Entenda o que é web scraping e como funciona


Palina Zabela
Content Manager, Octo Browser
O web scraping, ou coleta de dados em português, é uma maneira rápida de reunir informações on-line. Bots vasculham sites e coletam informações como preços de produtos, variedade de lojas on-line, contatos de possíveis clientes e muito mais. Essas informações são então vendidas ou utilizadas para o desenvolvimento de negócios. Além disso, redes neurais são treinadas com dados reunidos por web scrapers. Como se coleta informações de sites automaticamente? Quais ferramentas são usadas no processo? Como se acessa informações protegidas? A equipe do Octo Browser preparou um guia detalhado com respostas.
Índice
Mantenha o anonimato, aproveite o recurso multiconta e alcance seus objetivos com o melhor navegador antidetecção do mercado.
Você gostaria de experimentar o Octo Browser com desconto?
Use o código promocional OCTOSCRAPER para obter 30% de desconto em qualquer assinatura. Esta oferta é válida apenas para novos usuários.
O que é web scraping?
Web scraping é o processo de coletar grandes volumes de informações da web usando bots. O processo consiste em duas etapas: buscar as informações necessárias e estruturá-las. Quando você copia dados de texto de um site e os cola em um documento, você também está essencialmente envolvido em web scraping. A diferença é que os scripts trabalham mais rápido, evitam erros e extraem informações do código HTML em vez dos componentes visuais da página. Os web scrapers coletam bancos de dados usados para comparação de preços, análise de mercado, geração de leads e monitoramento de notícias.
Como os web scrapers funcionam?
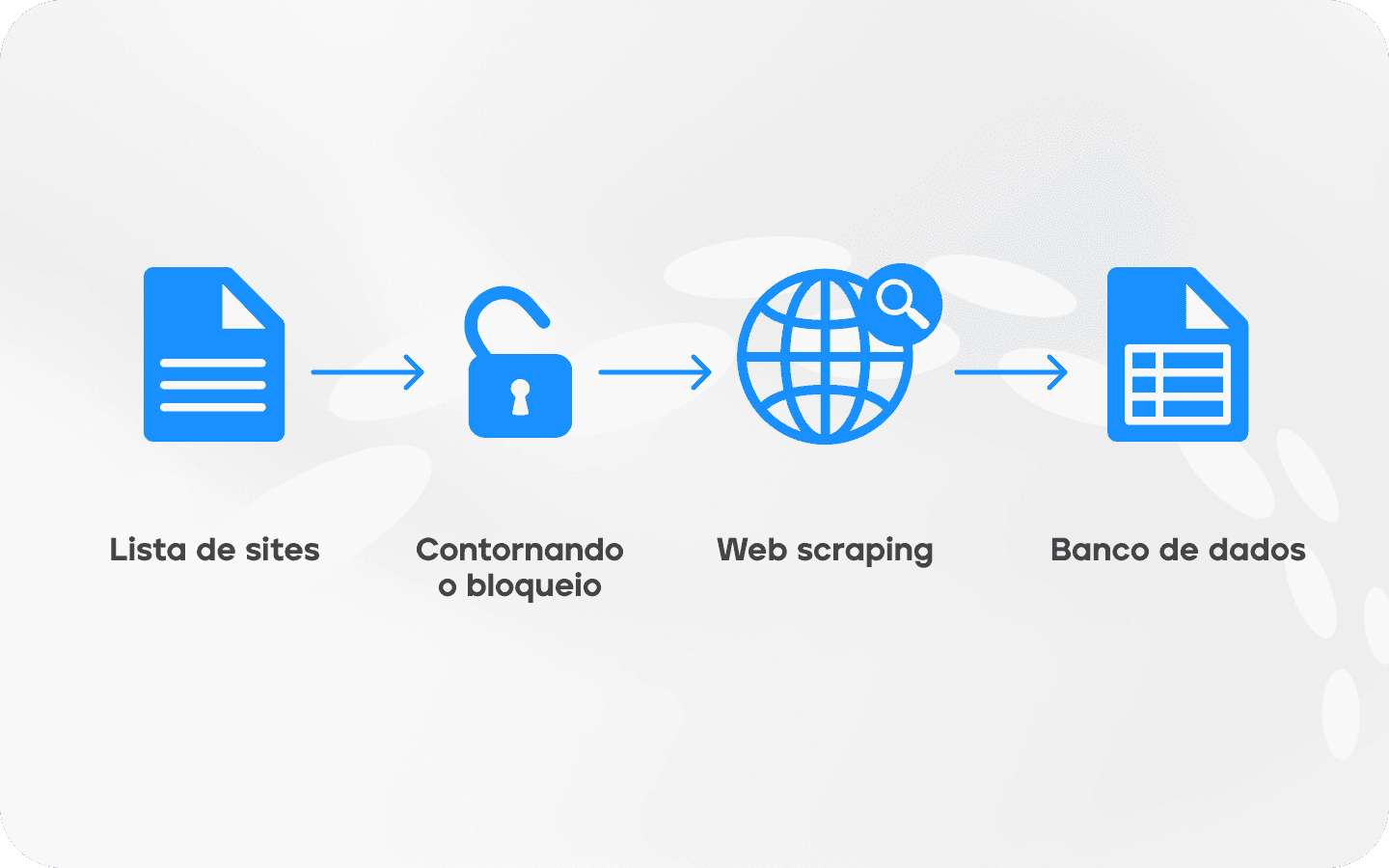
Scripts, bots, APIs e serviços com interface gráfica para web scraping operam basicamente da mesma forma. Primeiro, você compila uma lista de sites que o robô visitará e decide quais informações ele extrairá. Por exemplo, para comparação de preços, você precisa do nome do produto, link da loja e o próprio preço. Para análise competitiva, você também precisará de especificações do produto, métodos de envio e avaliações. Quanto menos detalhes você solicitar, mais rápido o script os coletará.
Uma vez formulada a tarefa, o bot acessa as páginas, carrega o código HTML e extrai as informações. Scripts mais complexos também são capazes de analisar CSS e JavaScript.
Às vezes, é necessário fazer login em uma conta na plataforma para coletar dados, por exemplo, quando você precisa reunir dados de contato de especialistas no LinkedIn. Nesses casos, um algoritmo para contornar as medidas de proteção do site é adicionado ao algoritmo de coleta de informações.
O último passo é a estruturação das informações coletadas na forma de tabela ou planilha (CSV ou Excel), um banco de dados ou em formato JSON, que é adequado para API.
Ferramentas de web scraping

Para coletar dados, você precisará de um web scraper que visite o site-alvo e recupere as informações necessárias dele. Existem várias opções para escolher:
Software de código aberto especificamente criado para web scraping: Scrapy, Crawlee, Mechanize;
Clientes HTTP: solicitações, HTTPX, Axios para extrair dados de HTML, XML, RSS, por exemplo, Beautiful Soup, lxml, Cheerio;
Soluções de automação de navegador: Puppeteer, Playwright, Selenium e outros serviços que podem se conectar a um navegador, recuperar HTML/XML e analisar o documento;
Serviços como Zyte, Apify, Surfsky, Browserless, Scrapingbee, Import.io, que fornecem API ou CDP e atuam como intermediários entre o script cliente e o serviço-alvo.
Para realizar web scraping com sucesso, você precisará, além de um parser, dos seguintes itens:
Uma ferramenta para ignorar CAPTCHAs;
Proxies;
Um navegador multiconta.
Os proprietários de sites aplicam medidas de proteção contra web scraping rastreando endereços IP e identificadores de dispositivos exclusivos chamados de impressões digitais. Se os sistemas de proteção detectarem atividade suspeita, como solicitações muito frequentes de um único dispositivo, eles bloqueiam o acesso ao site.
Alguns sites adicionam CAPTCHAs para evitar que os web scrapers coletem dados. Serviços especiais, como 2Captcha, CapSolver, Death By Captcha e BypassCaptcha, são capazes de resolver CAPTCHAs. Você precisa integrar o serviço ao aplicativo, chamá-lo via API, passar pelo CAPTCHA e obter a solução em questão de segundos. As ferramentas de resolução de CAPTCHA suportam linguagens de programação populares, como PHP, JavaScript, C#, Java e Python.
O problema do bloqueio por endereços IP é resolvido usando vários servidores proxy dinâmicos. Certifique-se de monitorar a frequência das solicitações para evitar a sobrecarga de recursos on-line. Dessa forma, o bot atrairá menos suspeitas, reduzindo a probabilidade de ser banido.
O rastreamento por impressão digital é contornado com a ajuda do Octo Browser, que é especificamente projetado para várias contas. Esse software substitui a impressão digital do seu dispositivo por outra de um usuário real. Os perfis de antidetecção de um navegador multiconta são indistinguíveis de outros visitantes regulares, então eles não são bloqueados ou forçados a resolver CAPTCHAs.
Além de spoofing de impressão digital, o Octo oferece outras funcionalidades úteis que simplificam o web scraping, como:
Adição em massa de proxies para economizar tempo;
API para automação;
Um navegador headless que reduz a carga do dispositivo e o consumo de recursos.
Linguagens de programação para web scraping
Você pode encontrar frameworks, bibliotecas e ferramentas para web scraping em várias linguagens. A Bright Data destaca cinco das mais populares:
Python possui um ótimo ecossistema de bibliotecas. Sua sintaxe simples e ferramentas prontas para uso, como Beautiful Soup e Scrapy, tornam-no uma escolha ideal para web scraping. No entanto, Python pode ter um desempenho inferior em comparação com linguagens compiladas.
JavaScript é usada no desenvolvimento front-end, então suporta recursos de navegador embutidos. JavaScript possui capacidades assíncronas e lida com HTML em páginas da web. Você pode usar bibliotecas como Axios, Cheerio, Puppeteer e Playwright para esses fins; no entanto, as capacidades dessa linguagem estão limitadas ao ambiente do navegador.
Ruby atrai desenvolvedores com sua sintaxe simples, flexibilidade, uma variedade de bibliotecas de web scraping (como Nokogiri, Mechanize, httparty, selenium-webdriver, OpenURI e Wati) e uma comunidade ativa. No entanto, Ruby fica atrás de outras linguagens em termos de desempenho.
PHP é adequada para desenvolvimento server-side e integração com bancos de dados. Uma comunidade ativa e uma variedade de ferramentas disponíveis são as principais vantagens da PHP e bibliotecas como PHP Simple HTML DOM Parser, Guzzle, Panther, Httpful e cURL são adequadas para web scraping. No entanto, o desempenho e a flexibilidade da PHP podem ser ligeiramente inferiores em comparação com outras linguagens.
C++ possui alto desempenho e controle total sobre recursos. Uma ampla seleção de bibliotecas, incluindo libcurl, Boost.Asio, htmlcxx e libtidy, e o suporte da comunidade tornam-na interessante para web scraping. No entanto, a sintaxe da C++ é mais complexa do que a de outras linguagens populares. Você também precisa ser capaz de compilar código, o que pode desencorajar alguns desenvolvedores.
Tipos de web scrapers
Existem quatro parâmetros principais para escolher a ferramenta de scraping certa.
Autointegrado ou pré-integrado
Você pode criar um web scraper por si próprio se souber como programar. Quanto mais funcionalidades desejar adicionar, mais conhecimento precisará para escrever o bot. Por outro lado, você pode encontrar programas prontos on-line que são compreensíveis até mesmo para aqueles que não sabem programar. Alguns deles até mesmo têm funcionalidades adicionais, como agendamento, exportação JSON e integração com Google Sheets.
Extensão de navegador vs. software
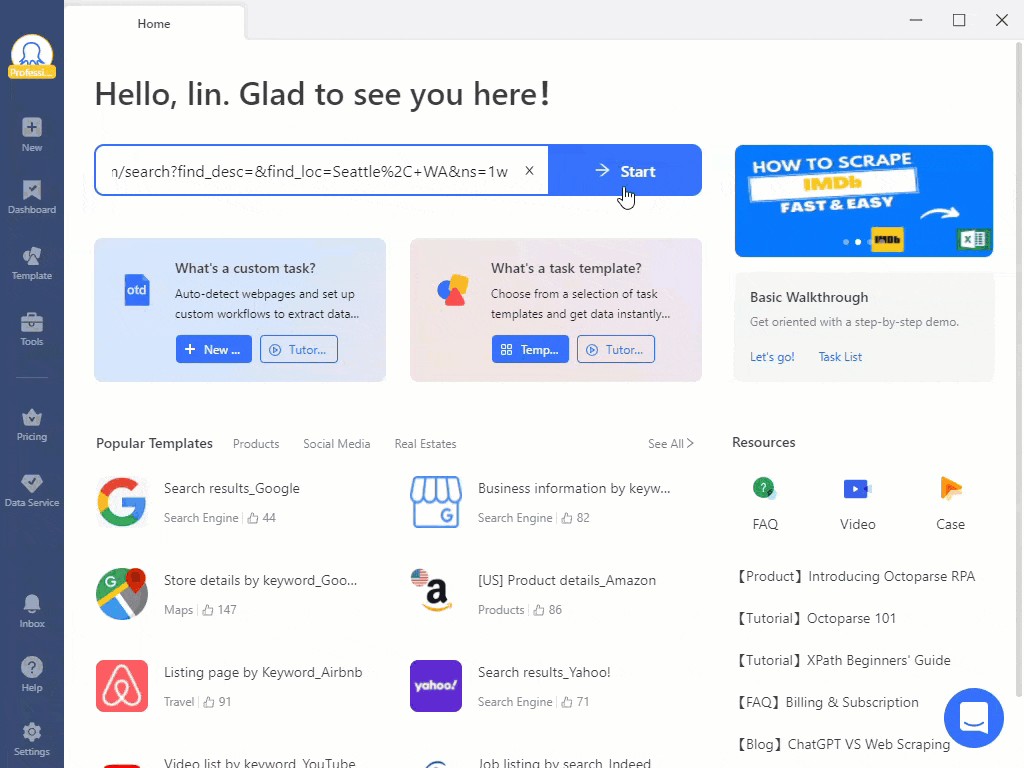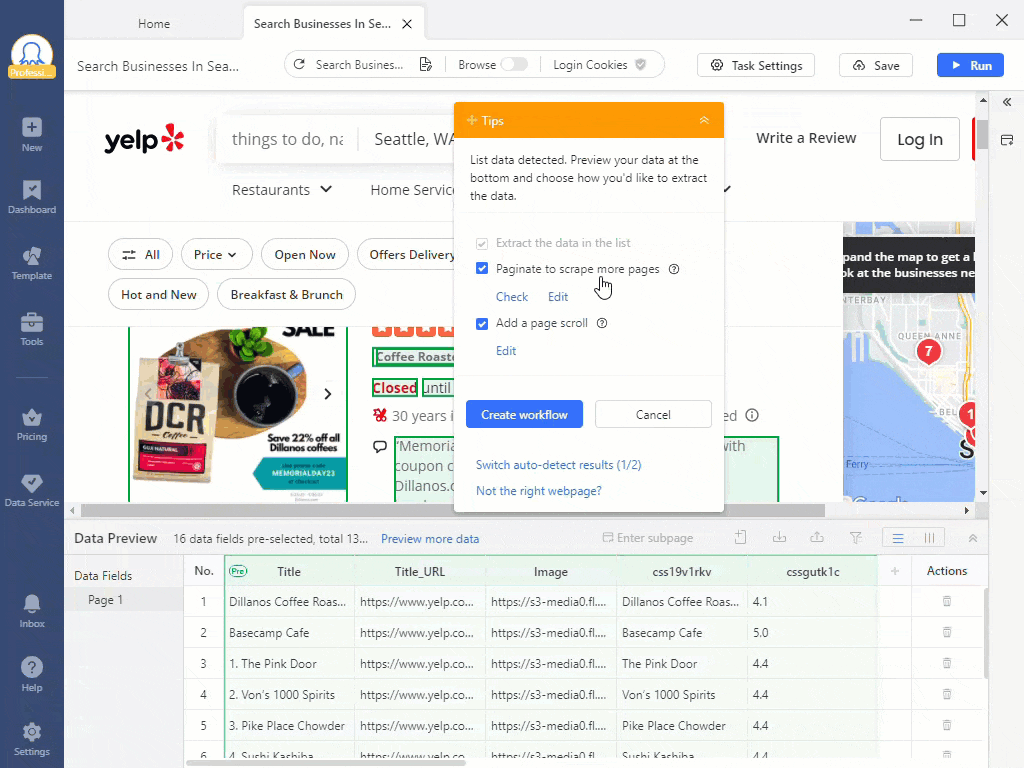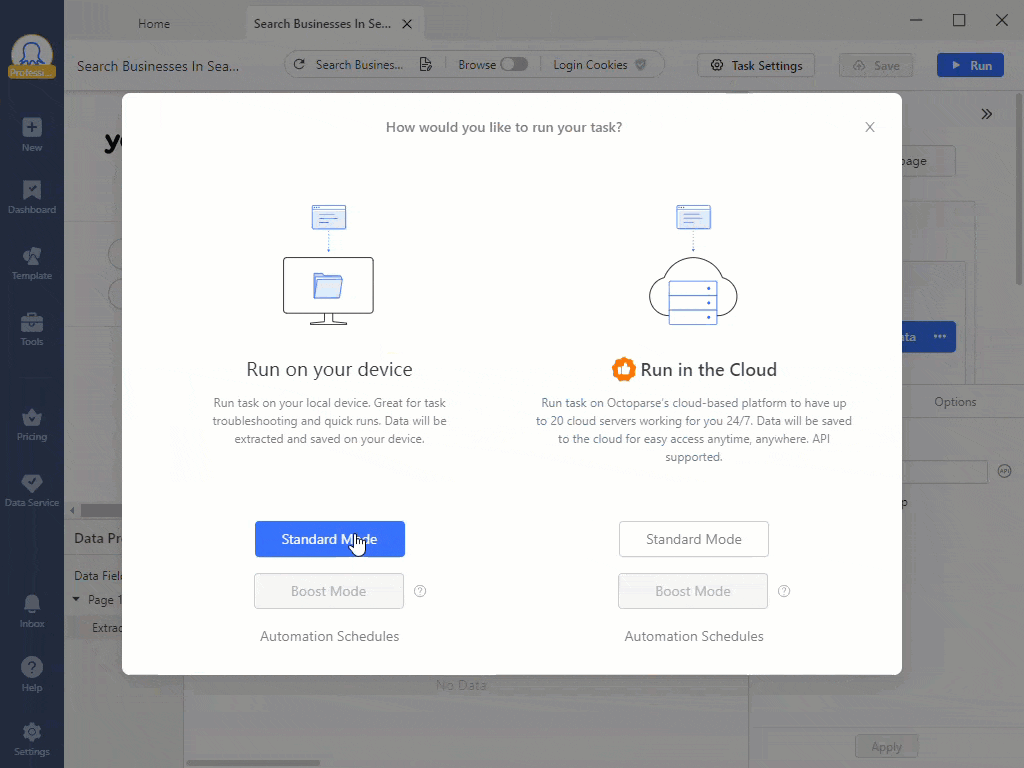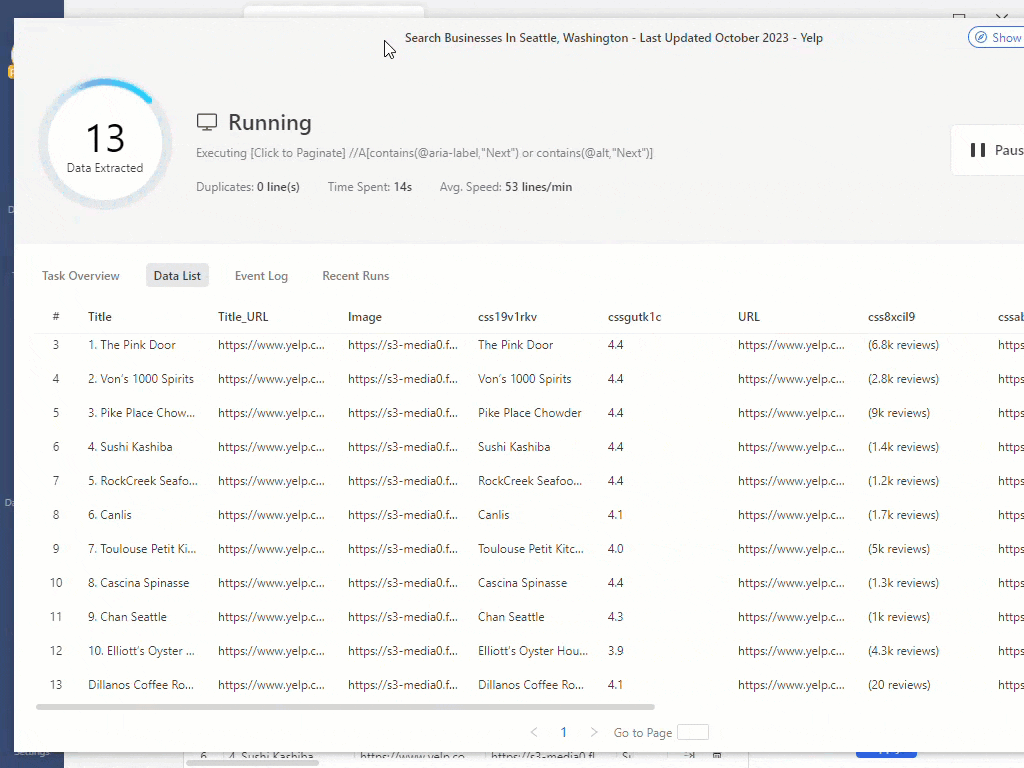
Web scraping com Octoparse
Trabalhar com uma extensão instalada dentro de um navegador é a opção mais fácil, mas suas capacidades são limitadas. Por exemplo, a rotação de IP pode não estar disponível. Ao mesmo tempo, programas de software autônomos são mais complexos, mas oferecem mais funcionalidades. Por exemplo, no Octoparse você pode criar seu próprio web scraper que irá percorrer sites em um cronograma, fornecer orientações durante o processo e resolver CAPTCHAs.
Interface do usuário
Algumas soluções de web scraping têm apenas uma interface de linha de comando e uma UI mínima, enquanto outras exibem o site, permitindo que você selecione as informações que deseja coletar. Alguns serviços até mesmo incluem dicas para ajudar os usuários a entender o objetivo de cada função.
Nuvem vs. local
Os web scrapers locais utilizam a RAM do dispositivo local, o que significa que você não pode executar outros processos simultaneamente. As ferramentas baseadas em nuvem funcionam em um servidor remoto. Enquanto o parser coleta dados, você pode realizar outras tarefas no seu dispositivo. Os serviços em nuvem também incluem funcionalidades adicionais, como rotação de IP.
Para que serve o web scraping?
As planilhas criadas por web scrapers são utilizadas por especialistas em marketing, analistas e empresários. As maneiras populares de usar bancos de dados coletados da internet são:
Pesquisa de mercado
Especialistas em marketing analisam vantagens e desvantagens de produtos, preços, métodos de entrega e estratégias dos concorrentes. Por meio do web scraping, os profissionais de marketing obtêm grandes volumes de dados precisos, o que ajuda a melhorar a precisão das previsões e otimizar as estratégias de marketing.
Rastreamento de preços
Agregadores comparam preços e buscam os produtos mais baratos, e serviços especializados analisam mudanças de preços. Algumas empresas monitoram constantemente os preços de seus concorrentes e ajustam os seus próprios para serem os mais baixos. Todos obtêm as informações necessárias por meio do web scraping.
Automatização de negócios
Funcionários de empresas gastam muito tempo coletando e processando grandes volumes de informações. Por exemplo, pesquisar 10 sites de concorrentes poderia levar vários dias. Um script pode fazer o mesmo trabalho em algumas horas e economizar os recursos do funcionário.
Geração de leads
Encontrar clientes é a principal tarefa dos profissionais de marketing. Para fazer isso, eles pesquisam as necessidades, problemas, interesses e comportamentos dos usuários. O web scraping acelera a busca por possíveis clientes. Este método é especialmente conveniente para o setor B2B, pois as empresas não ocultam informações on-line sobre si mesmas.
Monitoramento de notícias e conteúdo
A reputação da empresa afeta a confiança do cliente e as receitas. Para reagir a menções negativas de forma oportuna, os gerentes de RP monitoram as notícias diariamente por meio da análise de marca e acompanham as notícias sobre seus concorrentes. Tais sites coletam menções de marca usando web scrapers.
Web scraping é legal?
Uma parte significativa das informações on-line está disponível para todos os usuários. Por exemplo, você pode visitar a Wikipedia, ler um artigo e copiar seu texto. Não há nada ilegal em fazer o mesmo automaticamente. É proibido fazer scraping de conteúdo que:
esteja protegido por direitos autorais;
conteha dados pessoais;
esteja acessível apenas para usuários cadastrados no serviço.
Outro problema é a carga nos sites criada pelos bots. Se houver muitas solicitações de robôs, os usuários não poderão acessar o recurso. Para cumprir a lei, monitore as informações que você coleta e com que frequência envia solicitações.
Tudo o que você precisa saber sobre web scraping
Web scraping é o processo de coletar dados da internet, que são então usados em análises de marketing, monitoramento de preços e notícias, e automação de processos rotineiros. Você pode extrair informações de sites manualmente ou por meio de ferramentas especiais chamadas web scrapers. Convencionalmente, são divididas em quatro tipos: software de código aberto, extensões de navegador, clientes HTTP e serviços baseados em API e CDP.
Durante o web scraping, os scrapers podem encontrar medidas de proteção do site: CAPTCHAs, diversas armadilhas, bloqueio baseado em endereço IP e impressão digital. Essas medidas são contornadas ou evitadas com a ajuda de três serviços adicionais: ferramentas de resolução de CAPTCHA, proxies e navegadores multiconta.
Mantenha o anonimato, aproveite o recurso multiconta e alcance seus objetivos com o melhor navegador antidetecção do mercado.
Você gostaria de experimentar o Octo Browser com desconto?
Use o código promocional OCTOSCRAPER para obter 30% de desconto em qualquer assinatura. Esta oferta é válida apenas para novos usuários.
O que é web scraping?
Web scraping é o processo de coletar grandes volumes de informações da web usando bots. O processo consiste em duas etapas: buscar as informações necessárias e estruturá-las. Quando você copia dados de texto de um site e os cola em um documento, você também está essencialmente envolvido em web scraping. A diferença é que os scripts trabalham mais rápido, evitam erros e extraem informações do código HTML em vez dos componentes visuais da página. Os web scrapers coletam bancos de dados usados para comparação de preços, análise de mercado, geração de leads e monitoramento de notícias.
Como os web scrapers funcionam?
Scripts, bots, APIs e serviços com interface gráfica para web scraping operam basicamente da mesma forma. Primeiro, você compila uma lista de sites que o robô visitará e decide quais informações ele extrairá. Por exemplo, para comparação de preços, você precisa do nome do produto, link da loja e o próprio preço. Para análise competitiva, você também precisará de especificações do produto, métodos de envio e avaliações. Quanto menos detalhes você solicitar, mais rápido o script os coletará.
Uma vez formulada a tarefa, o bot acessa as páginas, carrega o código HTML e extrai as informações. Scripts mais complexos também são capazes de analisar CSS e JavaScript.
Às vezes, é necessário fazer login em uma conta na plataforma para coletar dados, por exemplo, quando você precisa reunir dados de contato de especialistas no LinkedIn. Nesses casos, um algoritmo para contornar as medidas de proteção do site é adicionado ao algoritmo de coleta de informações.
O último passo é a estruturação das informações coletadas na forma de tabela ou planilha (CSV ou Excel), um banco de dados ou em formato JSON, que é adequado para API.
Ferramentas de web scraping
Para coletar dados, você precisará de um web scraper que visite o site-alvo e recupere as informações necessárias dele. Existem várias opções para escolher:
Software de código aberto especificamente criado para web scraping: Scrapy, Crawlee, Mechanize;
Clientes HTTP: solicitações, HTTPX, Axios para extrair dados de HTML, XML, RSS, por exemplo, Beautiful Soup, lxml, Cheerio;
Soluções de automação de navegador: Puppeteer, Playwright, Selenium e outros serviços que podem se conectar a um navegador, recuperar HTML/XML e analisar o documento;
Serviços como Zyte, Apify, Surfsky, Browserless, Scrapingbee, Import.io, que fornecem API ou CDP e atuam como intermediários entre o script cliente e o serviço-alvo.
Para realizar web scraping com sucesso, você precisará, além de um parser, dos seguintes itens:
Uma ferramenta para ignorar CAPTCHAs;
Proxies;
Um navegador multiconta.
Os proprietários de sites aplicam medidas de proteção contra web scraping rastreando endereços IP e identificadores de dispositivos exclusivos chamados de impressões digitais. Se os sistemas de proteção detectarem atividade suspeita, como solicitações muito frequentes de um único dispositivo, eles bloqueiam o acesso ao site.
Alguns sites adicionam CAPTCHAs para evitar que os web scrapers coletem dados. Serviços especiais, como 2Captcha, CapSolver, Death By Captcha e BypassCaptcha, são capazes de resolver CAPTCHAs. Você precisa integrar o serviço ao aplicativo, chamá-lo via API, passar pelo CAPTCHA e obter a solução em questão de segundos. As ferramentas de resolução de CAPTCHA suportam linguagens de programação populares, como PHP, JavaScript, C#, Java e Python.
O problema do bloqueio por endereços IP é resolvido usando vários servidores proxy dinâmicos. Certifique-se de monitorar a frequência das solicitações para evitar a sobrecarga de recursos on-line. Dessa forma, o bot atrairá menos suspeitas, reduzindo a probabilidade de ser banido.
O rastreamento por impressão digital é contornado com a ajuda do Octo Browser, que é especificamente projetado para várias contas. Esse software substitui a impressão digital do seu dispositivo por outra de um usuário real. Os perfis de antidetecção de um navegador multiconta são indistinguíveis de outros visitantes regulares, então eles não são bloqueados ou forçados a resolver CAPTCHAs.
Além de spoofing de impressão digital, o Octo oferece outras funcionalidades úteis que simplificam o web scraping, como:
Adição em massa de proxies para economizar tempo;
API para automação;
Um navegador headless que reduz a carga do dispositivo e o consumo de recursos.
Linguagens de programação para web scraping
Você pode encontrar frameworks, bibliotecas e ferramentas para web scraping em várias linguagens. A Bright Data destaca cinco das mais populares:
Python possui um ótimo ecossistema de bibliotecas. Sua sintaxe simples e ferramentas prontas para uso, como Beautiful Soup e Scrapy, tornam-no uma escolha ideal para web scraping. No entanto, Python pode ter um desempenho inferior em comparação com linguagens compiladas.
JavaScript é usada no desenvolvimento front-end, então suporta recursos de navegador embutidos. JavaScript possui capacidades assíncronas e lida com HTML em páginas da web. Você pode usar bibliotecas como Axios, Cheerio, Puppeteer e Playwright para esses fins; no entanto, as capacidades dessa linguagem estão limitadas ao ambiente do navegador.
Ruby atrai desenvolvedores com sua sintaxe simples, flexibilidade, uma variedade de bibliotecas de web scraping (como Nokogiri, Mechanize, httparty, selenium-webdriver, OpenURI e Wati) e uma comunidade ativa. No entanto, Ruby fica atrás de outras linguagens em termos de desempenho.
PHP é adequada para desenvolvimento server-side e integração com bancos de dados. Uma comunidade ativa e uma variedade de ferramentas disponíveis são as principais vantagens da PHP e bibliotecas como PHP Simple HTML DOM Parser, Guzzle, Panther, Httpful e cURL são adequadas para web scraping. No entanto, o desempenho e a flexibilidade da PHP podem ser ligeiramente inferiores em comparação com outras linguagens.
C++ possui alto desempenho e controle total sobre recursos. Uma ampla seleção de bibliotecas, incluindo libcurl, Boost.Asio, htmlcxx e libtidy, e o suporte da comunidade tornam-na interessante para web scraping. No entanto, a sintaxe da C++ é mais complexa do que a de outras linguagens populares. Você também precisa ser capaz de compilar código, o que pode desencorajar alguns desenvolvedores.
Tipos de web scrapers
Existem quatro parâmetros principais para escolher a ferramenta de scraping certa.
Autointegrado ou pré-integrado
Você pode criar um web scraper por si próprio se souber como programar. Quanto mais funcionalidades desejar adicionar, mais conhecimento precisará para escrever o bot. Por outro lado, você pode encontrar programas prontos on-line que são compreensíveis até mesmo para aqueles que não sabem programar. Alguns deles até mesmo têm funcionalidades adicionais, como agendamento, exportação JSON e integração com Google Sheets.
Extensão de navegador vs. software
Web scraping com Octoparse
Trabalhar com uma extensão instalada dentro de um navegador é a opção mais fácil, mas suas capacidades são limitadas. Por exemplo, a rotação de IP pode não estar disponível. Ao mesmo tempo, programas de software autônomos são mais complexos, mas oferecem mais funcionalidades. Por exemplo, no Octoparse você pode criar seu próprio web scraper que irá percorrer sites em um cronograma, fornecer orientações durante o processo e resolver CAPTCHAs.
Interface do usuário
Algumas soluções de web scraping têm apenas uma interface de linha de comando e uma UI mínima, enquanto outras exibem o site, permitindo que você selecione as informações que deseja coletar. Alguns serviços até mesmo incluem dicas para ajudar os usuários a entender o objetivo de cada função.
Nuvem vs. local
Os web scrapers locais utilizam a RAM do dispositivo local, o que significa que você não pode executar outros processos simultaneamente. As ferramentas baseadas em nuvem funcionam em um servidor remoto. Enquanto o parser coleta dados, você pode realizar outras tarefas no seu dispositivo. Os serviços em nuvem também incluem funcionalidades adicionais, como rotação de IP.
Para que serve o web scraping?
As planilhas criadas por web scrapers são utilizadas por especialistas em marketing, analistas e empresários. As maneiras populares de usar bancos de dados coletados da internet são:
Pesquisa de mercado
Especialistas em marketing analisam vantagens e desvantagens de produtos, preços, métodos de entrega e estratégias dos concorrentes. Por meio do web scraping, os profissionais de marketing obtêm grandes volumes de dados precisos, o que ajuda a melhorar a precisão das previsões e otimizar as estratégias de marketing.
Rastreamento de preços
Agregadores comparam preços e buscam os produtos mais baratos, e serviços especializados analisam mudanças de preços. Algumas empresas monitoram constantemente os preços de seus concorrentes e ajustam os seus próprios para serem os mais baixos. Todos obtêm as informações necessárias por meio do web scraping.
Automatização de negócios
Funcionários de empresas gastam muito tempo coletando e processando grandes volumes de informações. Por exemplo, pesquisar 10 sites de concorrentes poderia levar vários dias. Um script pode fazer o mesmo trabalho em algumas horas e economizar os recursos do funcionário.
Geração de leads
Encontrar clientes é a principal tarefa dos profissionais de marketing. Para fazer isso, eles pesquisam as necessidades, problemas, interesses e comportamentos dos usuários. O web scraping acelera a busca por possíveis clientes. Este método é especialmente conveniente para o setor B2B, pois as empresas não ocultam informações on-line sobre si mesmas.
Monitoramento de notícias e conteúdo
A reputação da empresa afeta a confiança do cliente e as receitas. Para reagir a menções negativas de forma oportuna, os gerentes de RP monitoram as notícias diariamente por meio da análise de marca e acompanham as notícias sobre seus concorrentes. Tais sites coletam menções de marca usando web scrapers.
Web scraping é legal?
Uma parte significativa das informações on-line está disponível para todos os usuários. Por exemplo, você pode visitar a Wikipedia, ler um artigo e copiar seu texto. Não há nada ilegal em fazer o mesmo automaticamente. É proibido fazer scraping de conteúdo que:
esteja protegido por direitos autorais;
conteha dados pessoais;
esteja acessível apenas para usuários cadastrados no serviço.
Outro problema é a carga nos sites criada pelos bots. Se houver muitas solicitações de robôs, os usuários não poderão acessar o recurso. Para cumprir a lei, monitore as informações que você coleta e com que frequência envia solicitações.
Tudo o que você precisa saber sobre web scraping
Web scraping é o processo de coletar dados da internet, que são então usados em análises de marketing, monitoramento de preços e notícias, e automação de processos rotineiros. Você pode extrair informações de sites manualmente ou por meio de ferramentas especiais chamadas web scrapers. Convencionalmente, são divididas em quatro tipos: software de código aberto, extensões de navegador, clientes HTTP e serviços baseados em API e CDP.
Durante o web scraping, os scrapers podem encontrar medidas de proteção do site: CAPTCHAs, diversas armadilhas, bloqueio baseado em endereço IP e impressão digital. Essas medidas são contornadas ou evitadas com a ajuda de três serviços adicionais: ferramentas de resolução de CAPTCHA, proxies e navegadores multiconta.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.

Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.
Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.
Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.