Como extrair dados da Amazon: dicas, truques e ferramentas para web scraping


Artur Hvalei
Technical Support Specialist, Octo Browser
A Amazon é uma das maiores plataformas de e-commerce do mundo e uma vasta fonte de dados valiosos. Extrair e usar de forma eficaz informações sobre produtos, preços e avaliações de clientes é crucial para o desenvolvimento dos negócios. Seja para promover seus próprios produtos ou acompanhar os concorrentes, você precisará de ferramentas de coleta de dados para analisar o mercado. No entanto, fazer web scraping na Amazon tem particularidades que você precisa conhecer. Neste artigo, discutiremos as etapas necessárias para criar um web scraper e um especialista da equipe Octo oferecerá um exemplo de código para scraping na Amazon.
Índice
Mantenha o anonimato, aproveite o recurso multiconta e alcance seus objetivos com o melhor navegador antidetecção do mercado.
Você gostaria de experimentar o Octo Browser com desconto?
Use o código promocional OCTOSCRAPER para obter 30% de desconto em qualquer assinatura. Esta oferta é válida apenas para novos usuários.
O que é web scraping?
Web scraping é o processo de coleta automatizada de dados de sites. Programas ou scripts especiais, chamados de scrapers, extraem informações de páginas da Web e as convertem em um formato de dados estruturados, conveniente para análise e uso posterior. Os formatos mais comuns para armazenar e processar dados são CSV, JSON, SQL ou Excel.
Hoje em dia, o web scraping é amplamente utilizado na ciência de dados, marketing e e-commerce. Scrapers coletam vastas quantidades de informações para fins pessoais e profissionais. Além disso, gigantes tecnológicos modernos dependem de métodos de web scraping para monitorar e analisar tendências.
Ferramentas e tecnologias para web scraping
Python e bibliotecas
Python é uma das linguagens de programação mais populares para web scraping. É conhecida por sua sintaxe simples e clara, tornando-a uma escolha ideal tanto para iniciantes quanto para programadores experientes. Outra vantagem é a ampla gama de bibliotecas disponíveis para web scraping, como Beautiful Soup, Scrapy, Requests e Selenium. Essas bibliotecas permitem enviar facilmente solicitações HTTP, processar documentos HTML e interagir com páginas da Web.
APIs
A Amazon fornece APIs para acessar seus dados, como a Amazon Product Advertising API. Isso permite solicitar informações específicas em um formato estruturado sem precisar analisar toda a página HTML.
Serviços em nuvem
Plataformas em nuvem, como AWS Lambda e Google Cloud Functions, podem ser usadas para automatizar e escalar processos de web scraping. Elas oferecem alto desempenho e a capacidade de lidar com grandes volumes de dados.
Ferramentas especializadas
Existem também ferramentas adicionais para web scraping, como navegadores multiconta e proxies. Seu papel é falsificar a impressão digital para contornar restrições de segurança do site. Essas ferramentas aceleram a coleta de dados.
Aplicações do web scraping na Amazon
Análise de mercado e concorrência
O web scraping permite coletar dados sobre os produtos e preços dos concorrentes, analisar sua gama de produtos e identificar tendências. Isso ajuda as empresas a adaptar suas estratégias e se manterem competitivas.
Monitoramento de preços
Coletar dados sobre preços de produtos similares ajuda as empresas a definir preços competitivos e responder prontamente às mudanças do mercado. Isso é especialmente importante no contexto de preços dinâmicos e promoções.
Coleta de avaliações e classificações
Avaliações e classificações são uma fonte importante de informações sobre como os consumidores percebem os produtos. Analisar esses dados ajuda a identificar os pontos fortes e fracos dos produtos, bem como obter ideias para melhorá-los.
Pesquisa de gama de produtos
Usando web scraping, você pode analisar a gama de produtos na Amazon, identificar categorias populares e, com base nisso, tomar decisões sobre a expansão ou alteração do portfólio de produtos.
Acompanhamento de novos produtos
O web scraping pode ajudar você a saber rapidamente sobre o lançamento de novos produtos na plataforma, o que pode ser útil para fabricantes, distribuidores e analistas de mercado.
Navegação pelos elementos da interface da Amazon
Antes de começar a fazer web scraping, é importante entender como as páginas da Web são estruturadas. A maioria das páginas da Web é escrita em HTML e contém elementos como tags, atributos e classes. Conhecer HTML ajudará você a identificar e extrair corretamente os dados necessários.
Na página inicial da Amazon, os compradores usam a barra de pesquisa para inserir palavras-chave relacionadas ao produto desejado. Como resultado, recebem uma lista com nomes de produtos, preços, avaliações e outros atributos essenciais. Além disso, os produtos podem ser filtrados por vários parâmetros, como faixa de preço, categoria de produto e avaliações de clientes. Navegar por esses componentes ajuda os usuários a encontrar facilmente os produtos de interesse, comparar alternativas, visualizar informações adicionais e realizar compras de forma conveniente na Amazon.
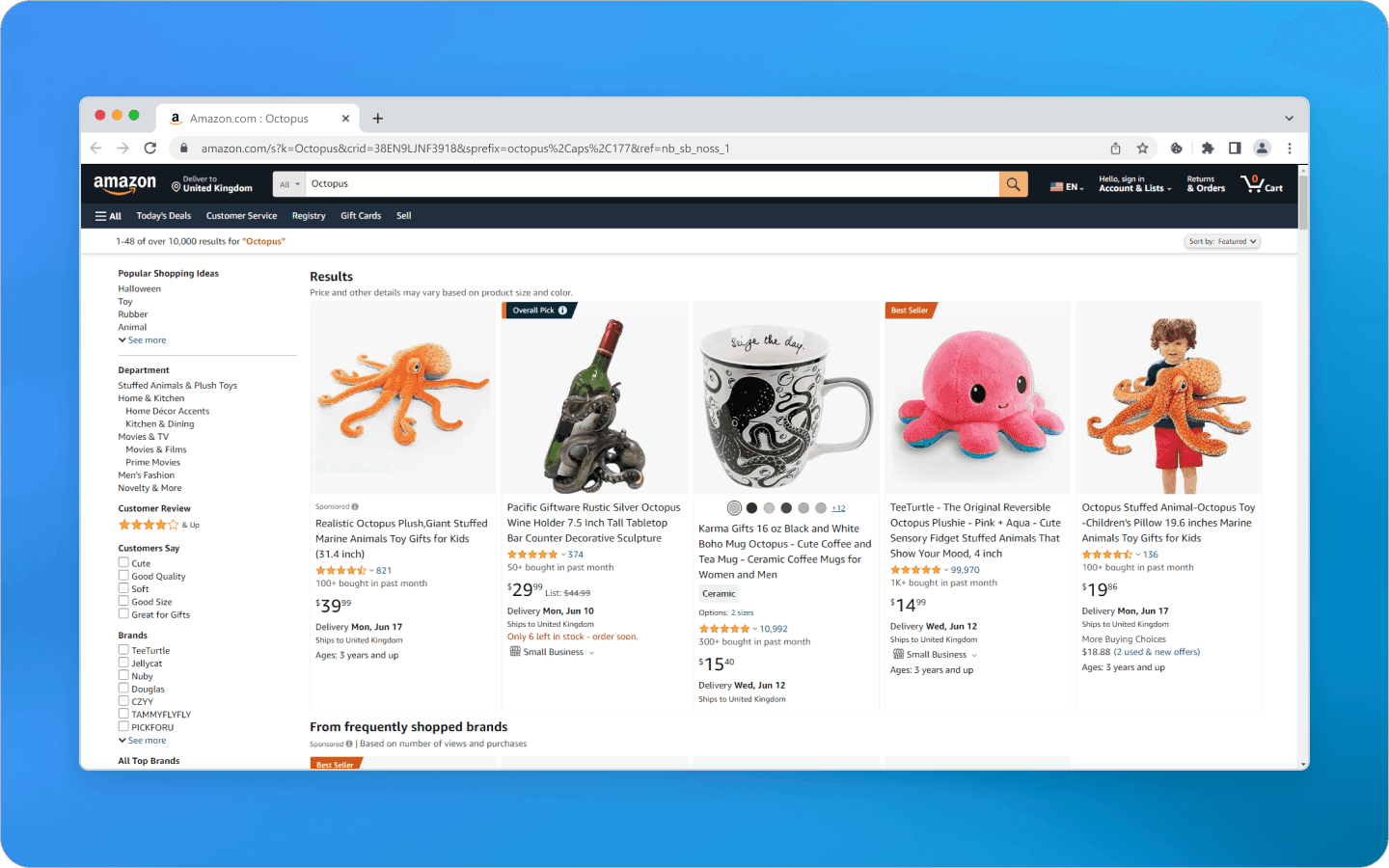
Página inicial da Amazon com uma consulta de pesquisa de Octopus
Para obter uma lista mais extensa de resultados, você pode usar os botões de paginação localizados na parte inferior da página. Cada página geralmente contém um grande número de listagens, permitindo que você navegue por mais produtos. Os filtros no topo da página permitem que você refine sua pesquisa de acordo com seus requisitos.
Para entender a estrutura HTML da Amazon, siga estas etapas:
Acesse o site.
Procure o produto desejado usando a barra de pesquisa ou selecione uma categoria da lista de produtos.
Abra as ferramentas de desenvolvedor clicando com o botão direito no produto e selecionando "Inspect" no menu suspenso.
Examine o layout HTML para identificar as tags e atributos dos dados que você pretende extrair.

Etapas principais para começar o web scraping
O web scraping envolve duas etapas principais: encontrar as informações necessárias e estruturá-las. Depois de estudar a estrutura do site, vamos configurar os componentes necessários para automatizar o processo de web scraping.
Para essa tarefa, usaremos Python e suas bibliotecas:
HTTPX: uma biblioteca HTTP Python totalmente assíncrona que também oferece suporte à execução de solicitações síncronas. O HTTPX fornece uma interface HTTP padrão semelhante à popular biblioteca de solicitações, mas também oferece suporte à assincronia, aos protocolos HTTP/1.1, HTTP/2, HTTP/3 e às conexões SOCKS.
BeautifulSoup: esta biblioteca é projetada para análise fácil e rápida de documentos HTML e XML. Ela fornece uma interface simples para navegar, buscar e modificar a árvore do documento, tornando o processo de web scraping mais intuitivo. Permite extrair informações de uma página procurando por tags, atributos ou texto específico.
Selenium: para interagir com páginas web dinâmicas.
Pandas: esta é uma biblioteca poderosa e confiável para tratamento e limpeza de dados. Por exemplo, após extrair dados de páginas da Web, você pode usar o Pandas para lidar com valores ausentes, transformar os dados no formato necessário e remover duplicatas.
Playwright: permite interação eficiente com páginas da Web que usam JavaScript para atualizações dinâmicas de conteúdo. Isso o torna especialmente útil para scraping de sites como a Amazon, onde muitos elementos carregam de forma assíncrona.
Scrapy: para tarefas de web scraping mais complexas.
Depois de preparar o Python, abra o terminal ou shell e crie um novo diretório de projeto usando os seguintes comandos:
mkdir scraping-amazon-python cd scraping-amazon-python
mkdir scraping-amazon-python cd scraping-amazon-python
Para instalar as bibliotecas, abra o terminal ou shell e execute os seguintes comandos:
pip install httpx pip3 install pandas pip3 install playwright playwright install
pip install httpx pip3 install pandas pip3 install playwright playwright install
Observação: o último comando (playwright install) é crucial, pois garante a instalação adequada dos arquivos de navegador necessários.
Certifique-se de que o processo de instalação seja concluído sem problemas antes de prosseguir para a próxima etapa. Se encontrar dificuldades durante a configuração do ambiente, você pode consultar serviços de IA como ChatGPT, Mistral AI e outros. Esses serviços podem ajudar na solução de erros e fornecer instruções passo a passo para resolvê-los.
Utilização do Python e bibliotecas para web scraping
No seu diretório de projeto, crie um novo script Python chamado amazon_scraper.py e adicione o seguinte código:
import httpx from playwright.async_api import async_playwright import asyncio import pandas as pd # Profile's uuid from Octo PROFILE_UUID = "UUID_SHOULD_BE_HERE" # searching request SEARCH_REQUEST = "fashion" async def main(): async with async_playwright() as p: async with httpx.AsyncClient() as client: response = await client.post( 'http://127.0.0.1:58888/api/profiles/start', json={ 'uuid': PROFILE_UUID, 'headless': False, 'debug_port': True } ) if not response.is_success: print(f'Start response is not successful: {response.json()}') return start_response = response.json() ws_endpoint = start_response.get('ws_endpoint') browser = await p.chromium.connect_over_cdp(ws_endpoint) page = browser.contexts[0].pages[0] # Opening Amazon await page.goto(f'https://www.amazon.com/s?k={SEARCH_REQUEST}') # Extract information results = [] listings = await page.query_selector_all('div.a-section.a-spacing-small') for listing in listings: result = {} # Product name name_element = await listing.query_selector('h2.a-size-mini > a > span') result['product_name'] = await name_element.inner_text() if name_element else 'N/A' # Rating rating_element = await listing.query_selector('span[aria-label*="out of 5 stars"] > span.a-size-base') result['rating'] = (await rating_element.inner_text())[0:3] if rating_element else 'N/A' # Number of reviews reviews_element = await listing.query_selector('span[aria-label*="stars"] + span > a > span') result['number_of_reviews'] = await reviews_element.inner_text() if reviews_element else 'N/A' # Price price_element = await listing.query_selector('span.a-price > span.a-offscreen') result['price'] = await price_element.inner_text() if price_element else 'N/A' if(result['product_name']=='N/A' and result['rating']=='N/A' and result['number_of_reviews']=='N/A' and result['price']=='N/A'): pass else: results.append(result) # Close browser await browser.close() return results # Run the scraper and save results to a CSV file results = asyncio.run(main()) df = pd.DataFrame(results) df.to_csv('amazon_products_listings.csv', index=False)
import httpx from playwright.async_api import async_playwright import asyncio import pandas as pd # Profile's uuid from Octo PROFILE_UUID = "UUID_SHOULD_BE_HERE" # searching request SEARCH_REQUEST = "fashion" async def main(): async with async_playwright() as p: async with httpx.AsyncClient() as client: response = await client.post( 'http://127.0.0.1:58888/api/profiles/start', json={ 'uuid': PROFILE_UUID, 'headless': False, 'debug_port': True } ) if not response.is_success: print(f'Start response is not successful: {response.json()}') return start_response = response.json() ws_endpoint = start_response.get('ws_endpoint') browser = await p.chromium.connect_over_cdp(ws_endpoint) page = browser.contexts[0].pages[0] # Opening Amazon await page.goto(f'https://www.amazon.com/s?k={SEARCH_REQUEST}') # Extract information results = [] listings = await page.query_selector_all('div.a-section.a-spacing-small') for listing in listings: result = {} # Product name name_element = await listing.query_selector('h2.a-size-mini > a > span') result['product_name'] = await name_element.inner_text() if name_element else 'N/A' # Rating rating_element = await listing.query_selector('span[aria-label*="out of 5 stars"] > span.a-size-base') result['rating'] = (await rating_element.inner_text())[0:3] if rating_element else 'N/A' # Number of reviews reviews_element = await listing.query_selector('span[aria-label*="stars"] + span > a > span') result['number_of_reviews'] = await reviews_element.inner_text() if reviews_element else 'N/A' # Price price_element = await listing.query_selector('span.a-price > span.a-offscreen') result['price'] = await price_element.inner_text() if price_element else 'N/A' if(result['product_name']=='N/A' and result['rating']=='N/A' and result['number_of_reviews']=='N/A' and result['price']=='N/A'): pass else: results.append(result) # Close browser await browser.close() return results # Run the scraper and save results to a CSV file results = asyncio.run(main()) df = pd.DataFrame(results) df.to_csv('amazon_products_listings.csv', index=False)
Nesse código, usamos as capacidades assíncronas do Python com a biblioteca Playwright para extrair listagens de produtos de uma página específica da Amazon. Nós lançamos um perfil do Octo Browser e, em seguida, nos conectamos a ele por meio da biblioteca Playwright. O script abre uma URL com uma consulta de pesquisa específica, que pode ser editada no topo do script na variável SEARCH_REQUEST.
Ao iniciar o navegador e navegar para a URL de destino da Amazon, você extrairá informações dos produtos: nome, avaliação, contagem de avaliações e preço. Após iterar por cada listagem na página, você pode filtrar as listagens que não possuem dados, que o script marcará como "N/A". Os resultados da pesquisa serão salvos em um Pandas DataFrame e, em seguida, exportados para um arquivo CSV chamado amazon_products_listings.csv.
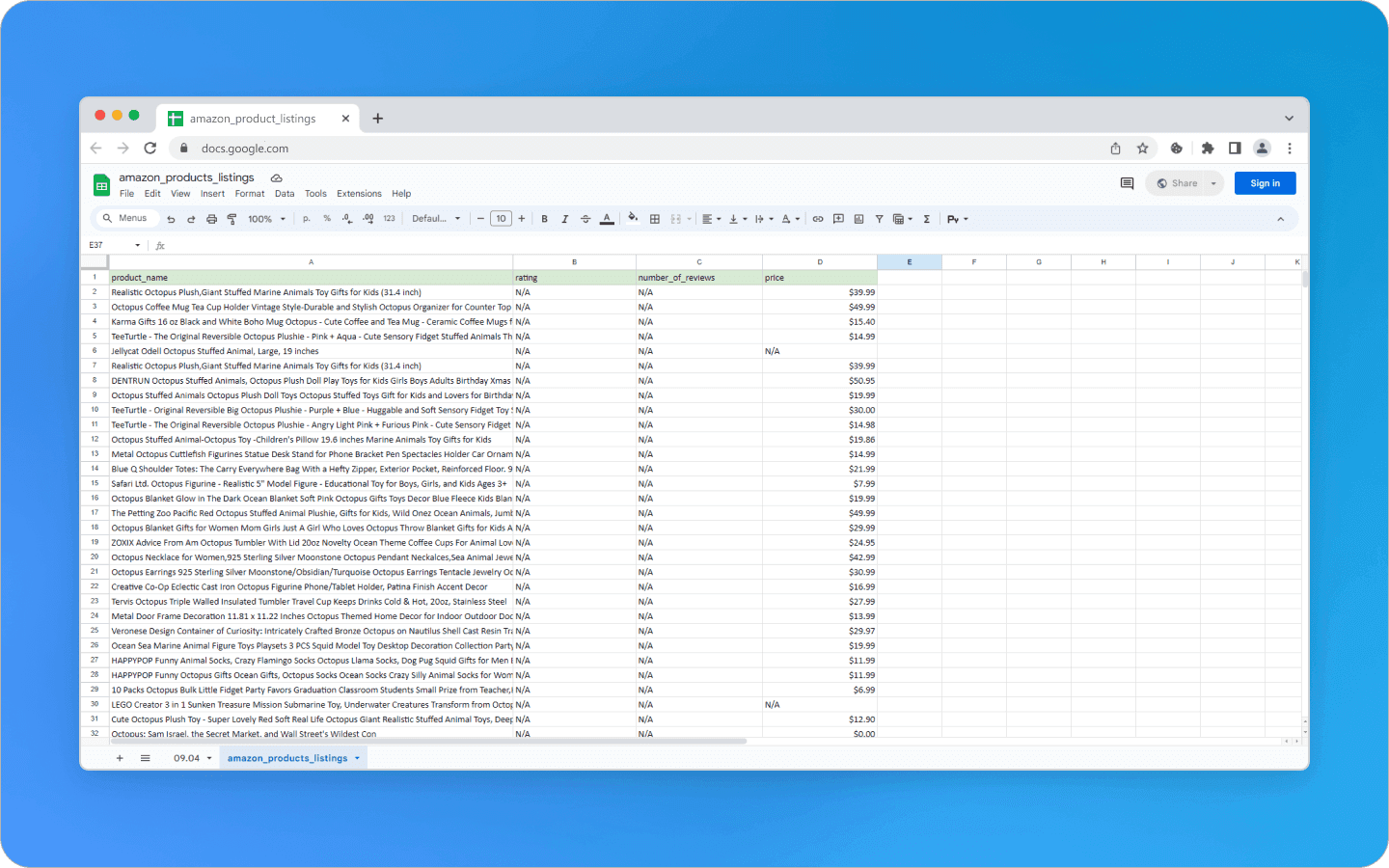
O que mais é necessário para um web scraping eficaz?
Fazer web scraping na Amazon sem proxies e ferramentas especializadas de scraping apresenta inúmeros desafios. Como muitas outras plataformas populares, a Amazon possui limites de taxa de solicitações, o que significa que pode bloquear seu endereço IP se você exceder o limite estabelecido. Além disso, a Amazon usa algoritmos de detecção de bots que identificam sua impressão digital quando você acessa as páginas do site.
Diante disso, recomenda-se seguir práticas recomendadas comumente usadas para evitar a detecção e o possível bloqueio pela Amazon. Aqui estão algumas das dicas e truques mais úteis:
Simulação de comportamento natural
A Amazon pode bloquear ou suspender temporariamente atividades que considere robóticas ou suspeitas. É crucial que seu scraper pareça o mais humano possível.
Para desenvolver um padrão de navegação bem-sucedido, pense em como um usuário médio se comportaria ao explorar uma página e adicione cliques, rolagens e movimentos do mouse correspondentes. Para evitar bloqueios, introduza atrasos ou intervalos aleatórios entre as solicitações usando funções como asyncio.sleep(random.uniform(1, 5)). Isso fará com que seu padrão pareça menos robótico.
Uma impressão digital realista
Use um navegador multiconta para falsificar sua impressão digital com a de um dispositivo real. Plataformas como a Amazon coletam vários parâmetros de impressão digital para identificar bots. Para evitar a detecção, certifique-se de que seus parâmetros de impressão digital e suas combinações sejam sempre plausíveis.
Além disso, para reduzir o risco de detecção, você deve alternar endereços IP. Proxies de alta qualidade desempenham um papel crucial ao trabalhar com um navegador multiconta. Escolha apenas provedores respeitáveis com os melhores preços. Os proxies devem ser selecionados de acordo com a estratégia de web scraping e considerando suas GEOs, já que a Amazon fornece conteúdo diferente para regiões diferentes. Certifique-se de que seus proxies tenham uma baixa pontuação de spam/abuso/fraude. Você também deve considerar a velocidade dos proxies. Por exemplo, proxies residenciais podem ter alta latência, o que afetará a velocidade do web scraping.
Serviços de solucionador de CAPTCHA
Além de um navegador multiconta, proxies de alta qualidade e um script bem pensado que simula o comportamento humano, um solucionador de CAPTCHA automático também pode ser útil. Para isso, você pode usar soluções OSS, serviços de solução manual como 2captcha e anti-captcha ou solucionadores automatizados como Capmonster.
Por que usar navegadores multiconta para web scraping?
Muitos sites, plataformas e serviços usam informações sobre o dispositivo do usuário, navegador e conexão para identificá-los. Esses conjuntos de dados são conhecidos como impressões digitais. Com base nas informações de impressão digital, os sistemas de segurança dos sites determinam se um usuário é suspeito.
O conjunto específico de parâmetros analisados pode variar dependendo do sistema de segurança do site. Para conectar e exibir corretamente o conteúdo, um navegador fornece mais de 50 parâmetros diferentes relacionados ao seu dispositivo, cada um dos quais pode fazer parte da impressão digital.
Além disso, um navegador pode ser encarregado de criar uma imagem 2D ou 3D simples e, com base em como o dispositivo realiza essa tarefa, um hash pode ser gerado. Esse hash distinguirá esse dispositivo de outros visitantes do site. É assim que funciona a impressão digital de hardware via Canvas e WebGL.
Mudanças mínimas em algumas características, das quais o navegador passa informações para os sistemas de segurança do site, não impedirão a identificação de um usuário já conhecido. Você pode mudar o navegador, fuso horário ou resolução da tela, mas mesmo que faça tudo isso simultaneamente, a probabilidade de identificação permanecerá alta.
A impressão digital, juntamente com outras tecnologias antiscraping, como limitação de taxa, geolocalização, WAF, desafios e CAPTCHAs, existe para proteger os sites de interações automatizadas. Um navegador multiconta com um sistema de manipulação de impressão digital de alta qualidade ajudará a contornar os sistemas de segurança dos sites. Como resultado, a eficácia do web scraping aumentará, pois a coleta de dados se tornará mais rápida e confiável.
Como funcionam os navegadores multiconta?
O papel dos navegadores multiconta em contornar os sistemas de segurança dos sites está na manipulação da impressão digital. Usando um navegador multiconta, você pode criar vários de navegador, que são cópias virtuais do navegador, isoladas umas das outras e com seu próprio conjunto de características e configurações: cookies, histórico de navegação, extensões, proxies, parâmetros de impressão digital. Cada perfil de navegador multiconta aparece para os sistemas de segurança dos sites como um usuário separado.
Como fazer web scraping usando um navegador multiconta
Os navegadores multiconta geralmente oferecem capacidades de automação por meio do protocolo Chrome Dev Tools. Ele permite que você automatize as ações necessárias de web scraping via interfaces de software. Para um trabalho conveniente, você pode usar bibliotecas OSS, como Puppeteer, Playwright, Selenium etc.
No Octo Browser, toda a documentação necessária para começar está disponível aqui e as instruções detalhadas da API podem ser encontradas aqui.
Um navegador multiconta reduz os custos de web scraping?
Os navegadores multiconta podem tanto aumentar quanto diminuir os custos de web scraping, dependendo do recurso e das condições de trabalho.
Os custos podem ser reduzidos ao minimizar o risco de bloqueios e automatizar tarefas manuais. Os navegadores multiconta oferecem um gerenciador de perfis e recursos de sincronização automática de dados de perfil para isso.Os custos podem ser aumentados principalmente pela compra de licenças para o número necessário de perfis.
Todo o resto sendo igual, no longo prazo, o uso de um navegador multiconta facilita economias e reduz os custos de web scraping.
Vale a pena o esforço de automação do web scraping?
O web scraping é uma ferramenta poderosa para a coleta e análise automática de dados. As empresas o utilizam para reunir as informações necessárias e tomar decisões informadas na área de e-commerce.
Use Python para pesquisar eficientemente produtos, avaliações, descrições e preços na Amazon. Escrever o código necessário pode levar algum tempo e esforço, mas os resultados superarão todas as expectativas. Para evitar a atenção dos sistemas de segurança, simule o comportamento natural do usuário, use endereços IP de terceiros e altere regularmente a impressão digital. Ferramentas especializadas, como navegadores multiconta e servidores proxy, permitirão que você alterne impressões digitais de navegador e endereços IP para contornar restrições e aumentar a velocidade do web scraping.
Perguntas frequentes
Que tipos de dados podem ser extraídos usando web scraping?
O web scraping pode extrair texto, imagens, tabelas, metadados e mais.
O scraping pode ser detectado?
Sim. A análise de dados pode ser detectada por sistemas antibot, que podem verificar seu endereço IP, se os parâmetros da sua impressão digital correspondem, e os padrões de comportamento. Se a verificação falhar, o acesso às páginas do site a partir do seu endereço IP e do seu dispositivo será bloqueado.
Como evito bloqueios durante o web scraping?
Use servidores proxy, simule ações reais de usuários e adicione atrasos entre as requisições.
Quais aspectos legais do web scraping precisam ser considerados?
Os aspectos legais do web scraping são regidos por leis de proteção de dados e direitos de propriedade intelectual. Fazer scraping de dados publicamente disponíveis em sites não é considerado ilegal se suas ações não violarem os Termos de Serviço (ToS) deles. Siga as regras da plataforma e sempre considere os aspectos legais do web scraping.
A Amazon permite web scraping?
Fazer scraping de dados publicamente disponíveis na Amazon não é considerado ilegal, desde que suas ações não violem os Termos de Serviço (ToS) dela.
Quais são os principais erros que podem ocorrer durante o web scraping e como posso evitá-los?
Erros típicos incluem problemas com a análise de HTML, acompanhar mudanças na estrutura do site e exceder os limites de taxa de solicitações. Para evitá-los, verifique e atualize seu código regularmente.
Como minimizo a ocorrência de CAPTCHAs ao fazer scraping na Amazon?
Use servidores proxy confiáveis e alterne seus endereços IP. Reduza a velocidade de scraping adicionando intervalos aleatórios entre as solicitações e ações. Certifique-se de que os parâmetros da sua impressão digital correspondam aos de dispositivos reais e não levantem suspeitas dos sistemas antibot.
Mantenha o anonimato, aproveite o recurso multiconta e alcance seus objetivos com o melhor navegador antidetecção do mercado.
Você gostaria de experimentar o Octo Browser com desconto?
Use o código promocional OCTOSCRAPER para obter 30% de desconto em qualquer assinatura. Esta oferta é válida apenas para novos usuários.
O que é web scraping?
Web scraping é o processo de coleta automatizada de dados de sites. Programas ou scripts especiais, chamados de scrapers, extraem informações de páginas da Web e as convertem em um formato de dados estruturados, conveniente para análise e uso posterior. Os formatos mais comuns para armazenar e processar dados são CSV, JSON, SQL ou Excel.
Hoje em dia, o web scraping é amplamente utilizado na ciência de dados, marketing e e-commerce. Scrapers coletam vastas quantidades de informações para fins pessoais e profissionais. Além disso, gigantes tecnológicos modernos dependem de métodos de web scraping para monitorar e analisar tendências.
Ferramentas e tecnologias para web scraping
Python e bibliotecas
Python é uma das linguagens de programação mais populares para web scraping. É conhecida por sua sintaxe simples e clara, tornando-a uma escolha ideal tanto para iniciantes quanto para programadores experientes. Outra vantagem é a ampla gama de bibliotecas disponíveis para web scraping, como Beautiful Soup, Scrapy, Requests e Selenium. Essas bibliotecas permitem enviar facilmente solicitações HTTP, processar documentos HTML e interagir com páginas da Web.
APIs
A Amazon fornece APIs para acessar seus dados, como a Amazon Product Advertising API. Isso permite solicitar informações específicas em um formato estruturado sem precisar analisar toda a página HTML.
Serviços em nuvem
Plataformas em nuvem, como AWS Lambda e Google Cloud Functions, podem ser usadas para automatizar e escalar processos de web scraping. Elas oferecem alto desempenho e a capacidade de lidar com grandes volumes de dados.
Ferramentas especializadas
Existem também ferramentas adicionais para web scraping, como navegadores multiconta e proxies. Seu papel é falsificar a impressão digital para contornar restrições de segurança do site. Essas ferramentas aceleram a coleta de dados.
Aplicações do web scraping na Amazon
Análise de mercado e concorrência
O web scraping permite coletar dados sobre os produtos e preços dos concorrentes, analisar sua gama de produtos e identificar tendências. Isso ajuda as empresas a adaptar suas estratégias e se manterem competitivas.
Monitoramento de preços
Coletar dados sobre preços de produtos similares ajuda as empresas a definir preços competitivos e responder prontamente às mudanças do mercado. Isso é especialmente importante no contexto de preços dinâmicos e promoções.
Coleta de avaliações e classificações
Avaliações e classificações são uma fonte importante de informações sobre como os consumidores percebem os produtos. Analisar esses dados ajuda a identificar os pontos fortes e fracos dos produtos, bem como obter ideias para melhorá-los.
Pesquisa de gama de produtos
Usando web scraping, você pode analisar a gama de produtos na Amazon, identificar categorias populares e, com base nisso, tomar decisões sobre a expansão ou alteração do portfólio de produtos.
Acompanhamento de novos produtos
O web scraping pode ajudar você a saber rapidamente sobre o lançamento de novos produtos na plataforma, o que pode ser útil para fabricantes, distribuidores e analistas de mercado.
Navegação pelos elementos da interface da Amazon
Antes de começar a fazer web scraping, é importante entender como as páginas da Web são estruturadas. A maioria das páginas da Web é escrita em HTML e contém elementos como tags, atributos e classes. Conhecer HTML ajudará você a identificar e extrair corretamente os dados necessários.
Na página inicial da Amazon, os compradores usam a barra de pesquisa para inserir palavras-chave relacionadas ao produto desejado. Como resultado, recebem uma lista com nomes de produtos, preços, avaliações e outros atributos essenciais. Além disso, os produtos podem ser filtrados por vários parâmetros, como faixa de preço, categoria de produto e avaliações de clientes. Navegar por esses componentes ajuda os usuários a encontrar facilmente os produtos de interesse, comparar alternativas, visualizar informações adicionais e realizar compras de forma conveniente na Amazon.
Página inicial da Amazon com uma consulta de pesquisa de Octopus
Para obter uma lista mais extensa de resultados, você pode usar os botões de paginação localizados na parte inferior da página. Cada página geralmente contém um grande número de listagens, permitindo que você navegue por mais produtos. Os filtros no topo da página permitem que você refine sua pesquisa de acordo com seus requisitos.
Para entender a estrutura HTML da Amazon, siga estas etapas:
Acesse o site.
Procure o produto desejado usando a barra de pesquisa ou selecione uma categoria da lista de produtos.
Abra as ferramentas de desenvolvedor clicando com o botão direito no produto e selecionando "Inspect" no menu suspenso.
Examine o layout HTML para identificar as tags e atributos dos dados que você pretende extrair.
Etapas principais para começar o web scraping
O web scraping envolve duas etapas principais: encontrar as informações necessárias e estruturá-las. Depois de estudar a estrutura do site, vamos configurar os componentes necessários para automatizar o processo de web scraping.
Para essa tarefa, usaremos Python e suas bibliotecas:
HTTPX: uma biblioteca HTTP Python totalmente assíncrona que também oferece suporte à execução de solicitações síncronas. O HTTPX fornece uma interface HTTP padrão semelhante à popular biblioteca de solicitações, mas também oferece suporte à assincronia, aos protocolos HTTP/1.1, HTTP/2, HTTP/3 e às conexões SOCKS.
BeautifulSoup: esta biblioteca é projetada para análise fácil e rápida de documentos HTML e XML. Ela fornece uma interface simples para navegar, buscar e modificar a árvore do documento, tornando o processo de web scraping mais intuitivo. Permite extrair informações de uma página procurando por tags, atributos ou texto específico.
Selenium: para interagir com páginas web dinâmicas.
Pandas: esta é uma biblioteca poderosa e confiável para tratamento e limpeza de dados. Por exemplo, após extrair dados de páginas da Web, você pode usar o Pandas para lidar com valores ausentes, transformar os dados no formato necessário e remover duplicatas.
Playwright: permite interação eficiente com páginas da Web que usam JavaScript para atualizações dinâmicas de conteúdo. Isso o torna especialmente útil para scraping de sites como a Amazon, onde muitos elementos carregam de forma assíncrona.
Scrapy: para tarefas de web scraping mais complexas.
Depois de preparar o Python, abra o terminal ou shell e crie um novo diretório de projeto usando os seguintes comandos:
mkdir scraping-amazon-python cd scraping-amazon-python
Para instalar as bibliotecas, abra o terminal ou shell e execute os seguintes comandos:
pip install httpx pip3 install pandas pip3 install playwright playwright install
Observação: o último comando (playwright install) é crucial, pois garante a instalação adequada dos arquivos de navegador necessários.
Certifique-se de que o processo de instalação seja concluído sem problemas antes de prosseguir para a próxima etapa. Se encontrar dificuldades durante a configuração do ambiente, você pode consultar serviços de IA como ChatGPT, Mistral AI e outros. Esses serviços podem ajudar na solução de erros e fornecer instruções passo a passo para resolvê-los.
Utilização do Python e bibliotecas para web scraping
No seu diretório de projeto, crie um novo script Python chamado amazon_scraper.py e adicione o seguinte código:
import httpx from playwright.async_api import async_playwright import asyncio import pandas as pd # Profile's uuid from Octo PROFILE_UUID = "UUID_SHOULD_BE_HERE" # searching request SEARCH_REQUEST = "fashion" async def main(): async with async_playwright() as p: async with httpx.AsyncClient() as client: response = await client.post( 'http://127.0.0.1:58888/api/profiles/start', json={ 'uuid': PROFILE_UUID, 'headless': False, 'debug_port': True } ) if not response.is_success: print(f'Start response is not successful: {response.json()}') return start_response = response.json() ws_endpoint = start_response.get('ws_endpoint') browser = await p.chromium.connect_over_cdp(ws_endpoint) page = browser.contexts[0].pages[0] # Opening Amazon await page.goto(f'https://www.amazon.com/s?k={SEARCH_REQUEST}') # Extract information results = [] listings = await page.query_selector_all('div.a-section.a-spacing-small') for listing in listings: result = {} # Product name name_element = await listing.query_selector('h2.a-size-mini > a > span') result['product_name'] = await name_element.inner_text() if name_element else 'N/A' # Rating rating_element = await listing.query_selector('span[aria-label*="out of 5 stars"] > span.a-size-base') result['rating'] = (await rating_element.inner_text())[0:3] if rating_element else 'N/A' # Number of reviews reviews_element = await listing.query_selector('span[aria-label*="stars"] + span > a > span') result['number_of_reviews'] = await reviews_element.inner_text() if reviews_element else 'N/A' # Price price_element = await listing.query_selector('span.a-price > span.a-offscreen') result['price'] = await price_element.inner_text() if price_element else 'N/A' if(result['product_name']=='N/A' and result['rating']=='N/A' and result['number_of_reviews']=='N/A' and result['price']=='N/A'): pass else: results.append(result) # Close browser await browser.close() return results # Run the scraper and save results to a CSV file results = asyncio.run(main()) df = pd.DataFrame(results) df.to_csv('amazon_products_listings.csv', index=False)
Nesse código, usamos as capacidades assíncronas do Python com a biblioteca Playwright para extrair listagens de produtos de uma página específica da Amazon. Nós lançamos um perfil do Octo Browser e, em seguida, nos conectamos a ele por meio da biblioteca Playwright. O script abre uma URL com uma consulta de pesquisa específica, que pode ser editada no topo do script na variável SEARCH_REQUEST.
Ao iniciar o navegador e navegar para a URL de destino da Amazon, você extrairá informações dos produtos: nome, avaliação, contagem de avaliações e preço. Após iterar por cada listagem na página, você pode filtrar as listagens que não possuem dados, que o script marcará como "N/A". Os resultados da pesquisa serão salvos em um Pandas DataFrame e, em seguida, exportados para um arquivo CSV chamado amazon_products_listings.csv.
O que mais é necessário para um web scraping eficaz?
Fazer web scraping na Amazon sem proxies e ferramentas especializadas de scraping apresenta inúmeros desafios. Como muitas outras plataformas populares, a Amazon possui limites de taxa de solicitações, o que significa que pode bloquear seu endereço IP se você exceder o limite estabelecido. Além disso, a Amazon usa algoritmos de detecção de bots que identificam sua impressão digital quando você acessa as páginas do site.
Diante disso, recomenda-se seguir práticas recomendadas comumente usadas para evitar a detecção e o possível bloqueio pela Amazon. Aqui estão algumas das dicas e truques mais úteis:
Simulação de comportamento natural
A Amazon pode bloquear ou suspender temporariamente atividades que considere robóticas ou suspeitas. É crucial que seu scraper pareça o mais humano possível.
Para desenvolver um padrão de navegação bem-sucedido, pense em como um usuário médio se comportaria ao explorar uma página e adicione cliques, rolagens e movimentos do mouse correspondentes. Para evitar bloqueios, introduza atrasos ou intervalos aleatórios entre as solicitações usando funções como asyncio.sleep(random.uniform(1, 5)). Isso fará com que seu padrão pareça menos robótico.
Uma impressão digital realista
Use um navegador multiconta para falsificar sua impressão digital com a de um dispositivo real. Plataformas como a Amazon coletam vários parâmetros de impressão digital para identificar bots. Para evitar a detecção, certifique-se de que seus parâmetros de impressão digital e suas combinações sejam sempre plausíveis.
Além disso, para reduzir o risco de detecção, você deve alternar endereços IP. Proxies de alta qualidade desempenham um papel crucial ao trabalhar com um navegador multiconta. Escolha apenas provedores respeitáveis com os melhores preços. Os proxies devem ser selecionados de acordo com a estratégia de web scraping e considerando suas GEOs, já que a Amazon fornece conteúdo diferente para regiões diferentes. Certifique-se de que seus proxies tenham uma baixa pontuação de spam/abuso/fraude. Você também deve considerar a velocidade dos proxies. Por exemplo, proxies residenciais podem ter alta latência, o que afetará a velocidade do web scraping.
Serviços de solucionador de CAPTCHA
Além de um navegador multiconta, proxies de alta qualidade e um script bem pensado que simula o comportamento humano, um solucionador de CAPTCHA automático também pode ser útil. Para isso, você pode usar soluções OSS, serviços de solução manual como 2captcha e anti-captcha ou solucionadores automatizados como Capmonster.
Por que usar navegadores multiconta para web scraping?
Muitos sites, plataformas e serviços usam informações sobre o dispositivo do usuário, navegador e conexão para identificá-los. Esses conjuntos de dados são conhecidos como impressões digitais. Com base nas informações de impressão digital, os sistemas de segurança dos sites determinam se um usuário é suspeito.
O conjunto específico de parâmetros analisados pode variar dependendo do sistema de segurança do site. Para conectar e exibir corretamente o conteúdo, um navegador fornece mais de 50 parâmetros diferentes relacionados ao seu dispositivo, cada um dos quais pode fazer parte da impressão digital.
Além disso, um navegador pode ser encarregado de criar uma imagem 2D ou 3D simples e, com base em como o dispositivo realiza essa tarefa, um hash pode ser gerado. Esse hash distinguirá esse dispositivo de outros visitantes do site. É assim que funciona a impressão digital de hardware via Canvas e WebGL.
Mudanças mínimas em algumas características, das quais o navegador passa informações para os sistemas de segurança do site, não impedirão a identificação de um usuário já conhecido. Você pode mudar o navegador, fuso horário ou resolução da tela, mas mesmo que faça tudo isso simultaneamente, a probabilidade de identificação permanecerá alta.
A impressão digital, juntamente com outras tecnologias antiscraping, como limitação de taxa, geolocalização, WAF, desafios e CAPTCHAs, existe para proteger os sites de interações automatizadas. Um navegador multiconta com um sistema de manipulação de impressão digital de alta qualidade ajudará a contornar os sistemas de segurança dos sites. Como resultado, a eficácia do web scraping aumentará, pois a coleta de dados se tornará mais rápida e confiável.
Como funcionam os navegadores multiconta?
O papel dos navegadores multiconta em contornar os sistemas de segurança dos sites está na manipulação da impressão digital. Usando um navegador multiconta, você pode criar vários de navegador, que são cópias virtuais do navegador, isoladas umas das outras e com seu próprio conjunto de características e configurações: cookies, histórico de navegação, extensões, proxies, parâmetros de impressão digital. Cada perfil de navegador multiconta aparece para os sistemas de segurança dos sites como um usuário separado.
Como fazer web scraping usando um navegador multiconta
Os navegadores multiconta geralmente oferecem capacidades de automação por meio do protocolo Chrome Dev Tools. Ele permite que você automatize as ações necessárias de web scraping via interfaces de software. Para um trabalho conveniente, você pode usar bibliotecas OSS, como Puppeteer, Playwright, Selenium etc.
No Octo Browser, toda a documentação necessária para começar está disponível aqui e as instruções detalhadas da API podem ser encontradas aqui.
Um navegador multiconta reduz os custos de web scraping?
Os navegadores multiconta podem tanto aumentar quanto diminuir os custos de web scraping, dependendo do recurso e das condições de trabalho.
Os custos podem ser reduzidos ao minimizar o risco de bloqueios e automatizar tarefas manuais. Os navegadores multiconta oferecem um gerenciador de perfis e recursos de sincronização automática de dados de perfil para isso.Os custos podem ser aumentados principalmente pela compra de licenças para o número necessário de perfis.
Todo o resto sendo igual, no longo prazo, o uso de um navegador multiconta facilita economias e reduz os custos de web scraping.
Vale a pena o esforço de automação do web scraping?
O web scraping é uma ferramenta poderosa para a coleta e análise automática de dados. As empresas o utilizam para reunir as informações necessárias e tomar decisões informadas na área de e-commerce.
Use Python para pesquisar eficientemente produtos, avaliações, descrições e preços na Amazon. Escrever o código necessário pode levar algum tempo e esforço, mas os resultados superarão todas as expectativas. Para evitar a atenção dos sistemas de segurança, simule o comportamento natural do usuário, use endereços IP de terceiros e altere regularmente a impressão digital. Ferramentas especializadas, como navegadores multiconta e servidores proxy, permitirão que você alterne impressões digitais de navegador e endereços IP para contornar restrições e aumentar a velocidade do web scraping.
Perguntas frequentes
Que tipos de dados podem ser extraídos usando web scraping?
O web scraping pode extrair texto, imagens, tabelas, metadados e mais.
O scraping pode ser detectado?
Sim. A análise de dados pode ser detectada por sistemas antibot, que podem verificar seu endereço IP, se os parâmetros da sua impressão digital correspondem, e os padrões de comportamento. Se a verificação falhar, o acesso às páginas do site a partir do seu endereço IP e do seu dispositivo será bloqueado.
Como evito bloqueios durante o web scraping?
Use servidores proxy, simule ações reais de usuários e adicione atrasos entre as requisições.
Quais aspectos legais do web scraping precisam ser considerados?
Os aspectos legais do web scraping são regidos por leis de proteção de dados e direitos de propriedade intelectual. Fazer scraping de dados publicamente disponíveis em sites não é considerado ilegal se suas ações não violarem os Termos de Serviço (ToS) deles. Siga as regras da plataforma e sempre considere os aspectos legais do web scraping.
A Amazon permite web scraping?
Fazer scraping de dados publicamente disponíveis na Amazon não é considerado ilegal, desde que suas ações não violem os Termos de Serviço (ToS) dela.
Quais são os principais erros que podem ocorrer durante o web scraping e como posso evitá-los?
Erros típicos incluem problemas com a análise de HTML, acompanhar mudanças na estrutura do site e exceder os limites de taxa de solicitações. Para evitá-los, verifique e atualize seu código regularmente.
Como minimizo a ocorrência de CAPTCHAs ao fazer scraping na Amazon?
Use servidores proxy confiáveis e alterne seus endereços IP. Reduza a velocidade de scraping adicionando intervalos aleatórios entre as solicitações e ações. Certifique-se de que os parâmetros da sua impressão digital correspondam aos de dispositivos reais e não levantem suspeitas dos sistemas antibot.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.

Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.
Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.
Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.