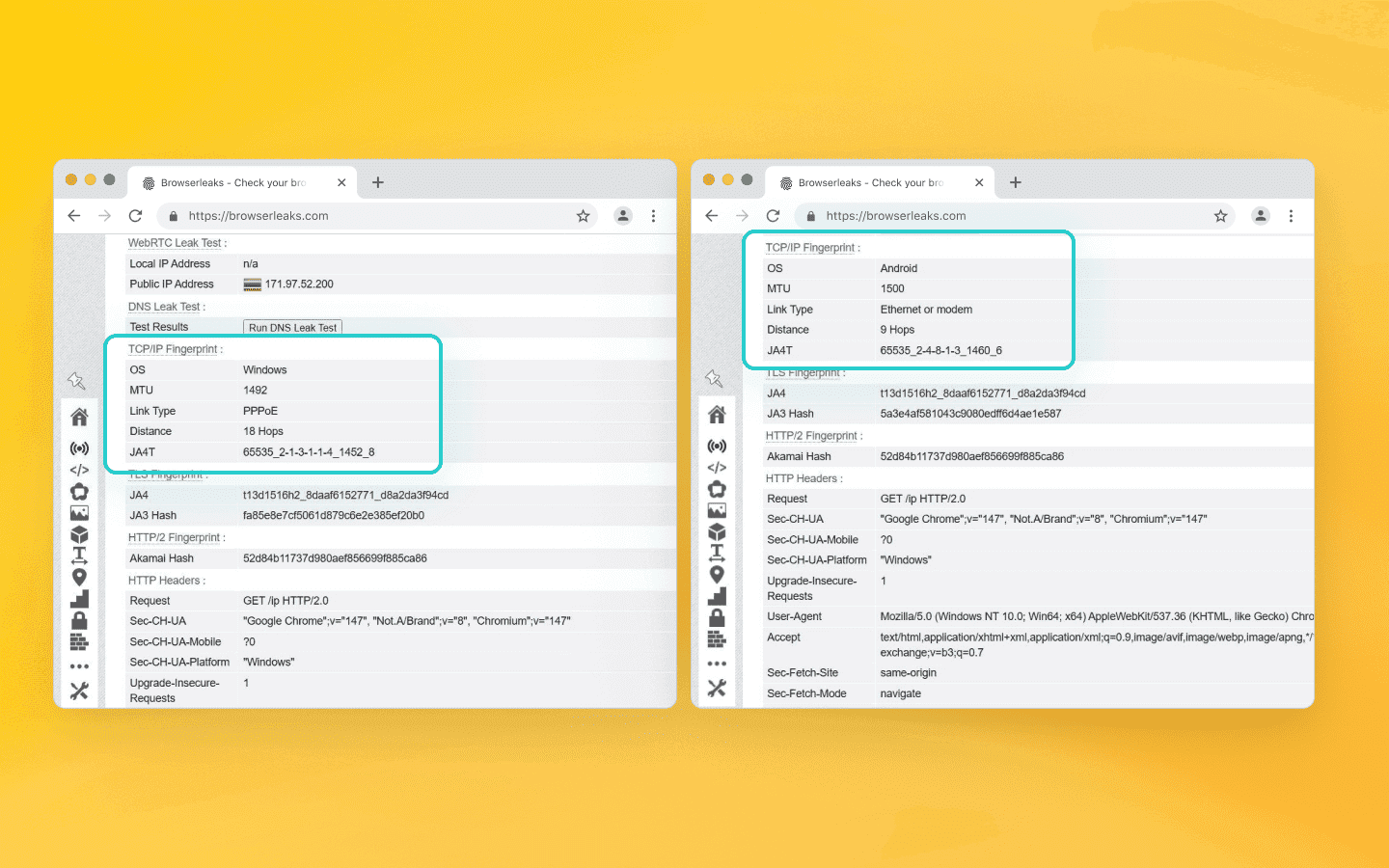
Como verificar seu fingerprint
Sempre teste seus scripts em condições do mundo real. Tente avaliar seu scraper sob a perspectiva do sistema antifraude.
Roteie o tráfego do seu scraper através do BrowserLeaks e role até a seção de Fingerprint de TCP/IP. Se a configuração do seu Puppeteer usa um User-Agent do Windows mas o serviço aponta OS Fingerprint: Linux/Android, você está enfrentando exatamente a divergência discutida neste artigo.
Soluções possíveis: como disfarçar o Linux
Então, como fazer seu scraper passar por uma proteção antifraude robusta?
Opção 1. Alterar o tipo de proxy
Como os proxies de datacenter podem estragar seu fingerprint com seus kernels do Linux, a solução mais confiável é parar de usá-los e mudar para proxies residenciais.
Os proxies residenciais roteiam o tráfego através de dispositivos de usuários reais (PCs domésticos com Windows ou macOS, roteadores domésticos). O ponto de extremidade que estabelece a conexão TCP com os servidores do Google não é mais um servidor Linux em um datacenter, mas um computador real.
Quando o tráfego passa por esses dispositivos, o servidor de destino vê um fingerprint de TCP legítimo de um dispositivo de consumo real que corresponde perfeitamente ao seu fingerprint de L7. O problema de incompatibilidade desaparece por si só.
Se você comprar proxies móveis (que operam através de fazendas de smartphones 4G reais), o ponto de extremidade se torna um dispositivo Android ou iOS. O Android é baseado no kernel do Linux. Se você rodar um scraper de desktop com um User-Agent do Windows 11 através de proxies móveis, o sistema antifraude receberá pacotes do Android e detectará a inconsistência.
O tipo do seu perfil L7 no navegador antidetecção deve corresponder estritamente ao tipo do ponto de extremidade do proxy. Com proxies móveis, ative a emulação do Chrome móvel. Com proxies residenciais, procure por pools que ofereçam IPs de Windows desktop.
Opção 2. Ajustar o kernel do Linux
Se você executa scripts diretamente de um servidor Linux sem proxies (or opera seus próprios proxies sobre os quais possui controle total), precisará disfarçar o stack de rede do sistema operacional.
Nível 1. Ajustes básicos (TTL)
Você pode alterar o TTL padrão para corresponder ao do Windows com um único comando iptables. O kernel reescreverá o valor de TTL do pacote imediatamente antes da transmissão:
iptables -t mangle -A POSTROUTING -j TTL --ttl-set 128
Nível 2. Modificação profunda (Window Size e TCP Options)
Falsificar o tamanho da janela inicial e a ordenação das opções de TCP é muito mais difícil. Configurações básicas do sysctl não são suficientes porque a estrutura do pacote é codificada de forma rígida no código-fonte do kernel do Linux.
Para disfarçar o Linux como Windows no nível de Opções de TCP, você pode usar o mecanismo do NFQueue. Veja como funciona:
Os pacotes de saída são interceptados pelo kernel e encaminhados para o espaço do usuário (user space).
Um utilitário especial (escrito em C ou Python utilizando a biblioteca
Scapy) captura esses pacotes.O programa analisa o cabeçalho TCP, altera o tamanho da janela para 65535 ou 64240, reorganiza as opções (
MSS,NOP,Window Scale, etc.) para a ordem desejada, recalcula o checksum e devolve o pacote ao kernel para transmissão.
Existem utilitários prontos (como o p0f-obfuscator e módulos de projetos de evasão de DPI) que podem realizar essas modificações em tempo real. A configuração é complexa e pode reduzir o desempenho de rede, mas torna seu servidor Linux invisível para técnicas de fingerprint passivo.
Opção 3. Migrar para uma infraestrutura Windows
A abordagem mais simples é não esconder o Linux, mas rodar toda a sua infraestrutura de scraping no Windows Server.
Você pode migrar seu código para uma máquina Windows e enviar o tráfego diretamente. Nesse caso, o stack de rede nativo da Microsoft gera pacotes naturais com:
TTL 128,
tamanhos de janela apropriados,
e a ordem canônica de opções TCP do Windows.
No entanto, essa abordagem tem desvantagens:
Custo. Servidores Windows são sempre mais caros de alugar.
Consumo de recursos. O próprio sistema operacional exige uma quantidade significativa de RAM e recursos de CPU para processos em segundo plano.
Escalabilidade. Implantar, atualizar e escalar uma frota de scrapers no Windows é muito mais difícil do que subir dezenas de contêineres móveis e leves do Docker no Ubuntu.
Conclusão
Simplesmente falsificar User-Agent, Canvas, WebGL e navigator.platform já não é suficiente para garantir o sucesso, especialmente ao lidar com plataformas altamente protegidas como Google, Cloudflare, Akamai ou DataDome. Os sistemas antifraude modernos aprenderam a analisar não apenas quais dados você envia, mas também como você os entrega no nível fundamental de rede.
Se você está enfrentando problemas de extração de dados e não consegue determinar a causa, é hora de olhar para a consistência de todas as camadas do modelo OSI. Se a sua camada de aplicação não corresponde lógica ou matematicamente às camadas de transporte e de rede (L3/L4), o problema pode estar aí.
Se a sua configuração cuidadosamente ajustada — com um navegador antidetecção de alta qualidade e proxies caros — começar a receber erros 403 inexplicáveis, exibir versões simplificadas das páginas ou exigir constantemente CAPTCHAs, pare de alterar fingerprints de JavaScript sem parar. Experimente olhar uma camada mais abaixo.
Mantenha o anonimato, aproveite o recurso multiconta e alcance seus objetivos com o melhor navegador antidetecção do mercado.
Você gostaria de experimentar o Octo Browser com desconto?
Use o código promocional OCTOSCRAPER para obter 30% de desconto em qualquer assinatura. Esta oferta é válida apenas para novos usuários.
Por que até mesmo um navegador antidetecção perfeito ainda não é suficiente
Para entender a real dimensão do problema, vamos primeiro relembrar como funciona uma configuração padrão antibloqueio.
Historicamente, a extração de dados (scraping) evoluiu como uma corrida armamentista nos níveis de HTTP e JavaScript. Quando os servidores começaram a bloquear cabeçalhos padrão, como os do python-requests, os desenvolvedores passaram a usar strings de User-Agent de navegadores reais. Quando os sistemas antifraude começaram a verificar as propriedades do objeto navigator, migramos para navegadores headless modificados através do Chrome DevTools Protocol (CDP) ou soluções prontas de navegador antidetecção.
Nós nos acostumamos a controlar a camada de aplicação (Camada 7). Esta é a camada onde o HTTP opera, os cookies e cabeçalhos são transmitidos e o JavaScript é executado.
O problema é que uma requisição HTTP não é enviada sozinha. Ela é encapsulada dentro de um protocolo de transporte (TCP — Camada 4), que por sua vez é encapsulado dentro de um protocolo de rede (IP — Camada 3). É aqui que reside a principal armadilha de arquitetura:
L7 (camada de aplicação) é totalmente controlada pela sua aplicação — seu script, Puppeteer ou navegador antidetecção.
L3 e L4 (camadas de rede e transporte) são controladas pelo kernel do sistema operacional no qual o código roda fisicamente (ou através do qual o tráfego é roteado). Uma chamada de socket
connect()simplesmente entrega o controle ao stack de rede do Linux ou Windows e, a partir desse ponto, o SO constrói os pacotes de acordo com suas próprias regras internas e codificadas rigidamente (hardcoded).
Os sistemas antifraude modernos sabem disso e usam técnicas de fingerprint passivo para analisar exatamente como uma conexão TCP é estabelecida antes mesmo de a primeira requisição HTTP ser enviada.
Se o seu User-Agent na L7 afirma ser o Chrome no Windows, mas o servidor vê uma estrutura de pacote TCP SYN característica do Linux na L4, o sistema antifraude considera isso uma óbvia anomalia. Do ponto de vista do servidor, uma máquina Windows real não pode fisicamente gerar tal pacote de rede. Portanto, trata-se de um robô rodando em um servidor Linux fingindo ser um usuário comum. O sistema antifraude então age de acordo com suas próprias políticas: o Google Maps, por exemplo, pode retornar uma página simplificada, exigir autenticação e exibir um CAPTCHA.
A anatomia de um pacote TCP SYN: como os servidores identificam seu sistema operacional real
Toda conexão HTTP(S) começa com o estabelecimento de uma conexão TCP — o chamado handshake de três vias (three-way handshake). O primeiríssimo pacote enviado ao recurso de destino é um pacote de rede com a flag SYN ativada. Este pequeno pacote contém tudo o que é necessário para a coleta passiva de fingerprint do sistema operacional. Os sistemas de segurança nem precisam esperar pelos seus cabeçalhos HTTP. Eles inspecionam os campos de serviço dentro do pacote SYN e determinam com notável precisão qual kernel de sistema operacional o criou.
Existem três marcadores principais:
1. Time To Live (TTL)
O TTL é um contador que diminui em uma unidade cada vez que um pacote passa por um roteador em seu caminho para o servidor. Diferentes sistemas operacionais utilizam diferentes valores padrão de partida:
Linux e macOS: o TTL padrão é 64.
Windows: o TTL padrão é 128.
Se o sistema antifraude do Google recebe um pacote com um TTL de 54, ele pode concluir com segurança que a origem é Linux ou macOS. Se recebe um valor de 115, o mais provável é Windows.
2. Tamanho da Janela TCP (TCP Window Size)
Trata-se essencialmente do tamanho do buffer de recepção. Ele indica quantos dados um dispositivo está preparado para aceitar de uma só vez.
Como os dados são transmitidos em fragmentos de aproximadamente 1.460 bytes, os sistemas operacionais geralmente alocam memória em múltiplos desse tamanho. Contudo, cada SO faz isso de forma diferente.
O Linux frequentemente aloca a janela inicial com base em um número fixo de pacotes:
5840 = 4 pacotes × 1460
14600 = 10 pacotes × 1460
29200 = 20 pacotes × 1460
Quando os sistemas antifraude veem 29200, eles reconhecem um padrão típico do kernel do Linux.
O Windows tende a usar potências de dois ou valores máximos:
8192 = 8 KB
65535 = o valor máximo que cabe em um campo Window Size de 16 bits
64240 = uma abordagem híbrida usada por versões modernas do Windows (44 pacotes × 1460)
Os sistemas antifraude comparam esses valores com o seu User-Agent. Se você afirma ser o Chrome no Windows, mas o tamanho da sua janela é 29200, a divergência é óbvia.
3. Ordem das opções do TCP (TCP Options order)
Este é o mecanismo de fingerprint mais poderoso.
Os pacotes SYN incluem parâmetros adicionais, como MSS, Window Scaling, SACK Permitted, Timestamps, entre outros. Os valores em si podem variar, mas a ordem em que aparecem é codificada de forma fixa (hardcoded) no kernel do sistema operacional.
Por exemplo:
Fingerprint típico do Windows:
MSS → NOP → Window Scaling → NOP → NOP → SACK Permitted
Fingerprint típico do Linux:
MSS → SACK Permitted → Timestamps → NOP → Window Scaling
Esses detalhes podem parecer insignificantes, mas qualquer sistema antifraude avançado identificará essas inconsistências, restringirá as sessões e impedirá uma extração de dados estável.
A armadilha do proxy de datacenter: por que seu sistema operacional local não importa mais
Se a coleta de fingerprint de TCP/IP é o problema, uma solução lógica pareceria ser executar o extrator (scraper) em um Windows Server.
Suponha que você inicie seu scraper em uma máquina Windows limpa. O sistema operacional gera pacotes TCP SYN com TTL=128, tamanhos de janela apropriados e a ordem correta de opções. Mesmo assim, CAPTCHAs e interrupções de sessão ainda aparecem. O motivo está na forma como os servidores proxy funcionam.
Operações sérias de scraping quase sempre dependem de proxies. Na maioria das configurações de automação, são usados proxies de datacenter porque são baratos, rápidos e estáveis. O problema é que a grande maioria desses servidores proxy roda distribuições Linux como Ubuntu, Debian ou CentOS.
Quando você usa um proxy, não há uma conexão de rede direta entre seu dispositivo e os servidores do Google. O processo é dividido em duas conexões independentes:
Conexão A (Seu computador → Servidor proxy)
Sua máquina Windows estabelece uma conexão TCP com o proxy.
Conexão B (Servidor proxy → Google)
Após receber sua requisição, o proxy cria uma conexão TCP totalmente nova com o servidor de destino em seu nome.
Como o servidor proxy roda Linux, o stack de rede do Linux gera o pacote SYN enviado ao Google.
Como resultado, o sistema antifraude do Google vê uma conexão TCP que foi claramente criada pelo Linux (TTL 64, tamanhos de janela padrão Linux, ordenação de opções TCP do Linux). Dentro dessa conexão (nível L7), porém, ele vê cabeçalhos HTTP alegando ser o Chrome no Windows.
Os proxies de datacenter expõem o fingerprint da sua camada de transporte local. Mesmo que você use uma fazenda cara de máquinas Windows reais, rotear o tráfego através de proxies de datacenter padrão baseados em Linux faz com que todo o seu tráfego apareça como Linux para o servidor de destino.
Este é um dos motivos pelos quais os proxies residenciais são melhores para scraping.
Como verificar seu fingerprint
Sempre teste seus scripts em condições do mundo real. Tente avaliar seu scraper sob a perspectiva do sistema antifraude.
Roteie o tráfego do seu scraper através do BrowserLeaks e role até a seção de Fingerprint de TCP/IP. Se a configuração do seu Puppeteer usa um User-Agent do Windows mas o serviço aponta OS Fingerprint: Linux/Android, você está enfrentando exatamente a divergência discutida neste artigo.
Soluções possíveis: como disfarçar o Linux
Então, como fazer seu scraper passar por uma proteção antifraude robusta?
Opção 1. Alterar o tipo de proxy
Como os proxies de datacenter podem estragar seu fingerprint com seus kernels do Linux, a solução mais confiável é parar de usá-los e mudar para proxies residenciais.
Os proxies residenciais roteiam o tráfego através de dispositivos de usuários reais (PCs domésticos com Windows ou macOS, roteadores domésticos). O ponto de extremidade que estabelece a conexão TCP com os servidores do Google não é mais um servidor Linux em um datacenter, mas um computador real.
Quando o tráfego passa por esses dispositivos, o servidor de destino vê um fingerprint de TCP legítimo de um dispositivo de consumo real que corresponde perfeitamente ao seu fingerprint de L7. O problema de incompatibilidade desaparece por si só.
Se você comprar proxies móveis (que operam através de fazendas de smartphones 4G reais), o ponto de extremidade se torna um dispositivo Android ou iOS. O Android é baseado no kernel do Linux. Se você rodar um scraper de desktop com um User-Agent do Windows 11 através de proxies móveis, o sistema antifraude receberá pacotes do Android e detectará a inconsistência.
O tipo do seu perfil L7 no navegador antidetecção deve corresponder estritamente ao tipo do ponto de extremidade do proxy. Com proxies móveis, ative a emulação do Chrome móvel. Com proxies residenciais, procure por pools que ofereçam IPs de Windows desktop.
Opção 2. Ajustar o kernel do Linux
Se você executa scripts diretamente de um servidor Linux sem proxies (or opera seus próprios proxies sobre os quais possui controle total), precisará disfarçar o stack de rede do sistema operacional.
Nível 1. Ajustes básicos (TTL)
Você pode alterar o TTL padrão para corresponder ao do Windows com um único comando iptables. O kernel reescreverá o valor de TTL do pacote imediatamente antes da transmissão:
iptables -t mangle -A POSTROUTING -j TTL --ttl-set 128
Nível 2. Modificação profunda (Window Size e TCP Options)
Falsificar o tamanho da janela inicial e a ordenação das opções de TCP é muito mais difícil. Configurações básicas do sysctl não são suficientes porque a estrutura do pacote é codificada de forma rígida no código-fonte do kernel do Linux.
Para disfarçar o Linux como Windows no nível de Opções de TCP, você pode usar o mecanismo do NFQueue. Veja como funciona:
Os pacotes de saída são interceptados pelo kernel e encaminhados para o espaço do usuário (user space).
Um utilitário especial (escrito em C ou Python utilizando a biblioteca
Scapy) captura esses pacotes.O programa analisa o cabeçalho TCP, altera o tamanho da janela para 65535 ou 64240, reorganiza as opções (
MSS,NOP,Window Scale, etc.) para a ordem desejada, recalcula o checksum e devolve o pacote ao kernel para transmissão.
Existem utilitários prontos (como o p0f-obfuscator e módulos de projetos de evasão de DPI) que podem realizar essas modificações em tempo real. A configuração é complexa e pode reduzir o desempenho de rede, mas torna seu servidor Linux invisível para técnicas de fingerprint passivo.
Opção 3. Migrar para uma infraestrutura Windows
A abordagem mais simples é não esconder o Linux, mas rodar toda a sua infraestrutura de scraping no Windows Server.
Você pode migrar seu código para uma máquina Windows e enviar o tráfego diretamente. Nesse caso, o stack de rede nativo da Microsoft gera pacotes naturais com:
TTL 128,
tamanhos de janela apropriados,
e a ordem canônica de opções TCP do Windows.
No entanto, essa abordagem tem desvantagens:
Custo. Servidores Windows são sempre mais caros de alugar.
Consumo de recursos. O próprio sistema operacional exige uma quantidade significativa de RAM e recursos de CPU para processos em segundo plano.
Escalabilidade. Implantar, atualizar e escalar uma frota de scrapers no Windows é muito mais difícil do que subir dezenas de contêineres móveis e leves do Docker no Ubuntu.
Conclusão
Simplesmente falsificar User-Agent, Canvas, WebGL e navigator.platform já não é suficiente para garantir o sucesso, especialmente ao lidar com plataformas altamente protegidas como Google, Cloudflare, Akamai ou DataDome. Os sistemas antifraude modernos aprenderam a analisar não apenas quais dados você envia, mas também como você os entrega no nível fundamental de rede.
Se você está enfrentando problemas de extração de dados e não consegue determinar a causa, é hora de olhar para a consistência de todas as camadas do modelo OSI. Se a sua camada de aplicação não corresponde lógica ou matematicamente às camadas de transporte e de rede (L3/L4), o problema pode estar aí.
Se a sua configuração cuidadosamente ajustada — com um navegador antidetecção de alta qualidade e proxies caros — começar a receber erros 403 inexplicáveis, exibir versões simplificadas das páginas ou exigir constantemente CAPTCHAs, pare de alterar fingerprints de JavaScript sem parar. Experimente olhar uma camada mais abaixo.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.

Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.
Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.
Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.