Как обнаруживать ловушки для распознавания ботов и избегать их
27.02.2026


Markus_automation
Expert in data parsing and automation
Автоматизированный парсинг стал неотъемлемой частью многих проектов: это и мониторинг цен, и сбор данных, и анализ социальных сетей. Однако владельцы сайтов стремятся защитить свои данные и снизить нагрузку на серверы, поэтому не поощряют парсинг. Но просто запретить парсить свой сайт или сервис они не могут, а вот расставить специальные ловушки, которые позволяют определить, что конкретный пользователь не человек, а скрипт, могут. В этой статье разберем самые распространенные приемы, с помощью которых сайты вычисляют ботов. Также рассмотрим способы обнаружения и обхода этих ловушек.
Содержание
Сохраняйте анонимность, используйте преимущества мультиаккаунтинга и добивайтесь своих целей с самым качественным решением на рынке антидетект-браузеров.
Невидимые honeypot-ловушки: скрытые ссылки и поля
Один из излюбленных трюков для поимки ботов — это так называемые honeypot-поля, подготовленные и спрятанные особым образом элементы страницы. Реальный человек их никогда не увидит и не кликнет, а вот простенький бот — вполне может.
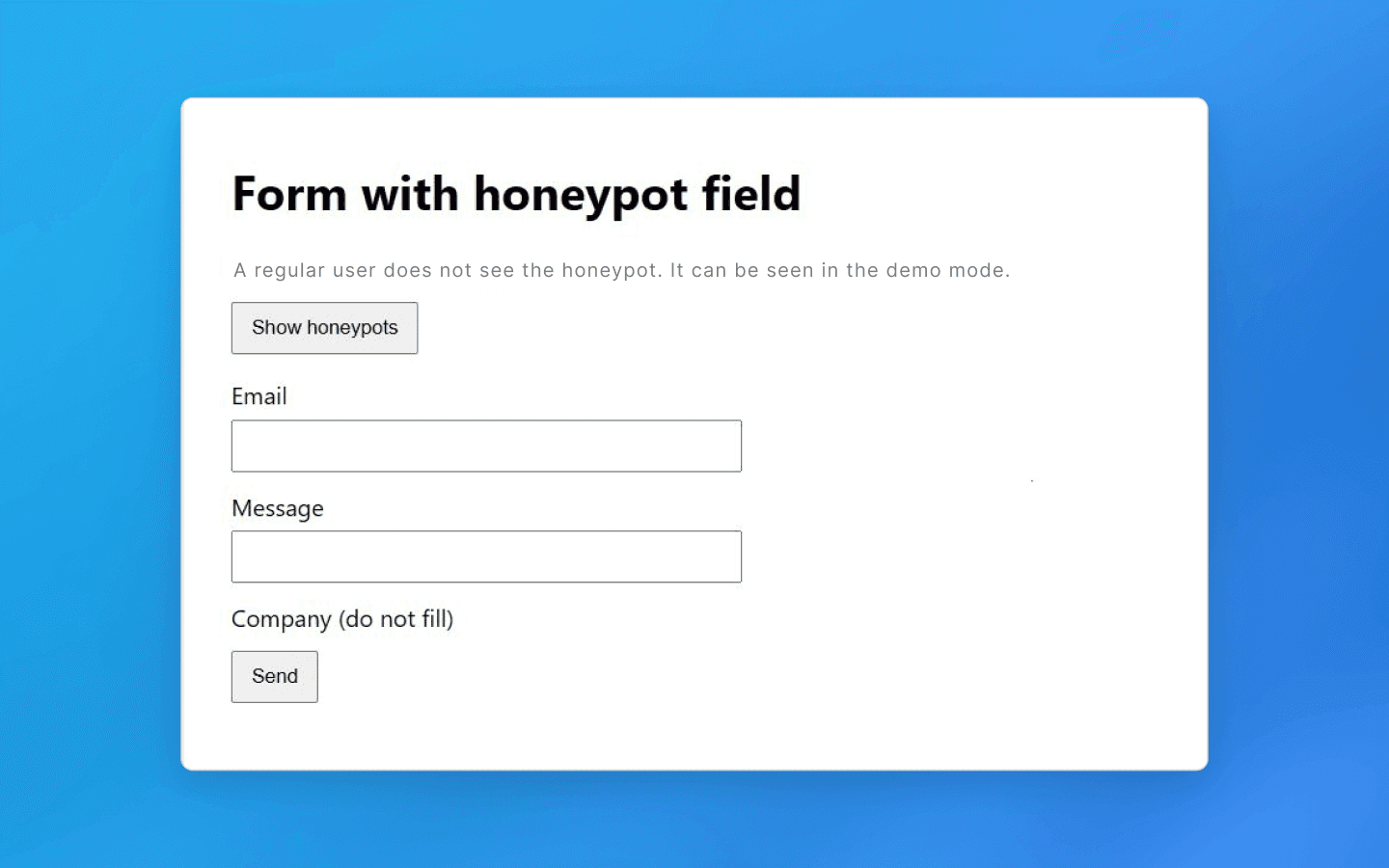
Простой пример — невидимая ссылка (созданная с помощью CSS-стилей вроде display: none или позиционирования за пределами экрана), которая ведет на особый URL-ловушку. Обычный юзер на такую ссылку не нажмет, потому что даже не подозревает о ее существовании, а вот парсер, методично обходящий все ссылки, — перейдет и тем самым выдаст себя. Как только скрипт загрузит эту страницу, сервер внесет его IP-адрес в черный список и заблокирует ему дальнейший доступ.
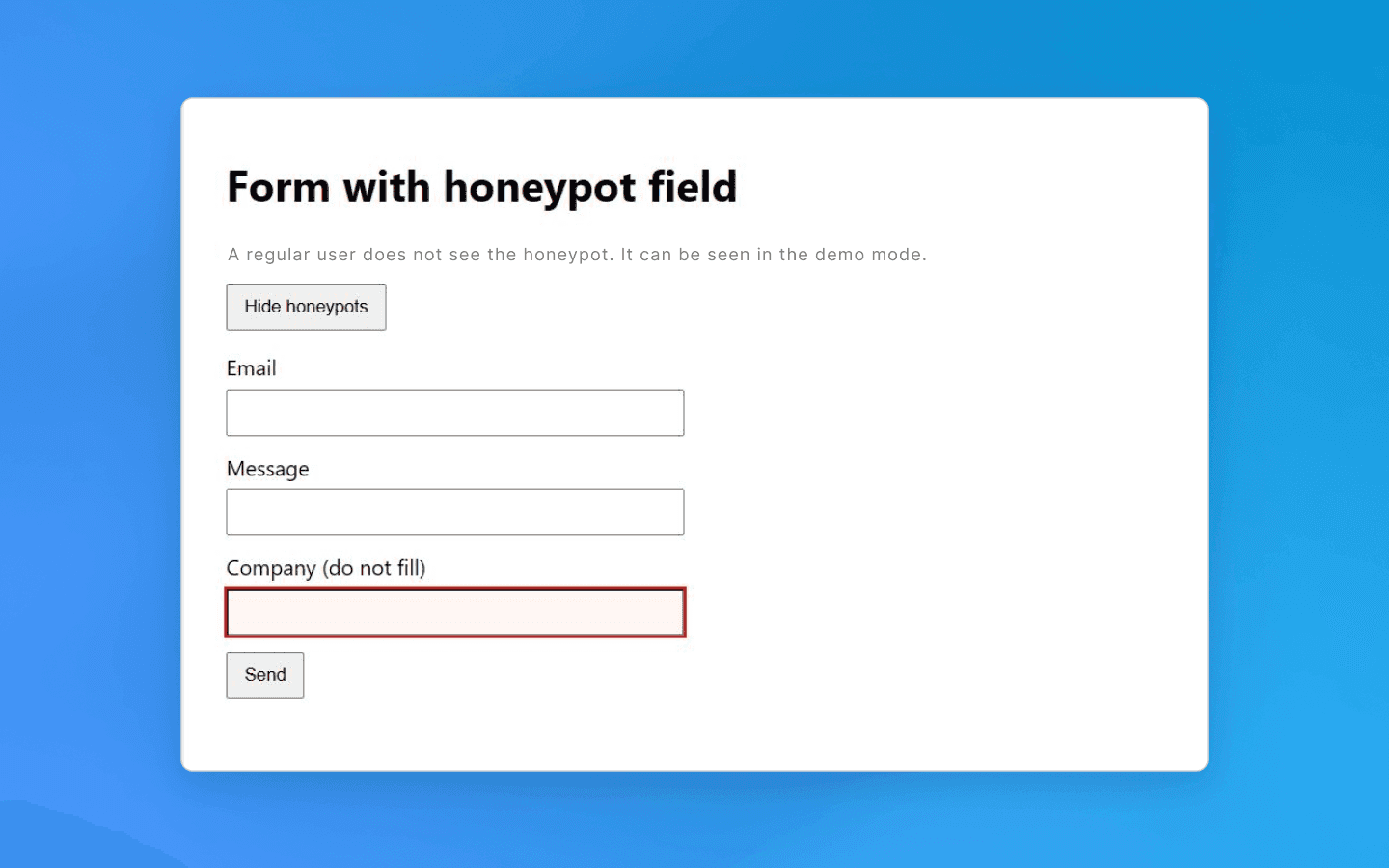
Аналогичная идея применяется и к веб-формам. В форму (например, форму регистрации или форму обратной связи) добавляется скрытое поле. Человек это поле не увидит, а бот найдет и заполнит. Такие honeypot-поля служат сигналом для обнаружения робота. Пришла форма, где скрытое поле содержит текст, — тревожный звонок. Запрос отклоняется или сессия помечается как ботовая. В любом случае работать вам дальше не дадут.
Как избежать: во-первых, при обходе страниц анализируйте свойства элементов перед кликом или переходом. Проверяйте стили ссылок: если ссылка или кнопка помечена как невидимая (display:none, opacity: 0 или размер 1×1 пиксель и т. п.), игнорируйте ее. Подобным образом перед отправкой формы убедитесь, что не заполнили скрытые поля (их можно распознать по нестандартным именам или атрибутам типа aria-hidden, tabindex="-1", стилям скрытия и т. д.). Новичку может показаться, что такие детали несущественны, однако это один из самых простых способов быть обнаруженным. Будет достаточно одного лишнего перехода по ссылке-ловушке — и ваш бот засвечен.
Естественно, владельцы сайтов (сервисов) знают о наличии контрмер, да и современные боты уже научились вычислять honeypot-элементы по подозрительным CSS-признакам, поэтому этот способ комбинируется с другими методами защиты. Но фильтрация невидимых ссылок/полей — обязательное условие для любого профессионального парсера.
CAPTCHA и JavaScript-челленджи
Более очевидный способ предотвратить автоматизированный доступ к своему ресурсу — CAPTCHA. Это те самые всплывающие окна с выбором картинок, галочки «Я не робот» и тому подобные вариации капч. Это прямой и весьма эффективный способ отличить человека от скрипта или бота. В отличие от скрытого honeypot, CAPTCHA демонстративно требует выполнить задание, с которым бот, предположительно, не должен справиться. Но в реальности простые виды капч можно обходить без особых сложностей, так как существует немало бесплатных open source-решений. Но более сложные капчи требуют подключения сторонних сервисов для обхода.
Если бот наткнулся на CAPTCHA, сценариев не особо много: либо решать ее автоматически через сторонний сервис, либо менять поток и переключаться на другой профиль. Платные способы распознавания капчи замедляют парсинг и повышают издержки. Вторая идея обхода капчи сводится к тому, чтобы не доводить до ее появления (снижение интенсивности запросов, чтобы не провоцировать включения защиты, или использовать кэш поисковых систем (Google Cache) для получения данных и т. п.).
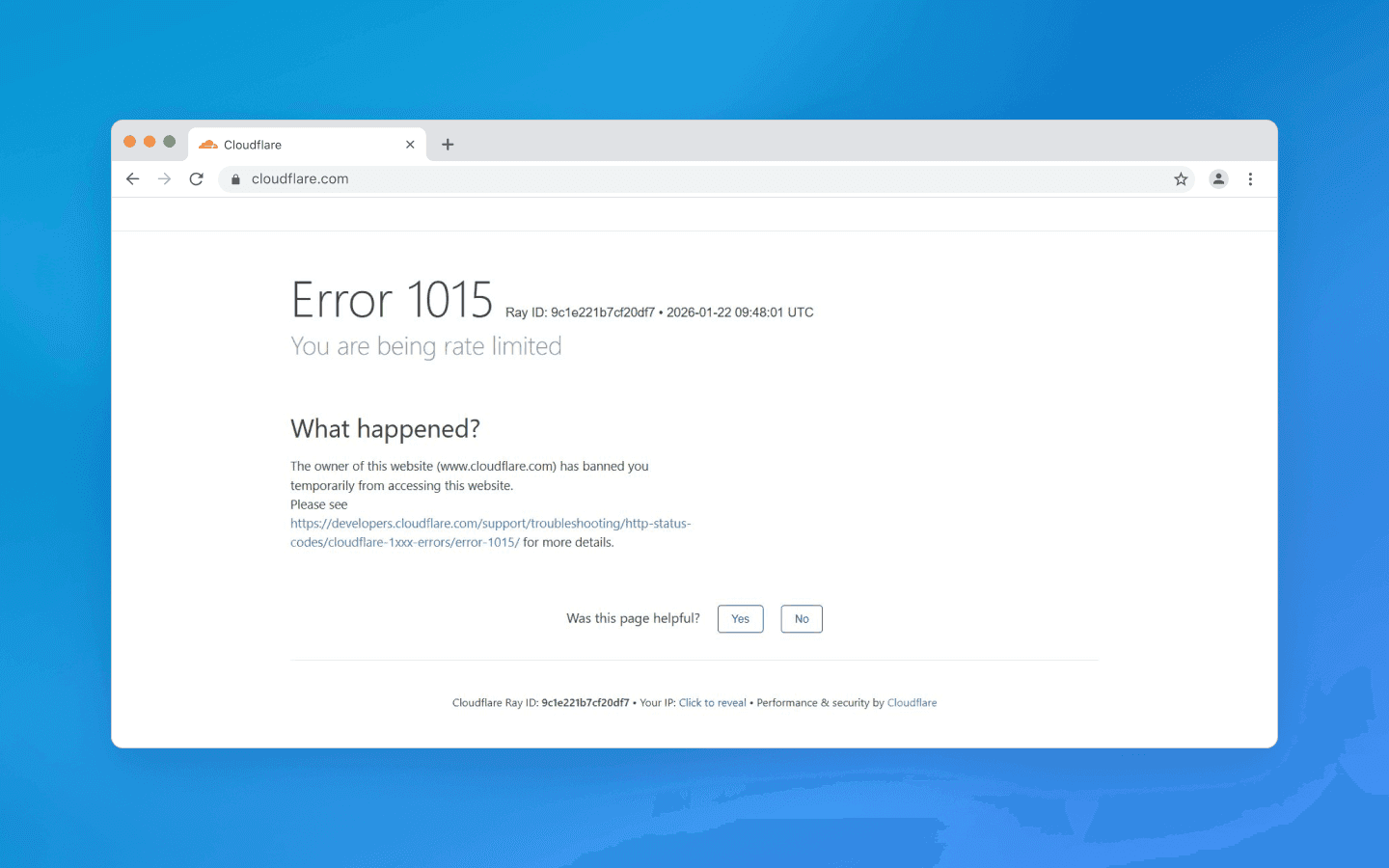
Особняком стоит такой тип капчи, как JavaScript-челлендж. Многие сайты (особенно за CDN-защитой типа Cloudflare) при подозрительном трафике сначала возвращают не сам контент, а страницу-проверку, которая выполняет на стороне клиента специальный JS-код. Этот код может вычислять некий токен, проверять окружение браузера, устанавливать cookie и т. п. — после чего уже перенаправлять на реальный контент. Цель в том, чтобы убедиться, что запрос выполняется настоящим браузером с поддержкой JS, а не просто HTTP-клиентом. Бот, который не умеет исполнять JavaScript, не пройдет такой тест и не получит доступ к странице.
Как избежать: если вы знаете, что целевой ресурс выдает капчу, нужно заранее решить, как именно вы будете обходить ее — технически и финансово. Если предотвратить появление капчи не получится (на некоторых сайтах капча показывается по дефолту), придется интегрировать стороннее решение для распознавания капчи. Что касается JS-челленджей, то самый очевидный путь обхода — использовать headless-браузер, который выполнит требуемый сценарий. Популярные инструменты автоматизации (Puppeteer, Playwright и др.) позволяют запускать браузер в фоновом режиме, но не забывайте про маскировку — при работе с такими инструментами нужно заметать автоматизированные следы.
Игнорировать JS-проверку не получится: уж если она есть, то либо вы ее проходите, либо доступа к данным не будет. Убедитесь, что парсер загружает связанные скрипты, выполняет их и сохраняет полученные cookies/токены для последующих запросов.
Анализ поведения: скорость, последовательность, взаимодействия
Даже если у бота получилось пройти прямые преграды в виде капчи и других заметных антибот-методов, нечеловеческое поведение может стать фатальным для него. Когда обычный пользователь просматривает страницу товара — это минимум несколько секунд, плюс юзер ее скроллит, может кликнуть по картинке, затем переходит по ссылке. Скрипт же способен дергать страницы молниеносно, да еще и в идеально повторяющемся порядке. Современные сайты отслеживают такие аномалии при взаимодействии с их ресурсом. Чрезмерно высокая скорость переходов или загрузки страниц, подозрительно регулярный интервал между запросами и тому подобные паттерны явно указывают на роботизацию.
Еще один маркер — необычная последовательность действий (например, бот обходит сайт по алфавиту URL или по карте сайта, чего реальные посетители не делают никогда). Наконец, тривиальный признак — отсутствие на странице любых действий, которые совершает человек. Если в логах сессии видно, что пользователь просматривал 100 страниц и ни разу не проскроллил экран и не подвигал мышью, можно с большой уверенностью считать эту сессию ботом.
Сюда же относятся и временные ловушки. На формах из-за этого стали ставить ограничения на минимальное время заполнения учетных данных. Большинство людей потратят на ввод хотя бы 5–10 секунд, а бот, естественно, способен прислать форму за доли секунды. Соответственно, если форма отправлена почти мгновенно — с вероятностью 99% это автоматизация, и сайт может отклонить такую заявку. Похожий подход используется и для переходов по страницам: слишком быстрый переход к следующему шагу (особенно сложному, вроде оплаты) настораживает антибот-систему.
Как избежать: главный принцип — маскироваться под поведение реального пользователя. Внесите элемент случайности и естественности в работу вашего парсера.
Во-первых, не гонитесь за максимальной скоростью сбора данных. Если это не критично — лучше работать чуть медленнее, но осторожнее. Вставляйте паузы между запросами (причем не фиксированные, а рандомные в некотором диапазоне). Задайте скрипту задержку на каждой странице, имитируя время на чтение контента.
Во-вторых, избегайте строгой последовательности в маршруте обхода. Если у вас есть возможность, добавьте немного случайности в порядок переходов (например, меняйте очередность обхода разделов, случайно выбирайте ссылки на странице вместо последовательного перечисления).
В-третьих, добавьте признаки естественного взаимодействия в headless-сценарии. В продвинутых пайплайнах это могут быть прокрутка, движения курсора, открытие элементов интерфейса и небольшие микропаузы между шагами. Эти действия не влияют на сбор данных напрямую, но делают последовательность шагов более похожей на человеческую — особенно на длинных страницах и в многошаговых сценариях (авторизация → выбор → оформление), где слишком ровный темп и отсутствие промежутков выглядят неестественно.
Отдельно смотрите на картину со стороны сайта: многие системы комбинируют поведенческий анализ с телеметрией и веб-аналитикой. На странице могут работать трекеры, которые фиксируют события взаимодействия и тайминг сессии. Если в логах получается пустая сессия без характерных сигналов — это подозрительно само по себе. Поэтому важно оценивать не только действия вашего инструмента, но и то, какие данные об этой сессии фактически сформировались и как они интерпретируются на стороне наблюдения.
Ограничение скорости и объема запросов
Еще один очевидный критерий, по которому отличают машину от человека, — частота запросов. Даже самый скоростной пользователь не в состоянии отправлять десятки запросов в секунду, а скрипт может. Поэтому на серверной стороне внедряются ограничения: например, не более N запросов с одного IP-адреса в минуту. Если лимит превышен, включается блокировка (временная или постоянная). На уровне веб-сервера или CDN это реализуется через отслеживание количества и отсеивание всплеска запросов сверх порога. Конкретные цифры зависят от политики сайта: где-то допустимо 5 запросов в секунду, а где-то и 1 запрос в секунду будет считаться перебором. Реализовать это несложно: через Nginx можно настроить лимит в 1 запрос/секунду на IP и отклонять все, что выше этого.
Кроме частоты, смотрят и на параллельность. Обычный пользователь вряд ли открывает 20 страниц сайта одновременно в разных вкладках, а парсер легко генерирует множество потоков. Это тоже отслеживается: слишком много одновременных сессий с одного адреса — повод заподозрить ботнет или парсер.
Как избежать: во-первых, ограничьте уровень параллелизма в вашем скрипте. Да, очень соблазнительно распараллелить обход каталога на 50 потоков и собрать данные за минуту, но в 99% случаев это сразу привлечет нежелательное внимание. Лучше работайте в несколько потоков (или даже в один), если видите, что сайт чувствителен к нагрузке.
Во-вторых, позаботьтесь о смене IP-адресов. Большинство сайтов логирует IP каждого посетителя и при обнаружении подозрительной активности блокирует целиком адрес. Поэтому использование прокси — стандарт для серьезного парсинга. Имеет смысл применять ротацию IP: после определенного числа запросов или при смене раздела менять выходной адрес. Идеально — использовать резидентные или мобильные прокси. Важно настроить парсер так, чтобы один IP не делал слишком много запросов подряд. Например, отправлять не более 5–10 запросов с одного адреса, затем переключаться. Если же пул прокси ограничен, пытайтесь хотя бы чередовать их и выдерживать паузы.
Кроме того, отслеживайте заголовки и коды ответа на свои запросы. Если вы начали получать HTTP 429 Too Many Requests или видите в тексте страницы что-то вроде Too fast, try later — это явный сигнал срабатывания лимита запросов. Такая ситуация требует либо снизить темп парсинга, либо увеличить количество прокси, либо использовать другие уловки. Как вариант, если лимит настроен на IP-адрес, а сайт доступен по HTTP и позволяет без проверки сменить User-Agent и Referrer, — может помочь их чередование.
В общем, не выделяйтесь: чем незаметнее вы впишетесь в фоновый трафик обычных пользователей, тем дольше парсер проживет без блокировок.
Заголовки и отпечатки браузера
Сайты могут распознать парсер еще на этапе соединения, анализируя технические параметры запроса. Каждый HTTP-запрос несет ряд заголовков (User-Agent, Accept, Accept-Language, Cookie и др.), которые в сумме образуют профиль браузера. У обычных браузеров эти профили довольно предсказуемы: например, зайдя с Chrome на сайт, вы отправите характерный набор заголовков, начиная с User-Agent: Mozilla/5.0 ... Chrome/версия ... , плюс список поддерживаемых языков (Accept-Language), флаги фетчинга (Sec-Fetch-* headers) и т. д. Бот же может выдать нестандартный или неполный набор заголовков. Многие сайты сразу блокируют запросы с подозрительными User-Agent-строками типа Scrapy, curl, Wget, Python и т. п. на уровне брандмауэра. И даже если вас не заблокируют за наличие таких подозрительных строк, сам факт будет учтен в совокупности факторов риска.
При смене User-Agent на распространенную строчку от браузера можно проколоться на деталях. Например, Headless Chrome раньше сам себя выдавал и в строке User-Agent содержал слово HeadlessChrome. Или еще пример — бот не отправляет заголовок Accept-Language (реальные браузеры всегда шлют предпочтения языка).
Еще признак: порядок заголовков или их значения не соответствуют заявленному браузеру. Антибот-системы хранят большие базы отпечатков браузеров — шаблонов с разными заголовками и значениями от разных версий Chrome, Safari, Firefox. Если вы, притворяясь Chrome 120+, отправляете соответствующий User-Agent, но при этом у вас нет типичных для современных Chromium-заголовков UA Client Hints (Sec-CH-UA, Sec-CH-UA-Mobile, Sec-CH-UA-Platform), или они в неправильном формате, либо в навигационном запросе, инициированном кликом пользователя, не приходит Sec-Fetch-User: ?1, хотя остальные Sec-Fetch-* присутствуют, — такие мелочи могут выдать автоматизацию. Пример условный, для понимания признака.
Более того, помимо HTTP-заголовков, браузер выдает себя через объект navigator и окружение JS. В headless-режимах есть свойство navigator.webdriver, которое обычно равно true у автоматизированного браузера. Сайты на стороне клиента запускают небольшой скрипт: if (navigator.webdriver) { /* Bot detected */ } — и таким вот нехитрым образом ловят новичков. Другие проверяют наличие специфических объектов, оставляемых Selenium или Playwright. Например, Playwright-инструмент вписывает в window некие служебные переменные (__playwright__binding__ и др.), и скрипт на странице может искать такие признаки постороннего вмешательства.
К более сложным можно отнести проверки через Canvas API или WebGL, когда рисуется скрытая картинка и собирается canvas-фингерпринт, который может совпасть с типичным для эмулятора.
Проверок множество — выявить подделку окружения можно даже по мелким расхождениям в реализации JS-движка.
Как избежать: максимально маскируйтесь под реальное устройство/браузер. Всегда устанавливайте достоверный User-Agent, соответствующий популярному браузеру, и не забывайте обновлять его под современные версии. Но одного заголовка мало: подгоняйте и остальные. Добавьте Accept-Language (с учетом региона IP), Accept с типами контента как у обычного браузера, Connection, Upgrade-Insecure-Requests, Sec-Fetch-* и т. д. Проще всего взглянуть, какие заголовки отправляет ваш браузер при заходе на целевой сайт (через инструменты разработчика или прокси), и эмулировать их. Обращайте внимание на консистентность: если называете себя Chrome на Windows — у вас должен быть и Windows-ориентированный User-Agent, и заголовок Sec-CH-UA-Platform: "Windows" при необходимости.
Если работаете с headless-браузером, используйте библиотеки или настройки, которые автоматически включают скрытие автоматизации (например, в Puppeteer есть пакет puppeteer-extra-plugin-stealth, отключающий navigator.webdriver и другие маркеры, или патченные версии библиотек playwright/puppeteer от rebrowser, которые скрывают многие стандартные уязвимости этих библиотек). Если пишете низкоуровневый парсер, вручную редактируйте navigator через DevTools Protocol: выставьте свойства, совпадающие с настоящим браузером.
Конечно, нет смысла эмулировать абсолютно все вплоть до случайного шума Canvas — рекомендую начать с основного — заголовков и простого JS. Не отправляйте явно подозрительных строк, регулярно обновляйте шаблон заголовков под актуальные браузеры, включайте эмуляцию небольших взаимодействий, и, по возможности, тестируйте свой бот на антидетект. Инструменты вроде BrowserScan или FingerprintJS покажут, какие сигналы выдает ваш скрипт.
Другие хитрости: от «бесконечных лабиринтов» до сторонних сервисов
Помимо перечисленного, есть и более экзотические ловушки, о которых следует знать. Некоторые ресурсы умышленно создают «бесконечные» структуры ссылок — своего рода лабиринт для парсера.
Классический пример — динамически генерируемые бесконечные календарные страницы или параметризованные URL, ведущие в циклы. Бот, не имеющий специальных условий остановки, может застрять, пытаясь перебрать нескончаемый поток ссылок. По итогу он тратит ваши ресурсы впустую и опять же сигнализирует о себе антибот-системе необычным поведением. Для реальных пользователей такие ссылки обычно недосягаемы, а вот бот может попасть в такую ловушку.
Как избежать: во-первых, всегда анализируйте получаемые данные на правдоподобность. Если ваш парсер неожиданно ушел по цепочке ссылок куда-то не туда и накачал тонны текстов, которые выглядят как набор случайных фраз, — возможно, вы попали в лабиринт. Не помешает внедрить в парсер логику обнаружения циклов: отслеживать уже посещенные URL, ограничивать глубину обхода, проверять, что новые ссылки принадлежат тому же домену/разделу, который вам нужен.
Во-вторых, учитывайте контекст: если вы парсите, скажем, сайт отзывов, а бот вдруг начал скачивать страницы с явно несвязным ИИ-сгенерированным текстом, стоит насторожиться и прервать такую сессию.
Также имейте в виду, что помощь в детектировании ботов сайтам оказывают сторонние сервисы. Такие продукты, как Datadome, Cloudflare Bot Management, PerimeterX и др., специализируются на обнаружении автоматического трафика. Они используют комбинацию методов — от поведенческого анализа и фингерпринтинга до баз известных ботов и даже машинного обучения для выявления нетипичных посетителей.
Если ваш бот наткнулся на мощную антибот-систему, задача усложняется — вас может вычислить совокупность малых факторов. Здесь работает все, о чем мы говорили, плюс постоянное улучшение правил с той стороны. В таких случаях иногда дешевле сменить тактику либо ограничиться тем объемом запросов, который не провоцирует срабатывание защиты. При использовании прокси можно попробовать мимикрировать под разных реальных пользователей — менять не только IP, но и геолокацию, юзер-агенты, время суток запросов (имитируя заходы в разные часы, а не круглосуточную скачку).
Заключение
Как видно, не существует одной волшебной кнопки, чтобы навсегда избавить бота от риска блокировки, — нужна комбинация технических приемов и аккуратность:
Обнаруживайте и игнорируйте honeypot-элементы: перед кликом по ссылке или заполнением поля убедитесь, что элемент не скрыт от человеческих глаз. Не переходите по подозрительным URL, не заполняйте невидимые поля форм.
Мимикрия под реального пользователя: используйте реальные заголовки и значения, присущие обычным браузерам (User-Agent, Accept-Language и др.). По возможности запускайте парсинг через браузерный движок антидетект- браузеров, чтобы пройти JS-чеки и обеспечить правдоподобное окружение (navigator, cookies, localStorage и т. д.).
Ограничивайте скорость и потоки: настройте задержки и паузы между запросами, случайные интервалы. Не превышайте лимиты запросов, повышайте масштаб постепенно и следите за реакцией сайта (HTTP-коды 429, капчи и пр.).
Ротируйте IP-адреса и идентификаторы сессии: используйте пул прокси или VPN-серверов, чередуйте IP, особенно при массовых обходах. Следите, чтобы один IP не использовался слишком часто. Желательно применять резидентные IP, они менее подозрительны для антибот-систем.
Встраивайте случайность в поведение: эмулируйте действия пользователя — небольшие прокрутки, движения мыши, время чтения страницы. Избегайте полностью последовательных маршрутов: разбавляйте шаблон действий, чтобы не демонстрировать наличие четкого алгоритма.
Противостояние в веб-скрейпинге продолжается — сайты придумывают новые способы детекции, а разработчики ботов ищут обходные пути. В этой игре победит тот, кто внимательнее и изобретательнее. Пусть ваш бот будет именно таким — осторожным, гибким и по-человечески непредсказуемым.
Сохраняйте анонимность, используйте преимущества мультиаккаунтинга и добивайтесь своих целей с самым качественным решением на рынке антидетект-браузеров.
Невидимые honeypot-ловушки: скрытые ссылки и поля
Один из излюбленных трюков для поимки ботов — это так называемые honeypot-поля, подготовленные и спрятанные особым образом элементы страницы. Реальный человек их никогда не увидит и не кликнет, а вот простенький бот — вполне может.
Простой пример — невидимая ссылка (созданная с помощью CSS-стилей вроде display: none или позиционирования за пределами экрана), которая ведет на особый URL-ловушку. Обычный юзер на такую ссылку не нажмет, потому что даже не подозревает о ее существовании, а вот парсер, методично обходящий все ссылки, — перейдет и тем самым выдаст себя. Как только скрипт загрузит эту страницу, сервер внесет его IP-адрес в черный список и заблокирует ему дальнейший доступ.
Аналогичная идея применяется и к веб-формам. В форму (например, форму регистрации или форму обратной связи) добавляется скрытое поле. Человек это поле не увидит, а бот найдет и заполнит. Такие honeypot-поля служат сигналом для обнаружения робота. Пришла форма, где скрытое поле содержит текст, — тревожный звонок. Запрос отклоняется или сессия помечается как ботовая. В любом случае работать вам дальше не дадут.
Как избежать: во-первых, при обходе страниц анализируйте свойства элементов перед кликом или переходом. Проверяйте стили ссылок: если ссылка или кнопка помечена как невидимая (display:none, opacity: 0 или размер 1×1 пиксель и т. п.), игнорируйте ее. Подобным образом перед отправкой формы убедитесь, что не заполнили скрытые поля (их можно распознать по нестандартным именам или атрибутам типа aria-hidden, tabindex="-1", стилям скрытия и т. д.). Новичку может показаться, что такие детали несущественны, однако это один из самых простых способов быть обнаруженным. Будет достаточно одного лишнего перехода по ссылке-ловушке — и ваш бот засвечен.
Естественно, владельцы сайтов (сервисов) знают о наличии контрмер, да и современные боты уже научились вычислять honeypot-элементы по подозрительным CSS-признакам, поэтому этот способ комбинируется с другими методами защиты. Но фильтрация невидимых ссылок/полей — обязательное условие для любого профессионального парсера.
CAPTCHA и JavaScript-челленджи
Более очевидный способ предотвратить автоматизированный доступ к своему ресурсу — CAPTCHA. Это те самые всплывающие окна с выбором картинок, галочки «Я не робот» и тому подобные вариации капч. Это прямой и весьма эффективный способ отличить человека от скрипта или бота. В отличие от скрытого honeypot, CAPTCHA демонстративно требует выполнить задание, с которым бот, предположительно, не должен справиться. Но в реальности простые виды капч можно обходить без особых сложностей, так как существует немало бесплатных open source-решений. Но более сложные капчи требуют подключения сторонних сервисов для обхода.
Если бот наткнулся на CAPTCHA, сценариев не особо много: либо решать ее автоматически через сторонний сервис, либо менять поток и переключаться на другой профиль. Платные способы распознавания капчи замедляют парсинг и повышают издержки. Вторая идея обхода капчи сводится к тому, чтобы не доводить до ее появления (снижение интенсивности запросов, чтобы не провоцировать включения защиты, или использовать кэш поисковых систем (Google Cache) для получения данных и т. п.).
Особняком стоит такой тип капчи, как JavaScript-челлендж. Многие сайты (особенно за CDN-защитой типа Cloudflare) при подозрительном трафике сначала возвращают не сам контент, а страницу-проверку, которая выполняет на стороне клиента специальный JS-код. Этот код может вычислять некий токен, проверять окружение браузера, устанавливать cookie и т. п. — после чего уже перенаправлять на реальный контент. Цель в том, чтобы убедиться, что запрос выполняется настоящим браузером с поддержкой JS, а не просто HTTP-клиентом. Бот, который не умеет исполнять JavaScript, не пройдет такой тест и не получит доступ к странице.
Как избежать: если вы знаете, что целевой ресурс выдает капчу, нужно заранее решить, как именно вы будете обходить ее — технически и финансово. Если предотвратить появление капчи не получится (на некоторых сайтах капча показывается по дефолту), придется интегрировать стороннее решение для распознавания капчи. Что касается JS-челленджей, то самый очевидный путь обхода — использовать headless-браузер, который выполнит требуемый сценарий. Популярные инструменты автоматизации (Puppeteer, Playwright и др.) позволяют запускать браузер в фоновом режиме, но не забывайте про маскировку — при работе с такими инструментами нужно заметать автоматизированные следы.
Игнорировать JS-проверку не получится: уж если она есть, то либо вы ее проходите, либо доступа к данным не будет. Убедитесь, что парсер загружает связанные скрипты, выполняет их и сохраняет полученные cookies/токены для последующих запросов.
Анализ поведения: скорость, последовательность, взаимодействия
Даже если у бота получилось пройти прямые преграды в виде капчи и других заметных антибот-методов, нечеловеческое поведение может стать фатальным для него. Когда обычный пользователь просматривает страницу товара — это минимум несколько секунд, плюс юзер ее скроллит, может кликнуть по картинке, затем переходит по ссылке. Скрипт же способен дергать страницы молниеносно, да еще и в идеально повторяющемся порядке. Современные сайты отслеживают такие аномалии при взаимодействии с их ресурсом. Чрезмерно высокая скорость переходов или загрузки страниц, подозрительно регулярный интервал между запросами и тому подобные паттерны явно указывают на роботизацию.
Еще один маркер — необычная последовательность действий (например, бот обходит сайт по алфавиту URL или по карте сайта, чего реальные посетители не делают никогда). Наконец, тривиальный признак — отсутствие на странице любых действий, которые совершает человек. Если в логах сессии видно, что пользователь просматривал 100 страниц и ни разу не проскроллил экран и не подвигал мышью, можно с большой уверенностью считать эту сессию ботом.
Сюда же относятся и временные ловушки. На формах из-за этого стали ставить ограничения на минимальное время заполнения учетных данных. Большинство людей потратят на ввод хотя бы 5–10 секунд, а бот, естественно, способен прислать форму за доли секунды. Соответственно, если форма отправлена почти мгновенно — с вероятностью 99% это автоматизация, и сайт может отклонить такую заявку. Похожий подход используется и для переходов по страницам: слишком быстрый переход к следующему шагу (особенно сложному, вроде оплаты) настораживает антибот-систему.
Как избежать: главный принцип — маскироваться под поведение реального пользователя. Внесите элемент случайности и естественности в работу вашего парсера.
Во-первых, не гонитесь за максимальной скоростью сбора данных. Если это не критично — лучше работать чуть медленнее, но осторожнее. Вставляйте паузы между запросами (причем не фиксированные, а рандомные в некотором диапазоне). Задайте скрипту задержку на каждой странице, имитируя время на чтение контента.
Во-вторых, избегайте строгой последовательности в маршруте обхода. Если у вас есть возможность, добавьте немного случайности в порядок переходов (например, меняйте очередность обхода разделов, случайно выбирайте ссылки на странице вместо последовательного перечисления).
В-третьих, добавьте признаки естественного взаимодействия в headless-сценарии. В продвинутых пайплайнах это могут быть прокрутка, движения курсора, открытие элементов интерфейса и небольшие микропаузы между шагами. Эти действия не влияют на сбор данных напрямую, но делают последовательность шагов более похожей на человеческую — особенно на длинных страницах и в многошаговых сценариях (авторизация → выбор → оформление), где слишком ровный темп и отсутствие промежутков выглядят неестественно.
Отдельно смотрите на картину со стороны сайта: многие системы комбинируют поведенческий анализ с телеметрией и веб-аналитикой. На странице могут работать трекеры, которые фиксируют события взаимодействия и тайминг сессии. Если в логах получается пустая сессия без характерных сигналов — это подозрительно само по себе. Поэтому важно оценивать не только действия вашего инструмента, но и то, какие данные об этой сессии фактически сформировались и как они интерпретируются на стороне наблюдения.
Ограничение скорости и объема запросов
Еще один очевидный критерий, по которому отличают машину от человека, — частота запросов. Даже самый скоростной пользователь не в состоянии отправлять десятки запросов в секунду, а скрипт может. Поэтому на серверной стороне внедряются ограничения: например, не более N запросов с одного IP-адреса в минуту. Если лимит превышен, включается блокировка (временная или постоянная). На уровне веб-сервера или CDN это реализуется через отслеживание количества и отсеивание всплеска запросов сверх порога. Конкретные цифры зависят от политики сайта: где-то допустимо 5 запросов в секунду, а где-то и 1 запрос в секунду будет считаться перебором. Реализовать это несложно: через Nginx можно настроить лимит в 1 запрос/секунду на IP и отклонять все, что выше этого.
Кроме частоты, смотрят и на параллельность. Обычный пользователь вряд ли открывает 20 страниц сайта одновременно в разных вкладках, а парсер легко генерирует множество потоков. Это тоже отслеживается: слишком много одновременных сессий с одного адреса — повод заподозрить ботнет или парсер.
Как избежать: во-первых, ограничьте уровень параллелизма в вашем скрипте. Да, очень соблазнительно распараллелить обход каталога на 50 потоков и собрать данные за минуту, но в 99% случаев это сразу привлечет нежелательное внимание. Лучше работайте в несколько потоков (или даже в один), если видите, что сайт чувствителен к нагрузке.
Во-вторых, позаботьтесь о смене IP-адресов. Большинство сайтов логирует IP каждого посетителя и при обнаружении подозрительной активности блокирует целиком адрес. Поэтому использование прокси — стандарт для серьезного парсинга. Имеет смысл применять ротацию IP: после определенного числа запросов или при смене раздела менять выходной адрес. Идеально — использовать резидентные или мобильные прокси. Важно настроить парсер так, чтобы один IP не делал слишком много запросов подряд. Например, отправлять не более 5–10 запросов с одного адреса, затем переключаться. Если же пул прокси ограничен, пытайтесь хотя бы чередовать их и выдерживать паузы.
Кроме того, отслеживайте заголовки и коды ответа на свои запросы. Если вы начали получать HTTP 429 Too Many Requests или видите в тексте страницы что-то вроде Too fast, try later — это явный сигнал срабатывания лимита запросов. Такая ситуация требует либо снизить темп парсинга, либо увеличить количество прокси, либо использовать другие уловки. Как вариант, если лимит настроен на IP-адрес, а сайт доступен по HTTP и позволяет без проверки сменить User-Agent и Referrer, — может помочь их чередование.
В общем, не выделяйтесь: чем незаметнее вы впишетесь в фоновый трафик обычных пользователей, тем дольше парсер проживет без блокировок.
Заголовки и отпечатки браузера
Сайты могут распознать парсер еще на этапе соединения, анализируя технические параметры запроса. Каждый HTTP-запрос несет ряд заголовков (User-Agent, Accept, Accept-Language, Cookie и др.), которые в сумме образуют профиль браузера. У обычных браузеров эти профили довольно предсказуемы: например, зайдя с Chrome на сайт, вы отправите характерный набор заголовков, начиная с User-Agent: Mozilla/5.0 ... Chrome/версия ... , плюс список поддерживаемых языков (Accept-Language), флаги фетчинга (Sec-Fetch-* headers) и т. д. Бот же может выдать нестандартный или неполный набор заголовков. Многие сайты сразу блокируют запросы с подозрительными User-Agent-строками типа Scrapy, curl, Wget, Python и т. п. на уровне брандмауэра. И даже если вас не заблокируют за наличие таких подозрительных строк, сам факт будет учтен в совокупности факторов риска.
При смене User-Agent на распространенную строчку от браузера можно проколоться на деталях. Например, Headless Chrome раньше сам себя выдавал и в строке User-Agent содержал слово HeadlessChrome. Или еще пример — бот не отправляет заголовок Accept-Language (реальные браузеры всегда шлют предпочтения языка).
Еще признак: порядок заголовков или их значения не соответствуют заявленному браузеру. Антибот-системы хранят большие базы отпечатков браузеров — шаблонов с разными заголовками и значениями от разных версий Chrome, Safari, Firefox. Если вы, притворяясь Chrome 120+, отправляете соответствующий User-Agent, но при этом у вас нет типичных для современных Chromium-заголовков UA Client Hints (Sec-CH-UA, Sec-CH-UA-Mobile, Sec-CH-UA-Platform), или они в неправильном формате, либо в навигационном запросе, инициированном кликом пользователя, не приходит Sec-Fetch-User: ?1, хотя остальные Sec-Fetch-* присутствуют, — такие мелочи могут выдать автоматизацию. Пример условный, для понимания признака.
Более того, помимо HTTP-заголовков, браузер выдает себя через объект navigator и окружение JS. В headless-режимах есть свойство navigator.webdriver, которое обычно равно true у автоматизированного браузера. Сайты на стороне клиента запускают небольшой скрипт: if (navigator.webdriver) { /* Bot detected */ } — и таким вот нехитрым образом ловят новичков. Другие проверяют наличие специфических объектов, оставляемых Selenium или Playwright. Например, Playwright-инструмент вписывает в window некие служебные переменные (__playwright__binding__ и др.), и скрипт на странице может искать такие признаки постороннего вмешательства.
К более сложным можно отнести проверки через Canvas API или WebGL, когда рисуется скрытая картинка и собирается canvas-фингерпринт, который может совпасть с типичным для эмулятора.
Проверок множество — выявить подделку окружения можно даже по мелким расхождениям в реализации JS-движка.
Как избежать: максимально маскируйтесь под реальное устройство/браузер. Всегда устанавливайте достоверный User-Agent, соответствующий популярному браузеру, и не забывайте обновлять его под современные версии. Но одного заголовка мало: подгоняйте и остальные. Добавьте Accept-Language (с учетом региона IP), Accept с типами контента как у обычного браузера, Connection, Upgrade-Insecure-Requests, Sec-Fetch-* и т. д. Проще всего взглянуть, какие заголовки отправляет ваш браузер при заходе на целевой сайт (через инструменты разработчика или прокси), и эмулировать их. Обращайте внимание на консистентность: если называете себя Chrome на Windows — у вас должен быть и Windows-ориентированный User-Agent, и заголовок Sec-CH-UA-Platform: "Windows" при необходимости.
Если работаете с headless-браузером, используйте библиотеки или настройки, которые автоматически включают скрытие автоматизации (например, в Puppeteer есть пакет puppeteer-extra-plugin-stealth, отключающий navigator.webdriver и другие маркеры, или патченные версии библиотек playwright/puppeteer от rebrowser, которые скрывают многие стандартные уязвимости этих библиотек). Если пишете низкоуровневый парсер, вручную редактируйте navigator через DevTools Protocol: выставьте свойства, совпадающие с настоящим браузером.
Конечно, нет смысла эмулировать абсолютно все вплоть до случайного шума Canvas — рекомендую начать с основного — заголовков и простого JS. Не отправляйте явно подозрительных строк, регулярно обновляйте шаблон заголовков под актуальные браузеры, включайте эмуляцию небольших взаимодействий, и, по возможности, тестируйте свой бот на антидетект. Инструменты вроде BrowserScan или FingerprintJS покажут, какие сигналы выдает ваш скрипт.
Другие хитрости: от «бесконечных лабиринтов» до сторонних сервисов
Помимо перечисленного, есть и более экзотические ловушки, о которых следует знать. Некоторые ресурсы умышленно создают «бесконечные» структуры ссылок — своего рода лабиринт для парсера.
Классический пример — динамически генерируемые бесконечные календарные страницы или параметризованные URL, ведущие в циклы. Бот, не имеющий специальных условий остановки, может застрять, пытаясь перебрать нескончаемый поток ссылок. По итогу он тратит ваши ресурсы впустую и опять же сигнализирует о себе антибот-системе необычным поведением. Для реальных пользователей такие ссылки обычно недосягаемы, а вот бот может попасть в такую ловушку.
Как избежать: во-первых, всегда анализируйте получаемые данные на правдоподобность. Если ваш парсер неожиданно ушел по цепочке ссылок куда-то не туда и накачал тонны текстов, которые выглядят как набор случайных фраз, — возможно, вы попали в лабиринт. Не помешает внедрить в парсер логику обнаружения циклов: отслеживать уже посещенные URL, ограничивать глубину обхода, проверять, что новые ссылки принадлежат тому же домену/разделу, который вам нужен.
Во-вторых, учитывайте контекст: если вы парсите, скажем, сайт отзывов, а бот вдруг начал скачивать страницы с явно несвязным ИИ-сгенерированным текстом, стоит насторожиться и прервать такую сессию.
Также имейте в виду, что помощь в детектировании ботов сайтам оказывают сторонние сервисы. Такие продукты, как Datadome, Cloudflare Bot Management, PerimeterX и др., специализируются на обнаружении автоматического трафика. Они используют комбинацию методов — от поведенческого анализа и фингерпринтинга до баз известных ботов и даже машинного обучения для выявления нетипичных посетителей.
Если ваш бот наткнулся на мощную антибот-систему, задача усложняется — вас может вычислить совокупность малых факторов. Здесь работает все, о чем мы говорили, плюс постоянное улучшение правил с той стороны. В таких случаях иногда дешевле сменить тактику либо ограничиться тем объемом запросов, который не провоцирует срабатывание защиты. При использовании прокси можно попробовать мимикрировать под разных реальных пользователей — менять не только IP, но и геолокацию, юзер-агенты, время суток запросов (имитируя заходы в разные часы, а не круглосуточную скачку).
Заключение
Как видно, не существует одной волшебной кнопки, чтобы навсегда избавить бота от риска блокировки, — нужна комбинация технических приемов и аккуратность:
Обнаруживайте и игнорируйте honeypot-элементы: перед кликом по ссылке или заполнением поля убедитесь, что элемент не скрыт от человеческих глаз. Не переходите по подозрительным URL, не заполняйте невидимые поля форм.
Мимикрия под реального пользователя: используйте реальные заголовки и значения, присущие обычным браузерам (User-Agent, Accept-Language и др.). По возможности запускайте парсинг через браузерный движок антидетект- браузеров, чтобы пройти JS-чеки и обеспечить правдоподобное окружение (navigator, cookies, localStorage и т. д.).
Ограничивайте скорость и потоки: настройте задержки и паузы между запросами, случайные интервалы. Не превышайте лимиты запросов, повышайте масштаб постепенно и следите за реакцией сайта (HTTP-коды 429, капчи и пр.).
Ротируйте IP-адреса и идентификаторы сессии: используйте пул прокси или VPN-серверов, чередуйте IP, особенно при массовых обходах. Следите, чтобы один IP не использовался слишком часто. Желательно применять резидентные IP, они менее подозрительны для антибот-систем.
Встраивайте случайность в поведение: эмулируйте действия пользователя — небольшие прокрутки, движения мыши, время чтения страницы. Избегайте полностью последовательных маршрутов: разбавляйте шаблон действий, чтобы не демонстрировать наличие четкого алгоритма.
Противостояние в веб-скрейпинге продолжается — сайты придумывают новые способы детекции, а разработчики ботов ищут обходные пути. В этой игре победит тот, кто внимательнее и изобретательнее. Пусть ваш бот будет именно таким — осторожным, гибким и по-человечески непредсказуемым.
Следите за последними новостями Octo Browser
Нажимая кнопку, вы соглашаетесь с нашей политикой конфиденциальности.
Следите за последними новостями Octo Browser
Нажимая кнопку, вы соглашаетесь с нашей политикой конфиденциальности.
Следите за последними новостями Octo Browser
Нажимая кнопку, вы соглашаетесь с нашей политикой конфиденциальности.

Присоединяйтесь к Octo Browser сейчас
Вы можете обращаться за помощью к нашим специалистам службы поддержки в чате в любое время.
Присоединяйтесь к Octo Browser сейчас
Вы можете обращаться за помощью к нашим специалистам службы поддержки в чате в любое время.
Присоединяйтесь к Octo Browser сейчас
Вы можете обращаться за помощью к нашим специалистам службы поддержки в чате в любое время.