Análise comportamental: o que é e como especialistas em automação podem contorná-la
22/05/2026


Markus_automation
Expert in data parsing and automation
Não faz muito tempo, os sistemas antifraude dependiam principalmente de atributos técnicos—endereços IP, cookies e impressões digitais do navegador. No entanto, à medida que os desenvolvedores de scripts e scrapers aprenderam a falsificar esses parâmetros de forma eficaz, o foco da proteção mudou para a análise comportamental.
A biometria comportamental avalia exatamente como um usuário interage com uma interface e está gradualmente se tornando um componente fundamental dos modernos sistemas de detecção de automação.
Neste artigo, discutimos como essa abordagem funciona e explicamos como reproduzir de forma realista o comportamento humano em cenários automatizados.
Índice
Mantenha o anonimato, aproveite o recurso multiconta e alcance seus objetivos com o melhor navegador antidetecção do mercado.
Você gostaria de experimentar o Octo Browser com desconto?
Use o código promocional OCTOSCRAPER para obter 30% de desconto em qualquer assinatura. Esta oferta é válida apenas para novos usuários.
Por que os CAPTCHAs estão dando lugar à análise comportamental
Antes, o CAPTCHA era o principal mecanismo de defesa contra bots. Os CAPTCHAs ainda existem hoje, embora tenham mudado significativamente. Eles se tornaram mais sofisticados, e algumas versões modernas e invisíveis (como reCAPTCHA v3) incorporaram justamente a biometria comportamental de que estamos falando.
Por que isso é necessário? Os CAPTCHAs tradicionais (semáforos e caracteres distorcidos) pioram a experiência do usuário e estão sendo resolvidos com cada vez mais facilidade por redes neurais treinadas. A nova abordagem, que funciona sem elementos visíveis, remove grande parte do ônus dos usuários e evita irritá-los.
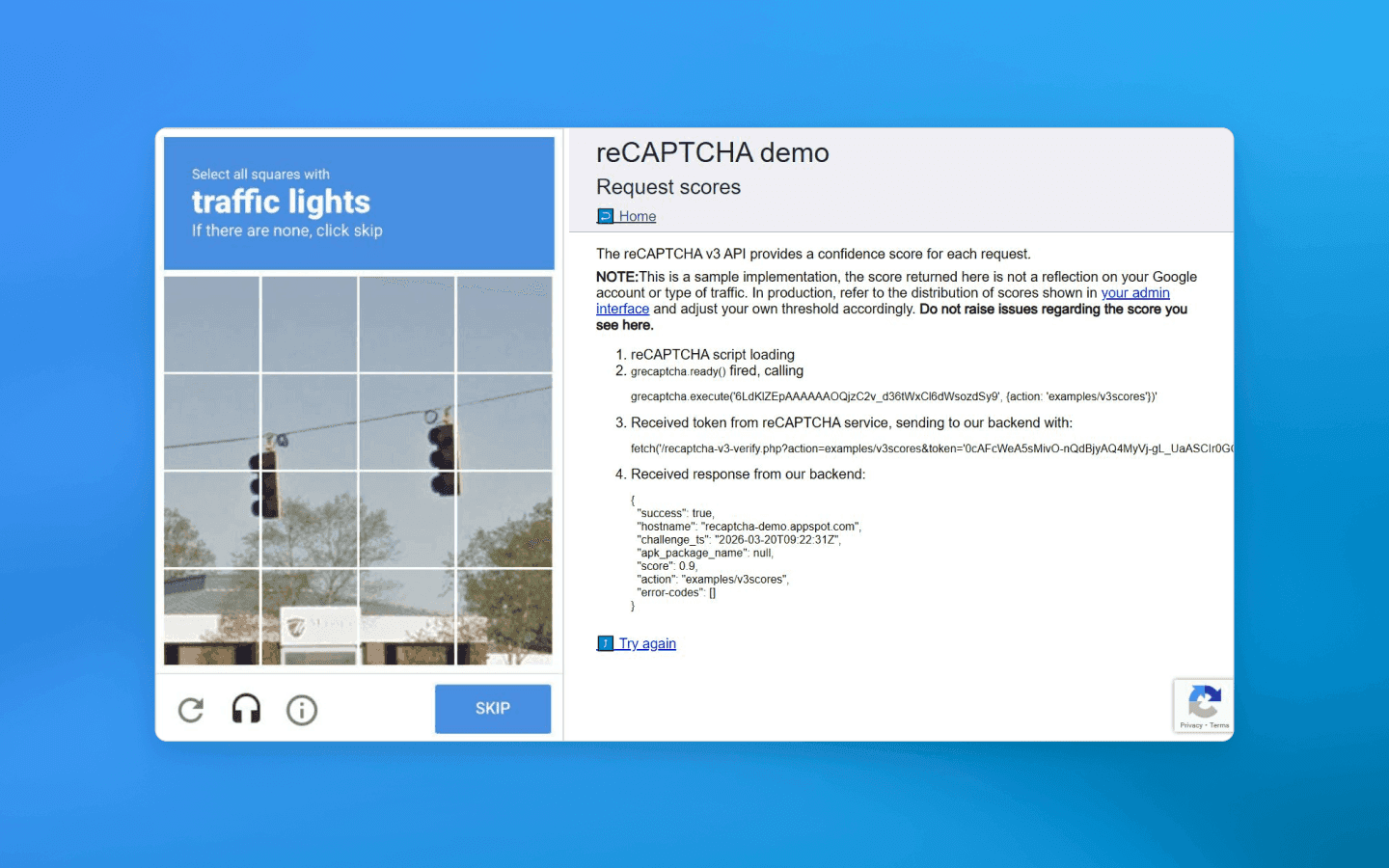
A biometria comportamental, como núcleo desse processo de verificação invisível, oferece autenticação contínua. Ela funciona analisando exatamente como um usuário interage com um dispositivo enquanto rola uma página ou preenche um formulário, sem exigir nenhuma entrada adicional.
No entanto, é importante fazer uma ressalva: a biometria comportamental não é usada como um método de verificação independente. Ela sempre funciona em conjunto com outras verificações. Além da biometria, os sistemas antifraude ainda analisam impressões digitais, reputação de IP e cookies.
Tipos de biometria comportamental
Vamos nos aprofundar na teoria. Os padrões comportamentais são, essencialmente, uma impressão digital do seu sistema nervoso transferida para um dispositivo. Os sistemas antifraude avançados não analisam parâmetros separadamente. Em vez disso, eles constroem um perfil multidimensional abrangente, que pode ser dividido nas seguintes categorias:
Interação com o dispositivo (cinestética)
Esta é a maior camada de dados para os aplicativos web e móveis tradicionais. Aqui, os sistemas analisam a física dos movimentos do usuário.
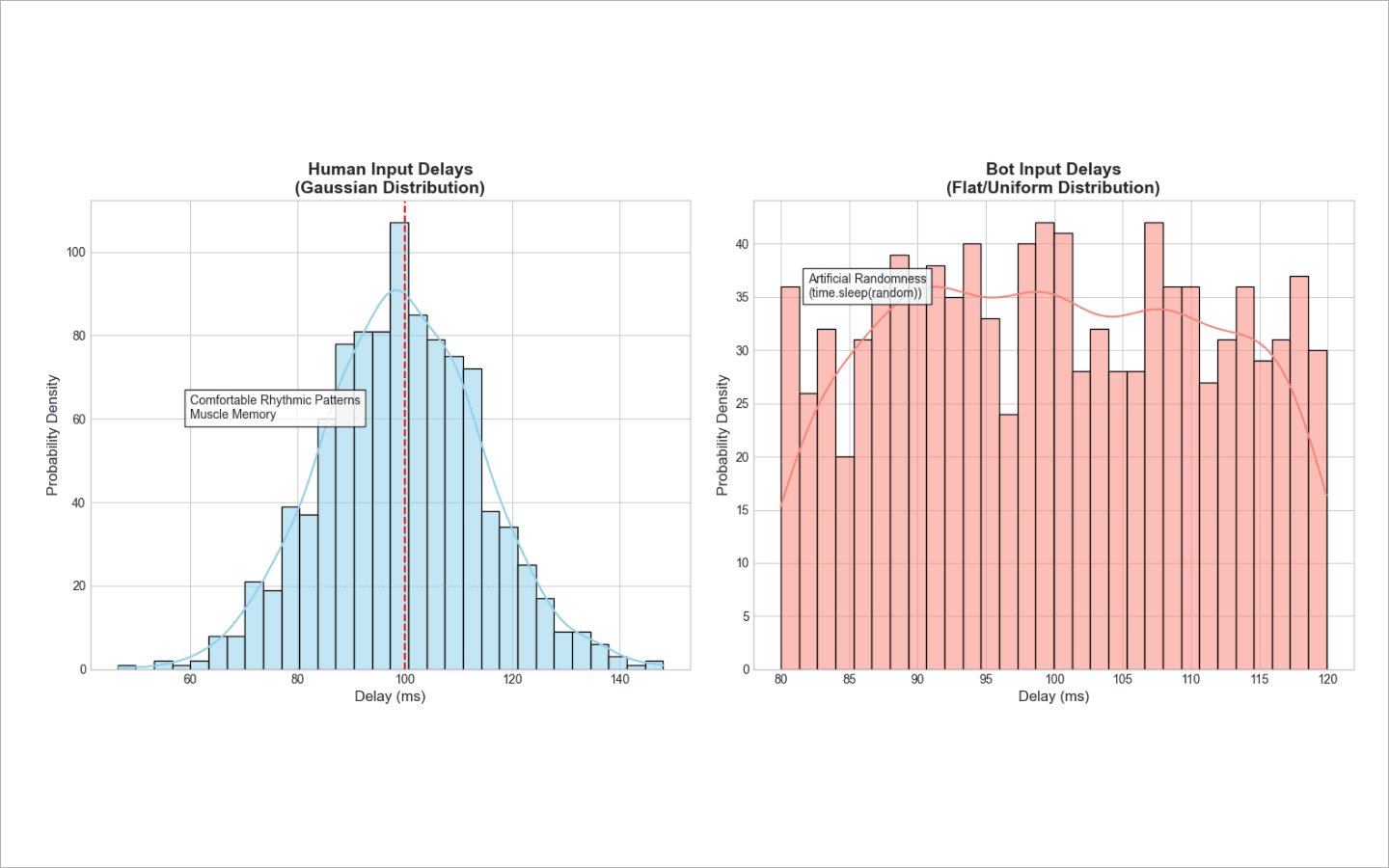
Teclado: não se trata de quais letras ou números você digita. Os sistemas antifraude avaliam dois parâmetros principais: por quanto tempo uma tecla é mantida pressionada (
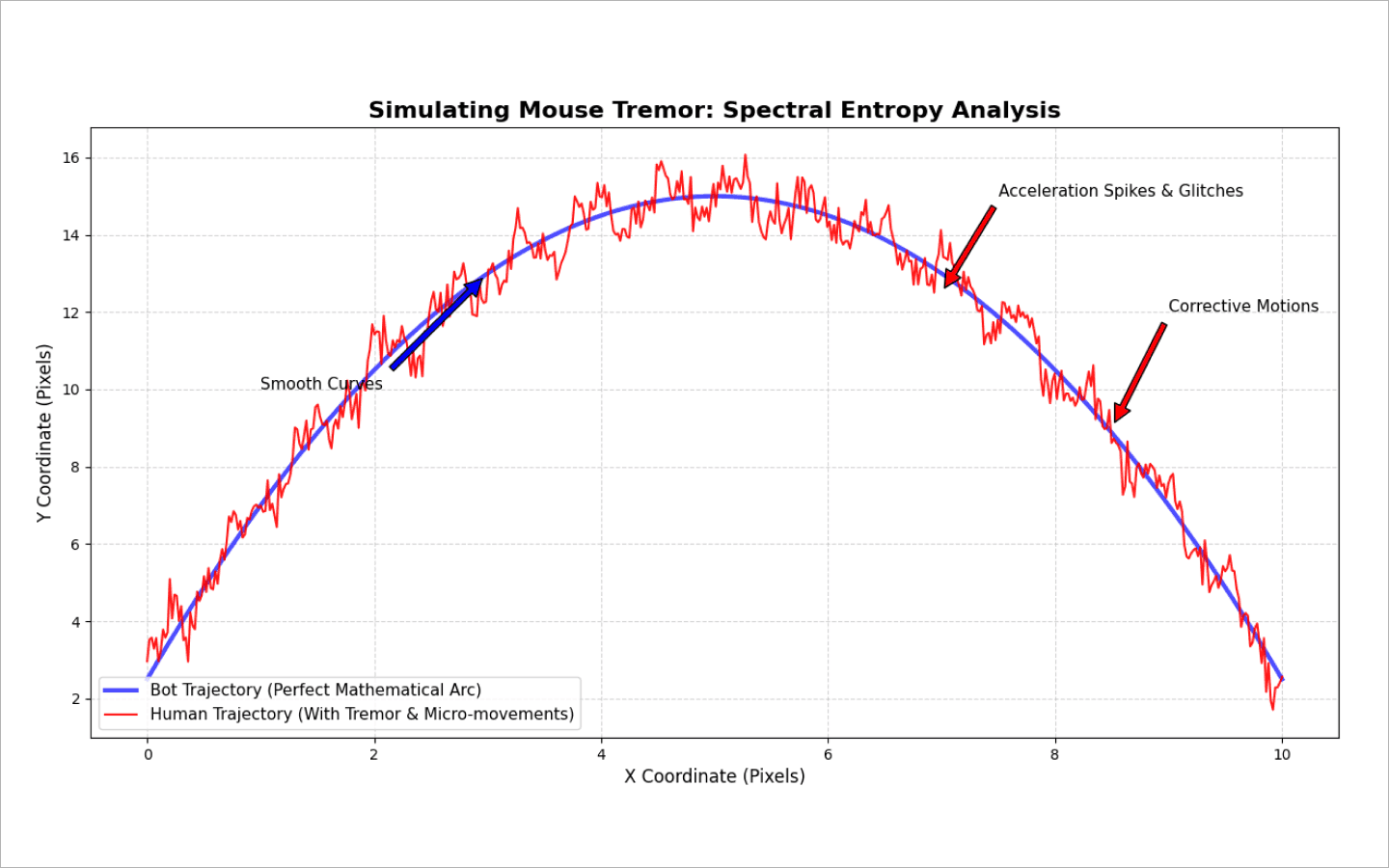
dwell time) e quanto tempo leva para se mover entre as teclas (flight time). Os humanos têm memória muscular — combinações familiares de teclas (por exemplo, finais comuns de palavras) são digitadas em microexplosões. Bots, por sua vez, ou injetam strings inteiras de uma vez ou imitam a digitação usando uma lógica simplista detime.sleep(random). Isso cria uma distribuição de atrasos plana e antinatural. A própria aleatoriedade se torna suspeita.Mouse: análise do cursor. O sistema registra coordenadas e calcula velocidade, aceleração, curvatura da trajetória e solavancos. Os humanos não movem um mouse em linhas perfeitamente retas. Miramos em um botão, erramos por alguns pixels, fazemos pequenos movimentos corretivos e pausamos brevemente antes de clicar.
Tela sensível ao toque: específica para a web móvel e para aplicativos nativos. Um swipe humano é um arco com velocidade irregular, pressão específica (se a API permitir detecção de pressão) e uma área de contato do dedo em constante mudança. Bots que emulam eventos de toque por meio de Appium ou scripts em JavaScript muitas vezes simplesmente “teletransportam” as coordenadas de foco. Escrever a matemática correta para um swipe realista é mais difícil, então os operadores de bots costumam tomar atalhos.
Padrões físicos (biomecânica)
Quando um usuário acessa uma plataforma a partir de um dispositivo móvel, os sensores de hardware entram em ação. E, como agora vivemos na era dos usuários mobile, isso importa bastante.
Padrões de caminhada e micromovimentos. Você está rolando o feed enquanto caminha, sentado em uma cadeira ou deitado no sofá? O acelerômetro e o giroscópio de um smartphone capturam constantemente pequenas vibrações do dispositivo. O telefone de um usuário real sempre treme levemente nas mãos, mesmo quando ele tenta mantê-lo perfeitamente parado. Fazendas de bots e emuladores executados em servidores geralmente não têm ruído de fundo de sensores por padrão, o que dá aos sistemas antifraude algo em que pensar e aumenta a pontuação de risco.
Padrões cognitivos (psicologia da interação)
É aqui que os sistemas analisam como o cérebro de um usuário funciona ao interagir com uma interface de usuário.
Velocidade de navegação e tomada de decisão. Com que rapidez um usuário encontra o botão necessário? Ele lê o texto antes de marcar uma caixa de seleção? As pessoas muitas vezes movem o cursor sobre o texto enquanto leem, de forma semelhante a seguir linhas em um livro com o dedo, ou fazem pausas em formulários complicados. Alguns usuários até destacam o texto. Um script de scraping, por outro lado, não tem dúvidas — ele conhece perfeitamente a estrutura do DOM e dispara o evento necessário exatamente após um timeout predefinido, ignorando completamente a lógica da busca visual.
Juntos, esses três níveis criam um perfil tão complexo que replicá-lo integralmente apenas adicionando atrasos aleatórios ao código do Selenium ou do Puppeteer se torna matematicamente impossível.
Coleta e pré-processamento de dados
As principais fontes para a coleta de dados biométricos são os eventos mousemove, keydown, keyup, touchstart e touchend, bem como a DeviceOrientation API para capturar leituras do acelerômetro e do giroscópio.
A parte mais difícil nesta etapa é lidar com o enorme volume de dados fragmentados e assíncronos. Um único evento mousemove, sozinho, pode ser disparado centenas de vezes por segundo. Se cada movimento do cursor acionasse processamento de backend ou cálculos pesados diretamente no lado do cliente, o sistema antifraude congelaria instantaneamente a UI e causaria um atraso perceptível no site do cliente. Nenhum negócio aceitaria isso.
É por isso que os scripts de coleta no lado do cliente são projetados para serem o mais leves e primitivos possível. Sua única tarefa é capturar rapidamente as coordenadas, anexar timestamps precisos, armazenar tudo em um buffer local e enviar os dados ao servidor em lote.
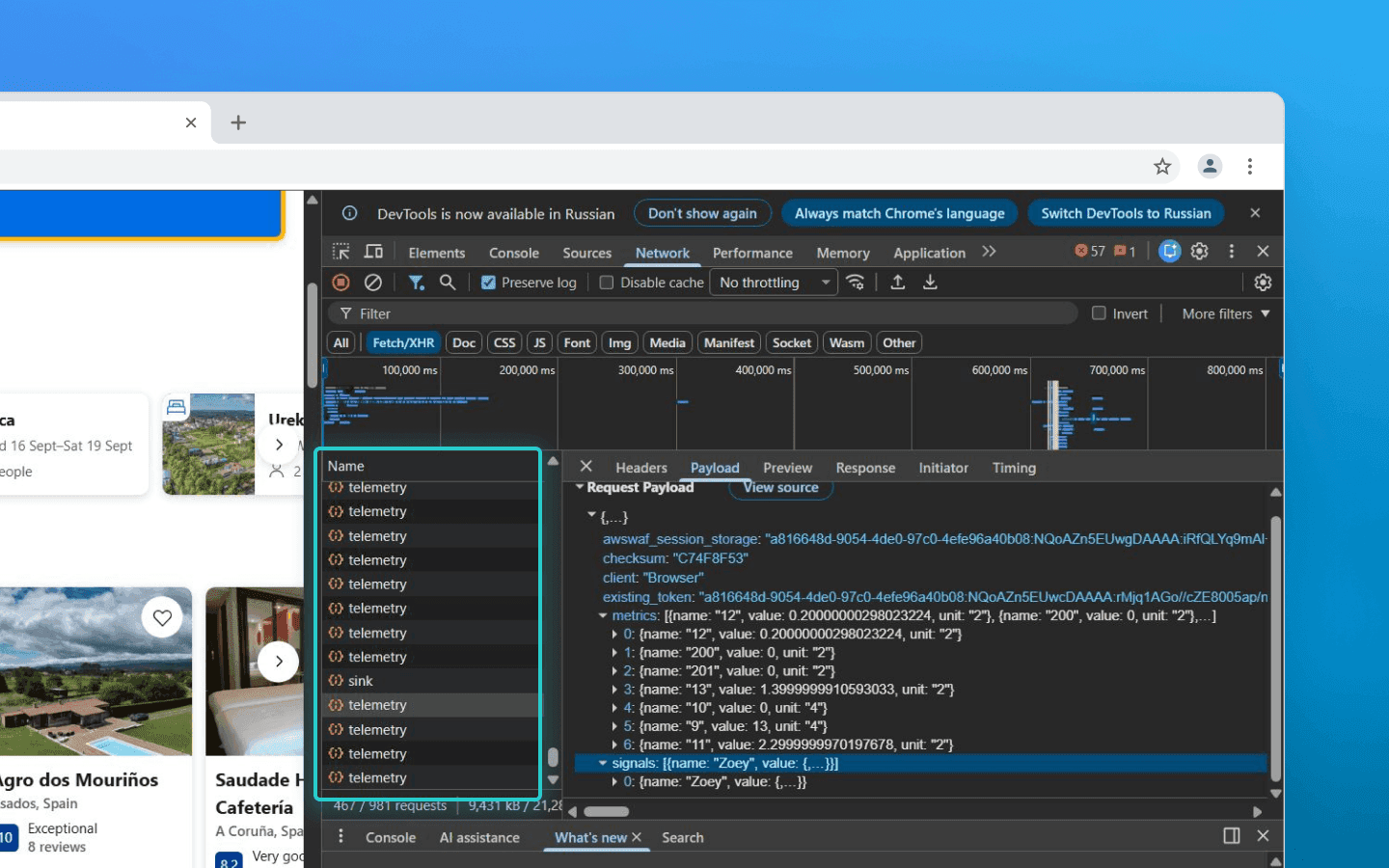
Esses lotes de objetos JSON são então transmitidos ao backend. Em sistemas de alta carga, eles não são gravados diretamente em bancos de dados nem enviados imediatamente para modelos de ML. Primeiro, são roteados por meio de message brokers como Kafka ou RabbitMQ. Isso é necessário para suavizar picos de tráfego, por exemplo, durante ataques de bots em larga escala ou aumentos naturais de usuários reais durante vendas ou promoções. Nesse ponto, a responsabilidade do lado do cliente termina.
Engenharia de features e modelos de ML
Então, os lotes brutos chegaram ao servidor. O que acontece em seguida?
Se você simplesmente alimentar esse array de pixels em um modelo de ML, ele não aprenderá a distinguir humanos de bots. Ele apenas memorizará onde os botões estão localizados no seu site e quebrará assim que o layout mudar um pouco. Os modelos de aprendizado de máquina não precisam da geografia da tela, eles precisam de abstrações comportamentais.
É por isso que existe uma camada dedicada de microsserviços chamada engenharia de features, localizada entre a fila de mensagens e as redes neurais. Normalmente, são pipelines construídos com Pandas e NumPy que agregam logs e os transformam em dados adequados para modelos de ML. Eles calculam:
distâncias euclidianas entre pontos;
diferenças de tempo;
velocidades instantâneas;
ângulos de mudança de trajetória.
Com base nesses cálculos, o sistema antifraude constrói um perfil comportamental complexo de features:
Teclado: vetores de atraso (
dwell timeeflight time), juntamente com sua mediana, variância e desvio padrão. Em outras palavras, quão consistente é o ritmo de digitação.Mouse: estatísticas de velocidade e aceleração, o número de micro-pausas e a entropia espectral da trajetória. Essa métrica mostra se o movimento parece caótico (como o de um humano) ou matematicamente perfeito (como o de um script).
Tela sensível ao toque: gradientes de pressão e mudanças na área de contato durante um swipe (nos casos em que a API do navegador ou do sistema operacional compartilha esses dados).
Features cognitivas:
idle timee atrasos antes de focar nos elementos-alvo. Por exemplo, uma pausa antes de clicar no botão “Pagar” enquanto o usuário confere mentalmente o valor.
Centenas desses parâmetros são extraídas de uma única sessão, removidas do contexto específico do layout e então repassadas aos modelos de ML.
Algoritmos clássicos de ML (Random Forest, SVM, Gradient Boosting)
Eles funcionam excepcionalmente bem com features estatísticas agregadas. Operam rapidamente, consomem recursos mínimos do servidor e normalmente são usados como a primeira e mais rápida linha de defesa.
Essencialmente, eles passam todo o vetor de estatísticas da sessão (velocidade da ação, variância temporal, entropia e assim por diante) por um sistema de limiares matemáticos cuidadosamente calibrados, filtrando instantaneamente anomalias óbvias, como variância zero na aceleração do cursor ou intervalos de clique anormalmente consistentes.
Redes neurais (LSTM, GRU e 1D-CNN)
Enquanto os algoritmos clássicos se concentram no panorama estatístico geral, as redes neurais recorrentes analisam a sequência real dos movimentos do cursor ao longo do tempo.
As redes recorrentes são projetadas para processar dados sequenciais (texto, fala, séries temporais), nos quais o contexto dos elementos anteriores importa. Ao contrário das redes tradicionais, as arquiteturas recorrentes têm “memória” por meio de loops de feedback, permitindo que levem em conta informações de passos anteriores. Como resultado, elas conseguem detectar padrões e ritmos antinaturais que ficam ocultos pela média estatística comum.
Autoencoders e detecção de anomalias
O maior desafio para os sistemas antifraude é que os desenvolvedores de bots inventam constantemente novas técnicas de spoofing. Treinar um modelo para cada bot existente é impossível, mas há milhões de sessões geradas por humanos reais. É por isso que o aprendizado não supervisionado, especialmente os autoencoders, é amplamente utilizado.
Um autoencoder é uma rede neural treinada exclusivamente com comportamento humano. Ele funciona como um filtro especializado: recebe os parâmetros da sessão como entrada, comprime-os matematicamente em uma representação compacta e depois tenta reconstruir os dados originais.
Como essa rede só viu sessões humanas genuínas, ela aprendeu a física do movimento humano com precisão quase perfeita e consegue reconstruir esses dados quase sem falhas. Mas, se o comportamento de um bot nunca visto antes — por mais sofisticado que seja — for alimentado no modelo, a rede tentará aplicar a ele regras de compressão humanas. Como resultado, a etapa de reconstrução produzirá uma saída imprecisa.
Quando há uma grande discrepância entre os dados originais e o que a rede conseguiu reconstruir, isso se torna um erro de reconstrução. Quanto maior o erro, maior a pontuação de risco, sinalizando comportamento anômalo.
Verificações de método único vs. sistemas híbridos
Confiar em apenas um tipo de verificação é ineficaz, e é por isso que ninguém usa um único modelo. Na maioria dos casos, a arquitetura é construída como uma cascata: algoritmos leves de ML podem filtrar instantaneamente até 90% dos scripts e bots simples, enquanto redes neurais mais pesadas são ativadas apenas para casos limítrofes em que as verificações anteriores produziram resultados incertos. Essa abordagem reduz significativamente os custos computacionais.
Deriva de características e adaptação
O comportamento humano real pode mudar ao longo do tempo, assim como a impressão digital do dispositivo. Um usuário pode comprar um mouse novo com configurações de DPI diferentes, trocar um computador desktop por um laptop com touchpad, machucar a mão, tomar um duplo espresso ou simplesmente ficar exausto no fim do dia de trabalho. Tudo isso altera instantaneamente o ritmo de digitação, o controle motor fino e a velocidade de reação.
Se um modelo antifraude é estático e depende de um perfil de referência coletado anos atrás, ele inevitavelmente começará a bloquear usuários legítimos. A porcentagem de falsos positivos aumentará, as taxas de conversão cairão e as empresas perderão receita e fidelidade do cliente.
Como resultado, os sistemas antifraude precisam evoluir continuamente junto com os usuários e se adaptar às condições em mudança.
Treinamento em tempo real de redes neurais
Ao contrário do treinamento em lote tradicional, em que um modelo é re-treinado uma vez por mês em um grande conjunto de dados acumulados, o aprendizado online permite que o algoritmo ajuste seus pesos continuamente em tempo real. Assim que uma sessão válida termina — confirmada, por exemplo, por uma compra ou por uma verificação 2FA bem-sucedida — suas features alteram levemente os limiares de decisão do modelo. Isso leva perfeitamente em conta mudanças graduais nos hábitos do usuário.
Janela deslizante de memória
Os algoritmos também dependem do princípio da janela deslizante de memória: dados recentes da sessão são constantemente adicionados ao perfil comportamental de referência e recebem o maior peso matemático. Registros mais antigos gradualmente perdem influência até que sua contribuição se aproxime de zero. O sistema sempre compara o comportamento atual com a forma como o usuário agiu nas últimas semanas, e não com o momento em que a conta foi criada anos atrás.
Monitoramento estatístico
Mas como o sistema distingue entre uma mudança legítima, como comprar um mouse novo, e um spoofing repentino de sessão por um bot sofisticado? Para isso, é aplicado um monitoramento estatístico rigoroso, incluindo:
Análise de Componentes Principais (PCA). Esse método projeta dezenas de features em um espaço 2D ou 3D e acompanha a deriva dos clusters. Se sessões novas se desviarem repentinamente do núcleo comportamental histórico do usuário, o sistema detecta a deriva.
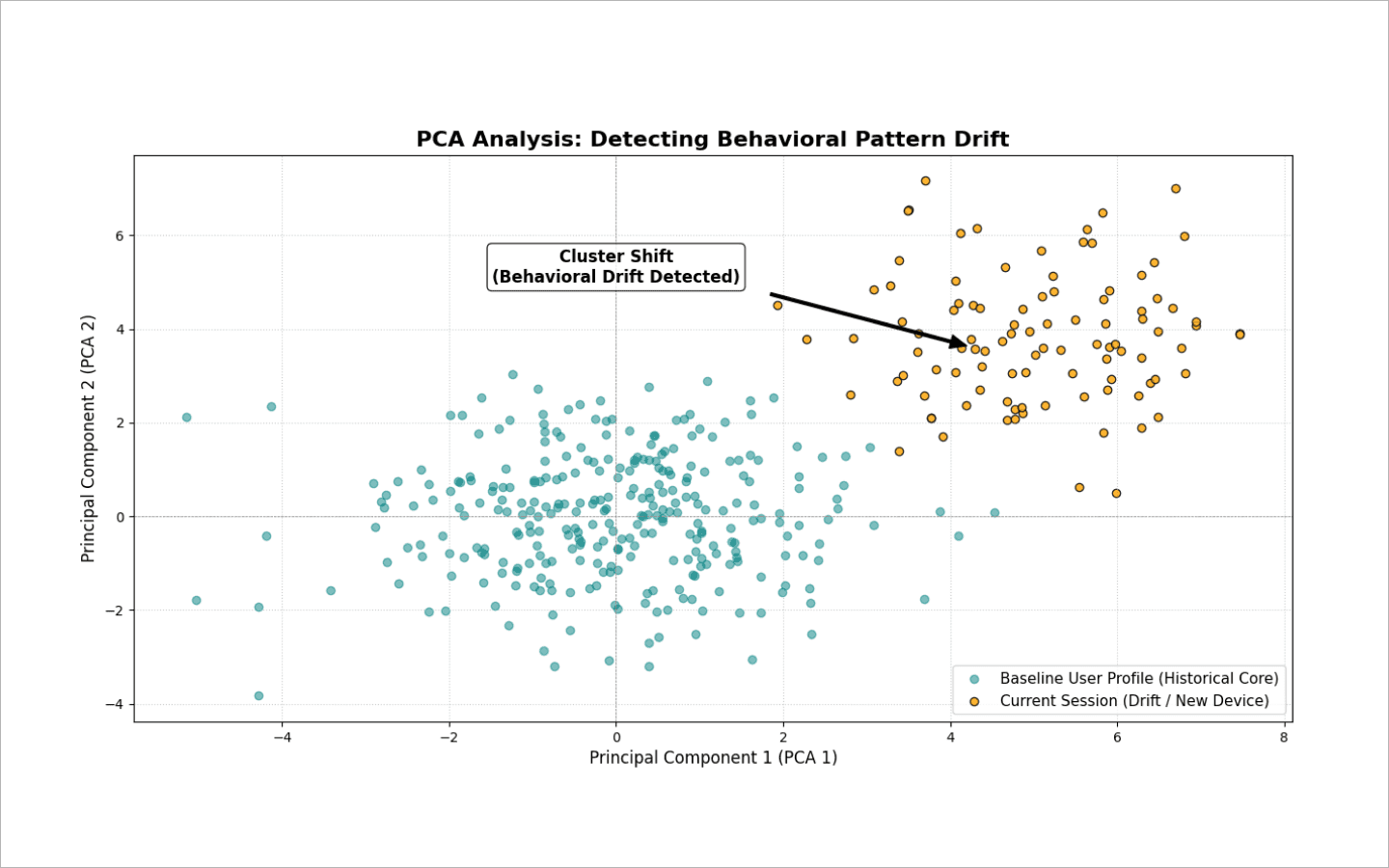
Testes estatísticos (como o teste de Kolmogorov–Smirnov). O algoritmo compara continuamente a distribuição dos novos dados com a distribuição de referência. Se for detectada divergência entre as duas amostras, o sistema reduz temporariamente a confiança no perfil. Nessa etapa, o usuário não é banido, mas recebe a solicitação para concluir um CAPTCHA. Se a verificação for concluída com sucesso, o modelo interpreta o desvio como legítimo — por exemplo, uma troca para um novo dispositivo — e atualiza o perfil de referência de acordo com isso.
Emulação do comportamento humano
Agora que entendemos como os algoritmos antifraude funcionam, vamos descobrir como treinar um bot para se comportar como um humano.
Apenas suavizar o movimento do cursor com curvas de Bézier ou adicionar chamadas de time.sleep() já não basta: os modelos de ML conseguem detectar automação em apenas alguns cliques. Para que um emulador realmente se pareça com um humano, ele precisa incorporar as leis da fisiologia e da biomecânica.
Injeção de jitter
Se você instruir um script a fazer pausas aleatórias de 80 a 120 milissegundos, ele gerará atrasos de 80 ms, 120 ms e 95 ms com aproximadamente a mesma frequência.
Os humanos não digitam assim. Cada um de nós tem um ritmo natural e confortável, no qual caímos na maior parte do tempo. Às vezes, nossos dedos aceleram ou desaceleram um pouco. É por isso que os atrasos devem ser gerados de acordo com uma distribuição Gaussiana (curva em sino). A grande maioria das pausas de um bot deve se concentrar em uma única velocidade-base, enquanto apenas algumas poucas variações devem se diferenciar de forma significativa em qualquer direção.
Emulação de tremor
Imagine tentar clicar rapidamente em uma pequena caixa de seleção. Você move o mouse de forma brusca, ultrapassa o alvo por alguns pixels, percebe o erro e puxa o cursor de volta.
Para imitar esse efeito e a tremedeira natural da mão humana, os desenvolvedores misturam funções matemáticas (ondas seno e cosseno) na trajetória ideal do cursor. Isso cria um micro-ruído realista capaz de enganar os sistemas antifraude.
Macro-pausas
Uma das técnicas mais avançadas e raramente implementadas é a introdução de macro-pausas que imitam ciclos fisiológicos. Os humanos não trabalham continuamente em um computador. Piscamos, perdendo temporariamente o contato visual com a tela, respiramos, olhamos para baixo para o teclado ou nos distraímos com nossos celulares.
Um emulador deve, portanto, incluir uma lógica de “perda de foco” — atrasos artificiais periódicos de 1 a 3 segundos antes de ações importantes, quebrando a monotonia mecânica.
Cópia de comportamento
Por que escrever modelos matemáticos complicados do zero para gerar o movimento de rolagem perfeito, com desaceleração natural e microsolavancos, quando você pode simplesmente usar um real? Essa abordagem é chamada de blending e leva a emulação a um nível totalmente novo.
Desenvolvedores avançados de bots criam seus próprios bancos de dados ou compram conjuntos prontos. Esses conjuntos de dados contêm sessões reais de usuários ao vivo: como as pessoas rolam feeds, movem o cursor enquanto leem texto ou deslocam o mouse inconscientemente enquanto pensam. Essas gravações são armazenadas como matrizes contendo vetores de movimento e dados de microtempo.
Quando um script construído com essa tecnologia precisa rolar uma página ou mover um cursor em direção a um formulário complexo, ele não usa window.scrollBy() nem curvas de Bézier. Em vez disso, ele recupera do banco de dados um fragmento adequado de um registro real de interação humana. A trajetória então é moldada: o script deforma matematicamente esse “instantâneo” para que ele se encaixe nas coordenadas atuais do navegador. Os vetores são deslocados apenas o suficiente para que o cursor termine sobre o botão necessário, após o que o controle é devolvido sem interrupções ao bot para o clique final.
Os modelos de ML antifraude percebem esses movimentos como ruído perfeito de alta frequência, tremor totalmente natural e micro-pausas realistas. Como resultado, eles permitem que o script funcione porque os dados subjacentes realmente se originaram de um humano vivo.
Qual é o problema? Para que esse método funcione em escala, o desenvolvedor do bot precisa de uma biblioteca realmente enorme de “instantâneos” comportamentais. Se o mesmo fragmento de rolagem for reutilizado por vários bots, os sistemas antifraude do lado do servidor detectarão rapidamente o duplicado matemático (acionando a proteção básica contra replay attack) e banirão toda a fazenda.
A vulnerabilidade dos loops
Não importa o quanto você randomize os timings e sacuda o cursor, todo bot sofre de uma fraqueza congênita: ele vive dentro de um loop programático (while ou for).
Os sistemas de proteção pegam os timings do seu script e os passam por análise espectral (transformada de Fourier). Isso filtra o ruído aleatório artificial e revela a frequência portadora oculta do loop. Os humanos são naturalmente arrítmicos; os bots, não.
Você consegue derrotar a análise de Fourier e convencer o servidor de que seu script é um humano vivo, sem frequência base detectável? Sim, mas fazer isso exige reescrever toda a arquitetura do seu scraper. Um simples Math.random() está muito longe de ser suficiente para isso.
Abandonar loops em favor de State Machines. Não use loops lineares
whileouforcombinados com chamadas aninhadas desleep(). Seu bot deve funcionar como uma máquina de estados finita orientada por eventos. Ele deve ter múltiplos estados, por exemplo, leitura, hesitação ou ociosidade, movimento e clique. As transições entre esses estados não devem ser rigidamente codificadas, mas determinadas probabilisticamente. Só então o ritmo geral da sessão se tornará imprevisível, como o de um humano que pode mudar de ideia de repente antes de clicar em um botão.A matemática das “heavy tails”. Esqueça a aleatoriedade uniforme ou mesmo distribuições Gaussianas. A maioria das suas pausas deve ser curta e bem concentrada, mas o bot deve ocasionalmente parar por um tempo anormalmente longo com certa probabilidade. Esses outliers raros, porém extremos, são justamente o que interrompe a análise de frequência de Fourier, borrando o espectro e escondendo o ritmo da máquina.
Uso da entropia do sistema operacional. Os geradores de números pseudorrandômicos embutidos em JavaScript ou Python têm seus próprios padrões previsíveis. Em vez disso, você pode extrair entropia real diretamente do sistema operacional, que coleta ruído caótico do hardware, desde flutuações na temperatura da CPU até interrupções de rede.
Conclusão: a economia do scraping e o jogo sem fim
A biometria comportamental não se tornou uma solução milagrosa contra bots. No entanto, ela mudou fundamentalmente tanto as regras do jogo quanto a economia da automação.
Antes, construir um scraper bem-sucedido exigia pouco mais do que comprar um lote de proxies e entender os cabeçalhos do navegador. Hoje, os desenvolvedores de automação precisam de conhecimento que se estende à biomecânica e às transformadas de Fourier. É claro que isso se aplica a projetos de grande porte, e não simplesmente à extração de fotos do Google Maps.
A corrida armamentista entre os sistemas antifraude e os desenvolvedores de bots continua, mas agora em um novo campo de batalha: a imitação do sistema nervoso humano. As soluções antifraude continuarão introduzindo métodos de verificação cada vez mais sofisticados, enquanto os scrapers aprenderão a “respirar” e procrastinar de forma ainda mais convincente.
Mantenha o anonimato, aproveite o recurso multiconta e alcance seus objetivos com o melhor navegador antidetecção do mercado.
Você gostaria de experimentar o Octo Browser com desconto?
Use o código promocional OCTOSCRAPER para obter 30% de desconto em qualquer assinatura. Esta oferta é válida apenas para novos usuários.
Por que os CAPTCHAs estão dando lugar à análise comportamental
Antes, o CAPTCHA era o principal mecanismo de defesa contra bots. Os CAPTCHAs ainda existem hoje, embora tenham mudado significativamente. Eles se tornaram mais sofisticados, e algumas versões modernas e invisíveis (como reCAPTCHA v3) incorporaram justamente a biometria comportamental de que estamos falando.
Por que isso é necessário? Os CAPTCHAs tradicionais (semáforos e caracteres distorcidos) pioram a experiência do usuário e estão sendo resolvidos com cada vez mais facilidade por redes neurais treinadas. A nova abordagem, que funciona sem elementos visíveis, remove grande parte do ônus dos usuários e evita irritá-los.
A biometria comportamental, como núcleo desse processo de verificação invisível, oferece autenticação contínua. Ela funciona analisando exatamente como um usuário interage com um dispositivo enquanto rola uma página ou preenche um formulário, sem exigir nenhuma entrada adicional.
No entanto, é importante fazer uma ressalva: a biometria comportamental não é usada como um método de verificação independente. Ela sempre funciona em conjunto com outras verificações. Além da biometria, os sistemas antifraude ainda analisam impressões digitais, reputação de IP e cookies.
Tipos de biometria comportamental
Vamos nos aprofundar na teoria. Os padrões comportamentais são, essencialmente, uma impressão digital do seu sistema nervoso transferida para um dispositivo. Os sistemas antifraude avançados não analisam parâmetros separadamente. Em vez disso, eles constroem um perfil multidimensional abrangente, que pode ser dividido nas seguintes categorias:
Interação com o dispositivo (cinestética)
Esta é a maior camada de dados para os aplicativos web e móveis tradicionais. Aqui, os sistemas analisam a física dos movimentos do usuário.
Teclado: não se trata de quais letras ou números você digita. Os sistemas antifraude avaliam dois parâmetros principais: por quanto tempo uma tecla é mantida pressionada (
dwell time) e quanto tempo leva para se mover entre as teclas (flight time). Os humanos têm memória muscular — combinações familiares de teclas (por exemplo, finais comuns de palavras) são digitadas em microexplosões. Bots, por sua vez, ou injetam strings inteiras de uma vez ou imitam a digitação usando uma lógica simplista detime.sleep(random). Isso cria uma distribuição de atrasos plana e antinatural. A própria aleatoriedade se torna suspeita.Mouse: análise do cursor. O sistema registra coordenadas e calcula velocidade, aceleração, curvatura da trajetória e solavancos. Os humanos não movem um mouse em linhas perfeitamente retas. Miramos em um botão, erramos por alguns pixels, fazemos pequenos movimentos corretivos e pausamos brevemente antes de clicar.
Tela sensível ao toque: específica para a web móvel e para aplicativos nativos. Um swipe humano é um arco com velocidade irregular, pressão específica (se a API permitir detecção de pressão) e uma área de contato do dedo em constante mudança. Bots que emulam eventos de toque por meio de Appium ou scripts em JavaScript muitas vezes simplesmente “teletransportam” as coordenadas de foco. Escrever a matemática correta para um swipe realista é mais difícil, então os operadores de bots costumam tomar atalhos.
Padrões físicos (biomecânica)
Quando um usuário acessa uma plataforma a partir de um dispositivo móvel, os sensores de hardware entram em ação. E, como agora vivemos na era dos usuários mobile, isso importa bastante.
Padrões de caminhada e micromovimentos. Você está rolando o feed enquanto caminha, sentado em uma cadeira ou deitado no sofá? O acelerômetro e o giroscópio de um smartphone capturam constantemente pequenas vibrações do dispositivo. O telefone de um usuário real sempre treme levemente nas mãos, mesmo quando ele tenta mantê-lo perfeitamente parado. Fazendas de bots e emuladores executados em servidores geralmente não têm ruído de fundo de sensores por padrão, o que dá aos sistemas antifraude algo em que pensar e aumenta a pontuação de risco.
Padrões cognitivos (psicologia da interação)
É aqui que os sistemas analisam como o cérebro de um usuário funciona ao interagir com uma interface de usuário.
Velocidade de navegação e tomada de decisão. Com que rapidez um usuário encontra o botão necessário? Ele lê o texto antes de marcar uma caixa de seleção? As pessoas muitas vezes movem o cursor sobre o texto enquanto leem, de forma semelhante a seguir linhas em um livro com o dedo, ou fazem pausas em formulários complicados. Alguns usuários até destacam o texto. Um script de scraping, por outro lado, não tem dúvidas — ele conhece perfeitamente a estrutura do DOM e dispara o evento necessário exatamente após um timeout predefinido, ignorando completamente a lógica da busca visual.
Juntos, esses três níveis criam um perfil tão complexo que replicá-lo integralmente apenas adicionando atrasos aleatórios ao código do Selenium ou do Puppeteer se torna matematicamente impossível.
Coleta e pré-processamento de dados
As principais fontes para a coleta de dados biométricos são os eventos mousemove, keydown, keyup, touchstart e touchend, bem como a DeviceOrientation API para capturar leituras do acelerômetro e do giroscópio.
A parte mais difícil nesta etapa é lidar com o enorme volume de dados fragmentados e assíncronos. Um único evento mousemove, sozinho, pode ser disparado centenas de vezes por segundo. Se cada movimento do cursor acionasse processamento de backend ou cálculos pesados diretamente no lado do cliente, o sistema antifraude congelaria instantaneamente a UI e causaria um atraso perceptível no site do cliente. Nenhum negócio aceitaria isso.
É por isso que os scripts de coleta no lado do cliente são projetados para serem o mais leves e primitivos possível. Sua única tarefa é capturar rapidamente as coordenadas, anexar timestamps precisos, armazenar tudo em um buffer local e enviar os dados ao servidor em lote.
Esses lotes de objetos JSON são então transmitidos ao backend. Em sistemas de alta carga, eles não são gravados diretamente em bancos de dados nem enviados imediatamente para modelos de ML. Primeiro, são roteados por meio de message brokers como Kafka ou RabbitMQ. Isso é necessário para suavizar picos de tráfego, por exemplo, durante ataques de bots em larga escala ou aumentos naturais de usuários reais durante vendas ou promoções. Nesse ponto, a responsabilidade do lado do cliente termina.
Engenharia de features e modelos de ML
Então, os lotes brutos chegaram ao servidor. O que acontece em seguida?
Se você simplesmente alimentar esse array de pixels em um modelo de ML, ele não aprenderá a distinguir humanos de bots. Ele apenas memorizará onde os botões estão localizados no seu site e quebrará assim que o layout mudar um pouco. Os modelos de aprendizado de máquina não precisam da geografia da tela, eles precisam de abstrações comportamentais.
É por isso que existe uma camada dedicada de microsserviços chamada engenharia de features, localizada entre a fila de mensagens e as redes neurais. Normalmente, são pipelines construídos com Pandas e NumPy que agregam logs e os transformam em dados adequados para modelos de ML. Eles calculam:
distâncias euclidianas entre pontos;
diferenças de tempo;
velocidades instantâneas;
ângulos de mudança de trajetória.
Com base nesses cálculos, o sistema antifraude constrói um perfil comportamental complexo de features:
Teclado: vetores de atraso (
dwell timeeflight time), juntamente com sua mediana, variância e desvio padrão. Em outras palavras, quão consistente é o ritmo de digitação.Mouse: estatísticas de velocidade e aceleração, o número de micro-pausas e a entropia espectral da trajetória. Essa métrica mostra se o movimento parece caótico (como o de um humano) ou matematicamente perfeito (como o de um script).
Tela sensível ao toque: gradientes de pressão e mudanças na área de contato durante um swipe (nos casos em que a API do navegador ou do sistema operacional compartilha esses dados).
Features cognitivas:
idle timee atrasos antes de focar nos elementos-alvo. Por exemplo, uma pausa antes de clicar no botão “Pagar” enquanto o usuário confere mentalmente o valor.
Centenas desses parâmetros são extraídas de uma única sessão, removidas do contexto específico do layout e então repassadas aos modelos de ML.
Algoritmos clássicos de ML (Random Forest, SVM, Gradient Boosting)
Eles funcionam excepcionalmente bem com features estatísticas agregadas. Operam rapidamente, consomem recursos mínimos do servidor e normalmente são usados como a primeira e mais rápida linha de defesa.
Essencialmente, eles passam todo o vetor de estatísticas da sessão (velocidade da ação, variância temporal, entropia e assim por diante) por um sistema de limiares matemáticos cuidadosamente calibrados, filtrando instantaneamente anomalias óbvias, como variância zero na aceleração do cursor ou intervalos de clique anormalmente consistentes.
Redes neurais (LSTM, GRU e 1D-CNN)
Enquanto os algoritmos clássicos se concentram no panorama estatístico geral, as redes neurais recorrentes analisam a sequência real dos movimentos do cursor ao longo do tempo.
As redes recorrentes são projetadas para processar dados sequenciais (texto, fala, séries temporais), nos quais o contexto dos elementos anteriores importa. Ao contrário das redes tradicionais, as arquiteturas recorrentes têm “memória” por meio de loops de feedback, permitindo que levem em conta informações de passos anteriores. Como resultado, elas conseguem detectar padrões e ritmos antinaturais que ficam ocultos pela média estatística comum.
Autoencoders e detecção de anomalias
O maior desafio para os sistemas antifraude é que os desenvolvedores de bots inventam constantemente novas técnicas de spoofing. Treinar um modelo para cada bot existente é impossível, mas há milhões de sessões geradas por humanos reais. É por isso que o aprendizado não supervisionado, especialmente os autoencoders, é amplamente utilizado.
Um autoencoder é uma rede neural treinada exclusivamente com comportamento humano. Ele funciona como um filtro especializado: recebe os parâmetros da sessão como entrada, comprime-os matematicamente em uma representação compacta e depois tenta reconstruir os dados originais.
Como essa rede só viu sessões humanas genuínas, ela aprendeu a física do movimento humano com precisão quase perfeita e consegue reconstruir esses dados quase sem falhas. Mas, se o comportamento de um bot nunca visto antes — por mais sofisticado que seja — for alimentado no modelo, a rede tentará aplicar a ele regras de compressão humanas. Como resultado, a etapa de reconstrução produzirá uma saída imprecisa.
Quando há uma grande discrepância entre os dados originais e o que a rede conseguiu reconstruir, isso se torna um erro de reconstrução. Quanto maior o erro, maior a pontuação de risco, sinalizando comportamento anômalo.
Verificações de método único vs. sistemas híbridos
Confiar em apenas um tipo de verificação é ineficaz, e é por isso que ninguém usa um único modelo. Na maioria dos casos, a arquitetura é construída como uma cascata: algoritmos leves de ML podem filtrar instantaneamente até 90% dos scripts e bots simples, enquanto redes neurais mais pesadas são ativadas apenas para casos limítrofes em que as verificações anteriores produziram resultados incertos. Essa abordagem reduz significativamente os custos computacionais.
Deriva de características e adaptação
O comportamento humano real pode mudar ao longo do tempo, assim como a impressão digital do dispositivo. Um usuário pode comprar um mouse novo com configurações de DPI diferentes, trocar um computador desktop por um laptop com touchpad, machucar a mão, tomar um duplo espresso ou simplesmente ficar exausto no fim do dia de trabalho. Tudo isso altera instantaneamente o ritmo de digitação, o controle motor fino e a velocidade de reação.
Se um modelo antifraude é estático e depende de um perfil de referência coletado anos atrás, ele inevitavelmente começará a bloquear usuários legítimos. A porcentagem de falsos positivos aumentará, as taxas de conversão cairão e as empresas perderão receita e fidelidade do cliente.
Como resultado, os sistemas antifraude precisam evoluir continuamente junto com os usuários e se adaptar às condições em mudança.
Treinamento em tempo real de redes neurais
Ao contrário do treinamento em lote tradicional, em que um modelo é re-treinado uma vez por mês em um grande conjunto de dados acumulados, o aprendizado online permite que o algoritmo ajuste seus pesos continuamente em tempo real. Assim que uma sessão válida termina — confirmada, por exemplo, por uma compra ou por uma verificação 2FA bem-sucedida — suas features alteram levemente os limiares de decisão do modelo. Isso leva perfeitamente em conta mudanças graduais nos hábitos do usuário.
Janela deslizante de memória
Os algoritmos também dependem do princípio da janela deslizante de memória: dados recentes da sessão são constantemente adicionados ao perfil comportamental de referência e recebem o maior peso matemático. Registros mais antigos gradualmente perdem influência até que sua contribuição se aproxime de zero. O sistema sempre compara o comportamento atual com a forma como o usuário agiu nas últimas semanas, e não com o momento em que a conta foi criada anos atrás.
Monitoramento estatístico
Mas como o sistema distingue entre uma mudança legítima, como comprar um mouse novo, e um spoofing repentino de sessão por um bot sofisticado? Para isso, é aplicado um monitoramento estatístico rigoroso, incluindo:
Análise de Componentes Principais (PCA). Esse método projeta dezenas de features em um espaço 2D ou 3D e acompanha a deriva dos clusters. Se sessões novas se desviarem repentinamente do núcleo comportamental histórico do usuário, o sistema detecta a deriva.
Testes estatísticos (como o teste de Kolmogorov–Smirnov). O algoritmo compara continuamente a distribuição dos novos dados com a distribuição de referência. Se for detectada divergência entre as duas amostras, o sistema reduz temporariamente a confiança no perfil. Nessa etapa, o usuário não é banido, mas recebe a solicitação para concluir um CAPTCHA. Se a verificação for concluída com sucesso, o modelo interpreta o desvio como legítimo — por exemplo, uma troca para um novo dispositivo — e atualiza o perfil de referência de acordo com isso.
Emulação do comportamento humano
Agora que entendemos como os algoritmos antifraude funcionam, vamos descobrir como treinar um bot para se comportar como um humano.
Apenas suavizar o movimento do cursor com curvas de Bézier ou adicionar chamadas de time.sleep() já não basta: os modelos de ML conseguem detectar automação em apenas alguns cliques. Para que um emulador realmente se pareça com um humano, ele precisa incorporar as leis da fisiologia e da biomecânica.
Injeção de jitter
Se você instruir um script a fazer pausas aleatórias de 80 a 120 milissegundos, ele gerará atrasos de 80 ms, 120 ms e 95 ms com aproximadamente a mesma frequência.
Os humanos não digitam assim. Cada um de nós tem um ritmo natural e confortável, no qual caímos na maior parte do tempo. Às vezes, nossos dedos aceleram ou desaceleram um pouco. É por isso que os atrasos devem ser gerados de acordo com uma distribuição Gaussiana (curva em sino). A grande maioria das pausas de um bot deve se concentrar em uma única velocidade-base, enquanto apenas algumas poucas variações devem se diferenciar de forma significativa em qualquer direção.
Emulação de tremor
Imagine tentar clicar rapidamente em uma pequena caixa de seleção. Você move o mouse de forma brusca, ultrapassa o alvo por alguns pixels, percebe o erro e puxa o cursor de volta.
Para imitar esse efeito e a tremedeira natural da mão humana, os desenvolvedores misturam funções matemáticas (ondas seno e cosseno) na trajetória ideal do cursor. Isso cria um micro-ruído realista capaz de enganar os sistemas antifraude.
Macro-pausas
Uma das técnicas mais avançadas e raramente implementadas é a introdução de macro-pausas que imitam ciclos fisiológicos. Os humanos não trabalham continuamente em um computador. Piscamos, perdendo temporariamente o contato visual com a tela, respiramos, olhamos para baixo para o teclado ou nos distraímos com nossos celulares.
Um emulador deve, portanto, incluir uma lógica de “perda de foco” — atrasos artificiais periódicos de 1 a 3 segundos antes de ações importantes, quebrando a monotonia mecânica.
Cópia de comportamento
Por que escrever modelos matemáticos complicados do zero para gerar o movimento de rolagem perfeito, com desaceleração natural e microsolavancos, quando você pode simplesmente usar um real? Essa abordagem é chamada de blending e leva a emulação a um nível totalmente novo.
Desenvolvedores avançados de bots criam seus próprios bancos de dados ou compram conjuntos prontos. Esses conjuntos de dados contêm sessões reais de usuários ao vivo: como as pessoas rolam feeds, movem o cursor enquanto leem texto ou deslocam o mouse inconscientemente enquanto pensam. Essas gravações são armazenadas como matrizes contendo vetores de movimento e dados de microtempo.
Quando um script construído com essa tecnologia precisa rolar uma página ou mover um cursor em direção a um formulário complexo, ele não usa window.scrollBy() nem curvas de Bézier. Em vez disso, ele recupera do banco de dados um fragmento adequado de um registro real de interação humana. A trajetória então é moldada: o script deforma matematicamente esse “instantâneo” para que ele se encaixe nas coordenadas atuais do navegador. Os vetores são deslocados apenas o suficiente para que o cursor termine sobre o botão necessário, após o que o controle é devolvido sem interrupções ao bot para o clique final.
Os modelos de ML antifraude percebem esses movimentos como ruído perfeito de alta frequência, tremor totalmente natural e micro-pausas realistas. Como resultado, eles permitem que o script funcione porque os dados subjacentes realmente se originaram de um humano vivo.
Qual é o problema? Para que esse método funcione em escala, o desenvolvedor do bot precisa de uma biblioteca realmente enorme de “instantâneos” comportamentais. Se o mesmo fragmento de rolagem for reutilizado por vários bots, os sistemas antifraude do lado do servidor detectarão rapidamente o duplicado matemático (acionando a proteção básica contra replay attack) e banirão toda a fazenda.
A vulnerabilidade dos loops
Não importa o quanto você randomize os timings e sacuda o cursor, todo bot sofre de uma fraqueza congênita: ele vive dentro de um loop programático (while ou for).
Os sistemas de proteção pegam os timings do seu script e os passam por análise espectral (transformada de Fourier). Isso filtra o ruído aleatório artificial e revela a frequência portadora oculta do loop. Os humanos são naturalmente arrítmicos; os bots, não.
Você consegue derrotar a análise de Fourier e convencer o servidor de que seu script é um humano vivo, sem frequência base detectável? Sim, mas fazer isso exige reescrever toda a arquitetura do seu scraper. Um simples Math.random() está muito longe de ser suficiente para isso.
Abandonar loops em favor de State Machines. Não use loops lineares
whileouforcombinados com chamadas aninhadas desleep(). Seu bot deve funcionar como uma máquina de estados finita orientada por eventos. Ele deve ter múltiplos estados, por exemplo, leitura, hesitação ou ociosidade, movimento e clique. As transições entre esses estados não devem ser rigidamente codificadas, mas determinadas probabilisticamente. Só então o ritmo geral da sessão se tornará imprevisível, como o de um humano que pode mudar de ideia de repente antes de clicar em um botão.A matemática das “heavy tails”. Esqueça a aleatoriedade uniforme ou mesmo distribuições Gaussianas. A maioria das suas pausas deve ser curta e bem concentrada, mas o bot deve ocasionalmente parar por um tempo anormalmente longo com certa probabilidade. Esses outliers raros, porém extremos, são justamente o que interrompe a análise de frequência de Fourier, borrando o espectro e escondendo o ritmo da máquina.
Uso da entropia do sistema operacional. Os geradores de números pseudorrandômicos embutidos em JavaScript ou Python têm seus próprios padrões previsíveis. Em vez disso, você pode extrair entropia real diretamente do sistema operacional, que coleta ruído caótico do hardware, desde flutuações na temperatura da CPU até interrupções de rede.
Conclusão: a economia do scraping e o jogo sem fim
A biometria comportamental não se tornou uma solução milagrosa contra bots. No entanto, ela mudou fundamentalmente tanto as regras do jogo quanto a economia da automação.
Antes, construir um scraper bem-sucedido exigia pouco mais do que comprar um lote de proxies e entender os cabeçalhos do navegador. Hoje, os desenvolvedores de automação precisam de conhecimento que se estende à biomecânica e às transformadas de Fourier. É claro que isso se aplica a projetos de grande porte, e não simplesmente à extração de fotos do Google Maps.
A corrida armamentista entre os sistemas antifraude e os desenvolvedores de bots continua, mas agora em um novo campo de batalha: a imitação do sistema nervoso humano. As soluções antifraude continuarão introduzindo métodos de verificação cada vez mais sofisticados, enquanto os scrapers aprenderão a “respirar” e procrastinar de forma ainda mais convincente.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.

Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.
Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.
Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.