Cách vượt qua giới hạn của ChatGPT
25/3/26


Nikolai Izoitko
Content Manager, Octo Browser
ChatGPT đã trở thành một giải pháp phổ biến cho công việc, học tập và sáng tạo. Tuy nhiên, nhiều người dùng thường xuyên gặp phải các hạn chế: dịch vụ báo cáo rằng giới hạn tin nhắn đã đạt và đề xuất chờ đợi hoặc chuyển sang một mô hình khác.
Những hạn chế này đặc biệt gây rối khi bạn đang làm việc. Đó là lý do tại sao người dùng tìm kiếm cách tăng thời gian truy cập vào ChatGPT, vượt qua những hạn chế này hoặc ít nhất là giảm thiểu ảnh hưởng của chúng.
Trong bài viết này, chúng tôi sẽ bàn luận về các giới hạn tồn tại trong ChatGPT vào năm 2026, lý do chúng tồn tại và những phương pháp có thể được sử dụng để vượt qua chúng.
Nội dung
Làm việc với nhiều tài khoản quảng cáo và thử nghiệm các thiết lập quảng cáo mà không phải thực hiện hoạt động thường nhật rườm rà. Né chặn và tăng doanh thu của bạn.
Giới hạn ChatGPT
Giới hạn của ChatGPT phụ thuộc vào gói đăng ký, mô hình được chọn và tải trọng hệ thống hiện tại. Điều quan trọng cần hiểu là hầu hết các giới hạn không cố định và có thể thay đổi.
1. Giới hạn tin nhắn (giới hạn tốc độ)
Người dùng miễn phí có thể gửi một số lượng giới hạn tin nhắn đến các mô hình mạnh mẽ hơn trong vòng vài giờ. Sau đó, quyền truy cập sẽ bị giới hạn tạm thời hoặc người dùng được gợi ý để chuyển sang mô hình nhẹ hơn.
Các gói đăng ký có trả phí cung cấp giới hạn cao hơn, nhưng chúng vẫn bị giới hạn: hàng chục hoặc hàng trăm tin nhắn trong vài giờ.
2. Giới hạn mô hình
Các mô hình tiên tiến (đặc biệt là những mô hình có khả năng suy luận nâng cao) có giới hạn nghiêm ngặt hơn so với phiên bản nhẹ hơn. Các mô hình nhẹ thông thường chỉ có sẵn với những hạn chế tối thiểu.
3. Giới hạn công cụ
Tạo hình ảnh, xử lý tệp và các tính năng khác có hạn mức riêng biệt không liên quan trực tiếp đến tin nhắn văn bản.
4. Giới hạn ngữ cảnh (token)
Mỗi mô hình có độ dài ngữ cảnh tối đa, thường lên đến hàng trăm nghìn token. Khi vượt quá giới hạn này, tin nhắn cũ sẽ bị cắt bỏ hoặc có lỗi xảy ra.
Tại sao có giới hạn ChatGPT
Giới hạn của ChatGPT không phải là tùy tiện vì chúng là một phần của kiến trúc dịch vụ. Chúng cần thiết cho hoạt động ổn định của ChatGPT và được thúc đẩy bởi nhiều yếu tố khác nhau.
1. Hạn chế tính toán
Các mô hình ngôn ngữ lớn hiện đại yêu cầu tài nguyên tính toán đáng kể. Ngay cả một yêu cầu đơn lẻ cũng có thể liên quan đến cơ sở hạ tầng phức tạp (GPU/TPU, hệ thống phân tán). Nếu không có giới hạn, điều này sẽ làm quá tải máy chủ và tăng độ trễ.
2. Cân bằng tải
Giới hạn giúp phân bổ tài nguyên đồng đều giữa các người dùng. Nếu không có họ, người dùng hoạt động nhiều nhất hoặc hệ thống tự động có thể tiêu thụ tỷ lệ tài nguyên tính toán không tương xứng.
3. Mô hình kinh tế
ChatGPT hoạt động theo mô hình freemium: truy cập cơ bản bị giới hạn, trong khi các gói đăng ký có phí cung cấp giới hạn cao hơn và truy cập ưu tiên.
4. Bảo mật
Giới hạn tốc độ giúp ngăn chặn các cuộc tấn công tự động, tạo ra nội dung có hại hàng loạt và lạm dụng API.
5. Yếu tố bổ sung
Trong một số trường hợp, các yếu tố gián tiếp như tiêu thụ năng lượng và hiệu quả cơ sở hạ tầng cũng được xem xét.
Cách làm việc xung quanh giới hạn ChatGPT
Không thể hoàn toàn vượt qua giới hạn ChatGPT. Ngay cả khi có các gói đăng ký trả phí, vẫn có hạn chế về tần suất yêu cầu và quyền truy cập vào các mô hình mạnh hơn. Tuy nhiên, trong thực tế, có một số phương pháp hiệu quả có thể tạm thời vượt qua giới hạn hoặc giảm đáng kể tác động của chúng, cho phép bạn tiếp tục làm việc mà không bị gián đoạn lâu.
Bot Telegram và ứng dụng
Lựa chọn rõ ràng nhất mà người dùng tìm đến sau khi đạt giới hạn là các dịch vụ của bên thứ ba. Bao gồm các bot Telegram cũng như các nền tảng AI độc lập như Poe, Perplexity, Grok và You.com.
Tuy nhiên, điều quan trọng là phải thực tế. Các nền tảng đầy đủ tính năng như Poe hoặc Perplexity ổn định và cung cấp quyền truy cập vào nhiều mô hình, đôi khi với giới hạn linh hoạt hơn hoặc hệ thống hạn mức riêng của họ. Đây là một cách hợp pháp và bền vững để tiếp tục làm việc, chỉ không phải trong chính ChatGPT.
Tuy nhiên, các bot Telegram ít tiên đoán hơn nhiều. Phần lớn hoạt động thông qua API hoặc proxy, thường sử dụng chung pools yêu cầu và có thể hạn chế người dùng bất kỳ lúc nào. Ngoài ra, các tuyên bố về quyền truy cập vào các mô hình hàng đầu hoặc chế độ “suy nghĩ” thường không đáng tin cậy vì người dùng thường không thể xác minh mô hình nào thực sự đang được sử dụng.
Một khía cạnh quan trọng khác cần xem xét là bảo mật dữ liệu. Với các bot, bạn hầu như luôn gửi yêu cầu qua cơ sở hạ tầng của bên thứ ba, có thể ghi lại hoặc phân tích đầu vào của bạn. Đối với các nhiệm vụ nhạy cảm, đây là một rủi ro nghiêm trọng.
Do đó, các dịch vụ này có thể giúp đỡ khi cần tiếp tục cuộc hội thoại gấp sau khi đạt giới hạn, nhưng như một quy trình làm việc chính, chúng không ổn định và khó kiểm soát.
Dùng thử miễn phí
Một phương pháp khác là sử dụng các giai đoạn thử nghiệm trong các dịch vụ tích hợp các mô hình ngôn ngữ lớn. Trong trường hợp này, bạn không trực tiếp vượt qua giới hạn, nhưng tạm thời có quyền truy cập vào một hệ thống khác với giới hạn riêng.
Ví dụ, Cursor cung cấp quyền truy cập thử nghiệm vào các tính năng AI của nó và được các nhà phát triển sử dụng rộng rãi. Replit cung cấp các trợ lý AI tích hợp với giới hạn, trong khi Codeium và Tabnine là các công cụ thay thế để làm việc với mã.
Về mặt kỹ thuật, điều này không phải đang xóa bỏ giới hạn ChatGPT mà là chuyển sang một dịch vụ khác với thử nghiệm miễn phí hoặc điều kiện tốt hơn cho người dùng mới. Cuối cùng, các hạn chế sẽ quay lại, hoặc là giới hạn hoặc là yêu cầu thanh toán.
Tuy nhiên, như một chiến lược tạm thời, phương pháp này hoạt động tốt, đặc biệt nếu các tác vụ được phân phối qua nhiều giải pháp khác nhau: tạo văn bản, mã hóa, tìm kiếm và phân tích.
Octo Browser
Hãy nhớ rằng giới hạn ChatGPT gắn liền với tài khoản, không phải thiết bị. Một tài khoản nghĩa là một tập hợp giới hạn. Nhiều tài khoản nghĩa là giới hạn kết hợp. Octo Browser, một trình duyệt chống phát hiện cho đa tài khoản, cho phép bạn quản lý các tài khoản như vậy bằng cách tạo các hồ sơ trình duyệt riêng biệt với vân tay số thực cho mỗi cái.
Điều này giải quyết vấn đề cốt lõi: hệ thống không liên kết các tài khoản với nhau nếu chúng xuất hiện dưới dạng người dùng độc lập. Kết quả là bạn có thể làm việc trong các phiên song song và phân bổ tải.
Cách sử dụng Octo Browser để làm việc xung quanh giới hạn ChatGPT:
Tạo hồ sơ Octo Browser riêng cho từng tài khoản OpenAI.
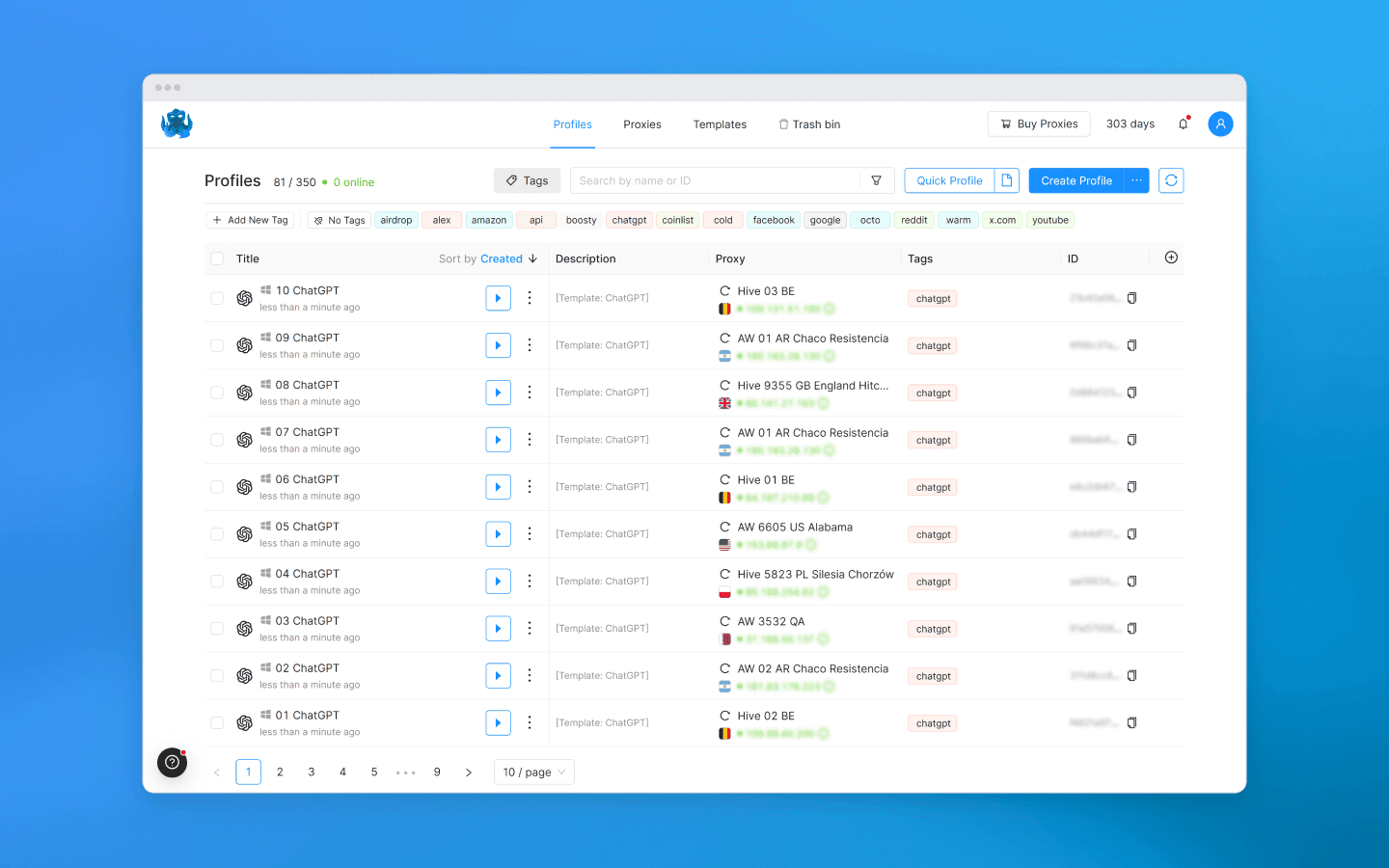
Mỗi hồ sơ sẽ có vân tay số của riêng nó: Canvas, WebGL, phông chữ, User-Agent, vị trí địa lý, múi giờ, WebRTC, v.v. Nếu bạn không chắc chắn nên chọn gì, bạn có thể để cài đặt mặc định.
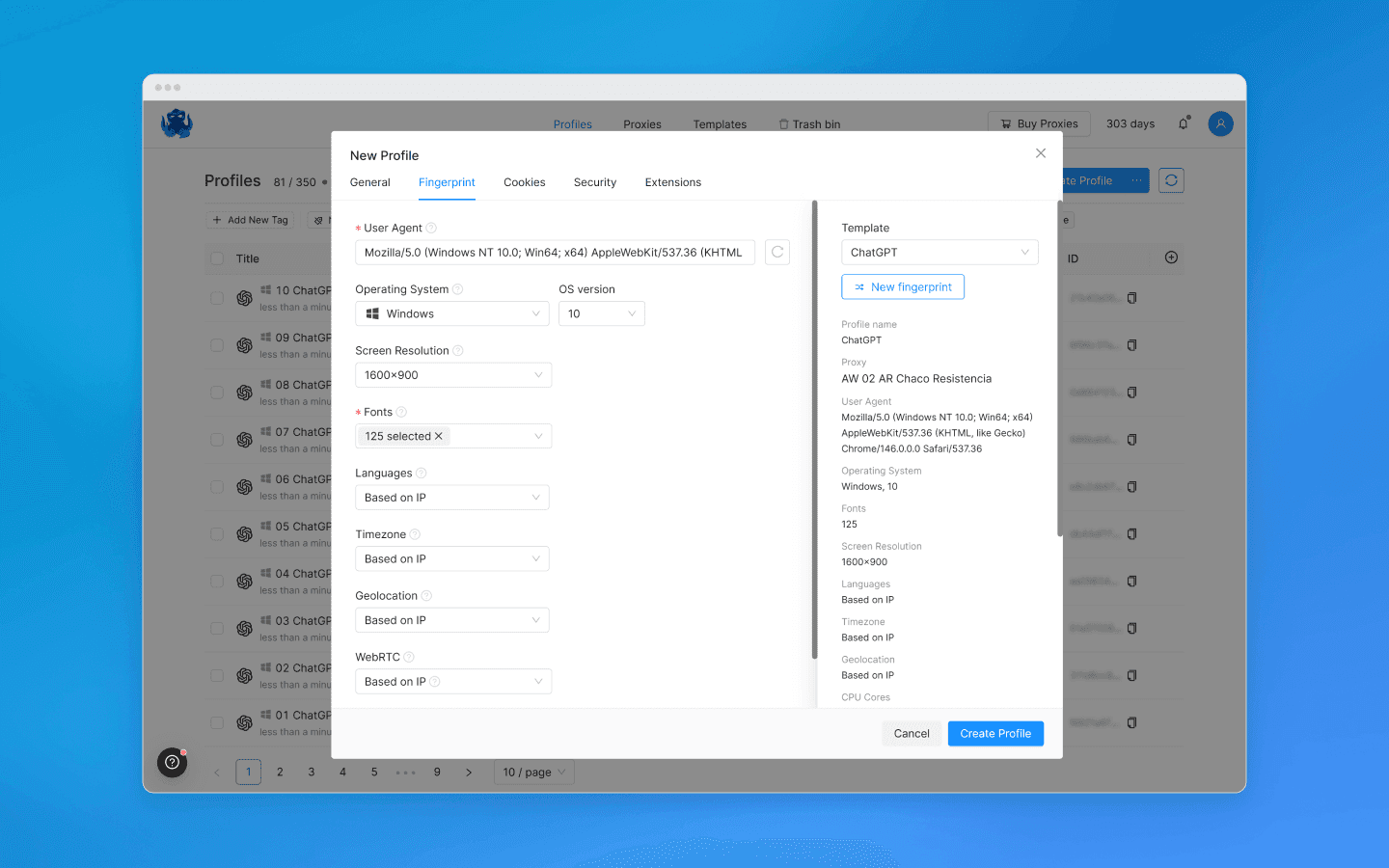
Gán proxy khác nhau cho mỗi hồ sơ.
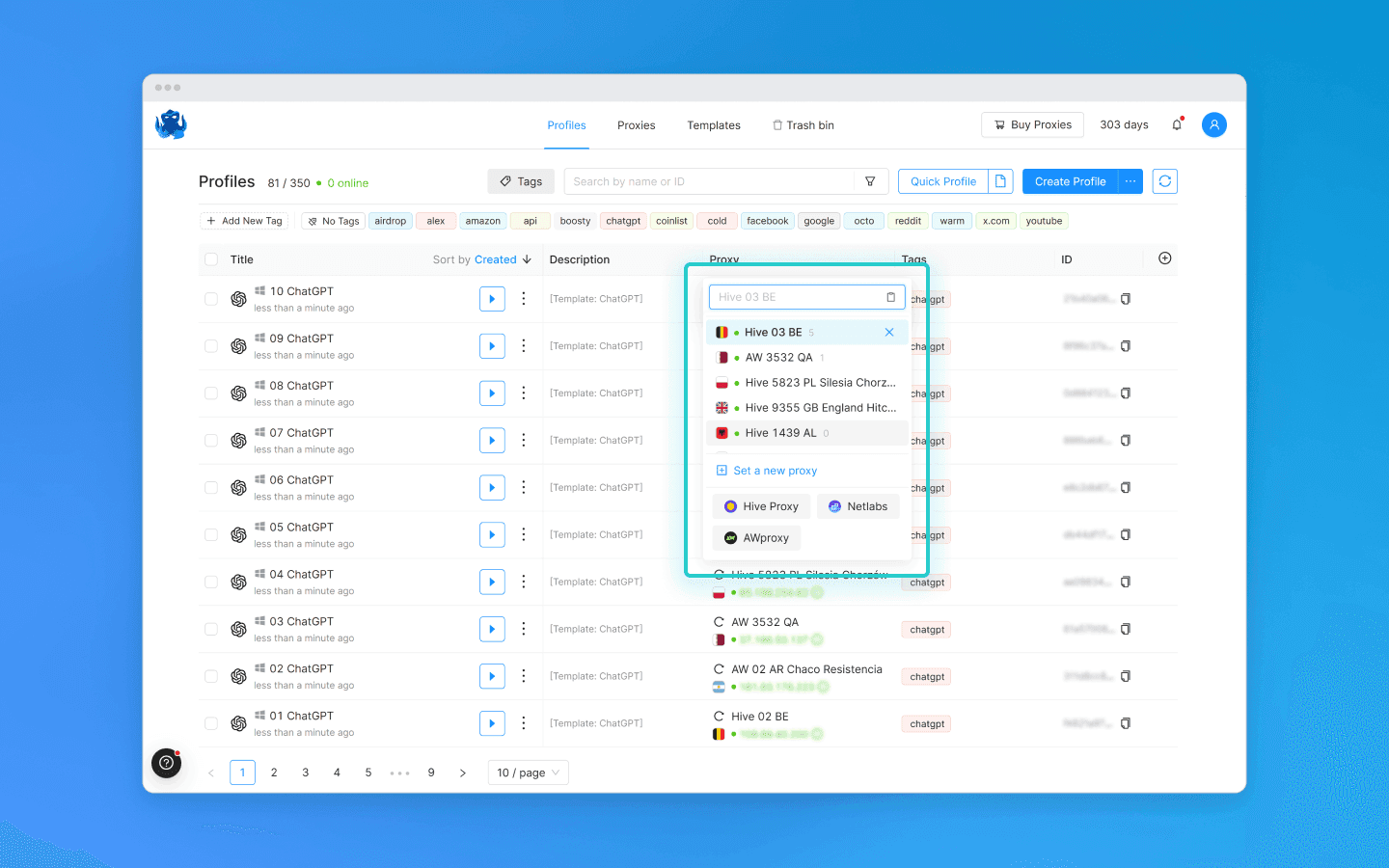
Đăng ký, mua hoặc thuê nhiều tài khoản ChatGPT.
Chuyển đổi giữa các hồ sơ khi cần thiết. Giới hạn ChatGPT được tính toán riêng cho mỗi tài khoản.
Lưu ý: hành động hung hăng (đăng ký hàng loạt, hành động giống hệt nhau, hoạt động đáng ngờ) vẫn mang rủi ro bị cấm.
Mẹo quản lý phiên và token
Ngay cả trong một tài khoản duy nhất, bạn có thể cải thiện hiệu quả đáng kể bằng cách làm việc thông minh hơn với các cuộc trò chuyện và yêu cầu. Những phương pháp này không vượt qua giới hạn ChatGPT trực tiếp, mà giúp giảm bớt các tin nhắn không cần thiết.
Tái sử dụng ngữ cảnh bất cứ khi nào có thể
Tiếp tục cùng một cuộc trò chuyện có nghĩa là bạn không cần nhập lại hướng dẫn, phong cách hoặc dữ liệu. ChatGPT chỉ xem xét ngữ cảnh hiện tại (tối đa hàng trăm nghìn token tùy thuộc vào mô hình), nên các cuộc trò chuyện dài hơn, có cấu trúc giúp giảm bớt sự trùng lặp tin nhắn.
Không bắt đầu cuộc trò chuyện mới về cùng một chủ đề trừ khi thực sự cần thiết.
Đặt tên cho các cuộc trò chuyện rõ ràng để dễ điều hướng hơn.
Chia các cuộc trò chuyện dài thành các khúc logic chỉ khi cần thiết.
Xóa ngữ cảnh để quản lý hiệu suất
Các cuộc trò chuyện rất dài có thể làm giảm chất lượng câu trả lời và làm cho công việc khó khăn hơn. Để tránh điều này:
Sử dụng các tính năng có sẵn như xóa hoặc phân nhánh một cuộc trò chuyện.
Bắt đầu một cuộc trò chuyện mới cho các chủ đề hoàn toàn khác nhau, chỉ mang lại các hướng dẫn chính.
Giám sát kích thước ngữ cảnh để tránh quá tải mô hình.
Quan trọng: xóa ngữ cảnh không đặt lại giới hạn tin nhắn, nó chỉ giúp quản lý chất lượng phản hồi.
Chia yêu cầu lớn thành những cái nhỏ hơn
Các yêu cầu rất lớn thường dẫn đến lỗi và yêu cầu giải thích không cần thiết. Tốt hơn là chia nhiệm vụ thành các bước:
lập kế hoạch;
viết các phần riêng biệt;
kiểm tra và tinh chỉnh.
Phương pháp này giúp bạn có kết quả tốt hơn nhanh hơn trong khi luôn trong giới hạn tin nhắn của ChatGPT.
Phương pháp tối ưu hóa nhắc nhở
Một nhắc nhở tốt là cách chính để giữ trong giới hạn ChatGPT của bạn. Yêu cầu rõ ràng và đầy đủ sản xuất một câu trả lời chính xác ngay từ lần đầu, không cần theo dõi không cần thiết.
Ví dụ, nếu bạn cần phân tích và gỡ lỗi mã Python, một loại nhiệm vụ mà giới hạn thường nhanh chóng bị cạn kiệt, hãy sử dụng phương pháp sau:
1. Gán vai trò cho mô hình
Xác định rõ ràng vai trò của mô hình. Điều này giúp tạo ra câu trả lời cấp chuyên gia và giảm các câu hỏi tiếp theo.
Ví dụ: “Bạn là một nhà phát triển Python cấp cao với 12 năm kinh nghiệm. Viết mã rõ ràng, theo phong cách và giải thích các thay đổi từng dòng.”
Phương pháp này biến nhắc nhở thành một tập hợp chỉ dẫn gọn gàng cho mô hình, giảm nhu cầu cho các sửa đổi lặp đi lặp lại.
2. Cung cấp đầy đủ ngữ cảnh từ đầu
Không gửi một nửa thông tin trong một tin nhắn và sau đó bổ sung lời giải thích sau. Nếu bạn đang làm việc với mã, cung cấp tất cả dữ liệu liên quan từ đầu:
mã, lỗi đã xác định, ngôn ngữ lập trình và phiên bản của nó, và nhiệm vụ mã được dự định thực hiện;
dữ liệu mẫu hoặc định dạng đầu ra mong muốn.
Ví dụ: thay vì “Tại sao mã này không hoạt động?” — cung cấp mã, lỗi, phiên bản Python và kết quả mong đợi ngay lập tức.
3. Chia nhiệm vụ thành các bước
Sử dụng phương pháp lặp để mô hình xử lý từng giai đoạn riêng, trong khi bạn có thể giám sát kết quả và sửa lỗi sớm.
Ví dụ:
Phân tích mã Python và xác định lỗi hoặc lỗ hổng tiềm tàng.
Sửa lỗi và đề xuất các tối ưu hóa hàm.
Thêm các trường hợp thử nghiệm để xác thực mã đã sửa chữa.
Bằng cách này, bạn giữ quyền kiểm soát tiến trình, giảm rủi ro cho các giải pháp không chính xác và tiết kiệm tin nhắn vì mỗi lần theo dõi đều gắn liền với một bước cụ thể.
4. Chỉ định định dạng đầu ra chính xác
Nếu bạn cần một phản hồi có cấu trúc, hãy định nghĩa định dạng trước, điều này giảm số lần sửa đổi và yêu cầu giải thích.
Ví dụ: “Chia phản hồi thành bốn phần: phân tích vấn đề, đề xuất thay đổi, mã đã sửa chữa và các trường hợp thử nghiệm.”
5. Sử dụng ví dụ
Chỉ cho mô hình kết quả mong đợi của bạn. Điều này đặc biệt hữu ích khi làm việc với mã, bảng hoặc định dạng.
Ví dụ:
Trước:
response.json()
response.json()
Sau:
response.raise_for_status() data = response.json()
response.raise_for_status() data = response.json()
Tại sao: raise_for_status() sẽ ném ra một ngoại lệ đối với lỗi HTTP, trong khi response.json() chỉ trả về dữ liệu nếu yêu cầu thành công.
6. Cắt giảm các từ ngữ không cần thiết
Nhắc nhở càng đơn giản và chính xác thì càng sử dụng ít token và tin nhắn.
Ví dụ:
Xấu: “Làm ơn giúp tôi với mã, nó không hoạt động, tôi không hiểu tại sao, giúp tôi ngay bây giờ.”
Tốt: “Phân tích và sửa mã dưới đây. Lỗi: JSONDecodeError trên phản hồi trống. Thêm xử lý lỗi mạng và HTTP.”
7. Sử dụng dấu phân cách cho các khối
Nếu nhắc nhở của bạn chứa nhiều phần, các dấu phân cách như ### giúp mô hình phân biệt giữa các chỉ dẫn, cải thiện độ chính xác và tiết kiệm tin nhắn.
Sử dụng API để quản lý giới hạn
API OpenAI là cách linh hoạt nhất để làm việc với ChatGPT mà không bị giới hạn của giao diện web. Thông qua API, bạn có quyền truy cập trực tiếp vào các mô hình (gpt-5.3, gpt-5.4, chế độ suy nghĩ) và quản lý hạn mức và token của riêng bạn.
1. Lấy khóa API và thiết lập
Để sử dụng API:
Truy cập platform.openai.com và đăng nhập.
Mở phần Khóa API trong menu bên trái.
Nhấp vào Tạo khóa bí mật mới.
Trong cửa sổ bật lên, nhập tên dự án nếu cần, đặt quyền và nhấp vào Tạo khóa bí mật mới.
Sao chép khóa và lưu trữ an toàn, vì nó cung cấp quyền truy cập đầy đủ vào tài khoản API của bạn.
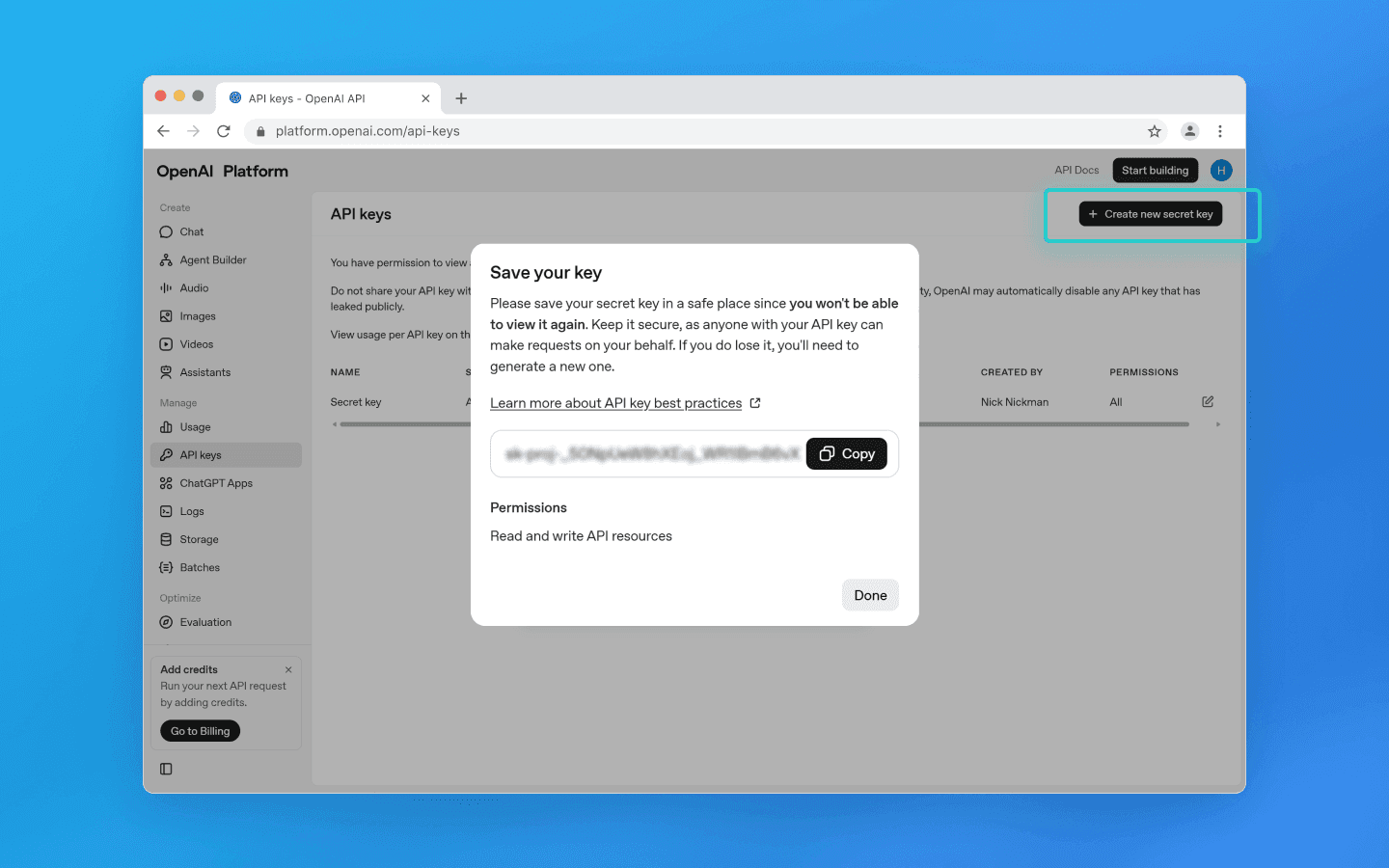
Quan trọng: Khóa API không gắn liền với các giới hạn ChatGPT web. Những giới hạn này chỉ phụ thuộc vào hạn mức API của bạn.
2. Hạn mức và giới hạn API
OpenAI sử dụng hệ thống hạn mức gắn liền với tài khoản và hóa đơn của bạn:
Tầng 0 (tài khoản mới): hạn mức nhỏ, ví dụ, 500–1.000 yêu cầu mỗi phút và 10k token mỗi phút cho các mô hình nhẹ.
Tầng 1+ (sau khi tiêu hơn $5): hàng nghìn yêu cầu mỗi phút (RPM) và hàng trăm nghìn token mỗi phút (TPM).
Tầng 5 (Doanh nghiệp): hạn mức gần như không giới hạn với các giới hạn tùy chỉnh theo thỏa thuận.
Hạn mức tăng tự động với thanh toán ổn định, nếu không có vi phạm.
Khác biệt với giao diện web: giới hạn API không dựa trên tin nhắn trò chuyện, mà trên RPM/TPM.
3. Sử dụng API hiệu quả
Để tiết kiệm hạn mức và cải thiện độ ổn định, hãy sử dụng những phương pháp tốt nhất sau:
Tham số hợp lý:
temperature— 0.2–0.5 cho chính xác mã, 0.7–1.0 cho các nhiệm vụ sáng tạo.max_tokens— giới hạn độ dài phản hồi để tránh sử dụng token không cần thiết.top_p— thường là 0.9–1.0.
Bộ nhớ đệm phản hồi: lưu trữ nhắc nhở lặp lại cục bộ (các tệp, Redis) để tránh gửi lại chúng.
Yêu cầu hàng loạt: gửi nhiều nhắc nhở trong một yêu cầu để tiết kiệm thời gian và token.
Sử dụng mô hình nhẹ cho bản nháp: sử dụng
gpt-4o-minihoặcgpt-5.3-instantcho bản thảo, sau đó hoàn thiện với mô hình hàng đầu.Chế độ phát trực tuyến:
stream=truecho phép bạn nhận phản hồi theo từng phần, tiết kiệm token nếu các phiên bị gián đoạn.Nhắc nhở hệ thống ngắn gọn: các chỉ dẫn vai trò và lõi ngắn hơn giảm sử dụng token trong mỗi yêu cầu.
4. Ví dụ Python
Một cách đơn giản để gọi API ChatGPT:
import requests api_key = "sk-..." url = "https://api.openai.com/v1/chat/completions" headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "gpt-5.3", "messages": [ {"role": "system", "content": "You are a senior Python developer. Write clean, idiomatic code."}, {"role": "user", "content": "Please review this code and fix any errors: ..."} ], "temperature": 0.3, "max_tokens": 800 } response = requests.post(url, headers=headers, json=data) print(response.json())
import requests api_key = "sk-..." url = "https://api.openai.com/v1/chat/completions" headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "gpt-5.3", "messages": [ {"role": "system", "content": "You are a senior Python developer. Write clean, idiomatic code."}, {"role": "user", "content": "Please review this code and fix any errors: ..."} ], "temperature": 0.3, "max_tokens": 800 } response = requests.post(url, headers=headers, json=data) print(response.json())
Chiến lược xử lý giới hạn tốc độ
Một giới hạn tốc độ trong ChatGPT là hạn chế về số lượng tin nhắn bạn có thể gửi trong một khoảng thời gian cụ thể. Nó hoạt động theo nguyên tắc cửa sổ xoay vòng.
Nguyên tắc cửa sổ xoay vòng có nghĩa gì:
Thay vì đặt lại vào thời điểm cố định (ví dụ, đúng 3:00), hệ thống theo dõi một khoảng thời gian dựa trên khi mỗi tin nhắn được gửi.
Ví dụ: nếu gói Plus của bạn cho phép 160 tin nhắn trong 3 giờ và bạn gửi tin nhắn đầu tiên lúc 10:00, nó sẽ chỉ ngừng tính vào giới hạn lúc 13:00. Điều tương tự áp dụng cho mỗi tin nhắn - cửa sổ liên tục thay đổi dựa trên thời gian gửi.
Điều này có nghĩa là giới hạn khôi phục dần dần, không phải tất cả cùng một lúc.
Để quản lý giới hạn tốc độ của bạn một cách hiệu quả, hãy làm theo các hướng dẫn sau:
1. Sử dụng mô hình nhẹ cho nhiệm vụ đơn giản
Phiên bản mini hoặc tức thời có giới hạn riêng và phù hợp cho kiểm tra nhanh, bản nháp hay giải thích đơn giản.
2. Xem thông báo của ChatGPT
Giao diện web hiển thị cảnh báo khi bạn sắp đạt tới giới hạn của mình.
3. Chia nhiệm vụ lớn thành khối
Thay vì một nhắc nhở dài, chia nhiệm vụ thành nhiều tin nhắn với chỉ dẫn rõ ràng. Điều này giúp tiết kiệm hạn mức của bạn, cải thiện kiểm soát và tăng cường chất lượng câu trả lời.
Kết luận
Các giới hạn ChatGPT năm 2026 không phải là một vấn đề tạm thời mà là một phần thường xuyên của việc làm việc với dịch vụ. Đối với người dùng, chúng thường trở thành điểm nghẽn: công việc dừng lại, các kỳ hạn bị trễ, và bạn phải chờ cho giới hạn đặt lại.
Trong bài viết này, chúng ta đã đề cập đến các hạn chế hiện tại, lý do đằng sau chúng (liên quan đến kỹ thuật, kinh tế và bảo mật) và các cách thực tế để giảm tác động của chúng. Cách tiếp cận hiệu quả nhất là kết hợp các phương pháp: nhiều tài khoản ChatGPT được tạo bằng trình duyệt chống phát hiện, tối ưu hóa nhắc nhở và quản lý ngữ cảnh đúng cách, làm việc qua API với hạn mức dựa trên tầng, và luân phiên hợp lý giữa các khoảng dừng và mô hình nhẹ.
Không thể loại bỏ hoàn toàn giới hạn ChatGPT mà không có gói Pro đắt tiền, nhưng áp dụng nhất quán và đúng cách các chiến lược này cho phép bạn làm việc lâu hơn và hiệu quả hơn.
Câu hỏi thường gặp
Giới hạn tốc độ trong ChatGPT kéo dài bao lâu?
ChatGPT sử dụng nguyên tắc cửa sổ xoay vòng. Điều này có nghĩa là giới hạn không đặt lại vào một thời điểm cố định mà được tính toán riêng cho từng tin nhắn. Sau 3-5 giờ, một tin nhắn cụ thể không còn tính vào cửa sổ hiện tại nữa.
Các mô hình ChatGPT khác nhau có giới hạn khác nhau không?
Có. Giới hạn phụ thuộc vào đăng ký của bạn. Trên gói Miễn phí, quyền truy cập vào các mô hình tiên tiến bị giới hạn (thường khoảng 10 tin nhắn trong vài giờ), sau đó hệ thống có thể chuyển sang mô hình nhẹ (mini). Các gói trả phí (như Plus) cung cấp hạn mức cao hơn đáng kể trong cùng một khoảng thời gian.
Giới hạn API có thể thay đổi không?
Có, nhưng không bằng tay. Giới hạn API của OpenAI được quản lý thông qua hạn mức (giới hạn tốc độ và giới hạn chi tiêu) và tăng tự động với sử dụng và thanh toán. Thanh toán ổn định và sử dụng cao hơn dẫn đến giới hạn có sẵn cao hơn (RPM/TPM). Trong một số trường hợp, giới hạn cho khách hàng lớn có thể được tăng thông qua hỗ trợ.
Giới hạn ChatGPT có đặt lại nếu tôi sử dụng các trình duyệt khác nhau không?
Không. Giới hạn gắn liền với tài khoản của bạn, không phải trình duyệt. Sử dụng trình duyệt hoặc tab khác nhau không thay đổi bộ đếm tin nhắn.
Giới hạn ChatGPT gắn liền với tài khoản hay thiết bị?
Giới hạn ChatGPT gắn liền với tài khoản. Thiết bị, trình duyệt, và địa chỉ IP không ảnh hưởng đến số lượng tin nhắn có sẵn. Một tài khoản bằng một giới hạn chung.
Sự khác biệt giữa giới hạn token và giới hạn tốc độ là gì?
Đây là các hệ thống khác nhau. Giới hạn token xác định số lượng văn bản (đầu vào và đầu ra) có thể được xử lý trong một yêu cầu duy nhất hoặc trong một ngữ cảnh đoạn hội thoại. Giới hạn tốc độ xác định tần suất bạn có thể gửi yêu cầu trong một khoảng thời gian. Bạn có thể đạt một giới hạn mà không đạt giới hạn khác.
Làm việc với nhiều tài khoản quảng cáo và thử nghiệm các thiết lập quảng cáo mà không phải thực hiện hoạt động thường nhật rườm rà. Né chặn và tăng doanh thu của bạn.
Giới hạn ChatGPT
Giới hạn của ChatGPT phụ thuộc vào gói đăng ký, mô hình được chọn và tải trọng hệ thống hiện tại. Điều quan trọng cần hiểu là hầu hết các giới hạn không cố định và có thể thay đổi.
1. Giới hạn tin nhắn (giới hạn tốc độ)
Người dùng miễn phí có thể gửi một số lượng giới hạn tin nhắn đến các mô hình mạnh mẽ hơn trong vòng vài giờ. Sau đó, quyền truy cập sẽ bị giới hạn tạm thời hoặc người dùng được gợi ý để chuyển sang mô hình nhẹ hơn.
Các gói đăng ký có trả phí cung cấp giới hạn cao hơn, nhưng chúng vẫn bị giới hạn: hàng chục hoặc hàng trăm tin nhắn trong vài giờ.
2. Giới hạn mô hình
Các mô hình tiên tiến (đặc biệt là những mô hình có khả năng suy luận nâng cao) có giới hạn nghiêm ngặt hơn so với phiên bản nhẹ hơn. Các mô hình nhẹ thông thường chỉ có sẵn với những hạn chế tối thiểu.
3. Giới hạn công cụ
Tạo hình ảnh, xử lý tệp và các tính năng khác có hạn mức riêng biệt không liên quan trực tiếp đến tin nhắn văn bản.
4. Giới hạn ngữ cảnh (token)
Mỗi mô hình có độ dài ngữ cảnh tối đa, thường lên đến hàng trăm nghìn token. Khi vượt quá giới hạn này, tin nhắn cũ sẽ bị cắt bỏ hoặc có lỗi xảy ra.
Tại sao có giới hạn ChatGPT
Giới hạn của ChatGPT không phải là tùy tiện vì chúng là một phần của kiến trúc dịch vụ. Chúng cần thiết cho hoạt động ổn định của ChatGPT và được thúc đẩy bởi nhiều yếu tố khác nhau.
1. Hạn chế tính toán
Các mô hình ngôn ngữ lớn hiện đại yêu cầu tài nguyên tính toán đáng kể. Ngay cả một yêu cầu đơn lẻ cũng có thể liên quan đến cơ sở hạ tầng phức tạp (GPU/TPU, hệ thống phân tán). Nếu không có giới hạn, điều này sẽ làm quá tải máy chủ và tăng độ trễ.
2. Cân bằng tải
Giới hạn giúp phân bổ tài nguyên đồng đều giữa các người dùng. Nếu không có họ, người dùng hoạt động nhiều nhất hoặc hệ thống tự động có thể tiêu thụ tỷ lệ tài nguyên tính toán không tương xứng.
3. Mô hình kinh tế
ChatGPT hoạt động theo mô hình freemium: truy cập cơ bản bị giới hạn, trong khi các gói đăng ký có phí cung cấp giới hạn cao hơn và truy cập ưu tiên.
4. Bảo mật
Giới hạn tốc độ giúp ngăn chặn các cuộc tấn công tự động, tạo ra nội dung có hại hàng loạt và lạm dụng API.
5. Yếu tố bổ sung
Trong một số trường hợp, các yếu tố gián tiếp như tiêu thụ năng lượng và hiệu quả cơ sở hạ tầng cũng được xem xét.
Cách làm việc xung quanh giới hạn ChatGPT
Không thể hoàn toàn vượt qua giới hạn ChatGPT. Ngay cả khi có các gói đăng ký trả phí, vẫn có hạn chế về tần suất yêu cầu và quyền truy cập vào các mô hình mạnh hơn. Tuy nhiên, trong thực tế, có một số phương pháp hiệu quả có thể tạm thời vượt qua giới hạn hoặc giảm đáng kể tác động của chúng, cho phép bạn tiếp tục làm việc mà không bị gián đoạn lâu.
Bot Telegram và ứng dụng
Lựa chọn rõ ràng nhất mà người dùng tìm đến sau khi đạt giới hạn là các dịch vụ của bên thứ ba. Bao gồm các bot Telegram cũng như các nền tảng AI độc lập như Poe, Perplexity, Grok và You.com.
Tuy nhiên, điều quan trọng là phải thực tế. Các nền tảng đầy đủ tính năng như Poe hoặc Perplexity ổn định và cung cấp quyền truy cập vào nhiều mô hình, đôi khi với giới hạn linh hoạt hơn hoặc hệ thống hạn mức riêng của họ. Đây là một cách hợp pháp và bền vững để tiếp tục làm việc, chỉ không phải trong chính ChatGPT.
Tuy nhiên, các bot Telegram ít tiên đoán hơn nhiều. Phần lớn hoạt động thông qua API hoặc proxy, thường sử dụng chung pools yêu cầu và có thể hạn chế người dùng bất kỳ lúc nào. Ngoài ra, các tuyên bố về quyền truy cập vào các mô hình hàng đầu hoặc chế độ “suy nghĩ” thường không đáng tin cậy vì người dùng thường không thể xác minh mô hình nào thực sự đang được sử dụng.
Một khía cạnh quan trọng khác cần xem xét là bảo mật dữ liệu. Với các bot, bạn hầu như luôn gửi yêu cầu qua cơ sở hạ tầng của bên thứ ba, có thể ghi lại hoặc phân tích đầu vào của bạn. Đối với các nhiệm vụ nhạy cảm, đây là một rủi ro nghiêm trọng.
Do đó, các dịch vụ này có thể giúp đỡ khi cần tiếp tục cuộc hội thoại gấp sau khi đạt giới hạn, nhưng như một quy trình làm việc chính, chúng không ổn định và khó kiểm soát.
Dùng thử miễn phí
Một phương pháp khác là sử dụng các giai đoạn thử nghiệm trong các dịch vụ tích hợp các mô hình ngôn ngữ lớn. Trong trường hợp này, bạn không trực tiếp vượt qua giới hạn, nhưng tạm thời có quyền truy cập vào một hệ thống khác với giới hạn riêng.
Ví dụ, Cursor cung cấp quyền truy cập thử nghiệm vào các tính năng AI của nó và được các nhà phát triển sử dụng rộng rãi. Replit cung cấp các trợ lý AI tích hợp với giới hạn, trong khi Codeium và Tabnine là các công cụ thay thế để làm việc với mã.
Về mặt kỹ thuật, điều này không phải đang xóa bỏ giới hạn ChatGPT mà là chuyển sang một dịch vụ khác với thử nghiệm miễn phí hoặc điều kiện tốt hơn cho người dùng mới. Cuối cùng, các hạn chế sẽ quay lại, hoặc là giới hạn hoặc là yêu cầu thanh toán.
Tuy nhiên, như một chiến lược tạm thời, phương pháp này hoạt động tốt, đặc biệt nếu các tác vụ được phân phối qua nhiều giải pháp khác nhau: tạo văn bản, mã hóa, tìm kiếm và phân tích.
Octo Browser
Hãy nhớ rằng giới hạn ChatGPT gắn liền với tài khoản, không phải thiết bị. Một tài khoản nghĩa là một tập hợp giới hạn. Nhiều tài khoản nghĩa là giới hạn kết hợp. Octo Browser, một trình duyệt chống phát hiện cho đa tài khoản, cho phép bạn quản lý các tài khoản như vậy bằng cách tạo các hồ sơ trình duyệt riêng biệt với vân tay số thực cho mỗi cái.
Điều này giải quyết vấn đề cốt lõi: hệ thống không liên kết các tài khoản với nhau nếu chúng xuất hiện dưới dạng người dùng độc lập. Kết quả là bạn có thể làm việc trong các phiên song song và phân bổ tải.
Cách sử dụng Octo Browser để làm việc xung quanh giới hạn ChatGPT:
Tạo hồ sơ Octo Browser riêng cho từng tài khoản OpenAI.
Mỗi hồ sơ sẽ có vân tay số của riêng nó: Canvas, WebGL, phông chữ, User-Agent, vị trí địa lý, múi giờ, WebRTC, v.v. Nếu bạn không chắc chắn nên chọn gì, bạn có thể để cài đặt mặc định.
Gán proxy khác nhau cho mỗi hồ sơ.
Đăng ký, mua hoặc thuê nhiều tài khoản ChatGPT.
Chuyển đổi giữa các hồ sơ khi cần thiết. Giới hạn ChatGPT được tính toán riêng cho mỗi tài khoản.
Lưu ý: hành động hung hăng (đăng ký hàng loạt, hành động giống hệt nhau, hoạt động đáng ngờ) vẫn mang rủi ro bị cấm.
Mẹo quản lý phiên và token
Ngay cả trong một tài khoản duy nhất, bạn có thể cải thiện hiệu quả đáng kể bằng cách làm việc thông minh hơn với các cuộc trò chuyện và yêu cầu. Những phương pháp này không vượt qua giới hạn ChatGPT trực tiếp, mà giúp giảm bớt các tin nhắn không cần thiết.
Tái sử dụng ngữ cảnh bất cứ khi nào có thể
Tiếp tục cùng một cuộc trò chuyện có nghĩa là bạn không cần nhập lại hướng dẫn, phong cách hoặc dữ liệu. ChatGPT chỉ xem xét ngữ cảnh hiện tại (tối đa hàng trăm nghìn token tùy thuộc vào mô hình), nên các cuộc trò chuyện dài hơn, có cấu trúc giúp giảm bớt sự trùng lặp tin nhắn.
Không bắt đầu cuộc trò chuyện mới về cùng một chủ đề trừ khi thực sự cần thiết.
Đặt tên cho các cuộc trò chuyện rõ ràng để dễ điều hướng hơn.
Chia các cuộc trò chuyện dài thành các khúc logic chỉ khi cần thiết.
Xóa ngữ cảnh để quản lý hiệu suất
Các cuộc trò chuyện rất dài có thể làm giảm chất lượng câu trả lời và làm cho công việc khó khăn hơn. Để tránh điều này:
Sử dụng các tính năng có sẵn như xóa hoặc phân nhánh một cuộc trò chuyện.
Bắt đầu một cuộc trò chuyện mới cho các chủ đề hoàn toàn khác nhau, chỉ mang lại các hướng dẫn chính.
Giám sát kích thước ngữ cảnh để tránh quá tải mô hình.
Quan trọng: xóa ngữ cảnh không đặt lại giới hạn tin nhắn, nó chỉ giúp quản lý chất lượng phản hồi.
Chia yêu cầu lớn thành những cái nhỏ hơn
Các yêu cầu rất lớn thường dẫn đến lỗi và yêu cầu giải thích không cần thiết. Tốt hơn là chia nhiệm vụ thành các bước:
lập kế hoạch;
viết các phần riêng biệt;
kiểm tra và tinh chỉnh.
Phương pháp này giúp bạn có kết quả tốt hơn nhanh hơn trong khi luôn trong giới hạn tin nhắn của ChatGPT.
Phương pháp tối ưu hóa nhắc nhở
Một nhắc nhở tốt là cách chính để giữ trong giới hạn ChatGPT của bạn. Yêu cầu rõ ràng và đầy đủ sản xuất một câu trả lời chính xác ngay từ lần đầu, không cần theo dõi không cần thiết.
Ví dụ, nếu bạn cần phân tích và gỡ lỗi mã Python, một loại nhiệm vụ mà giới hạn thường nhanh chóng bị cạn kiệt, hãy sử dụng phương pháp sau:
1. Gán vai trò cho mô hình
Xác định rõ ràng vai trò của mô hình. Điều này giúp tạo ra câu trả lời cấp chuyên gia và giảm các câu hỏi tiếp theo.
Ví dụ: “Bạn là một nhà phát triển Python cấp cao với 12 năm kinh nghiệm. Viết mã rõ ràng, theo phong cách và giải thích các thay đổi từng dòng.”
Phương pháp này biến nhắc nhở thành một tập hợp chỉ dẫn gọn gàng cho mô hình, giảm nhu cầu cho các sửa đổi lặp đi lặp lại.
2. Cung cấp đầy đủ ngữ cảnh từ đầu
Không gửi một nửa thông tin trong một tin nhắn và sau đó bổ sung lời giải thích sau. Nếu bạn đang làm việc với mã, cung cấp tất cả dữ liệu liên quan từ đầu:
mã, lỗi đã xác định, ngôn ngữ lập trình và phiên bản của nó, và nhiệm vụ mã được dự định thực hiện;
dữ liệu mẫu hoặc định dạng đầu ra mong muốn.
Ví dụ: thay vì “Tại sao mã này không hoạt động?” — cung cấp mã, lỗi, phiên bản Python và kết quả mong đợi ngay lập tức.
3. Chia nhiệm vụ thành các bước
Sử dụng phương pháp lặp để mô hình xử lý từng giai đoạn riêng, trong khi bạn có thể giám sát kết quả và sửa lỗi sớm.
Ví dụ:
Phân tích mã Python và xác định lỗi hoặc lỗ hổng tiềm tàng.
Sửa lỗi và đề xuất các tối ưu hóa hàm.
Thêm các trường hợp thử nghiệm để xác thực mã đã sửa chữa.
Bằng cách này, bạn giữ quyền kiểm soát tiến trình, giảm rủi ro cho các giải pháp không chính xác và tiết kiệm tin nhắn vì mỗi lần theo dõi đều gắn liền với một bước cụ thể.
4. Chỉ định định dạng đầu ra chính xác
Nếu bạn cần một phản hồi có cấu trúc, hãy định nghĩa định dạng trước, điều này giảm số lần sửa đổi và yêu cầu giải thích.
Ví dụ: “Chia phản hồi thành bốn phần: phân tích vấn đề, đề xuất thay đổi, mã đã sửa chữa và các trường hợp thử nghiệm.”
5. Sử dụng ví dụ
Chỉ cho mô hình kết quả mong đợi của bạn. Điều này đặc biệt hữu ích khi làm việc với mã, bảng hoặc định dạng.
Ví dụ:
Trước:
response.json()
Sau:
response.raise_for_status() data = response.json()
Tại sao: raise_for_status() sẽ ném ra một ngoại lệ đối với lỗi HTTP, trong khi response.json() chỉ trả về dữ liệu nếu yêu cầu thành công.
6. Cắt giảm các từ ngữ không cần thiết
Nhắc nhở càng đơn giản và chính xác thì càng sử dụng ít token và tin nhắn.
Ví dụ:
Xấu: “Làm ơn giúp tôi với mã, nó không hoạt động, tôi không hiểu tại sao, giúp tôi ngay bây giờ.”
Tốt: “Phân tích và sửa mã dưới đây. Lỗi: JSONDecodeError trên phản hồi trống. Thêm xử lý lỗi mạng và HTTP.”
7. Sử dụng dấu phân cách cho các khối
Nếu nhắc nhở của bạn chứa nhiều phần, các dấu phân cách như ### giúp mô hình phân biệt giữa các chỉ dẫn, cải thiện độ chính xác và tiết kiệm tin nhắn.
Sử dụng API để quản lý giới hạn
API OpenAI là cách linh hoạt nhất để làm việc với ChatGPT mà không bị giới hạn của giao diện web. Thông qua API, bạn có quyền truy cập trực tiếp vào các mô hình (gpt-5.3, gpt-5.4, chế độ suy nghĩ) và quản lý hạn mức và token của riêng bạn.
1. Lấy khóa API và thiết lập
Để sử dụng API:
Truy cập platform.openai.com và đăng nhập.
Mở phần Khóa API trong menu bên trái.
Nhấp vào Tạo khóa bí mật mới.
Trong cửa sổ bật lên, nhập tên dự án nếu cần, đặt quyền và nhấp vào Tạo khóa bí mật mới.
Sao chép khóa và lưu trữ an toàn, vì nó cung cấp quyền truy cập đầy đủ vào tài khoản API của bạn.
Quan trọng: Khóa API không gắn liền với các giới hạn ChatGPT web. Những giới hạn này chỉ phụ thuộc vào hạn mức API của bạn.
2. Hạn mức và giới hạn API
OpenAI sử dụng hệ thống hạn mức gắn liền với tài khoản và hóa đơn của bạn:
Tầng 0 (tài khoản mới): hạn mức nhỏ, ví dụ, 500–1.000 yêu cầu mỗi phút và 10k token mỗi phút cho các mô hình nhẹ.
Tầng 1+ (sau khi tiêu hơn $5): hàng nghìn yêu cầu mỗi phút (RPM) và hàng trăm nghìn token mỗi phút (TPM).
Tầng 5 (Doanh nghiệp): hạn mức gần như không giới hạn với các giới hạn tùy chỉnh theo thỏa thuận.
Hạn mức tăng tự động với thanh toán ổn định, nếu không có vi phạm.
Khác biệt với giao diện web: giới hạn API không dựa trên tin nhắn trò chuyện, mà trên RPM/TPM.
3. Sử dụng API hiệu quả
Để tiết kiệm hạn mức và cải thiện độ ổn định, hãy sử dụng những phương pháp tốt nhất sau:
Tham số hợp lý:
temperature— 0.2–0.5 cho chính xác mã, 0.7–1.0 cho các nhiệm vụ sáng tạo.max_tokens— giới hạn độ dài phản hồi để tránh sử dụng token không cần thiết.top_p— thường là 0.9–1.0.
Bộ nhớ đệm phản hồi: lưu trữ nhắc nhở lặp lại cục bộ (các tệp, Redis) để tránh gửi lại chúng.
Yêu cầu hàng loạt: gửi nhiều nhắc nhở trong một yêu cầu để tiết kiệm thời gian và token.
Sử dụng mô hình nhẹ cho bản nháp: sử dụng
gpt-4o-minihoặcgpt-5.3-instantcho bản thảo, sau đó hoàn thiện với mô hình hàng đầu.Chế độ phát trực tuyến:
stream=truecho phép bạn nhận phản hồi theo từng phần, tiết kiệm token nếu các phiên bị gián đoạn.Nhắc nhở hệ thống ngắn gọn: các chỉ dẫn vai trò và lõi ngắn hơn giảm sử dụng token trong mỗi yêu cầu.
4. Ví dụ Python
Một cách đơn giản để gọi API ChatGPT:
import requests api_key = "sk-..." url = "https://api.openai.com/v1/chat/completions" headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "gpt-5.3", "messages": [ {"role": "system", "content": "You are a senior Python developer. Write clean, idiomatic code."}, {"role": "user", "content": "Please review this code and fix any errors: ..."} ], "temperature": 0.3, "max_tokens": 800 } response = requests.post(url, headers=headers, json=data) print(response.json())
Chiến lược xử lý giới hạn tốc độ
Một giới hạn tốc độ trong ChatGPT là hạn chế về số lượng tin nhắn bạn có thể gửi trong một khoảng thời gian cụ thể. Nó hoạt động theo nguyên tắc cửa sổ xoay vòng.
Nguyên tắc cửa sổ xoay vòng có nghĩa gì:
Thay vì đặt lại vào thời điểm cố định (ví dụ, đúng 3:00), hệ thống theo dõi một khoảng thời gian dựa trên khi mỗi tin nhắn được gửi.
Ví dụ: nếu gói Plus của bạn cho phép 160 tin nhắn trong 3 giờ và bạn gửi tin nhắn đầu tiên lúc 10:00, nó sẽ chỉ ngừng tính vào giới hạn lúc 13:00. Điều tương tự áp dụng cho mỗi tin nhắn - cửa sổ liên tục thay đổi dựa trên thời gian gửi.
Điều này có nghĩa là giới hạn khôi phục dần dần, không phải tất cả cùng một lúc.
Để quản lý giới hạn tốc độ của bạn một cách hiệu quả, hãy làm theo các hướng dẫn sau:
1. Sử dụng mô hình nhẹ cho nhiệm vụ đơn giản
Phiên bản mini hoặc tức thời có giới hạn riêng và phù hợp cho kiểm tra nhanh, bản nháp hay giải thích đơn giản.
2. Xem thông báo của ChatGPT
Giao diện web hiển thị cảnh báo khi bạn sắp đạt tới giới hạn của mình.
3. Chia nhiệm vụ lớn thành khối
Thay vì một nhắc nhở dài, chia nhiệm vụ thành nhiều tin nhắn với chỉ dẫn rõ ràng. Điều này giúp tiết kiệm hạn mức của bạn, cải thiện kiểm soát và tăng cường chất lượng câu trả lời.
Kết luận
Các giới hạn ChatGPT năm 2026 không phải là một vấn đề tạm thời mà là một phần thường xuyên của việc làm việc với dịch vụ. Đối với người dùng, chúng thường trở thành điểm nghẽn: công việc dừng lại, các kỳ hạn bị trễ, và bạn phải chờ cho giới hạn đặt lại.
Trong bài viết này, chúng ta đã đề cập đến các hạn chế hiện tại, lý do đằng sau chúng (liên quan đến kỹ thuật, kinh tế và bảo mật) và các cách thực tế để giảm tác động của chúng. Cách tiếp cận hiệu quả nhất là kết hợp các phương pháp: nhiều tài khoản ChatGPT được tạo bằng trình duyệt chống phát hiện, tối ưu hóa nhắc nhở và quản lý ngữ cảnh đúng cách, làm việc qua API với hạn mức dựa trên tầng, và luân phiên hợp lý giữa các khoảng dừng và mô hình nhẹ.
Không thể loại bỏ hoàn toàn giới hạn ChatGPT mà không có gói Pro đắt tiền, nhưng áp dụng nhất quán và đúng cách các chiến lược này cho phép bạn làm việc lâu hơn và hiệu quả hơn.
Câu hỏi thường gặp
Giới hạn tốc độ trong ChatGPT kéo dài bao lâu?
ChatGPT sử dụng nguyên tắc cửa sổ xoay vòng. Điều này có nghĩa là giới hạn không đặt lại vào một thời điểm cố định mà được tính toán riêng cho từng tin nhắn. Sau 3-5 giờ, một tin nhắn cụ thể không còn tính vào cửa sổ hiện tại nữa.
Các mô hình ChatGPT khác nhau có giới hạn khác nhau không?
Có. Giới hạn phụ thuộc vào đăng ký của bạn. Trên gói Miễn phí, quyền truy cập vào các mô hình tiên tiến bị giới hạn (thường khoảng 10 tin nhắn trong vài giờ), sau đó hệ thống có thể chuyển sang mô hình nhẹ (mini). Các gói trả phí (như Plus) cung cấp hạn mức cao hơn đáng kể trong cùng một khoảng thời gian.
Giới hạn API có thể thay đổi không?
Có, nhưng không bằng tay. Giới hạn API của OpenAI được quản lý thông qua hạn mức (giới hạn tốc độ và giới hạn chi tiêu) và tăng tự động với sử dụng và thanh toán. Thanh toán ổn định và sử dụng cao hơn dẫn đến giới hạn có sẵn cao hơn (RPM/TPM). Trong một số trường hợp, giới hạn cho khách hàng lớn có thể được tăng thông qua hỗ trợ.
Giới hạn ChatGPT có đặt lại nếu tôi sử dụng các trình duyệt khác nhau không?
Không. Giới hạn gắn liền với tài khoản của bạn, không phải trình duyệt. Sử dụng trình duyệt hoặc tab khác nhau không thay đổi bộ đếm tin nhắn.
Giới hạn ChatGPT gắn liền với tài khoản hay thiết bị?
Giới hạn ChatGPT gắn liền với tài khoản. Thiết bị, trình duyệt, và địa chỉ IP không ảnh hưởng đến số lượng tin nhắn có sẵn. Một tài khoản bằng một giới hạn chung.
Sự khác biệt giữa giới hạn token và giới hạn tốc độ là gì?
Đây là các hệ thống khác nhau. Giới hạn token xác định số lượng văn bản (đầu vào và đầu ra) có thể được xử lý trong một yêu cầu duy nhất hoặc trong một ngữ cảnh đoạn hội thoại. Giới hạn tốc độ xác định tần suất bạn có thể gửi yêu cầu trong một khoảng thời gian. Bạn có thể đạt một giới hạn mà không đạt giới hạn khác.
Cập nhật với các tin tức Octo Browser mới nhất
Khi nhấp vào nút này, bạn sẽ đồng ý với Chính sách Quyền riêng tư của chúng tôi.
Cập nhật với các tin tức Octo Browser mới nhất
Khi nhấp vào nút này, bạn sẽ đồng ý với Chính sách Quyền riêng tư của chúng tôi.
Cập nhật với các tin tức Octo Browser mới nhất
Khi nhấp vào nút này, bạn sẽ đồng ý với Chính sách Quyền riêng tư của chúng tôi.

Tham gia Octo Browser ngay
Hoặc liên hệ với Dịch vụ khách hàng bất kì lúc nào nếu bạn có bất cứ thắc mắc nào.
Tham gia Octo Browser ngay
Hoặc liên hệ với Dịch vụ khách hàng bất kì lúc nào nếu bạn có bất cứ thắc mắc nào.
Tham gia Octo Browser ngay
Hoặc liên hệ với Dịch vụ khách hàng bất kì lúc nào nếu bạn có bất cứ thắc mắc nào.