Phân tích hành vi: đó là gì và các chuyên gia tự động hóa có thể vượt qua nó như thế nào
22/5/26


Markus_automation
Expert in data parsing and automation
Cách đây không lâu, các hệ thống chống gian lận chủ yếu dựa vào các thuộc tính kỹ thuật—địa chỉ IP, cookie và dấu vân tay trình duyệt. Tuy nhiên, khi các nhà phát triển script và scraper học được cách giả mạo hiệu quả những tham số này, trọng tâm của công tác bảo vệ đã chuyển sang phân tích hành vi.
Sinh trắc học hành vi đánh giá chính xác cách một người dùng tương tác với giao diện và đang dần trở thành một thành phần then chốt của các hệ thống phát hiện tự động hóa hiện đại.
Trong bài viết này, chúng tôi thảo luận về cách phương pháp này hoạt động và giải thích cách tái tạo hành vi con người một cách chân thực trong các kịch bản tự động hóa.
Nội dung
Giữ kín danh tính, tận dụng tính năng nhiều tài khoản và đạt được mục tiêu của bạn với trình duyệt chống phát hiện chất lượng cao nhất trên thị trường.
Bạn có muốn thử Octo Browser với giá giảm không?
Sử dụng mã khuyến mãi OCTOSCRAPER để được giảm giá 30% cho bất kỳ gói đăng ký nào. Ưu đãi này chỉ dành cho người dùng mới.
Tại sao CAPTCHA đang nhường chỗ cho phân tích hành vi
Trước đây, CAPTCHA là cơ chế phòng thủ chính chống lại bot. CAPTCHA vẫn tồn tại ngày nay, dù đã thay đổi đáng kể. Chúng đã trở nên tinh vi hơn, và một số phiên bản vô hình hiện đại (như reCAPTCHA v3) đã tích hợp chính những sinh trắc học hành vi mà chúng ta đang bàn đến.
Tại sao điều này cần thiết? CAPTCHA truyền thống (đèn giao thông và các ký tự méo mó) làm xấu đi trải nghiệm người dùng và ngày càng bị các mạng nơ-ron đã huấn luyện giải quyết dễ dàng. Cách tiếp cận mới, hoạt động mà không cần các phần tử hiển thị, giúp giảm gánh nặng cho người dùng và tránh làm họ khó chịu.
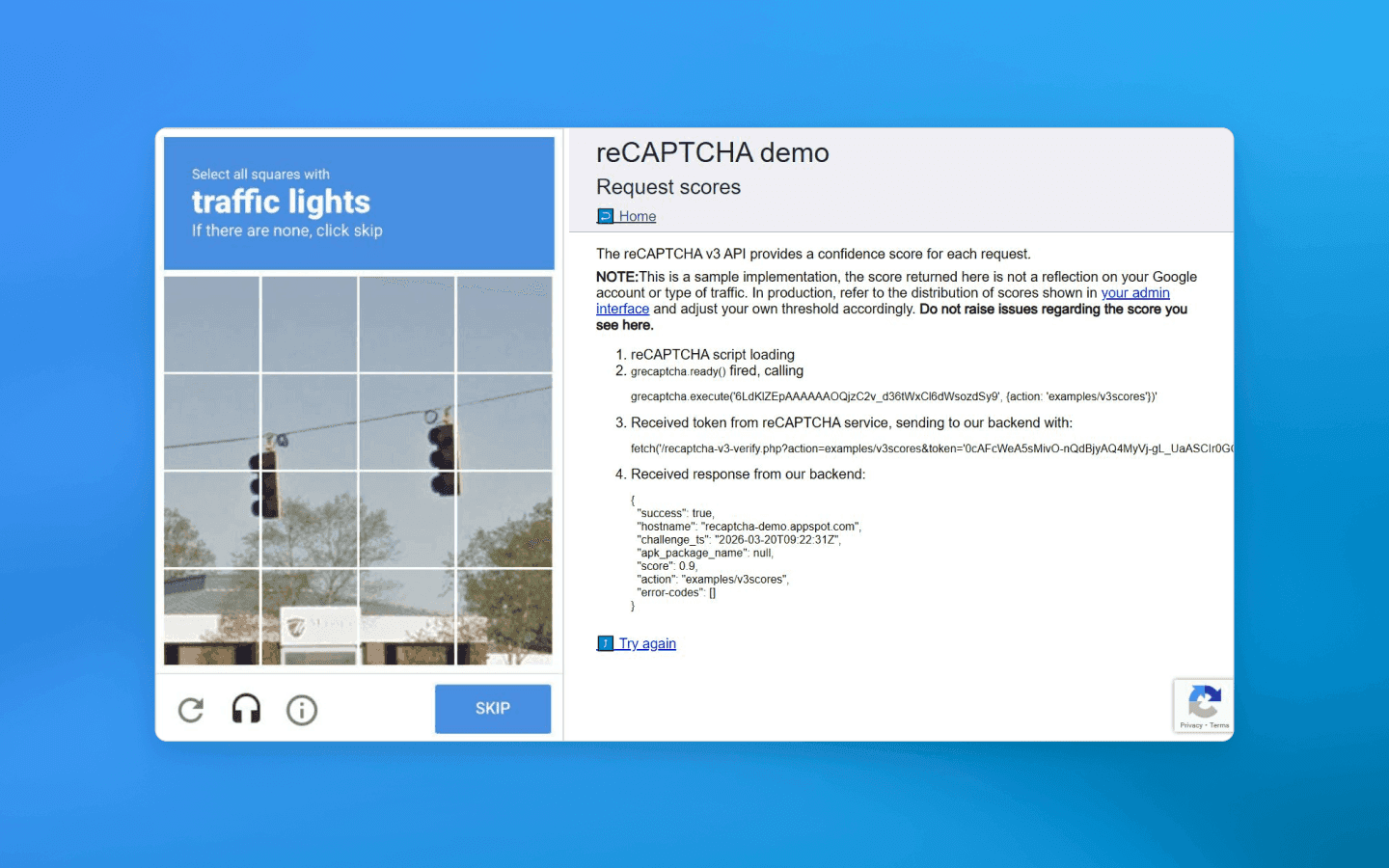
Sinh trắc học hành vi, với vai trò là lõi của quy trình xác minh vô hình này, cung cấp xác thực liên tục. Nó hoạt động bằng cách phân tích chính xác cách một người dùng tương tác với thiết bị khi cuộn trang hoặc điền biểu mẫu, mà không cần bất kỳ đầu vào bổ sung nào.
Tuy nhiên, cần làm rõ một điểm quan trọng: sinh trắc học hành vi không được dùng như một phương pháp xác minh độc lập. Nó luôn hoạt động cùng với các kiểm tra khác. Ngoài sinh trắc học, các hệ thống chống gian lận vẫn phân tích vân tay số, uy tín IP và cookie.
Các loại sinh trắc học hành vi
Hãy đi sâu hơn vào lý thuyết. Các mẫu hành vi về cơ bản là một vân tay số của hệ thần kinh của bạn được chuyển lên thiết bị. Các hệ thống chống gian lận tiên tiến không phân tích các tham số riêng rẽ. Thay vào đó, họ xây dựng một hồ sơ đa chiều toàn diện có thể được chia thành các nhóm sau:
Tương tác thiết bị (kinesthetics)
Đây là lớp dữ liệu lớn nhất đối với các ứng dụng web và di động truyền thống. Ở đây, các hệ thống phân tích vật lý của chuyển động người dùng.
Bàn phím: không phải là bạn gõ những chữ cái hay con số nào. Các hệ thống chống gian lận đánh giá hai tham số chính: một phím được giữ xuống bao lâu (
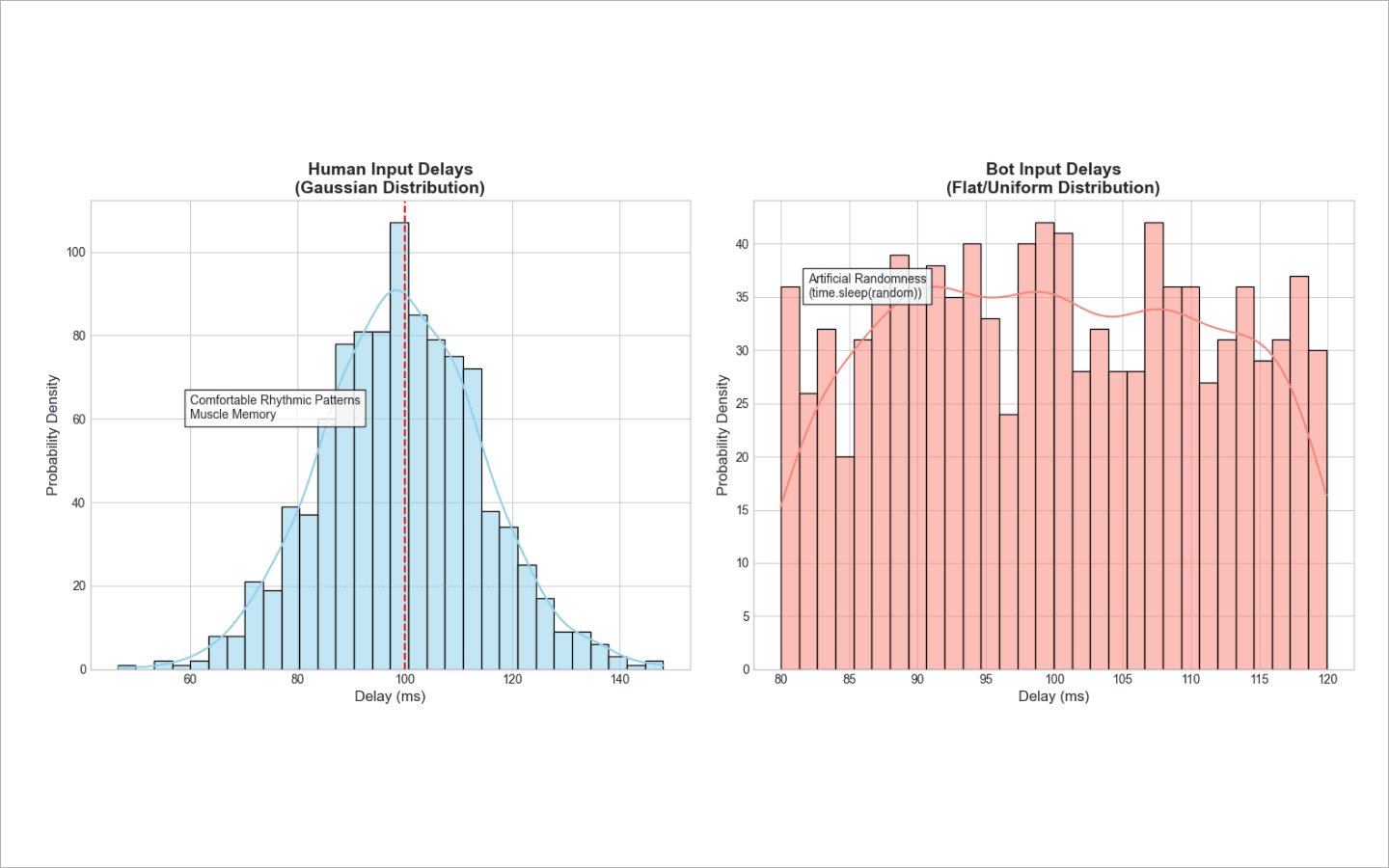
dwell time) và mất bao lâu để di chuyển giữa các phím (flight time). Con người có trí nhớ cơ bắp — các tổ hợp phím quen thuộc (ví dụ, những đuôi từ phổ biến) được gõ thành các đợt vi mô. Trong khi đó, bot hoặc chèn toàn bộ chuỗi cùng lúc, hoặc giả lập việc gõ bằng logictime.sleep(random)đơn giản. Điều này tạo ra một phân bố độ trễ phẳng, không tự nhiên. Bản thân tính ngẫu nhiên cũng trở nên đáng ngờ.Chuột: phân tích con trỏ. Hệ thống ghi lại tọa độ và tính tốc độ, gia tốc, độ cong của quỹ đạo và các cú giật. Con người không di chuyển chuột theo những đường thẳng hoàn hảo. Chúng ta nhắm vào một nút, lệch vài pixel, thực hiện những chỉnh sửa nhỏ, rồi tạm dừng ngắn trước khi nhấp.
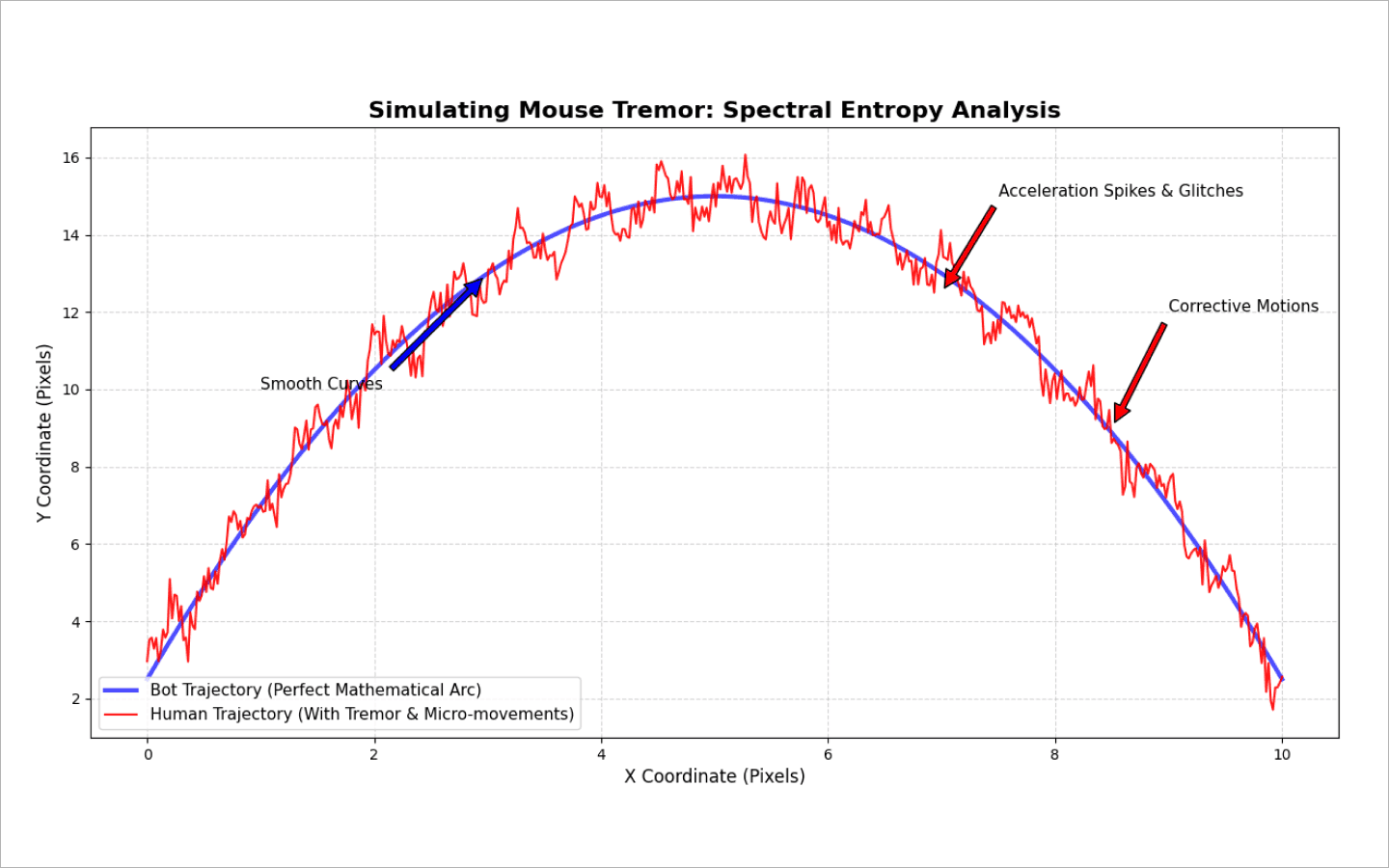
Màn hình cảm ứng: dành riêng cho web di động và các ứng dụng gốc. Một cú vuốt của con người là một cung với tốc độ không đều, áp lực cụ thể (nếu API cho phép phát hiện áp lực), và diện tích tiếp xúc của ngón tay thay đổi. Các bot giả lập sự kiện chạm qua Appium hoặc các script JavaScript thường chỉ đơn giản “dịch chuyển tức thời” tọa độ focus. Viết đúng toán học cho một cú vuốt thực tế khó hơn nhiều, nên những người vận hành bot thường làm qua loa.
Các mẫu vật lý (sinh cơ học)
Khi một người dùng truy cập nền tảng từ thiết bị di động, các cảm biến phần cứng sẽ tham gia. Và vì chúng ta hiện đang sống trong thời đại người dùng di động, điều này rất quan trọng.
Mẫu bước đi và vi chuyển động. Bạn đang cuộn bảng tin khi đang đi bộ, ngồi trên ghế hay nằm trên ghế sofa? Gia tốc kế và con quay hồi chuyển của điện thoại thông minh liên tục ghi lại những rung động rất nhỏ của thiết bị. Điện thoại của một người dùng thực luôn hơi rung trong tay họ, ngay cả khi họ cố giữ nó thật yên. Các trang trại bot và trình giả lập chạy trên máy chủ thường mặc định hoàn toàn không có nhiễu nền từ cảm biến, cho các hệ thống chống gian lận một điều để nghĩ tới và làm tăng điểm rủi ro.
Các mẫu nhận thức (tâm lý tương tác)
Đây là lúc các hệ thống phân tích cách bộ não của người dùng hoạt động khi tương tác với UI.
Tốc độ điều hướng và ra quyết định. Người dùng tìm nút cần thiết nhanh đến mức nào? Họ có đọc văn bản trước khi tích vào ô kiểm không? Con người thường di chuyển con trỏ qua đoạn văn khi đọc, giống như lần theo các dòng trong một cuốn sách bằng ngón tay, hoặc dừng lại ở những biểu mẫu phức tạp. Một số người thậm chí còn tô sáng văn bản. Ngược lại, một script scraper không hề do dự — nó biết hoàn hảo cấu trúc DOM và kích hoạt sự kiện cần thiết đúng sau một khoảng timeout định sẵn, hoàn toàn bỏ qua logic tìm kiếm trực quan.
Kết hợp lại, ba tầng này tạo ra một hồ sơ phức tạp đến mức việc sao chép hoàn toàn nó chỉ bằng cách thêm các độ trễ ngẫu nhiên vào mã Selenium hoặc Puppeteer trở thành điều bất khả thi về mặt toán học.
Thu thập và tiền xử lý dữ liệu
Các nguồn chính để thu thập dữ liệu sinh trắc học là các sự kiện mousemove, keydown, keyup, touchstart và touchend, cũng như DeviceOrientation API để ghi lại số đo từ gia tốc kế và con quay hồi chuyển.
Phần khó nhất ở giai đoạn này là xử lý khối lượng khổng lồ của dữ liệu phân mảnh và không đồng bộ. Chỉ riêng một sự kiện mousemove có thể kích hoạt hàng trăm lần mỗi giây. Nếu mọi chuyển động con trỏ đều trực tiếp kích hoạt xử lý backend hoặc các phép tính nặng ngay trên phía client, hệ thống chống gian lận sẽ lập tức làm UI bị đơ và gây ra độ trễ rõ rệt trên website của khách hàng. Không doanh nghiệp nào chấp nhận điều đó.
Đó là lý do các script thu thập phía client được thiết kế càng nhẹ và càng đơn giản càng tốt. Nhiệm vụ duy nhất của chúng là nhanh chóng ghi lại tọa độ, gắn các dấu thời gian chính xác, lưu mọi thứ vào một bộ đệm cục bộ và gửi dữ liệu lên máy chủ theo lô.
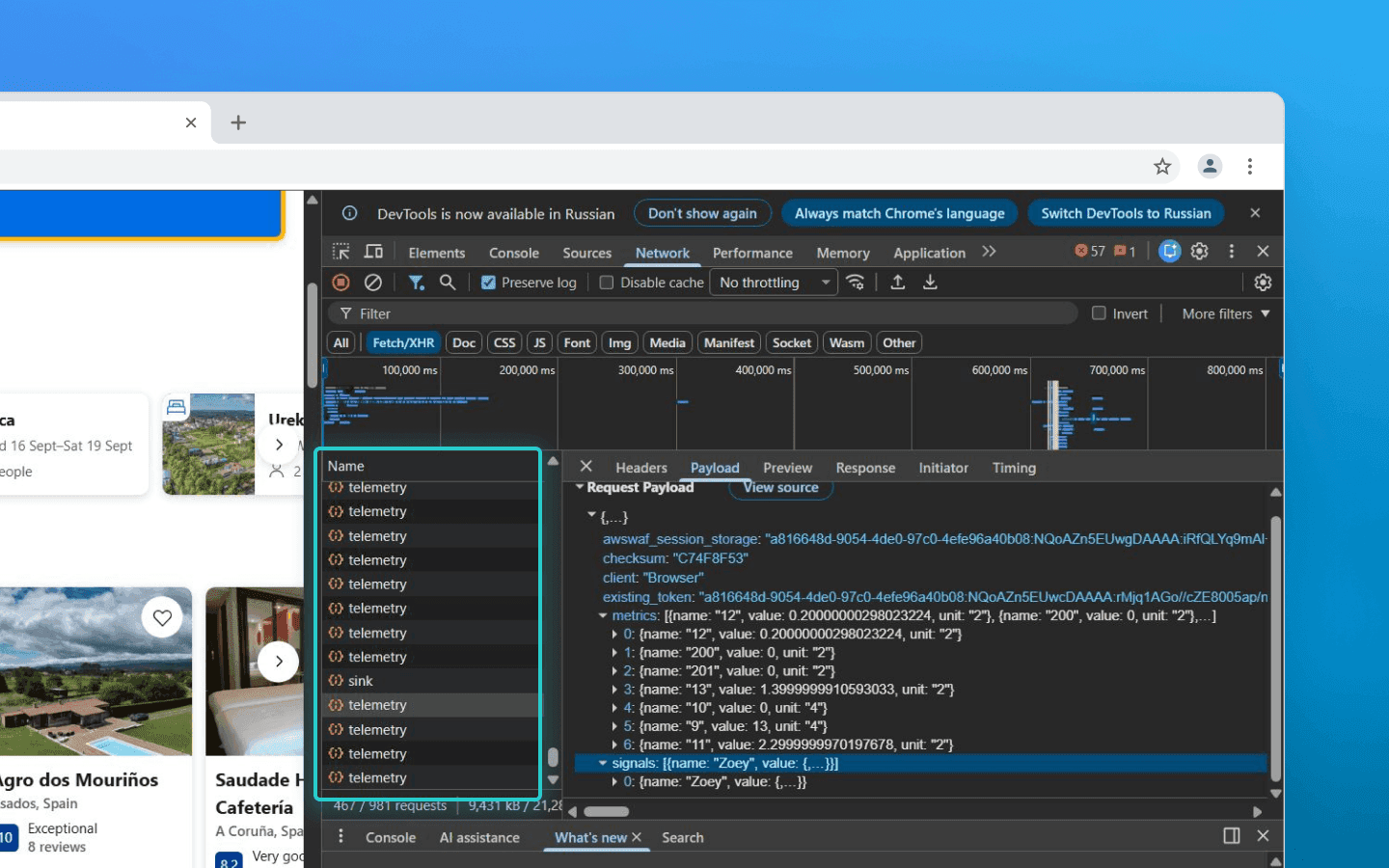
Những lô đối tượng JSON này sau đó được truyền đến backend. Trong các hệ thống tải cao, chúng không được ghi trực tiếp vào cơ sở dữ liệu hoặc chuyển ngay vào các mô hình ML. Trước tiên, chúng được định tuyến qua các message broker như Kafka hoặc RabbitMQ. Điều này là cần thiết để làm mượt các đợt tăng đột biến lưu lượng, ví dụ, trong các cuộc tấn công bot quy mô lớn hoặc các đợt tăng tự nhiên của người dùng thật trong thời gian khuyến mãi hoặc giảm giá. Ở điểm này, trách nhiệm phía client kết thúc.
Kỹ thuật đặc trưng và mô hình ML
Vậy là các lô dữ liệu thô đã đến máy chủ. Điều gì xảy ra tiếp theo?
Nếu bạn chỉ đơn giản đưa mảng pixel này vào một mô hình ML, nó sẽ không học được cách phân biệt người với bot. Nó chỉ ghi nhớ vị trí các nút trên website của bạn và sẽ hỏng ngay khi bố cục thay đổi dù chỉ một chút. Các mô hình học máy không cần địa lý màn hình, chúng cần các trừu tượng hành vi.
Đó là lý do có một lớp microservice chuyên biệt gọi là kỹ thuật đặc trưng nằm giữa hàng đợi thông điệp và các mạng nơ-ron. Đây thường là các pipeline xây dựng trên Pandas và NumPy để tổng hợp log và biến chúng thành dữ liệu phù hợp cho các mô hình ML. Chúng tính toán:
Khoảng cách Euclid giữa các điểm;
độ chênh thời gian;
vận tốc tức thời;
các góc ngoặt của quỹ đạo.
Dựa trên các phép tính này, hệ thống chống gian lận xây dựng một hồ sơ đặc trưng hành vi phức tạp:
Bàn phím: các vector độ trễ (
dwell timevàflight time), cùng với trung vị, phương sai và độ lệch chuẩn của chúng. Nói cách khác, nhịp gõ phím nhất quán đến mức nào.Chuột: thống kê về tốc độ và gia tốc, số lượng các khoảng dừng vi mô, và entropy phổ của quỹ đạo. Chỉ số này cho thấy chuyển động có vẻ hỗn loạn (như con người) hay hoàn hảo về mặt toán học (như script).
Màn hình cảm ứng: các gradient của áp lực và các thay đổi diện tích tiếp xúc trong một cú vuốt (trong những trường hợp trình duyệt hoặc API của hệ điều hành chia sẻ dữ liệu như vậy).
Các đặc trưng nhận thức:
idle timevà các độ trễ trước khi tập trung vào các phần tử mục tiêu. Ví dụ, một khoảng dừng trước khi nhấp vào nút “Pay” trong lúc người dùng tự kiểm tra lại số tiền một cách thầm lặng.
Hàng trăm tham số như vậy được trích xuất từ một phiên duy nhất, loại bỏ ngữ cảnh phụ thuộc bố cục, rồi chuyển vào các mô hình ML.
Các thuật toán ML cổ điển (Random Forest, SVM, Gradient Boosting)
Chúng hoạt động cực kỳ tốt với các đặc trưng thống kê đã được tổng hợp. Chúng vận hành nhanh, tiêu tốn rất ít tài nguyên máy chủ, và thường được dùng như tuyến phòng thủ đầu tiên và nhanh nhất.
Về cơ bản, chúng đưa toàn bộ vector thống kê phiên (tốc độ hành động, độ lệch thời gian, entropy, v.v.) qua một hệ thống các ngưỡng toán học được hiệu chỉnh cẩn thận, ngay lập tức lọc ra các bất thường rõ ràng như phương sai bằng 0 trong gia tốc con trỏ hoặc các khoảng cách nhấp chuột nhất quán một cách phi tự nhiên.
Mạng nơ-ron (LSTM, GRU và 1D-CNN)
Trong khi các thuật toán cổ điển tập trung vào bức tranh thống kê tổng thể, các mạng nơ-ron hồi quy phân tích chính chuỗi chuyển động con trỏ theo thời gian.
Các mạng hồi quy được thiết kế để xử lý dữ liệu tuần tự (văn bản, giọng nói, chuỗi thời gian), nơi ngữ cảnh của các phần tử trước đó có ý nghĩa. Không giống như các mạng truyền thống, kiến trúc hồi quy có “trí nhớ” thông qua các vòng phản hồi, cho phép chúng tính đến thông tin từ các bước trước. Kết quả là, chúng có thể phát hiện những mẫu và nhịp điệu không tự nhiên bị che khuất bởi phép trung bình thống kê thông thường.
Autoencoder và phát hiện bất thường
Thách thức lớn nhất đối với các hệ thống chống gian lận là các nhà phát triển bot liên tục nghĩ ra những kỹ thuật giả mạo mới. Huấn luyện một mô hình trên mọi bot hiện có là không thể, nhưng lại có hàng triệu phiên do người thật tạo ra. Đó là lý do học không giám sát, đặc biệt là autoencoder, được sử dụng rộng rãi.
Autoencoder là một mạng nơ-ron chỉ được huấn luyện trên hành vi của con người. Nó hoạt động như một bộ lọc chuyên biệt: nhận các tham số phiên làm đầu vào, nén chúng về mặt toán học thành một biểu diễn gọn hơn, rồi cố gắng tái tạo lại dữ liệu gốc.
Vì mạng như vậy chỉ từng thấy các phiên người dùng thật, nó đã học được vật lý của chuyển động con người với độ chính xác gần như hoàn hảo và có thể tái tạo dữ liệu đó gần như không sai sót. Nhưng nếu hành vi của một bot chưa từng thấy trước đây — bất kể tinh vi đến đâu — được đưa vào mô hình, mạng sẽ cố áp dụng các quy tắc nén của con người lên nó. Kết quả là giai đoạn tái tạo sẽ tạo ra đầu ra không chính xác.
Khi có sự khác biệt lớn giữa dữ liệu gốc và những gì mạng tái tạo được, điều này trở thành lỗi tái tạo. Lỗi càng lớn, điểm rủi ro càng cao, báo hiệu hành vi bất thường.
Kiểm tra một phương pháp so với hệ thống lai
Việc chỉ dựa vào một loại xác minh là không hiệu quả, đó là lý do không ai dùng một mô hình duy nhất. Trong hầu hết các trường hợp, kiến trúc được xây dựng như một chuỗi: các thuật toán ML nhẹ có thể ngay lập tức loại bỏ tới 90% các script và bot đơn giản, trong khi các mạng nơ-ron nặng hơn chỉ được kích hoạt cho những trường hợp sát ngưỡng, nơi các kiểm tra trước đó cho kết quả không chắc chắn. Cách tiếp cận này giúp giảm đáng kể chi phí tính toán.
Độ trôi đặc trưng và thích ứng
Hành vi thật của con người có thể thay đổi theo thời gian, giống như vân tay số của thiết bị họ. Một người dùng có thể mua một con chuột mới với cài đặt DPI khác, chuyển từ máy tính để bàn sang laptop có touchpad, làm đau tay, uống một ly espresso đôi, hoặc đơn giản là kiệt sức vào cuối ngày làm việc. Tất cả những điều này ngay lập tức thay đổi nhịp gõ phím, khả năng kiểm soát vận động tinh và tốc độ phản ứng của họ.
Nếu một mô hình chống gian lận là tĩnh và dựa trên hồ sơ tham chiếu được thu thập từ nhiều năm trước, nó chắc chắn sẽ bắt đầu chặn nhầm người dùng hợp lệ. Tỷ lệ dương tính giả sẽ tăng, tỷ lệ chuyển đổi sẽ giảm, và doanh nghiệp sẽ mất cả doanh thu lẫn lòng trung thành của khách hàng.
Kết quả là, các hệ thống chống gian lận phải liên tục tiến hóa cùng với người dùng và thích ứng với các điều kiện thay đổi.
Huấn luyện mạng nơ-ron theo thời gian thực
Không giống như huấn luyện theo lô truyền thống, nơi một mô hình được huấn luyện lại mỗi tháng một lần trên một bộ dữ liệu tích lũy khổng lồ, học trực tuyến cho phép thuật toán điều chỉnh trọng số của nó liên tục theo thời gian thực. Ngay khi một phiên hợp lệ kết thúc — được xác nhận, chẳng hạn, bằng một giao dịch mua hoặc xác minh 2FA thành công — các đặc trưng của nó sẽ làm thay đổi nhẹ các ngưỡng quyết định của mô hình. Điều này tính đến hoàn hảo những thay đổi dần dần trong thói quen người dùng.
Cửa sổ bộ nhớ trượt
Các thuật toán cũng dựa trên nguyên lý cửa sổ bộ nhớ trượt: dữ liệu phiên mới được liên tục thêm vào hồ sơ hành vi tham chiếu và được gán trọng số toán học cao nhất. Các bản ghi cũ dần mất ảnh hưởng cho đến khi đóng góp của chúng tiến gần về 0. Hệ thống luôn so sánh hành vi hiện tại với cách người dùng đã hành xử trong những tuần gần đây, chứ không phải với thời điểm tài khoản được tạo ra cách đây nhiều năm.
Giám sát thống kê
Nhưng làm sao hệ thống phân biệt giữa một thay đổi hợp lệ, như mua một con chuột mới, với một hành vi giả mạo phiên đột ngột từ một bot tinh vi? Vì mục đích này, việc giám sát thống kê nghiêm ngặt được áp dụng, bao gồm:
Phân tích thành phần chính (PCA). Phương pháp này chiếu hàng chục đặc trưng vào không gian 2D hoặc 3D và theo dõi sự trôi của các cụm. Nếu các phiên mới đột ngột lệch khỏi lõi hành vi lịch sử của người dùng, hệ thống sẽ phát hiện sự trôi đó.
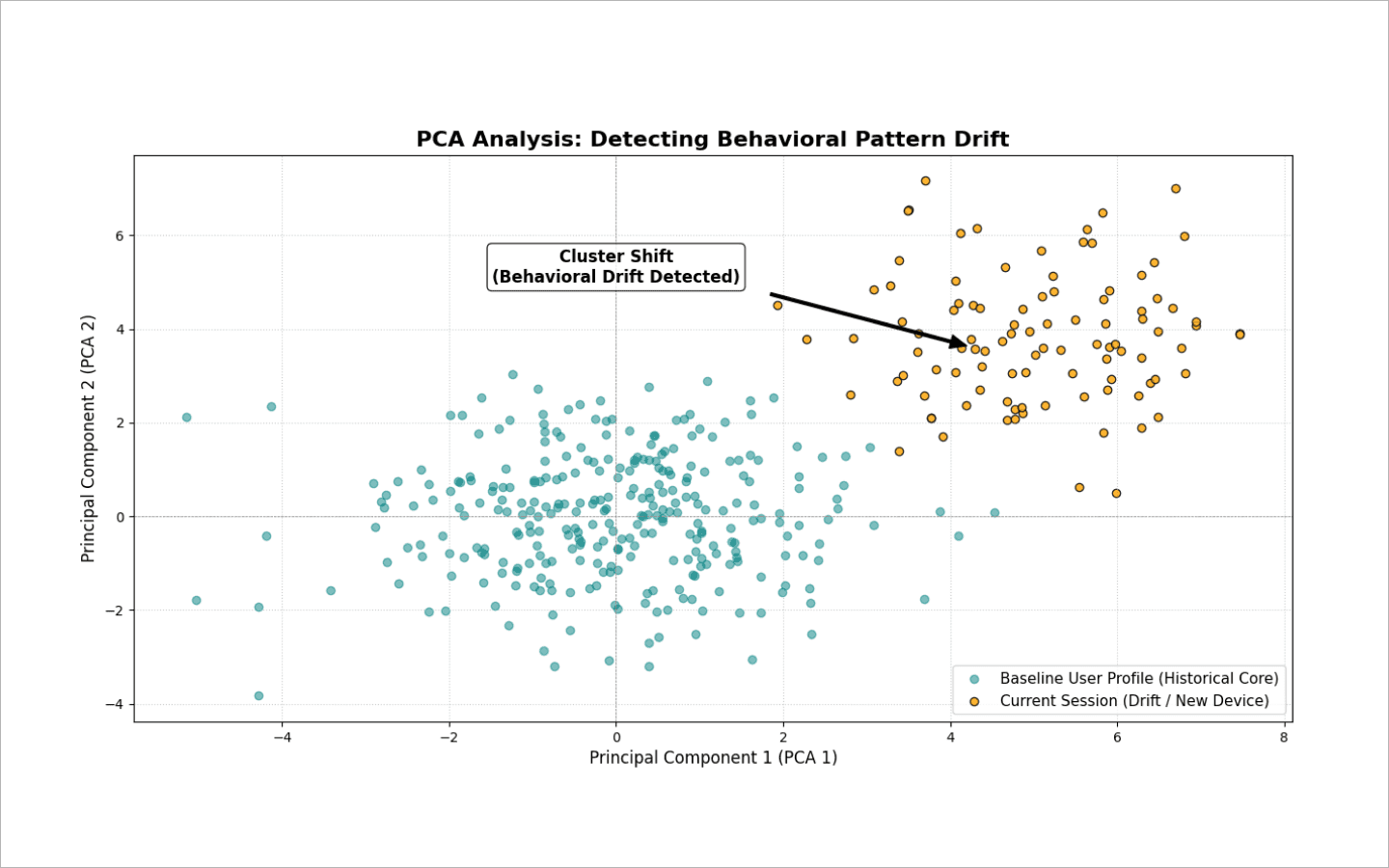
Các kiểm định thống kê (như kiểm định Kolmogorov–Smirnov). Thuật toán liên tục so sánh phân phối của dữ liệu mới với phân phối tham chiếu. Nếu phát hiện sự phân kỳ giữa hai mẫu, hệ thống sẽ tạm thời giảm niềm tin vào hồ sơ. Ở giai đoạn này, người dùng không bị cấm mà sẽ được yêu cầu hoàn thành CAPTCHA. Nếu xác minh thành công, mô hình sẽ diễn giải độ lệch là hợp lệ — ví dụ như chuyển sang một thiết bị mới — và cập nhật hồ sơ tham chiếu cho phù hợp.
Mô phỏng hành vi con người
Bây giờ khi đã hiểu cách các thuật toán chống gian lận hoạt động, hãy cùng tìm hiểu cách huấn luyện một bot để cư xử như con người.
Chỉ cần làm mượt chuyển động con trỏ bằng các đường cong Bézier hoặc thêm các lệnh time.sleep() là không còn đủ nữa: các mô hình ML có thể phát hiện tự động hóa chỉ sau vài cú nhấp. Để làm một trình giả lập thực sự giống con người, nó phải đưa các quy luật sinh lý và sinh cơ học vào.
Tiêm jitter
Nếu bạn yêu cầu một script tạo ra các khoảng dừng ngẫu nhiên kéo dài từ 80 đến 120 mili giây, nó sẽ tạo ra các độ trễ 80 ms, 120 ms và 95 ms với tần suất gần như như nhau.
Con người không gõ như vậy. Mỗi người chúng ta đều có một nhịp tự nhiên, thoải mái mà ta thường rơi vào. Thỉnh thoảng, các ngón tay của chúng ta tăng hoặc giảm tốc nhẹ. Đó là lý do các độ trễ nên được tạo theo phân phối Gaussian (đường cong hình chuông). Phần lớn áp đảo các khoảng dừng của bot nên tập trung quanh một tốc độ cơ sở duy nhất, trong khi chỉ một vài độ lệch thay đổi đáng kể theo cả hai hướng.
Mô phỏng rung tay
Hãy tưởng tượng bạn đang cố nhấp nhanh vào một ô kiểm rất nhỏ. Bạn di chuyển chuột đột ngột, vượt quá mục tiêu vài pixel, nhận ra lỗi và kéo con trỏ trở lại.
Để bắt chước hiệu ứng này và độ rung tự nhiên của bàn tay con người, các nhà phát triển trộn các hàm toán học (sóng sine và cosine) vào quỹ đạo con trỏ lý tưởng. Điều này tạo ra nhiễu vi mô thực tế có thể đánh lừa các hệ thống chống gian lận.
Khoảng dừng lớn
Một trong những kỹ thuật tiên tiến nhất và hiếm khi được triển khai là đưa vào các khoảng dừng lớn mô phỏng các chu kỳ sinh lý. Con người không làm việc liên tục trước máy tính. Chúng ta chớp mắt, tạm thời mất liên lạc thị giác với màn hình, hít vào thở ra, liếc xuống bàn phím, hoặc bị điện thoại làm phân tâm.
Vì vậy, một trình giả lập phải bao gồm logic “mất tập trung” — các độ trễ nhân tạo định kỳ từ 1–3 giây trước các hành động quan trọng, phá vỡ sự đơn điệu như máy móc.
Sao chép hành vi
Tại sao phải viết từ đầu những mô hình toán học phức tạp để tạo ra chuyển động cuộn hoàn hảo với sự giảm tốc tự nhiên và các cú giật vi mô, trong khi bạn có thể đơn giản dùng một chuyển động thật? Cách tiếp cận này được gọi là blending, và nó nâng mức mô phỏng lên một cấp độ hoàn toàn mới.
Các nhà phát triển bot tiên tiến xây dựng cơ sở dữ liệu riêng hoặc mua những bộ có sẵn. Các bộ dữ liệu này chứa các phiên thực từ người dùng thật: cách mọi người cuộn qua bảng tin, di chuyển con trỏ khi đọc văn bản, hoặc vô thức dịch chuyển chuột khi suy nghĩ. Những bản ghi này được lưu dưới dạng các mảng chứa vector chuyển động và dữ liệu vi thời gian.
Khi một script xây trên công nghệ này cần cuộn trang hoặc di chuyển con trỏ tới một biểu mẫu phức tạp, nó không dùng window.scrollBy() hay các đường cong Bézier. Thay vào đó, nó truy xuất từ cơ sở dữ liệu một đoạn thích hợp của nhật ký tương tác người thật. Quỹ đạo sau đó được biến dạng: script làm méo “ảnh chụp” này về mặt toán học để nó khớp với tọa độ hiện tại của trình duyệt. Các vector được dịch chuyển vừa đủ để con trỏ kết thúc ngay trên nút cần thiết, sau đó quyền điều khiển được trả lại liền mạch cho bot để thực hiện cú nhấp cuối cùng.
Các mô hình ML chống gian lận nhìn nhận những chuyển động này như nhiễu tần số cao hoàn hảo, rung tự nhiên hoàn chỉnh và các khoảng dừng vi mô chân thực. Kết quả là, chúng cho phép script hoạt động vì dữ liệu nền tảng thực sự xuất phát từ một con người đang hoạt động thật.
Điểm mấu chốt là gì? Để phương pháp này hoạt động ở quy mô lớn, nhà phát triển bot cần một thư viện “ảnh chụp” hành vi thực sự khổng lồ. Nếu cùng một đoạn cuộn được tái sử dụng trên nhiều bot, các hệ thống chống gian lận phía máy chủ sẽ nhanh chóng phát hiện bản sao toán học (kích hoạt cơ chế bảo vệ chống phát lại cơ bản) và cấm cả trang trại bot.
Điểm yếu của vòng lặp
Dù bạn có ngẫu nhiên hóa thời gian và làm con trỏ rung đến đâu, mỗi bot vẫn mang một điểm yếu bẩm sinh: nó sống bên trong một vòng lặp chương trình (while hoặc for).
Các hệ thống bảo vệ lấy thời gian của script bạn và chạy chúng qua phân tích phổ (biến đổi Fourier). Điều này lọc bỏ nhiễu ngẫu nhiên nhân tạo và làm lộ tần số mang ẩn của vòng lặp. Con người vốn không có nhịp đều; bot thì có.
Bạn có thể đánh bại phân tích Fourier và thuyết phục máy chủ rằng script của bạn là một con người sống, không có tần số cơ sở nào có thể phát hiện không? Có, nhưng để làm vậy đòi hỏi phải viết lại toàn bộ kiến trúc của trình thu thập dữ liệu. Một Math.random() đơn giản là hoàn toàn không đủ.
Loại bỏ vòng lặp để thay bằng Máy trạng thái. Đừng dùng các vòng lặp
whilehoặcfortuyến tính kết hợp với các lệnhsleep()lồng nhau. Bot của bạn nên hoạt động như một máy trạng thái hữu hạn do sự kiện điều khiển. Nó nên có nhiều trạng thái, ví dụ: đọc, do dự hoặc nhàn rỗi, di chuyển, nhấp. Việc chuyển đổi giữa các trạng thái này không nên được mã hóa cứng một cách cứng nhắc mà phải được xác định theo xác suất. Chỉ khi đó nhịp chung của phiên mới trở nên khó đoán, giống như một người có thể đột ngột đổi ý trước khi nhấp nút.Toán học của “đuôi dày”. Hãy quên tính ngẫu nhiên đều hoặc thậm chí phân phối Gaussian đi. Phần lớn các khoảng dừng của bạn nên ngắn và tập trung chặt, nhưng bot thỉnh thoảng nên dừng lại một thời gian bất thường dài với một xác suất nhất định. Chính những ngoại lệ hiếm nhưng cực đoan này làm rối phân tích tần số Fourier, làm loãng phổ và che đi nhịp máy móc.
Sử dụng entropy từ hệ điều hành. Các bộ sinh số giả ngẫu nhiên có sẵn trong JavaScript hoặc Python có những mẫu có thể dự đoán được của riêng chúng. Thay vào đó, bạn có thể lấy entropy thật trực tiếp từ hệ điều hành, nơi thu thập nhiễu phần cứng hỗn loạn, từ dao động nhiệt độ CPU đến các ngắt mạng.
Kết luận: kinh tế học của việc scraping và trò chơi bất tận
Sinh trắc học hành vi chưa trở thành một viên đạn bạc chống lại bot. Tuy nhiên, nó đã thay đổi căn bản cả luật chơi lẫn kinh tế của tự động hóa.
Trước đây, để xây dựng một scraper thành công chỉ cần mua một lô proxy và hiểu các header của trình duyệt. Ngày nay, các nhà phát triển tự động hóa cần chuyên môn mở rộng sang sinh cơ học và biến đổi Fourier. Tất nhiên, điều này áp dụng cho các dự án quy mô lớn, chứ không chỉ đơn giản là scrape ảnh từ Google Maps.
Cuộc chạy đua vũ trang giữa các hệ thống chống gian lận và các nhà phát triển bot vẫn tiếp diễn, nhưng giờ là trên một chiến trường mới: mô phỏng hệ thần kinh con người. Các giải pháp chống gian lận sẽ tiếp tục đưa ra những phương pháp xác minh ngày càng tinh vi, trong khi các scraper sẽ học cách “thở” và trì hoãn một cách thuyết phục hơn nữa.
Giữ kín danh tính, tận dụng tính năng nhiều tài khoản và đạt được mục tiêu của bạn với trình duyệt chống phát hiện chất lượng cao nhất trên thị trường.
Bạn có muốn thử Octo Browser với giá giảm không?
Sử dụng mã khuyến mãi OCTOSCRAPER để được giảm giá 30% cho bất kỳ gói đăng ký nào. Ưu đãi này chỉ dành cho người dùng mới.
Tại sao CAPTCHA đang nhường chỗ cho phân tích hành vi
Trước đây, CAPTCHA là cơ chế phòng thủ chính chống lại bot. CAPTCHA vẫn tồn tại ngày nay, dù đã thay đổi đáng kể. Chúng đã trở nên tinh vi hơn, và một số phiên bản vô hình hiện đại (như reCAPTCHA v3) đã tích hợp chính những sinh trắc học hành vi mà chúng ta đang bàn đến.
Tại sao điều này cần thiết? CAPTCHA truyền thống (đèn giao thông và các ký tự méo mó) làm xấu đi trải nghiệm người dùng và ngày càng bị các mạng nơ-ron đã huấn luyện giải quyết dễ dàng. Cách tiếp cận mới, hoạt động mà không cần các phần tử hiển thị, giúp giảm gánh nặng cho người dùng và tránh làm họ khó chịu.
Sinh trắc học hành vi, với vai trò là lõi của quy trình xác minh vô hình này, cung cấp xác thực liên tục. Nó hoạt động bằng cách phân tích chính xác cách một người dùng tương tác với thiết bị khi cuộn trang hoặc điền biểu mẫu, mà không cần bất kỳ đầu vào bổ sung nào.
Tuy nhiên, cần làm rõ một điểm quan trọng: sinh trắc học hành vi không được dùng như một phương pháp xác minh độc lập. Nó luôn hoạt động cùng với các kiểm tra khác. Ngoài sinh trắc học, các hệ thống chống gian lận vẫn phân tích vân tay số, uy tín IP và cookie.
Các loại sinh trắc học hành vi
Hãy đi sâu hơn vào lý thuyết. Các mẫu hành vi về cơ bản là một vân tay số của hệ thần kinh của bạn được chuyển lên thiết bị. Các hệ thống chống gian lận tiên tiến không phân tích các tham số riêng rẽ. Thay vào đó, họ xây dựng một hồ sơ đa chiều toàn diện có thể được chia thành các nhóm sau:
Tương tác thiết bị (kinesthetics)
Đây là lớp dữ liệu lớn nhất đối với các ứng dụng web và di động truyền thống. Ở đây, các hệ thống phân tích vật lý của chuyển động người dùng.
Bàn phím: không phải là bạn gõ những chữ cái hay con số nào. Các hệ thống chống gian lận đánh giá hai tham số chính: một phím được giữ xuống bao lâu (
dwell time) và mất bao lâu để di chuyển giữa các phím (flight time). Con người có trí nhớ cơ bắp — các tổ hợp phím quen thuộc (ví dụ, những đuôi từ phổ biến) được gõ thành các đợt vi mô. Trong khi đó, bot hoặc chèn toàn bộ chuỗi cùng lúc, hoặc giả lập việc gõ bằng logictime.sleep(random)đơn giản. Điều này tạo ra một phân bố độ trễ phẳng, không tự nhiên. Bản thân tính ngẫu nhiên cũng trở nên đáng ngờ.Chuột: phân tích con trỏ. Hệ thống ghi lại tọa độ và tính tốc độ, gia tốc, độ cong của quỹ đạo và các cú giật. Con người không di chuyển chuột theo những đường thẳng hoàn hảo. Chúng ta nhắm vào một nút, lệch vài pixel, thực hiện những chỉnh sửa nhỏ, rồi tạm dừng ngắn trước khi nhấp.
Màn hình cảm ứng: dành riêng cho web di động và các ứng dụng gốc. Một cú vuốt của con người là một cung với tốc độ không đều, áp lực cụ thể (nếu API cho phép phát hiện áp lực), và diện tích tiếp xúc của ngón tay thay đổi. Các bot giả lập sự kiện chạm qua Appium hoặc các script JavaScript thường chỉ đơn giản “dịch chuyển tức thời” tọa độ focus. Viết đúng toán học cho một cú vuốt thực tế khó hơn nhiều, nên những người vận hành bot thường làm qua loa.
Các mẫu vật lý (sinh cơ học)
Khi một người dùng truy cập nền tảng từ thiết bị di động, các cảm biến phần cứng sẽ tham gia. Và vì chúng ta hiện đang sống trong thời đại người dùng di động, điều này rất quan trọng.
Mẫu bước đi và vi chuyển động. Bạn đang cuộn bảng tin khi đang đi bộ, ngồi trên ghế hay nằm trên ghế sofa? Gia tốc kế và con quay hồi chuyển của điện thoại thông minh liên tục ghi lại những rung động rất nhỏ của thiết bị. Điện thoại của một người dùng thực luôn hơi rung trong tay họ, ngay cả khi họ cố giữ nó thật yên. Các trang trại bot và trình giả lập chạy trên máy chủ thường mặc định hoàn toàn không có nhiễu nền từ cảm biến, cho các hệ thống chống gian lận một điều để nghĩ tới và làm tăng điểm rủi ro.
Các mẫu nhận thức (tâm lý tương tác)
Đây là lúc các hệ thống phân tích cách bộ não của người dùng hoạt động khi tương tác với UI.
Tốc độ điều hướng và ra quyết định. Người dùng tìm nút cần thiết nhanh đến mức nào? Họ có đọc văn bản trước khi tích vào ô kiểm không? Con người thường di chuyển con trỏ qua đoạn văn khi đọc, giống như lần theo các dòng trong một cuốn sách bằng ngón tay, hoặc dừng lại ở những biểu mẫu phức tạp. Một số người thậm chí còn tô sáng văn bản. Ngược lại, một script scraper không hề do dự — nó biết hoàn hảo cấu trúc DOM và kích hoạt sự kiện cần thiết đúng sau một khoảng timeout định sẵn, hoàn toàn bỏ qua logic tìm kiếm trực quan.
Kết hợp lại, ba tầng này tạo ra một hồ sơ phức tạp đến mức việc sao chép hoàn toàn nó chỉ bằng cách thêm các độ trễ ngẫu nhiên vào mã Selenium hoặc Puppeteer trở thành điều bất khả thi về mặt toán học.
Thu thập và tiền xử lý dữ liệu
Các nguồn chính để thu thập dữ liệu sinh trắc học là các sự kiện mousemove, keydown, keyup, touchstart và touchend, cũng như DeviceOrientation API để ghi lại số đo từ gia tốc kế và con quay hồi chuyển.
Phần khó nhất ở giai đoạn này là xử lý khối lượng khổng lồ của dữ liệu phân mảnh và không đồng bộ. Chỉ riêng một sự kiện mousemove có thể kích hoạt hàng trăm lần mỗi giây. Nếu mọi chuyển động con trỏ đều trực tiếp kích hoạt xử lý backend hoặc các phép tính nặng ngay trên phía client, hệ thống chống gian lận sẽ lập tức làm UI bị đơ và gây ra độ trễ rõ rệt trên website của khách hàng. Không doanh nghiệp nào chấp nhận điều đó.
Đó là lý do các script thu thập phía client được thiết kế càng nhẹ và càng đơn giản càng tốt. Nhiệm vụ duy nhất của chúng là nhanh chóng ghi lại tọa độ, gắn các dấu thời gian chính xác, lưu mọi thứ vào một bộ đệm cục bộ và gửi dữ liệu lên máy chủ theo lô.
Những lô đối tượng JSON này sau đó được truyền đến backend. Trong các hệ thống tải cao, chúng không được ghi trực tiếp vào cơ sở dữ liệu hoặc chuyển ngay vào các mô hình ML. Trước tiên, chúng được định tuyến qua các message broker như Kafka hoặc RabbitMQ. Điều này là cần thiết để làm mượt các đợt tăng đột biến lưu lượng, ví dụ, trong các cuộc tấn công bot quy mô lớn hoặc các đợt tăng tự nhiên của người dùng thật trong thời gian khuyến mãi hoặc giảm giá. Ở điểm này, trách nhiệm phía client kết thúc.
Kỹ thuật đặc trưng và mô hình ML
Vậy là các lô dữ liệu thô đã đến máy chủ. Điều gì xảy ra tiếp theo?
Nếu bạn chỉ đơn giản đưa mảng pixel này vào một mô hình ML, nó sẽ không học được cách phân biệt người với bot. Nó chỉ ghi nhớ vị trí các nút trên website của bạn và sẽ hỏng ngay khi bố cục thay đổi dù chỉ một chút. Các mô hình học máy không cần địa lý màn hình, chúng cần các trừu tượng hành vi.
Đó là lý do có một lớp microservice chuyên biệt gọi là kỹ thuật đặc trưng nằm giữa hàng đợi thông điệp và các mạng nơ-ron. Đây thường là các pipeline xây dựng trên Pandas và NumPy để tổng hợp log và biến chúng thành dữ liệu phù hợp cho các mô hình ML. Chúng tính toán:
Khoảng cách Euclid giữa các điểm;
độ chênh thời gian;
vận tốc tức thời;
các góc ngoặt của quỹ đạo.
Dựa trên các phép tính này, hệ thống chống gian lận xây dựng một hồ sơ đặc trưng hành vi phức tạp:
Bàn phím: các vector độ trễ (
dwell timevàflight time), cùng với trung vị, phương sai và độ lệch chuẩn của chúng. Nói cách khác, nhịp gõ phím nhất quán đến mức nào.Chuột: thống kê về tốc độ và gia tốc, số lượng các khoảng dừng vi mô, và entropy phổ của quỹ đạo. Chỉ số này cho thấy chuyển động có vẻ hỗn loạn (như con người) hay hoàn hảo về mặt toán học (như script).
Màn hình cảm ứng: các gradient của áp lực và các thay đổi diện tích tiếp xúc trong một cú vuốt (trong những trường hợp trình duyệt hoặc API của hệ điều hành chia sẻ dữ liệu như vậy).
Các đặc trưng nhận thức:
idle timevà các độ trễ trước khi tập trung vào các phần tử mục tiêu. Ví dụ, một khoảng dừng trước khi nhấp vào nút “Pay” trong lúc người dùng tự kiểm tra lại số tiền một cách thầm lặng.
Hàng trăm tham số như vậy được trích xuất từ một phiên duy nhất, loại bỏ ngữ cảnh phụ thuộc bố cục, rồi chuyển vào các mô hình ML.
Các thuật toán ML cổ điển (Random Forest, SVM, Gradient Boosting)
Chúng hoạt động cực kỳ tốt với các đặc trưng thống kê đã được tổng hợp. Chúng vận hành nhanh, tiêu tốn rất ít tài nguyên máy chủ, và thường được dùng như tuyến phòng thủ đầu tiên và nhanh nhất.
Về cơ bản, chúng đưa toàn bộ vector thống kê phiên (tốc độ hành động, độ lệch thời gian, entropy, v.v.) qua một hệ thống các ngưỡng toán học được hiệu chỉnh cẩn thận, ngay lập tức lọc ra các bất thường rõ ràng như phương sai bằng 0 trong gia tốc con trỏ hoặc các khoảng cách nhấp chuột nhất quán một cách phi tự nhiên.
Mạng nơ-ron (LSTM, GRU và 1D-CNN)
Trong khi các thuật toán cổ điển tập trung vào bức tranh thống kê tổng thể, các mạng nơ-ron hồi quy phân tích chính chuỗi chuyển động con trỏ theo thời gian.
Các mạng hồi quy được thiết kế để xử lý dữ liệu tuần tự (văn bản, giọng nói, chuỗi thời gian), nơi ngữ cảnh của các phần tử trước đó có ý nghĩa. Không giống như các mạng truyền thống, kiến trúc hồi quy có “trí nhớ” thông qua các vòng phản hồi, cho phép chúng tính đến thông tin từ các bước trước. Kết quả là, chúng có thể phát hiện những mẫu và nhịp điệu không tự nhiên bị che khuất bởi phép trung bình thống kê thông thường.
Autoencoder và phát hiện bất thường
Thách thức lớn nhất đối với các hệ thống chống gian lận là các nhà phát triển bot liên tục nghĩ ra những kỹ thuật giả mạo mới. Huấn luyện một mô hình trên mọi bot hiện có là không thể, nhưng lại có hàng triệu phiên do người thật tạo ra. Đó là lý do học không giám sát, đặc biệt là autoencoder, được sử dụng rộng rãi.
Autoencoder là một mạng nơ-ron chỉ được huấn luyện trên hành vi của con người. Nó hoạt động như một bộ lọc chuyên biệt: nhận các tham số phiên làm đầu vào, nén chúng về mặt toán học thành một biểu diễn gọn hơn, rồi cố gắng tái tạo lại dữ liệu gốc.
Vì mạng như vậy chỉ từng thấy các phiên người dùng thật, nó đã học được vật lý của chuyển động con người với độ chính xác gần như hoàn hảo và có thể tái tạo dữ liệu đó gần như không sai sót. Nhưng nếu hành vi của một bot chưa từng thấy trước đây — bất kể tinh vi đến đâu — được đưa vào mô hình, mạng sẽ cố áp dụng các quy tắc nén của con người lên nó. Kết quả là giai đoạn tái tạo sẽ tạo ra đầu ra không chính xác.
Khi có sự khác biệt lớn giữa dữ liệu gốc và những gì mạng tái tạo được, điều này trở thành lỗi tái tạo. Lỗi càng lớn, điểm rủi ro càng cao, báo hiệu hành vi bất thường.
Kiểm tra một phương pháp so với hệ thống lai
Việc chỉ dựa vào một loại xác minh là không hiệu quả, đó là lý do không ai dùng một mô hình duy nhất. Trong hầu hết các trường hợp, kiến trúc được xây dựng như một chuỗi: các thuật toán ML nhẹ có thể ngay lập tức loại bỏ tới 90% các script và bot đơn giản, trong khi các mạng nơ-ron nặng hơn chỉ được kích hoạt cho những trường hợp sát ngưỡng, nơi các kiểm tra trước đó cho kết quả không chắc chắn. Cách tiếp cận này giúp giảm đáng kể chi phí tính toán.
Độ trôi đặc trưng và thích ứng
Hành vi thật của con người có thể thay đổi theo thời gian, giống như vân tay số của thiết bị họ. Một người dùng có thể mua một con chuột mới với cài đặt DPI khác, chuyển từ máy tính để bàn sang laptop có touchpad, làm đau tay, uống một ly espresso đôi, hoặc đơn giản là kiệt sức vào cuối ngày làm việc. Tất cả những điều này ngay lập tức thay đổi nhịp gõ phím, khả năng kiểm soát vận động tinh và tốc độ phản ứng của họ.
Nếu một mô hình chống gian lận là tĩnh và dựa trên hồ sơ tham chiếu được thu thập từ nhiều năm trước, nó chắc chắn sẽ bắt đầu chặn nhầm người dùng hợp lệ. Tỷ lệ dương tính giả sẽ tăng, tỷ lệ chuyển đổi sẽ giảm, và doanh nghiệp sẽ mất cả doanh thu lẫn lòng trung thành của khách hàng.
Kết quả là, các hệ thống chống gian lận phải liên tục tiến hóa cùng với người dùng và thích ứng với các điều kiện thay đổi.
Huấn luyện mạng nơ-ron theo thời gian thực
Không giống như huấn luyện theo lô truyền thống, nơi một mô hình được huấn luyện lại mỗi tháng một lần trên một bộ dữ liệu tích lũy khổng lồ, học trực tuyến cho phép thuật toán điều chỉnh trọng số của nó liên tục theo thời gian thực. Ngay khi một phiên hợp lệ kết thúc — được xác nhận, chẳng hạn, bằng một giao dịch mua hoặc xác minh 2FA thành công — các đặc trưng của nó sẽ làm thay đổi nhẹ các ngưỡng quyết định của mô hình. Điều này tính đến hoàn hảo những thay đổi dần dần trong thói quen người dùng.
Cửa sổ bộ nhớ trượt
Các thuật toán cũng dựa trên nguyên lý cửa sổ bộ nhớ trượt: dữ liệu phiên mới được liên tục thêm vào hồ sơ hành vi tham chiếu và được gán trọng số toán học cao nhất. Các bản ghi cũ dần mất ảnh hưởng cho đến khi đóng góp của chúng tiến gần về 0. Hệ thống luôn so sánh hành vi hiện tại với cách người dùng đã hành xử trong những tuần gần đây, chứ không phải với thời điểm tài khoản được tạo ra cách đây nhiều năm.
Giám sát thống kê
Nhưng làm sao hệ thống phân biệt giữa một thay đổi hợp lệ, như mua một con chuột mới, với một hành vi giả mạo phiên đột ngột từ một bot tinh vi? Vì mục đích này, việc giám sát thống kê nghiêm ngặt được áp dụng, bao gồm:
Phân tích thành phần chính (PCA). Phương pháp này chiếu hàng chục đặc trưng vào không gian 2D hoặc 3D và theo dõi sự trôi của các cụm. Nếu các phiên mới đột ngột lệch khỏi lõi hành vi lịch sử của người dùng, hệ thống sẽ phát hiện sự trôi đó.
Các kiểm định thống kê (như kiểm định Kolmogorov–Smirnov). Thuật toán liên tục so sánh phân phối của dữ liệu mới với phân phối tham chiếu. Nếu phát hiện sự phân kỳ giữa hai mẫu, hệ thống sẽ tạm thời giảm niềm tin vào hồ sơ. Ở giai đoạn này, người dùng không bị cấm mà sẽ được yêu cầu hoàn thành CAPTCHA. Nếu xác minh thành công, mô hình sẽ diễn giải độ lệch là hợp lệ — ví dụ như chuyển sang một thiết bị mới — và cập nhật hồ sơ tham chiếu cho phù hợp.
Mô phỏng hành vi con người
Bây giờ khi đã hiểu cách các thuật toán chống gian lận hoạt động, hãy cùng tìm hiểu cách huấn luyện một bot để cư xử như con người.
Chỉ cần làm mượt chuyển động con trỏ bằng các đường cong Bézier hoặc thêm các lệnh time.sleep() là không còn đủ nữa: các mô hình ML có thể phát hiện tự động hóa chỉ sau vài cú nhấp. Để làm một trình giả lập thực sự giống con người, nó phải đưa các quy luật sinh lý và sinh cơ học vào.
Tiêm jitter
Nếu bạn yêu cầu một script tạo ra các khoảng dừng ngẫu nhiên kéo dài từ 80 đến 120 mili giây, nó sẽ tạo ra các độ trễ 80 ms, 120 ms và 95 ms với tần suất gần như như nhau.
Con người không gõ như vậy. Mỗi người chúng ta đều có một nhịp tự nhiên, thoải mái mà ta thường rơi vào. Thỉnh thoảng, các ngón tay của chúng ta tăng hoặc giảm tốc nhẹ. Đó là lý do các độ trễ nên được tạo theo phân phối Gaussian (đường cong hình chuông). Phần lớn áp đảo các khoảng dừng của bot nên tập trung quanh một tốc độ cơ sở duy nhất, trong khi chỉ một vài độ lệch thay đổi đáng kể theo cả hai hướng.
Mô phỏng rung tay
Hãy tưởng tượng bạn đang cố nhấp nhanh vào một ô kiểm rất nhỏ. Bạn di chuyển chuột đột ngột, vượt quá mục tiêu vài pixel, nhận ra lỗi và kéo con trỏ trở lại.
Để bắt chước hiệu ứng này và độ rung tự nhiên của bàn tay con người, các nhà phát triển trộn các hàm toán học (sóng sine và cosine) vào quỹ đạo con trỏ lý tưởng. Điều này tạo ra nhiễu vi mô thực tế có thể đánh lừa các hệ thống chống gian lận.
Khoảng dừng lớn
Một trong những kỹ thuật tiên tiến nhất và hiếm khi được triển khai là đưa vào các khoảng dừng lớn mô phỏng các chu kỳ sinh lý. Con người không làm việc liên tục trước máy tính. Chúng ta chớp mắt, tạm thời mất liên lạc thị giác với màn hình, hít vào thở ra, liếc xuống bàn phím, hoặc bị điện thoại làm phân tâm.
Vì vậy, một trình giả lập phải bao gồm logic “mất tập trung” — các độ trễ nhân tạo định kỳ từ 1–3 giây trước các hành động quan trọng, phá vỡ sự đơn điệu như máy móc.
Sao chép hành vi
Tại sao phải viết từ đầu những mô hình toán học phức tạp để tạo ra chuyển động cuộn hoàn hảo với sự giảm tốc tự nhiên và các cú giật vi mô, trong khi bạn có thể đơn giản dùng một chuyển động thật? Cách tiếp cận này được gọi là blending, và nó nâng mức mô phỏng lên một cấp độ hoàn toàn mới.
Các nhà phát triển bot tiên tiến xây dựng cơ sở dữ liệu riêng hoặc mua những bộ có sẵn. Các bộ dữ liệu này chứa các phiên thực từ người dùng thật: cách mọi người cuộn qua bảng tin, di chuyển con trỏ khi đọc văn bản, hoặc vô thức dịch chuyển chuột khi suy nghĩ. Những bản ghi này được lưu dưới dạng các mảng chứa vector chuyển động và dữ liệu vi thời gian.
Khi một script xây trên công nghệ này cần cuộn trang hoặc di chuyển con trỏ tới một biểu mẫu phức tạp, nó không dùng window.scrollBy() hay các đường cong Bézier. Thay vào đó, nó truy xuất từ cơ sở dữ liệu một đoạn thích hợp của nhật ký tương tác người thật. Quỹ đạo sau đó được biến dạng: script làm méo “ảnh chụp” này về mặt toán học để nó khớp với tọa độ hiện tại của trình duyệt. Các vector được dịch chuyển vừa đủ để con trỏ kết thúc ngay trên nút cần thiết, sau đó quyền điều khiển được trả lại liền mạch cho bot để thực hiện cú nhấp cuối cùng.
Các mô hình ML chống gian lận nhìn nhận những chuyển động này như nhiễu tần số cao hoàn hảo, rung tự nhiên hoàn chỉnh và các khoảng dừng vi mô chân thực. Kết quả là, chúng cho phép script hoạt động vì dữ liệu nền tảng thực sự xuất phát từ một con người đang hoạt động thật.
Điểm mấu chốt là gì? Để phương pháp này hoạt động ở quy mô lớn, nhà phát triển bot cần một thư viện “ảnh chụp” hành vi thực sự khổng lồ. Nếu cùng một đoạn cuộn được tái sử dụng trên nhiều bot, các hệ thống chống gian lận phía máy chủ sẽ nhanh chóng phát hiện bản sao toán học (kích hoạt cơ chế bảo vệ chống phát lại cơ bản) và cấm cả trang trại bot.
Điểm yếu của vòng lặp
Dù bạn có ngẫu nhiên hóa thời gian và làm con trỏ rung đến đâu, mỗi bot vẫn mang một điểm yếu bẩm sinh: nó sống bên trong một vòng lặp chương trình (while hoặc for).
Các hệ thống bảo vệ lấy thời gian của script bạn và chạy chúng qua phân tích phổ (biến đổi Fourier). Điều này lọc bỏ nhiễu ngẫu nhiên nhân tạo và làm lộ tần số mang ẩn của vòng lặp. Con người vốn không có nhịp đều; bot thì có.
Bạn có thể đánh bại phân tích Fourier và thuyết phục máy chủ rằng script của bạn là một con người sống, không có tần số cơ sở nào có thể phát hiện không? Có, nhưng để làm vậy đòi hỏi phải viết lại toàn bộ kiến trúc của trình thu thập dữ liệu. Một Math.random() đơn giản là hoàn toàn không đủ.
Loại bỏ vòng lặp để thay bằng Máy trạng thái. Đừng dùng các vòng lặp
whilehoặcfortuyến tính kết hợp với các lệnhsleep()lồng nhau. Bot của bạn nên hoạt động như một máy trạng thái hữu hạn do sự kiện điều khiển. Nó nên có nhiều trạng thái, ví dụ: đọc, do dự hoặc nhàn rỗi, di chuyển, nhấp. Việc chuyển đổi giữa các trạng thái này không nên được mã hóa cứng một cách cứng nhắc mà phải được xác định theo xác suất. Chỉ khi đó nhịp chung của phiên mới trở nên khó đoán, giống như một người có thể đột ngột đổi ý trước khi nhấp nút.Toán học của “đuôi dày”. Hãy quên tính ngẫu nhiên đều hoặc thậm chí phân phối Gaussian đi. Phần lớn các khoảng dừng của bạn nên ngắn và tập trung chặt, nhưng bot thỉnh thoảng nên dừng lại một thời gian bất thường dài với một xác suất nhất định. Chính những ngoại lệ hiếm nhưng cực đoan này làm rối phân tích tần số Fourier, làm loãng phổ và che đi nhịp máy móc.
Sử dụng entropy từ hệ điều hành. Các bộ sinh số giả ngẫu nhiên có sẵn trong JavaScript hoặc Python có những mẫu có thể dự đoán được của riêng chúng. Thay vào đó, bạn có thể lấy entropy thật trực tiếp từ hệ điều hành, nơi thu thập nhiễu phần cứng hỗn loạn, từ dao động nhiệt độ CPU đến các ngắt mạng.
Kết luận: kinh tế học của việc scraping và trò chơi bất tận
Sinh trắc học hành vi chưa trở thành một viên đạn bạc chống lại bot. Tuy nhiên, nó đã thay đổi căn bản cả luật chơi lẫn kinh tế của tự động hóa.
Trước đây, để xây dựng một scraper thành công chỉ cần mua một lô proxy và hiểu các header của trình duyệt. Ngày nay, các nhà phát triển tự động hóa cần chuyên môn mở rộng sang sinh cơ học và biến đổi Fourier. Tất nhiên, điều này áp dụng cho các dự án quy mô lớn, chứ không chỉ đơn giản là scrape ảnh từ Google Maps.
Cuộc chạy đua vũ trang giữa các hệ thống chống gian lận và các nhà phát triển bot vẫn tiếp diễn, nhưng giờ là trên một chiến trường mới: mô phỏng hệ thần kinh con người. Các giải pháp chống gian lận sẽ tiếp tục đưa ra những phương pháp xác minh ngày càng tinh vi, trong khi các scraper sẽ học cách “thở” và trì hoãn một cách thuyết phục hơn nữa.
Cập nhật với các tin tức Octo Browser mới nhất
Khi nhấp vào nút này, bạn sẽ đồng ý với Chính sách Quyền riêng tư của chúng tôi.
Cập nhật với các tin tức Octo Browser mới nhất
Khi nhấp vào nút này, bạn sẽ đồng ý với Chính sách Quyền riêng tư của chúng tôi.
Cập nhật với các tin tức Octo Browser mới nhất
Khi nhấp vào nút này, bạn sẽ đồng ý với Chính sách Quyền riêng tư của chúng tôi.

Tham gia Octo Browser ngay
Hoặc liên hệ với Dịch vụ khách hàng bất kì lúc nào nếu bạn có bất cứ thắc mắc nào.
Tham gia Octo Browser ngay
Hoặc liên hệ với Dịch vụ khách hàng bất kì lúc nào nếu bạn có bất cứ thắc mắc nào.
Tham gia Octo Browser ngay
Hoặc liên hệ với Dịch vụ khách hàng bất kì lúc nào nếu bạn có bất cứ thắc mắc nào.