Como contornar o limite do ChatGPT
25/03/2026


Nikolai Izoitko
Content Manager, Octo Browser
O ChatGPT se tornou uma solução popular para trabalho, aprendizado e criatividade. No entanto, muitos usuários ativos enfrentam regularmente restrições: o serviço informa que o limite de mensagens foi atingido e sugere esperar ou mudar para outro modelo.
Essas limitações são especialmente disruptivas quando você está trabalhando. É por isso que os usuários buscam maneiras de aumentar a duração de seu acesso ao ChatGPT, contornar essas restrições ou pelo menos reduzir seu impacto.
Neste artigo, discutimos quais limites existem no ChatGPT em 2026, por que existem e quais métodos podem ser usados para contorná-los.
Índice
Trabalhe com várias contas de anúncios e teste configurações de anúncios sem rotinas desnecessárias. Evite banimentos e aumente sua receita.
Limitações do ChatGPT
As limitações do ChatGPT dependem da assinatura, do modelo selecionado e da carga atual do sistema. É importante entender que a maioria das limitações não é fixa e pode mudar.
1. Limites de mensagens (limites de taxa)
Os usuários gratuitos podem enviar um número limitado de mensagens para modelos mais poderosos em algumas horas. Após isso, o acesso é temporariamente restrito ou os usuários são incentivados a trocar para um modelo mais leve.
Assinaturas pagas oferecem limites mais altos, mas ainda são limitadas: dezenas ou centenas de mensagens ao longo de várias horas.
2. Limites de modelo
Modelos mais avançados (especialmente os com raciocínio aprimorado) têm limites mais rigorosos do que versões mais leves. Modelos leves geralmente estão disponíveis com restrições mínimas.
3. Limites de ferramentas
Geração de imagens, manuseio de arquivos e outros recursos têm cotas separadas que não estão diretamente ligadas a mensagens de texto.
4. Limites de contexto (tokens)
Cada modelo tem um comprimento máximo de contexto, geralmente de até centenas de milhares de tokens. Quando esse limite é excedido, mensagens antigas são truncadas ou ocorre um erro.
Por que existem limites do ChatGPT
Os limites do ChatGPT não são arbitrários, pois fazem parte da arquitetura do serviço. Eles são necessários para a operação estável do ChatGPT e são impulsionados por vários fatores.
1. Restrições computacionais
Modelos de linguagem modernos e grandes exigem recursos computacionais significativos. Mesmo uma única solicitação pode envolver infraestrutura complexa (GPU/TPU, sistemas distribuídos). Sem limites, isso sobrecarregaria os servidores e aumentaria a latência.
2. Balanceamento de carga
Os limites ajudam a distribuir recursos uniformemente entre os usuários. Sem eles, os usuários mais ativos ou sistemas automatizados poderiam consumir uma parte desproporcional da capacidade computacional.
3. Modelo econômico
O ChatGPT opera em um modelo freemium: o acesso básico é limitado, enquanto assinaturas pagas oferecem limites mais altos e acesso prioritário.
4. Segurança
Limites de taxa ajudam a prevenir ataques automatizados, geração em massa de conteúdo prejudicial e abuso de API.
5. Fatores adicionais
Em alguns casos, fatores indiretos como consumo de energia e eficiência da infraestrutura também são considerados.
Maneiras de contornar os limites do ChatGPT
Não é possível contornar completamente os limites do ChatGPT. Mesmo assinaturas pagas incluem restrições na frequência de solicitações e no acesso a modelos mais poderosos. No entanto, na prática, existem várias abordagens eficazes que ou temporariamente contornam os limites ou reduzem significativamente seu impacto, permitindo que você continue trabalhando sem longas pausas.
Bots e aplicativos do Telegram
A opção mais óbvia para usuários que atingem limites são serviços de terceiros. Estes incluem bots do Telegram, assim como plataformas de IA independentes como Poe, Perplexity, Grok e You.com.
No entanto, é importante ser realista. Plataformas completas como Poe ou Perplexity são estáveis e oferecem acesso a múltiplos modelos, às vezes com limites mais flexíveis ou seus próprios sistemas de cotas. Esta é uma maneira legítima e sustentável de continuar trabalhando, só que não dentro do ChatGPT em si.
Os bots do Telegram, no entanto, são muito menos previsíveis. A maioria opera via API ou proxies, muitas vezes usando pools de solicitações compartilhados, e pode restringir usuários a qualquer momento. Além disso, afirmações sobre acesso a modelos de ponta ou modos de "pensamento" são frequentemente pouco confiáveis, já que o usuário normalmente não pode verificar qual modelo está realmente sendo usado.
Outro aspecto importante a considerar é a segurança dos dados. Com bots, você está quase sempre enviando solicitações através de infraestrutura de terceiros, que pode registrar ou analisar sua entrada. Para tarefas sensíveis, isso representa um risco sério.
Assim, esses serviços podem ajudar quando você precisa urgentemente continuar uma conversa após atingir um limite. Mas como fluxo de trabalho principal, eles são instáveis e difíceis de controlar.
Testes gratuitos
Outra abordagem é usar períodos de teste em serviços que integram grandes modelos de linguagem. Neste caso, você não está contornando limites diretamente, mas ganhando acesso temporário a outro sistema com seus próprios limites.
Por exemplo, Cursor oferece periodicamente acesso de teste aos seus recursos de IA e é amplamente usado por desenvolvedores. Replit fornece assistentes de IA integrados com limites, enquanto Codeium e Tabnine são ferramentas alternativas para trabalhar com código.
Tecnicamente, isso não remove limites do ChatGPT, mas faz com que você troque para outro serviço com teste gratuito ou melhores condições para novos usuários. Eventualmente, as restrições retornam, seja como limites ou como uma exigência de pagamento.
Ainda assim, como estratégia temporária, isso funciona bem, especialmente se as tarefas forem distribuídas entre diferentes soluções: geração de texto, codificação, pesquisa e análise.
Octo Browser
Tenha em mente que os limites do ChatGPT estão ligados à conta, não ao dispositivo. Uma conta significa um conjunto de limites. Múltiplas contas significam limites combinados. Octo Browser, um navegador antidetecção para múltiplas contas, permite que você gerencie essas contas criando perfis de navegador separados com impressões digitais reais para cada uma.
Isso resolve o problema principal: o sistema não vincula contas juntas se elas aparecerem como usuários independentes. Como resultado, você pode trabalhar em sessões paralelas e distribuir a carga.
Como usar Octo Browser para contornar os limites do ChatGPT:
Crie um perfil separado de Octo Browser para cada conta OpenAI.
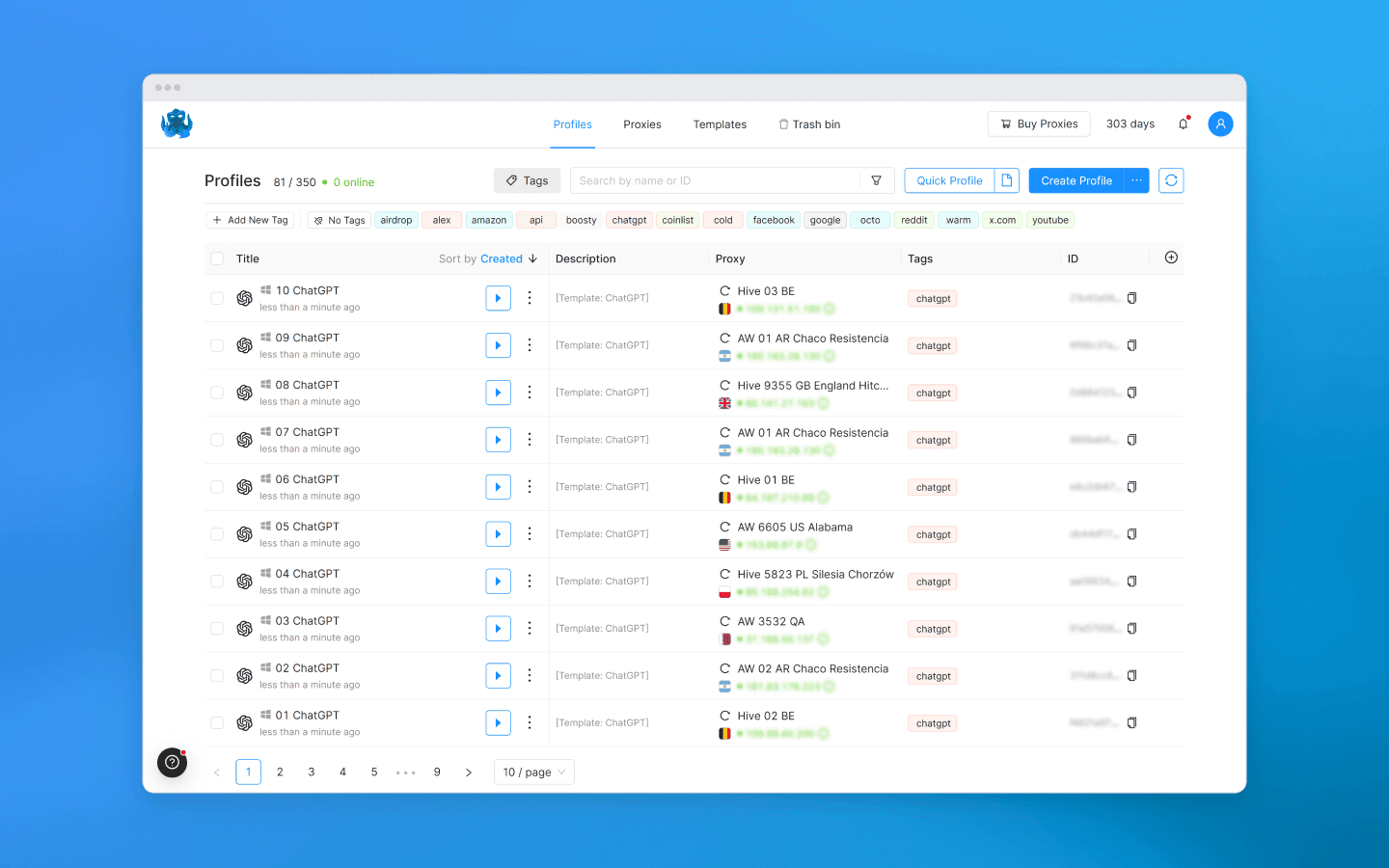
Cada perfil recebe sua própria impressão digital: diferentes Canvas, WebGL, fontes, User-Agent, geolocalização, fuso horário, WebRTC, e assim por diante. Se você não tiver certeza do que escolher, pode deixar as configurações padrão.
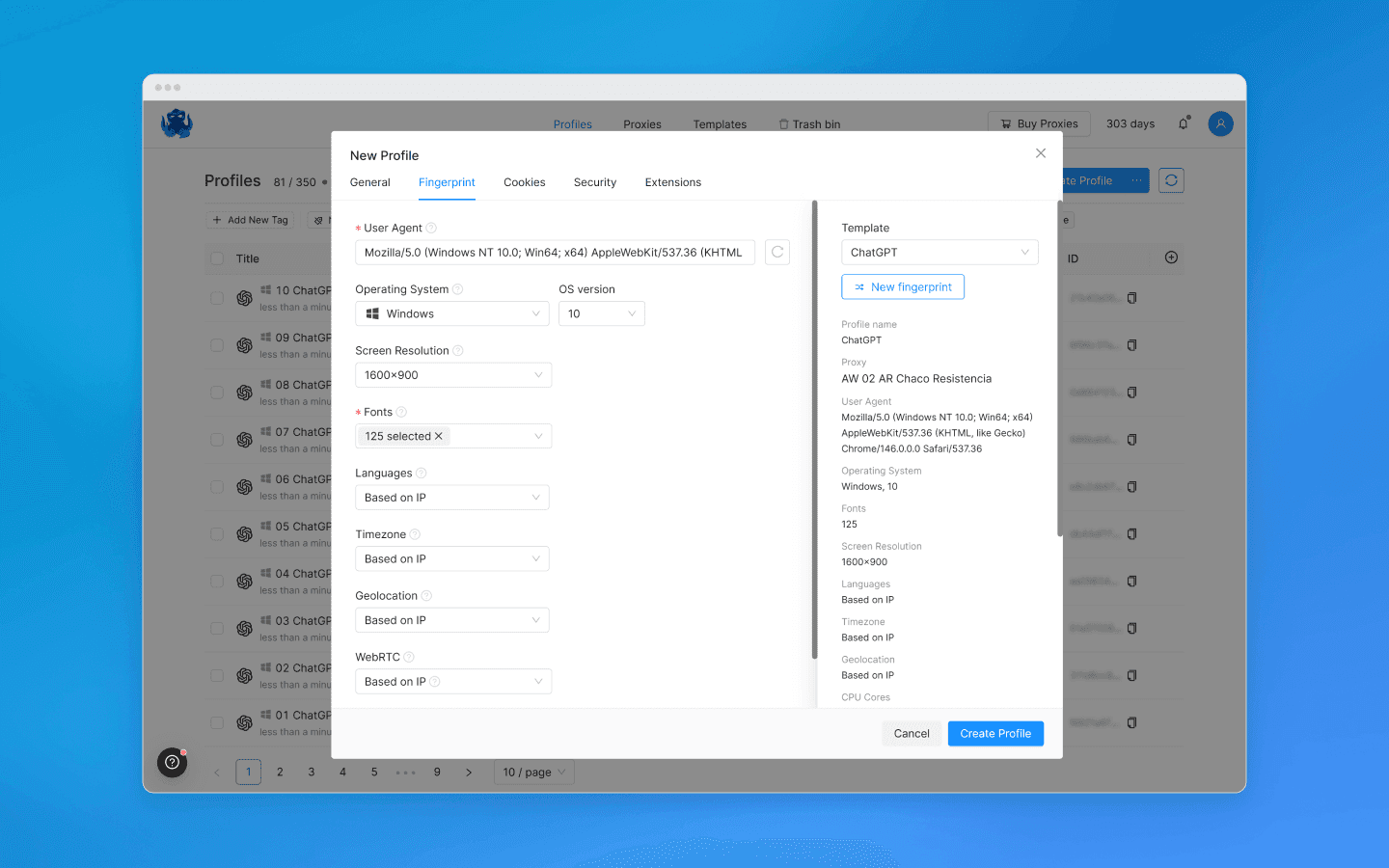
Assigne diferentes proxies a cada perfil.
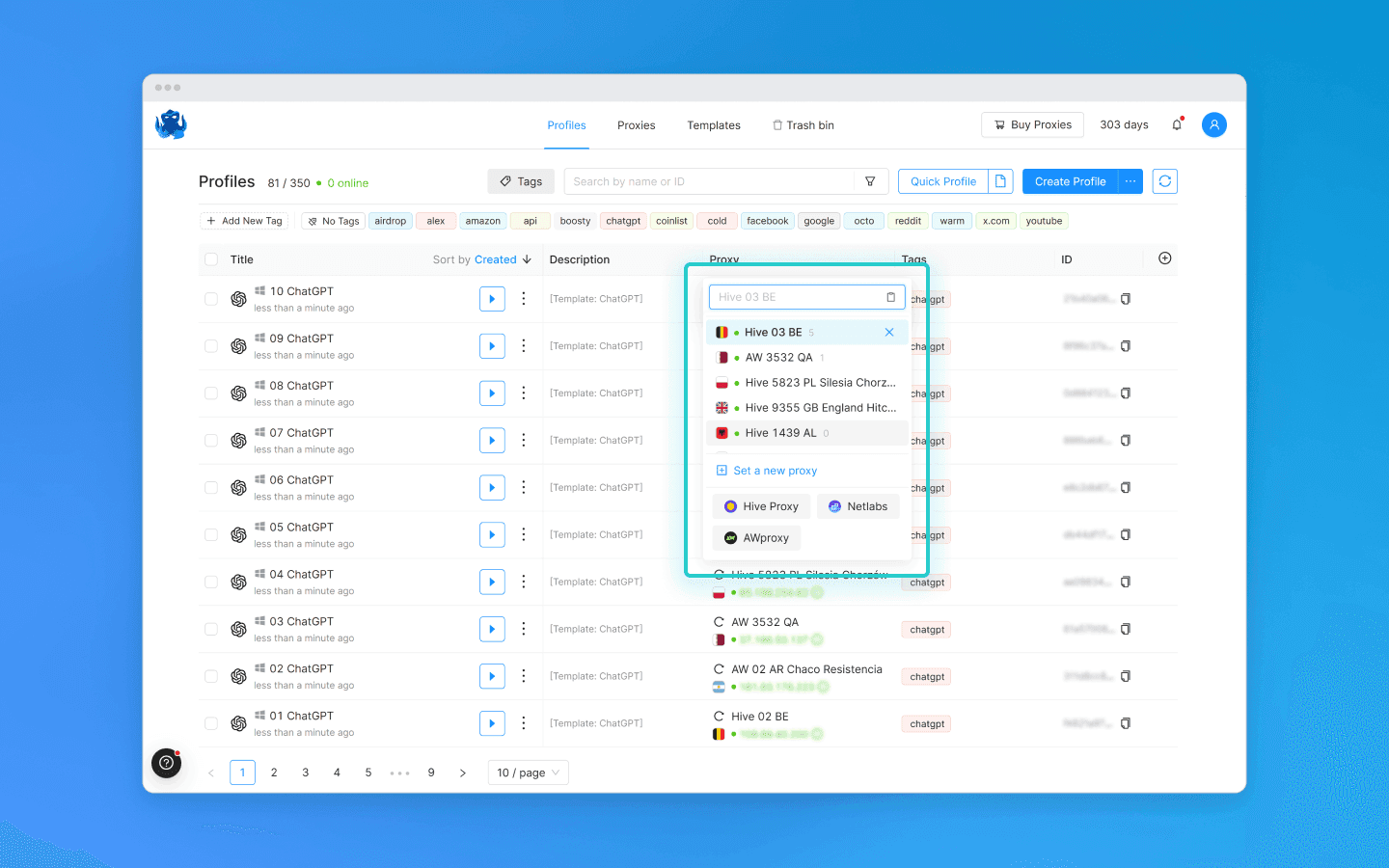
Registre, compre ou alugue múltiplas contas de ChatGPT.
Alterne entre perfis conforme necessário. Os limites do ChatGPT são calculados separadamente para cada conta.
Tenha em mente: comportamento agressivo (registro em massa, ações idênticas, atividade suspeita) ainda traz risco de banimentos.
Dicas para gerenciar sessões e tokens
Mesmo dentro de uma única conta, você pode melhorar significativamente a eficiência trabalhando de forma mais inteligente com chats e solicitações. Esses métodos não contornam diretamente os limites do ChatGPT, mas ajudam a reduzir mensagens desnecessárias.
Reutilize o contexto sempre que possível
Continuar a mesma conversa significa que não há necessidade de reinserir instruções, estilo ou dados. O ChatGPT considera apenas o contexto atual (até centenas de milhares de tokens dependendo do modelo), então conversas mais longas e estruturadas ajudam a reduzir mensagens redundantes.
Não inicie um novo chat sobre o mesmo tópico, a menos que seja estritamente necessário.
Dê nomes claros aos chats para facilitar a navegação.
Divida conversas longas em blocos lógicos apenas quando necessário.
Limpar o contexto para gerenciar o desempenho
Chats muito longos podem reduzir a qualidade das respostas e dificultar o trabalho. Para evitar isso:
Use recursos integrados, como limpar ou ramificar um chat.
Inicie um novo chat para tópicos completamente diferentes, levando apenas as instruções principais.
Monitore o tamanho do contexto para evitar sobrecarregar o modelo.
Importante: limpar o contexto não redefine os limites de mensagens, apenas ajuda a gerenciar a qualidade das respostas.
Dividir uma solicitação grande em várias menores
Prompts muito grandes frequentemente levam a erros e esclarecimentos desnecessários. É melhor dividir tarefas em etapas:
planejamento;
escrevendo partes individuais;
revisão e refinamento.
Essa abordagem ajuda você a obter melhores resultados mais rapidamente, enquanto permanece dentro dos seus limites de mensagens do ChatGPT.
Métodos de otimização de prompts
Um bom prompt é a principal maneira de permanecer dentro do seu limite do ChatGPT. Uma solicitação clara e completa produz uma resposta precisa na primeira tentativa, sem seguimentos desnecessários.
Por exemplo, se você precisa analisar e depurar código Python, tipo de tarefa em que os limites frequentemente são rapidamente esgotados, use a seguinte abordagem:
1. Atribuir um papel ao modelo
Defina claramente o papel do modelo. Isso ajuda a produzir respostas de nível especialista e reduz perguntas de acompanhamento.
Exemplo: “Você é um desenvolvedor Python sênior com 12 anos de experiência. Escreva código limpo e idiomático e explique as mudanças linha por linha.”
Essa abordagem transforma o prompt em um conjunto compacto de instruções para o modelo, reduzindo a necessidade de correções repetidas.
2. Fornecer todo o contexto de uma vez
Não envie metade das informações em uma mensagem e adicione esclarecimentos depois. Se você está trabalhando com código, forneça todos os dados relevantes de uma vez:
o código, os erros identificados, linguagem de programação e sua versão, e a tarefa que o código deve realizar;
dados de exemplo ou o formato de saída desejado.
Exemplo: em vez de “Por que esse código não funciona?” — forneça o código, o erro, a versão do Python e o resultado esperado imediatamente.
3. Dividir a tarefa em etapas
Use uma abordagem iterativa para que o modelo lide com cada etapa separadamente, enquanto você pode monitorar os resultados e corrigir problemas precocemente.
Exemplo:
Analisar o código Python e identificar possíveis erros ou vulnerabilidades.
Corrigir os problemas e sugerir otimizações de funções.
Adicionar casos de teste para validar o código corrigido.
Assim, você mantém controle do processo, reduz o risco de soluções incorretas e economiza mensagens porque cada seguimento está ligado a uma etapa específica.
4. Especificar o formato exato de saída
Se precisar de uma resposta estruturada, defina o formato com antecedência, pois isso reduz o número de revisões e esclarecimentos.
Exemplo: “Divida a resposta em quatro partes: análise do problema, alterações propostas, código corrigido e casos de teste.”
5. Usar exemplos
Mostre ao modelo que tipo de resultado você espera. Isso é especialmente útil ao trabalhar com código, tabelas ou formatação.
Exemplo:
Antes:
response.json()
response.json()
Depois:
response.raise_for_status() data = response.json()
response.raise_for_status() data = response.json()
Por que: raise_for_status() lança uma exceção em erros HTTP, enquanto response.json() retorna dados somente se a solicitação for bem sucedida.
6. Cortar palavras desnecessárias
Quanto mais simples e preciso o prompt, menos tokens e mensagens ele utiliza.
Exemplo:
Ruim: “Por favor, me ajude com o código, ele não funciona, não entendo por quê, me ajude agora.”
Bom: “Analise e corrija o código abaixo. Erro: JSONDecodeError em resposta vazia. Adicione tratamento de erros de rede e HTTP.”
7. Usar separadores para blocos
Se o seu prompt contiver várias partes, separadores como ### ajudam o modelo a distinguir entre instruções, melhorando a precisão e economizando mensagens.
Usando a API para gerenciar limites
A API da OpenAI é a maneira mais flexível de trabalhar com o ChatGPT sem as limitações da interface web. Através da API, você tem acesso direto aos modelos (gpt-5.3, gpt-5.4, modos de pensamento) e gerencia suas próprias cotas e tokens.
1. Obtendo sua chave de API e configuração
Para usar a API:
Vá para platform.openai.com e faça login.
Abra a seção Chaves de API no menu à esquerda.
Clique em Criar nova chave secreta.
Na janela pop-up, digite um nome de projeto, se necessário, defina permissões e clique em Criar nova chave secreta.
Copie a chave e armazene-a com segurança, pois ela fornece acesso completo à sua conta de API.
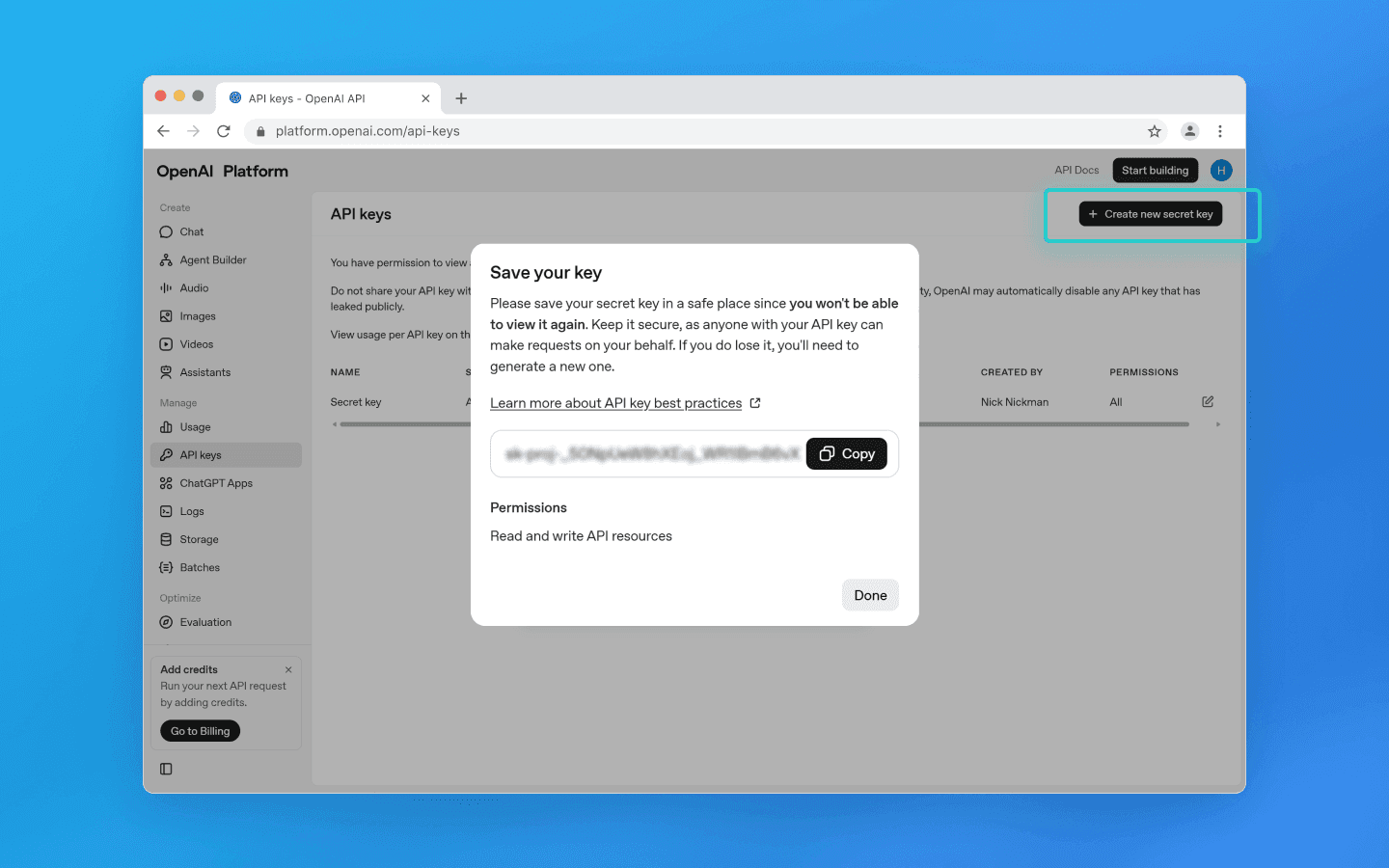
Importante: As chaves de API não estão vinculadas aos limites da web do ChatGPT. Esses limites dependem apenas da sua cota de API.
2. Cotas e limites da API
A OpenAI usa um sistema de cotas vinculado à sua conta e cobrança:
Nível 0 (nova conta): pequenas cotas, por exemplo, 500–1.000 solicitações por minuto e 10k tokens por minuto para modelos leves.
Nível 1+ (após gastar mais de $5): milhares de solicitações por minuto (RPM) e centenas de milhares de tokens por minuto (TPM).
Nível 5 (Enterprise): cotas quase ilimitadas com limites personalizados por acordo.
As cotas aumentam automaticamente com pagamento consistente, desde que não haja violações.
Diferença da interface web: limites da API não são baseados em mensagens de chat, mas em RPM/TPM.
3. Uso eficiente da API
Para economizar cotas e melhorar a estabilidade, use estas práticas recomendadas:
Parâmetros razoáveis:
temperature— 0.2–0.5 para código preciso, 0.7–1.0 para tarefas criativas.max_tokens— limite o comprimento da resposta para evitar uso desnecessário de tokens.top_p— geralmente 0.9–1.0.
Cache de respostas: armazene prompts repetidos localmente (arquivos, Redis) para evitar enviá-los novamente.
Solicitações em lote: envie múltiplos prompts em uma única solicitação para economizar tempo e tokens.
Use modelos leves para rascunhos: use
gpt-4o-miniougpt-5.3-instantpara rascunhos, depois finalize com um modelo de ponta.Modo de streaming:
stream=truepermite que você receba respostas em partes, economizando tokens se sessões forem interrompidas.Prompts de sistema compactos: instruções mais curtas para o papel e o núcleo reduzem o uso de tokens em cada solicitação.
4. Exemplo em Python
Uma maneira simples de chamar a API do ChatGPT:
import requests api_key = "sk-..." url = "https://api.openai.com/v1/chat/completions" headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "gpt-5.3", "messages": [ {"role": "system", "content": "You are a senior Python developer. Write clean, idiomatic code."}, {"role": "user", "content": "Please review this code and fix any errors: ..."} ], "temperature": 0.3, "max_tokens": 800 } response = requests.post(url, headers=headers, json=data) print(response.json())
import requests api_key = "sk-..." url = "https://api.openai.com/v1/chat/completions" headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "gpt-5.3", "messages": [ {"role": "system", "content": "You are a senior Python developer. Write clean, idiomatic code."}, {"role": "user", "content": "Please review this code and fix any errors: ..."} ], "temperature": 0.3, "max_tokens": 800 } response = requests.post(url, headers=headers, json=data) print(response.json())
Estratégias para lidar com limites de taxa
Um limite de taxa no ChatGPT é uma restrição sobre quantas mensagens você pode enviar dentro de um determinado período. Ele opera usando o princípio da janela deslizante.
O que o princípio da janela deslizante significa:
Em vez de redefinir em um momento fixo (por exemplo, exatamente às 3:00), o sistema rastreia uma janela de tempo com base em quando cada mensagem foi enviada.
Exemplo: se seu plano Plus permite 160 mensagens por 3 horas e você envia a primeira mensagem às 10:00, ela só deixará de contar para o limite às 13:00. O mesmo se aplica a cada mensagem— a janela se move continuamente com base no horário de envio.
Isso significa que o limite se restaura gradualmente, não de uma vez.
Para gerenciar seu limite de taxa eficientemente, siga estas diretrizes:
1. Use modelos leves para tarefas simples
Versões mini ou instantâneas têm limites separados e são adequadas para verificações rápidas, rascunhos ou esclarecimentos simples.
2. Fique de olho nas notificações do ChatGPT
A interface web exibe alertas à medida que você se aproxima de seu limite.
3. Divida grandes tarefas em blocos
Em vez de um prompt longo, divida a tarefa em múltiplas mensagens com instruções claras. Isso ajuda a economizar sua cota, melhora o controle e aumenta a qualidade da resposta.
Conclusão
Os limites do ChatGPT em 2026 não são um problema temporário, mas uma parte permanente do trabalho com o serviço. Para os usuários, eles frequentemente se tornam um gargalo: o trabalho para, prazos se atrasam, e você tem que esperar os limites se resetarem.
Neste artigo, cobrimos as restrições atuais, os motivos por trás delas (técnicos, econômicos e relacionados à segurança), e maneiras práticas de reduzir seu impacto. A abordagem mais eficaz é combinar métodos: múltiplas contas do ChatGPT criadas com um navegador antidetecção, otimização adequada de prompt e gerenciamento de contexto, trabalhando por meio da API com cotas baseadas em níveis, e alternância razoável de pausas e modelos leves.
É impossível remover completamente os limites do ChatGPT sem uma assinatura Pro cara, mas aplicar essas estratégias de forma consistente e correta permite que você trabalhe por mais tempo e com mais eficiência.
FAQ
Quanto tempo dura o limite de taxa no ChatGPT?
O ChatGPT usa o princípio da janela deslizante. Isso significa que o limite não se redefine em um momento fixo, mas é calculado individualmente para cada mensagem. Após 3-5 horas, uma mensagem específica não conta mais para a janela atual.
Modelos diferentes do ChatGPT têm limites diferentes?
Sim. Os limites dependem da sua assinatura. No plano Gratuito, o acesso a modelos avançados é limitado (geralmente em torno de 10 mensagens durante várias horas), após o que o sistema pode alternar para um modelo leve (mini). Planos pagos (como Plus) oferecem cotas significativamente mais altas dentro da mesma janela de tempo.
Os limites da API podem ser alterados?
Sim, mas não manualmente. Os limites da API da OpenAI são gerenciados através de cotas (limites de taxa e limites de gastos) e aumentam automaticamente com o uso e pagamentos. Cobrança estável e uso mais alto levam a limites mais altos disponíveis (RPM/TPM). Em alguns casos, limites para grandes clientes podem ser aumentados através do suporte.
Os limites do ChatGPT se resetam se eu usar navegadores diferentes?
Não. Os limites estão vinculados à sua conta, não ao navegador. Usar navegadores ou abas diferentes não altera o contador de mensagens.
Os limites do ChatGPT estão vinculados à conta ou ao dispositivo?
Os limites do ChatGPT estão vinculados à conta. Dispositivo, navegador e endereço IP não afetam o número de mensagens disponíveis. Uma conta equivale a um limite compartilhado.
Qual é a diferença entre limites de tokens e limites de taxa?
Estes são sistemas diferentes. Os limites de tokens definem quanto texto (entrada e saída) pode ser processado em uma única solicitação ou dentro de um contexto de conversa. Os limites de taxa definem com que frequência você pode enviar solicitações ao longo de um período de tempo. Você pode atingir um limite sem alcançar o outro.
Trabalhe com várias contas de anúncios e teste configurações de anúncios sem rotinas desnecessárias. Evite banimentos e aumente sua receita.
Limitações do ChatGPT
As limitações do ChatGPT dependem da assinatura, do modelo selecionado e da carga atual do sistema. É importante entender que a maioria das limitações não é fixa e pode mudar.
1. Limites de mensagens (limites de taxa)
Os usuários gratuitos podem enviar um número limitado de mensagens para modelos mais poderosos em algumas horas. Após isso, o acesso é temporariamente restrito ou os usuários são incentivados a trocar para um modelo mais leve.
Assinaturas pagas oferecem limites mais altos, mas ainda são limitadas: dezenas ou centenas de mensagens ao longo de várias horas.
2. Limites de modelo
Modelos mais avançados (especialmente os com raciocínio aprimorado) têm limites mais rigorosos do que versões mais leves. Modelos leves geralmente estão disponíveis com restrições mínimas.
3. Limites de ferramentas
Geração de imagens, manuseio de arquivos e outros recursos têm cotas separadas que não estão diretamente ligadas a mensagens de texto.
4. Limites de contexto (tokens)
Cada modelo tem um comprimento máximo de contexto, geralmente de até centenas de milhares de tokens. Quando esse limite é excedido, mensagens antigas são truncadas ou ocorre um erro.
Por que existem limites do ChatGPT
Os limites do ChatGPT não são arbitrários, pois fazem parte da arquitetura do serviço. Eles são necessários para a operação estável do ChatGPT e são impulsionados por vários fatores.
1. Restrições computacionais
Modelos de linguagem modernos e grandes exigem recursos computacionais significativos. Mesmo uma única solicitação pode envolver infraestrutura complexa (GPU/TPU, sistemas distribuídos). Sem limites, isso sobrecarregaria os servidores e aumentaria a latência.
2. Balanceamento de carga
Os limites ajudam a distribuir recursos uniformemente entre os usuários. Sem eles, os usuários mais ativos ou sistemas automatizados poderiam consumir uma parte desproporcional da capacidade computacional.
3. Modelo econômico
O ChatGPT opera em um modelo freemium: o acesso básico é limitado, enquanto assinaturas pagas oferecem limites mais altos e acesso prioritário.
4. Segurança
Limites de taxa ajudam a prevenir ataques automatizados, geração em massa de conteúdo prejudicial e abuso de API.
5. Fatores adicionais
Em alguns casos, fatores indiretos como consumo de energia e eficiência da infraestrutura também são considerados.
Maneiras de contornar os limites do ChatGPT
Não é possível contornar completamente os limites do ChatGPT. Mesmo assinaturas pagas incluem restrições na frequência de solicitações e no acesso a modelos mais poderosos. No entanto, na prática, existem várias abordagens eficazes que ou temporariamente contornam os limites ou reduzem significativamente seu impacto, permitindo que você continue trabalhando sem longas pausas.
Bots e aplicativos do Telegram
A opção mais óbvia para usuários que atingem limites são serviços de terceiros. Estes incluem bots do Telegram, assim como plataformas de IA independentes como Poe, Perplexity, Grok e You.com.
No entanto, é importante ser realista. Plataformas completas como Poe ou Perplexity são estáveis e oferecem acesso a múltiplos modelos, às vezes com limites mais flexíveis ou seus próprios sistemas de cotas. Esta é uma maneira legítima e sustentável de continuar trabalhando, só que não dentro do ChatGPT em si.
Os bots do Telegram, no entanto, são muito menos previsíveis. A maioria opera via API ou proxies, muitas vezes usando pools de solicitações compartilhados, e pode restringir usuários a qualquer momento. Além disso, afirmações sobre acesso a modelos de ponta ou modos de "pensamento" são frequentemente pouco confiáveis, já que o usuário normalmente não pode verificar qual modelo está realmente sendo usado.
Outro aspecto importante a considerar é a segurança dos dados. Com bots, você está quase sempre enviando solicitações através de infraestrutura de terceiros, que pode registrar ou analisar sua entrada. Para tarefas sensíveis, isso representa um risco sério.
Assim, esses serviços podem ajudar quando você precisa urgentemente continuar uma conversa após atingir um limite. Mas como fluxo de trabalho principal, eles são instáveis e difíceis de controlar.
Testes gratuitos
Outra abordagem é usar períodos de teste em serviços que integram grandes modelos de linguagem. Neste caso, você não está contornando limites diretamente, mas ganhando acesso temporário a outro sistema com seus próprios limites.
Por exemplo, Cursor oferece periodicamente acesso de teste aos seus recursos de IA e é amplamente usado por desenvolvedores. Replit fornece assistentes de IA integrados com limites, enquanto Codeium e Tabnine são ferramentas alternativas para trabalhar com código.
Tecnicamente, isso não remove limites do ChatGPT, mas faz com que você troque para outro serviço com teste gratuito ou melhores condições para novos usuários. Eventualmente, as restrições retornam, seja como limites ou como uma exigência de pagamento.
Ainda assim, como estratégia temporária, isso funciona bem, especialmente se as tarefas forem distribuídas entre diferentes soluções: geração de texto, codificação, pesquisa e análise.
Octo Browser
Tenha em mente que os limites do ChatGPT estão ligados à conta, não ao dispositivo. Uma conta significa um conjunto de limites. Múltiplas contas significam limites combinados. Octo Browser, um navegador antidetecção para múltiplas contas, permite que você gerencie essas contas criando perfis de navegador separados com impressões digitais reais para cada uma.
Isso resolve o problema principal: o sistema não vincula contas juntas se elas aparecerem como usuários independentes. Como resultado, você pode trabalhar em sessões paralelas e distribuir a carga.
Como usar Octo Browser para contornar os limites do ChatGPT:
Crie um perfil separado de Octo Browser para cada conta OpenAI.
Cada perfil recebe sua própria impressão digital: diferentes Canvas, WebGL, fontes, User-Agent, geolocalização, fuso horário, WebRTC, e assim por diante. Se você não tiver certeza do que escolher, pode deixar as configurações padrão.
Assigne diferentes proxies a cada perfil.
Registre, compre ou alugue múltiplas contas de ChatGPT.
Alterne entre perfis conforme necessário. Os limites do ChatGPT são calculados separadamente para cada conta.
Tenha em mente: comportamento agressivo (registro em massa, ações idênticas, atividade suspeita) ainda traz risco de banimentos.
Dicas para gerenciar sessões e tokens
Mesmo dentro de uma única conta, você pode melhorar significativamente a eficiência trabalhando de forma mais inteligente com chats e solicitações. Esses métodos não contornam diretamente os limites do ChatGPT, mas ajudam a reduzir mensagens desnecessárias.
Reutilize o contexto sempre que possível
Continuar a mesma conversa significa que não há necessidade de reinserir instruções, estilo ou dados. O ChatGPT considera apenas o contexto atual (até centenas de milhares de tokens dependendo do modelo), então conversas mais longas e estruturadas ajudam a reduzir mensagens redundantes.
Não inicie um novo chat sobre o mesmo tópico, a menos que seja estritamente necessário.
Dê nomes claros aos chats para facilitar a navegação.
Divida conversas longas em blocos lógicos apenas quando necessário.
Limpar o contexto para gerenciar o desempenho
Chats muito longos podem reduzir a qualidade das respostas e dificultar o trabalho. Para evitar isso:
Use recursos integrados, como limpar ou ramificar um chat.
Inicie um novo chat para tópicos completamente diferentes, levando apenas as instruções principais.
Monitore o tamanho do contexto para evitar sobrecarregar o modelo.
Importante: limpar o contexto não redefine os limites de mensagens, apenas ajuda a gerenciar a qualidade das respostas.
Dividir uma solicitação grande em várias menores
Prompts muito grandes frequentemente levam a erros e esclarecimentos desnecessários. É melhor dividir tarefas em etapas:
planejamento;
escrevendo partes individuais;
revisão e refinamento.
Essa abordagem ajuda você a obter melhores resultados mais rapidamente, enquanto permanece dentro dos seus limites de mensagens do ChatGPT.
Métodos de otimização de prompts
Um bom prompt é a principal maneira de permanecer dentro do seu limite do ChatGPT. Uma solicitação clara e completa produz uma resposta precisa na primeira tentativa, sem seguimentos desnecessários.
Por exemplo, se você precisa analisar e depurar código Python, tipo de tarefa em que os limites frequentemente são rapidamente esgotados, use a seguinte abordagem:
1. Atribuir um papel ao modelo
Defina claramente o papel do modelo. Isso ajuda a produzir respostas de nível especialista e reduz perguntas de acompanhamento.
Exemplo: “Você é um desenvolvedor Python sênior com 12 anos de experiência. Escreva código limpo e idiomático e explique as mudanças linha por linha.”
Essa abordagem transforma o prompt em um conjunto compacto de instruções para o modelo, reduzindo a necessidade de correções repetidas.
2. Fornecer todo o contexto de uma vez
Não envie metade das informações em uma mensagem e adicione esclarecimentos depois. Se você está trabalhando com código, forneça todos os dados relevantes de uma vez:
o código, os erros identificados, linguagem de programação e sua versão, e a tarefa que o código deve realizar;
dados de exemplo ou o formato de saída desejado.
Exemplo: em vez de “Por que esse código não funciona?” — forneça o código, o erro, a versão do Python e o resultado esperado imediatamente.
3. Dividir a tarefa em etapas
Use uma abordagem iterativa para que o modelo lide com cada etapa separadamente, enquanto você pode monitorar os resultados e corrigir problemas precocemente.
Exemplo:
Analisar o código Python e identificar possíveis erros ou vulnerabilidades.
Corrigir os problemas e sugerir otimizações de funções.
Adicionar casos de teste para validar o código corrigido.
Assim, você mantém controle do processo, reduz o risco de soluções incorretas e economiza mensagens porque cada seguimento está ligado a uma etapa específica.
4. Especificar o formato exato de saída
Se precisar de uma resposta estruturada, defina o formato com antecedência, pois isso reduz o número de revisões e esclarecimentos.
Exemplo: “Divida a resposta em quatro partes: análise do problema, alterações propostas, código corrigido e casos de teste.”
5. Usar exemplos
Mostre ao modelo que tipo de resultado você espera. Isso é especialmente útil ao trabalhar com código, tabelas ou formatação.
Exemplo:
Antes:
response.json()
Depois:
response.raise_for_status() data = response.json()
Por que: raise_for_status() lança uma exceção em erros HTTP, enquanto response.json() retorna dados somente se a solicitação for bem sucedida.
6. Cortar palavras desnecessárias
Quanto mais simples e preciso o prompt, menos tokens e mensagens ele utiliza.
Exemplo:
Ruim: “Por favor, me ajude com o código, ele não funciona, não entendo por quê, me ajude agora.”
Bom: “Analise e corrija o código abaixo. Erro: JSONDecodeError em resposta vazia. Adicione tratamento de erros de rede e HTTP.”
7. Usar separadores para blocos
Se o seu prompt contiver várias partes, separadores como ### ajudam o modelo a distinguir entre instruções, melhorando a precisão e economizando mensagens.
Usando a API para gerenciar limites
A API da OpenAI é a maneira mais flexível de trabalhar com o ChatGPT sem as limitações da interface web. Através da API, você tem acesso direto aos modelos (gpt-5.3, gpt-5.4, modos de pensamento) e gerencia suas próprias cotas e tokens.
1. Obtendo sua chave de API e configuração
Para usar a API:
Vá para platform.openai.com e faça login.
Abra a seção Chaves de API no menu à esquerda.
Clique em Criar nova chave secreta.
Na janela pop-up, digite um nome de projeto, se necessário, defina permissões e clique em Criar nova chave secreta.
Copie a chave e armazene-a com segurança, pois ela fornece acesso completo à sua conta de API.
Importante: As chaves de API não estão vinculadas aos limites da web do ChatGPT. Esses limites dependem apenas da sua cota de API.
2. Cotas e limites da API
A OpenAI usa um sistema de cotas vinculado à sua conta e cobrança:
Nível 0 (nova conta): pequenas cotas, por exemplo, 500–1.000 solicitações por minuto e 10k tokens por minuto para modelos leves.
Nível 1+ (após gastar mais de $5): milhares de solicitações por minuto (RPM) e centenas de milhares de tokens por minuto (TPM).
Nível 5 (Enterprise): cotas quase ilimitadas com limites personalizados por acordo.
As cotas aumentam automaticamente com pagamento consistente, desde que não haja violações.
Diferença da interface web: limites da API não são baseados em mensagens de chat, mas em RPM/TPM.
3. Uso eficiente da API
Para economizar cotas e melhorar a estabilidade, use estas práticas recomendadas:
Parâmetros razoáveis:
temperature— 0.2–0.5 para código preciso, 0.7–1.0 para tarefas criativas.max_tokens— limite o comprimento da resposta para evitar uso desnecessário de tokens.top_p— geralmente 0.9–1.0.
Cache de respostas: armazene prompts repetidos localmente (arquivos, Redis) para evitar enviá-los novamente.
Solicitações em lote: envie múltiplos prompts em uma única solicitação para economizar tempo e tokens.
Use modelos leves para rascunhos: use
gpt-4o-miniougpt-5.3-instantpara rascunhos, depois finalize com um modelo de ponta.Modo de streaming:
stream=truepermite que você receba respostas em partes, economizando tokens se sessões forem interrompidas.Prompts de sistema compactos: instruções mais curtas para o papel e o núcleo reduzem o uso de tokens em cada solicitação.
4. Exemplo em Python
Uma maneira simples de chamar a API do ChatGPT:
import requests api_key = "sk-..." url = "https://api.openai.com/v1/chat/completions" headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "gpt-5.3", "messages": [ {"role": "system", "content": "You are a senior Python developer. Write clean, idiomatic code."}, {"role": "user", "content": "Please review this code and fix any errors: ..."} ], "temperature": 0.3, "max_tokens": 800 } response = requests.post(url, headers=headers, json=data) print(response.json())
Estratégias para lidar com limites de taxa
Um limite de taxa no ChatGPT é uma restrição sobre quantas mensagens você pode enviar dentro de um determinado período. Ele opera usando o princípio da janela deslizante.
O que o princípio da janela deslizante significa:
Em vez de redefinir em um momento fixo (por exemplo, exatamente às 3:00), o sistema rastreia uma janela de tempo com base em quando cada mensagem foi enviada.
Exemplo: se seu plano Plus permite 160 mensagens por 3 horas e você envia a primeira mensagem às 10:00, ela só deixará de contar para o limite às 13:00. O mesmo se aplica a cada mensagem— a janela se move continuamente com base no horário de envio.
Isso significa que o limite se restaura gradualmente, não de uma vez.
Para gerenciar seu limite de taxa eficientemente, siga estas diretrizes:
1. Use modelos leves para tarefas simples
Versões mini ou instantâneas têm limites separados e são adequadas para verificações rápidas, rascunhos ou esclarecimentos simples.
2. Fique de olho nas notificações do ChatGPT
A interface web exibe alertas à medida que você se aproxima de seu limite.
3. Divida grandes tarefas em blocos
Em vez de um prompt longo, divida a tarefa em múltiplas mensagens com instruções claras. Isso ajuda a economizar sua cota, melhora o controle e aumenta a qualidade da resposta.
Conclusão
Os limites do ChatGPT em 2026 não são um problema temporário, mas uma parte permanente do trabalho com o serviço. Para os usuários, eles frequentemente se tornam um gargalo: o trabalho para, prazos se atrasam, e você tem que esperar os limites se resetarem.
Neste artigo, cobrimos as restrições atuais, os motivos por trás delas (técnicos, econômicos e relacionados à segurança), e maneiras práticas de reduzir seu impacto. A abordagem mais eficaz é combinar métodos: múltiplas contas do ChatGPT criadas com um navegador antidetecção, otimização adequada de prompt e gerenciamento de contexto, trabalhando por meio da API com cotas baseadas em níveis, e alternância razoável de pausas e modelos leves.
É impossível remover completamente os limites do ChatGPT sem uma assinatura Pro cara, mas aplicar essas estratégias de forma consistente e correta permite que você trabalhe por mais tempo e com mais eficiência.
FAQ
Quanto tempo dura o limite de taxa no ChatGPT?
O ChatGPT usa o princípio da janela deslizante. Isso significa que o limite não se redefine em um momento fixo, mas é calculado individualmente para cada mensagem. Após 3-5 horas, uma mensagem específica não conta mais para a janela atual.
Modelos diferentes do ChatGPT têm limites diferentes?
Sim. Os limites dependem da sua assinatura. No plano Gratuito, o acesso a modelos avançados é limitado (geralmente em torno de 10 mensagens durante várias horas), após o que o sistema pode alternar para um modelo leve (mini). Planos pagos (como Plus) oferecem cotas significativamente mais altas dentro da mesma janela de tempo.
Os limites da API podem ser alterados?
Sim, mas não manualmente. Os limites da API da OpenAI são gerenciados através de cotas (limites de taxa e limites de gastos) e aumentam automaticamente com o uso e pagamentos. Cobrança estável e uso mais alto levam a limites mais altos disponíveis (RPM/TPM). Em alguns casos, limites para grandes clientes podem ser aumentados através do suporte.
Os limites do ChatGPT se resetam se eu usar navegadores diferentes?
Não. Os limites estão vinculados à sua conta, não ao navegador. Usar navegadores ou abas diferentes não altera o contador de mensagens.
Os limites do ChatGPT estão vinculados à conta ou ao dispositivo?
Os limites do ChatGPT estão vinculados à conta. Dispositivo, navegador e endereço IP não afetam o número de mensagens disponíveis. Uma conta equivale a um limite compartilhado.
Qual é a diferença entre limites de tokens e limites de taxa?
Estes são sistemas diferentes. Os limites de tokens definem quanto texto (entrada e saída) pode ser processado em uma única solicitação ou dentro de um contexto de conversa. Os limites de taxa definem com que frequência você pode enviar solicitações ao longo de um período de tempo. Você pode atingir um limite sem alcançar o outro.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.

Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.
Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.
Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.