Как обойти лимит ChatGPT
25.03.2026


Nikolai Izoitko
Content Manager, Octo Browser
ChatGPT стал привычным инструментом для работы, обучения и творчества. Однако многие активные пользователи регулярно сталкиваются с ограничениями: сервис сообщает, что достигнут лимит сообщений, и предлагает подождать или переключиться на другую модель.
Эти ограничения особенно мешают, когда работа в самом разгаре. Поэтому пользователи ищут способы увеличить доступ, обойти ограничения или хотя бы снизить их влияние.
В этой статье разберем, какие лимиты действуют в ChatGPT в 2026 году, почему они существуют и какими методами их можно обойти.
Содержание
Работайте с несколькими рекламными аккаунтами и тестируйте связки без лишней рутины. Избегайте блокировок и масштабируйте свой заработок.
Какие лимиты есть у ChatGPT
Лимиты ChatGPT зависят от тарифа, выбранной модели и текущей нагрузки на систему. При этом важно понимать: большинство ограничений не фиксированы и могут меняться.
1. Лимиты по сообщениям (rate limit)
Бесплатные пользователи могут отправлять ограниченное количество сообщений к более мощным моделям в течение нескольких часов. После этого доступ либо временно блокируется, либо предлагается перейти на более легкую модель.
В платных тарифах лимиты выше, но также остаются ограниченными: десятки или сотни сообщений за несколько часов.
2. Лимиты по моделям
Более продвинутые модели (особенно с усиленным reasoning) имеют более жесткие ограничения, чем облегченные версии. Легкие модели обычно доступны практически без строгих лимитов.
3. Лимиты по инструментам
Генерация изображений, работа с файлами и другие инструменты имеют отдельные квоты, не связанные напрямую с текстовыми сообщениями.
4. Лимиты по контексту (токены)
Каждая модель имеет ограничение на длину контекста — обычно до сотен тысяч токенов. При превышении старые сообщения обрезаются или возникает ошибка.
Почему существуют лимиты на использование ChatGPT
Лимиты в ChatGPT — это не случайное ограничение, а часть архитектуры сервиса. Они необходимы для стабильной работы системы и управляются сразу несколькими факторами.
1. Вычислительные ограничения
Современные языковые модели требуют значительных вычислительных ресурсов. Даже один запрос может задействовать сложную инфраструктуру (GPU/TPU, распределенные системы). Без ограничений это привело бы к перегрузке серверов и росту задержек.
2. Управление нагрузкой
Лимиты позволяют равномерно распределять ресурсы между пользователями. Без них наиболее активные клиенты или автоматизированные системы могли бы занять значительную часть мощности.
3. Экономическая модель
ChatGPT работает по freemium-принципу: базовый доступ ограничен, а платные тарифы предлагают более высокие лимиты и приоритетный доступ к ресурсам.
4. Безопасность
Ограничения по частоте запросов помогают предотвращать автоматизированные атаки, массовую генерацию вредоносного контента и злоупотребления API.
5. Дополнительные факторы
В некоторых случаях учитываются и косвенные аспекты, такие как энергопотребление и эффективность использования инфраструктуры.
Способы обойти лимиты ChatGPT
Полностью обойти лимиты ChatGPT нельзя — даже на платных тарифах остаются ограничения по частоте запросов и доступу к более мощным моделям. Но на практике есть несколько рабочих подходов, которые позволяют либо временно обойти лимит, либо значительно снизить его влияние и продолжить работу без долгих пауз.
Telegram-боты и приложения
Самый очевидный способ, к которому приходят пользователи после первого столкновения с лимитом, — это сторонние сервисы. В первую очередь Telegram-боты, а также отдельные AI-платформы вроде Poe, Perplexity, Grok и You.com.
Здесь важно сразу разделить ожидания и реальность. Полноценные платформы вроде Poe или Perplexity действительно работают стабильно и предоставляют доступ к разным моделям — иногда с более мягкими лимитами или собственной системой квот. Это легальный и устойчивый способ продолжить работу, просто не внутри ChatGPT, а через другой интерфейс.
А вот Telegram-боты — гораздо менее предсказуемы. Большинство из них работают через API или прокси, часто используют общий пул запросов и могут ограничивать пользователей в любой момент. Кроме того, заявления о доступе к топ-моделям или thinking-режиму в таких ботах далеко не всегда соответствуют действительности — пользователь фактически не видит, какая модель используется на самом деле.
Отдельный момент — данные. В случае с ботами вы почти всегда отправляете запросы через стороннюю инфраструктуру, которая может логировать или анализировать содержимое. Для чувствительных задач это серьезный риск.
В итоге такие сервисы действительно помогают, если нужно срочно продолжить диалог после достижения лимита. Но как основная рабочая схема они нестабильны, а контролировать их сложно.
Бесплатные пробные версии
Другой подход — использовать пробные периоды в сервисах, которые интегрируют языковые модели. Здесь вы не обходите ограничения напрямую, а временно получаете доступ к другой системе с собственными лимитами.
Например, Cursor периодически дает trial-доступ к своим AI-функциям и активно используется разработчиками. Replit предлагает встроенных AI-ассистентов с лимитами, а Codeium и Tabnine — альтернативные инструменты для работы с кодом.
Однако технически это не снятие лимита ChatGPT, а переключение на другой сервис, у которого просто есть бесплатный период или более выгодные условия для новых пользователей. Через какое-то время ограничения возвращаются — либо как лимиты, либо как необходимость оплаты.
Тем не менее как временная стратегия это работает хорошо. Особенно если задачи распределяются между разными инструментами: где-то генерация текста, где-то код, где-то поиск и анализ.
Octo Browser
Помните, что лимиты ChatGPT привязаны к аккаунту, а не к устройству. Если у вас один аккаунт — у вас один лимит. Если их несколько — лимиты суммируются. Браузер для мультиаккаунтинга Octo Browser позволяет управлять такими аккаунтами, создавая для каждого отдельный браузерный профиль с реальным цифровым отпечатком.
Это решает основную проблему: система не связывает аккаунты между собой, если они выглядят как независимые пользователи. В результате можно работать параллельно в нескольких сессиях и распределять нагрузку.
Как использовать Octo Browser для обхода лимита ChatGPT:
Создайте отдельный профиль в Octo Browser для каждого аккаунта OpenAI.
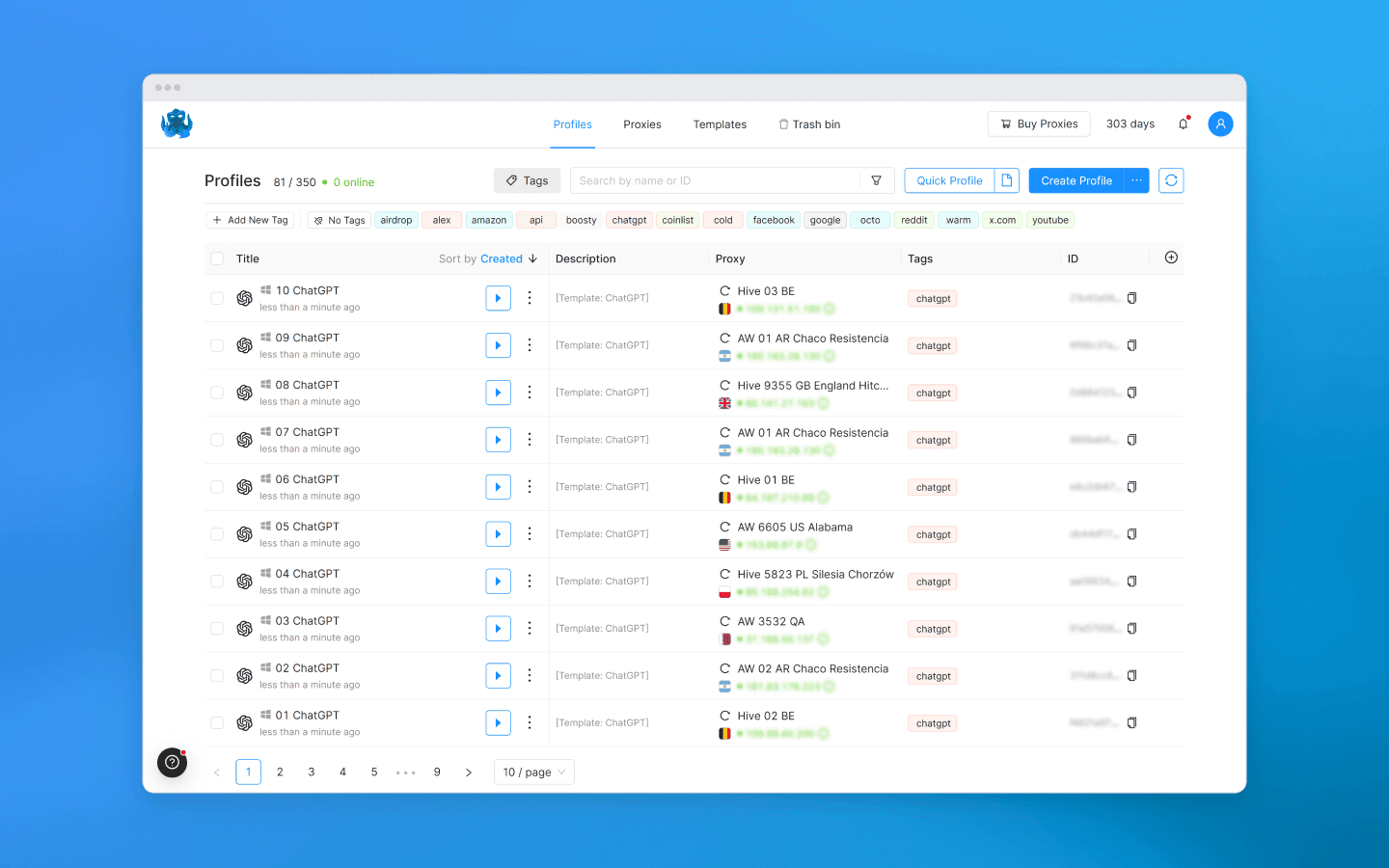
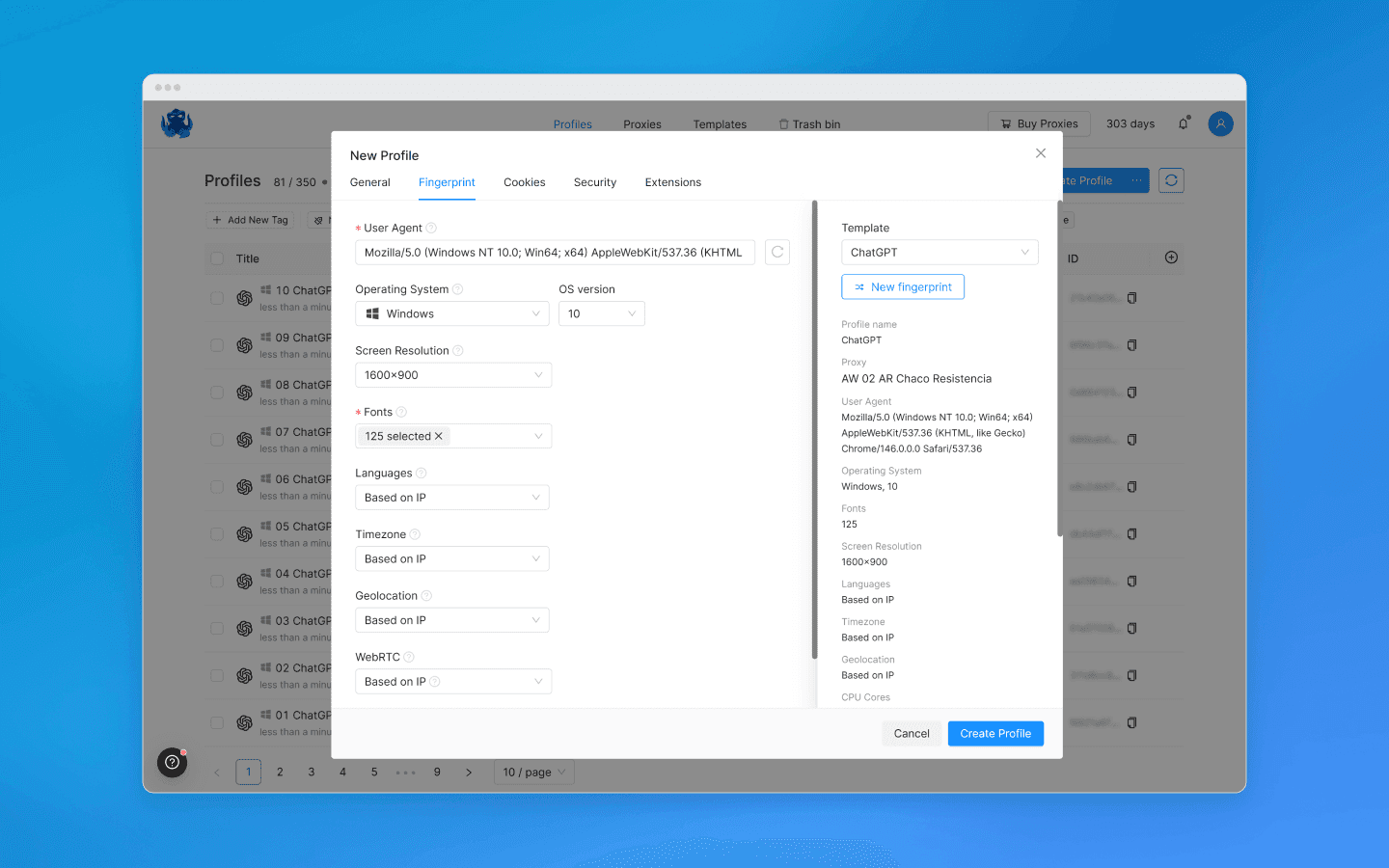
Каждый профиль получает свой цифровой отпечаток: другой Canvas, WebGL, шрифты, User-Agent, геолокацию, часовой пояс, WebRTC и т. д. Если не знаете, что выбрать, можно оставить параметры по умолчанию.
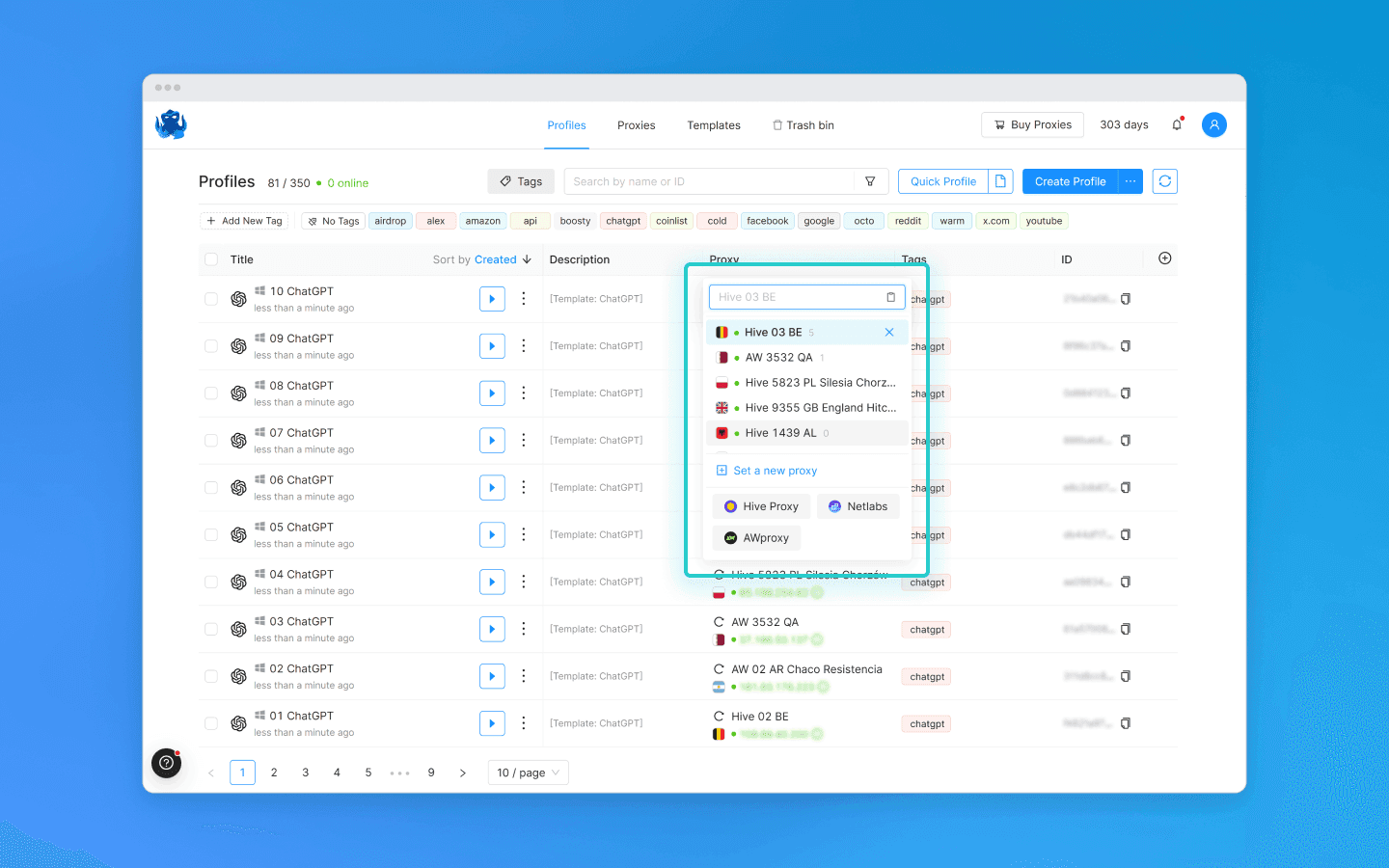
Подключите разные прокси к каждому профилю.
Зарегистрируйте/купите/арендуйте несколько аккаунтов ChatGPT.
По мере необходимости переключайтесь между профилями — лимит ChatGPT считается отдельно для каждого аккаунта.
Следует помнить: при агрессивных сценариях (массовые регистрации, одинаковые действия, подозрительная активность) риски блокировок остаются.
Советы по управлению сессиями и токенами
Даже в рамках одного аккаунта можно заметно повысить эффективность использования лимита, если грамотно работать с чатами и запросами. Эти методы не обходят лимит напрямую, но позволяют сократить количество лишних сообщений.
Повторное использование контекста, когда это возможно
Продолжение одного диалога позволяет не вводить заново инструкции, стиль и данные. ChatGPT учитывает только текущий контекст (до сотен тысяч токенов в зависимости от модели), поэтому длинные, последовательные чаты помогают сократить количество лишних сообщений.
Не создавайте новый чат по той же теме без необходимости.
Назначайте чатам понятные имена, чтобы легко ориентироваться.
Разбивайте длинный диалог на смысловые блоки только при необходимости.
Очистка контекста для сброса ограничений
Слишком длинный чат может ухудшать точность ответов и затруднять работу. Чтобы избежать этого:
Используйте встроенные функции очистки или разветвления чата (Branch in new chat в ChatGPT).
Для совершенно другой темы начинайте новый чат, перенеся только ключевые инструкции.
Следите за размером контекста, чтобы не перегружать модель.
Важно: очистка контекста не сбрасывает лимит сообщений, она помогает только управлять качеством ответов.
Разделение одного длинного запроса на несколько коротких
Огромные запросы с тысячами слов часто приводят к ошибкам и лишним уточнениям. Лучше делить задачу на шаги:
составление плана;
написание отдельных частей;
проверка и доработка.
Так вы быстрее получите качественный результат и сэкономите сообщения до лимита.
Методы оптимизации промптов
Хороший промпт — это главный способ сэкономить лимит ChatGPT. Если запрос четкий и полный, модель дает точный ответ с первого раза, без лишних уточнений.
Например, вам нужно проанализировать и отладить код на Python. Обычно именно на таких задачах лимиты быстро улетают. Вот как работать с лимитами ChatGPT экономнее.
1. Назначайте роль модели
Сразу укажите, кем модели следует себя представить. Это помогает выдавать экспертные ответы и сокращает количество уточняющих сообщений.
Пример: «Ты — senior Python-разработчик с 12-летним опытом. Пиши чистый, идиоматичный код и объясняй изменения построчно».
Такой подход превращает промпт в компактное руководство для модели, снижая количество повторных исправлений.
2. Включайте полный контекст сразу
Не отправляйте половину информации в одном сообщении, а потом уточнения. Если вы работаете с кодом, сразу давайте следующие данные:
код, выявленные ошибки, язык программирования и его версию, задачи кода;
примеры данных или желаемый формат ответа.
Пример: вместо «Почему код не работает?» — сразу: код, ошибка, версия Python, ожидаемый результат.
3. Разбейте задачу на шаги
Используйте итеративный подход, чтобы модель выполняла каждый этап отдельно, а вы могли контролировать результат и корректировать ошибки на ранних этапах.
Пример:
1. Проанализируй код на Python и найди потенциальные ошибки или уязвимости.
2. Исправь найденные ошибки и предложи оптимизацию функций.
3. Добавь тестовые примеры для проверки исправленного кода.
Так вы сохраняете контроль над процессом, уменьшаете вероятность неправильных решений и экономите сообщения, потому что каждое уточнение направлено на конкретный шаг.
4. Указывайте точный формат вывода
Если нужен структурированный ответ, пропишите формат заранее — это сокращает количество исправлений и уточнений.
Пример: «Ответ разделить на 4 блока: анализ проблемы, предложенные изменения, исправленный код, тестовые случаи».
5. Используйте примеры
Покажите модели, каким вы хотите видеть результат. Это особенно полезно при работе с кодом, таблицами или оформлением текста.
Пример:
Было:
response.json()
response.json()
Стало:
response.raise_for_status() data = response.json()
response.raise_for_status() data = response.json()
Почему: raise_for_status() выбрасывает исключение при ошибочном статусе HTTP, а response.json() возвращает данные только если запрос успешен.
6. Сокращайте лишние слова
Чем проще и точнее промпт, тем меньше расходуется токенов и сообщений.
Пример:
Плохо: «Пожалуйста, помоги с кодом, он не работает, не понимаю почему, помоги срочно».
Хорошо: «Анализ + фикс кода ниже. Ошибка: JSONDecodeError на пустом ответе. Добавь обработку ошибок сети и HTTP».
7. Используйте разделители для блоков
Если промпт содержит несколько частей, разделители типа ### помогают модели не смешивать инструкции, что повышает точность и экономит сообщения.
Использование API для управления ограничениями
API OpenAI — самый гибкий способ работать с ChatGPT без лимитов веб-интерфейса. Через API вы получаете прямой доступ к моделям (gpt-5.3, gpt-5.4, Thinking-режимы) и управляете своими квотами и токенами напрямую.
1. Получение ключа и настройка
Чтобы работать с API:
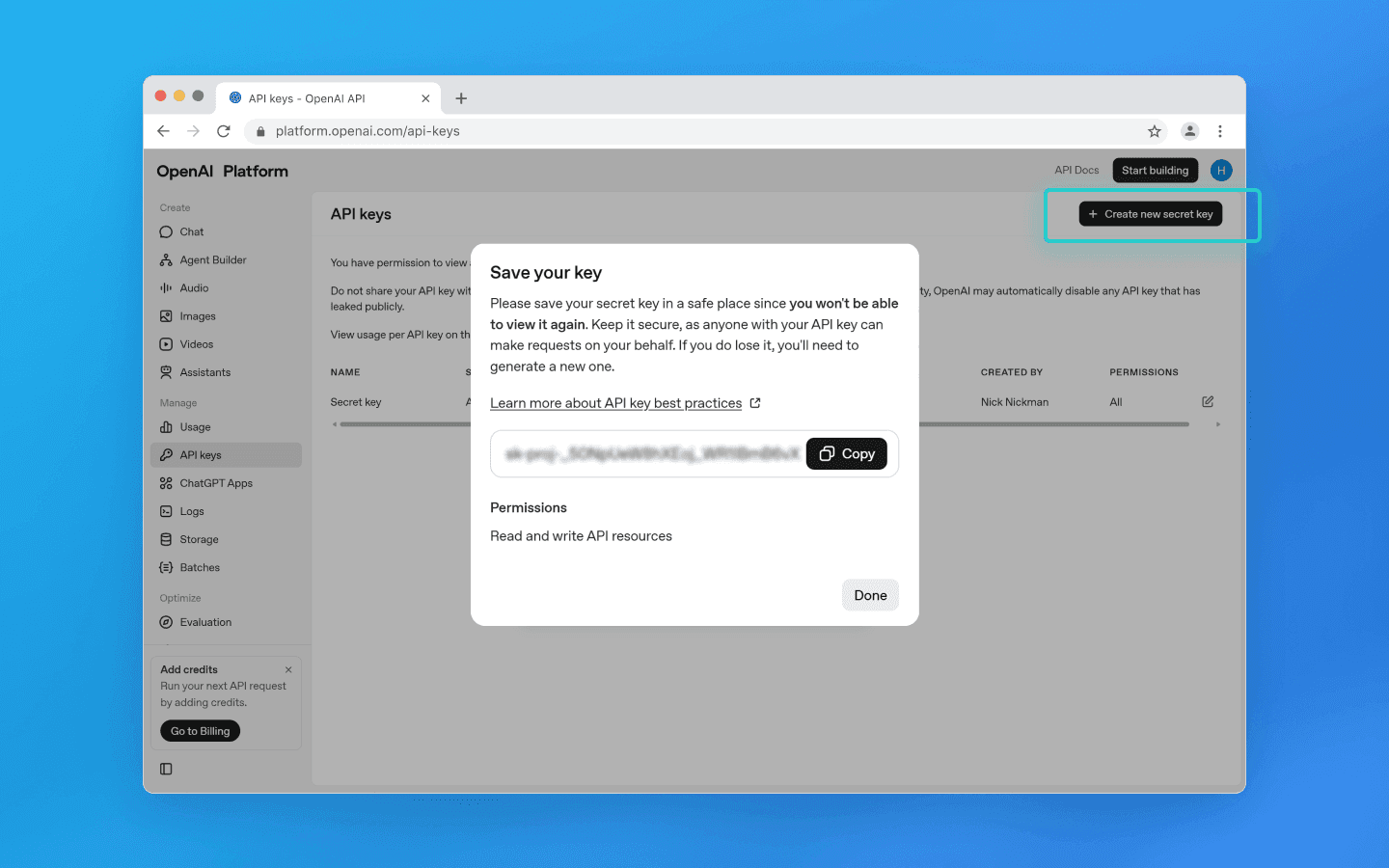
Зайдите на platform.openai.com и залогиньтесь.
Перейдите в раздел API Keys в меню слева.
Нажмите Create new secret key.
В появившемся окне при необходимости введите имя проекта и задайте разрешения, а затем нажмите Create new secret key.
Скопируйте ключ и храните его в безопасном месте — он дает полный доступ к вашему аккаунту API.
Важно: ключи не привязаны к лимитам веб-версии ChatGPT. Ограничения зависят только от вашей квоты API.
2. Квоты и лимиты API
OpenAI использует систему квот, привязанную к вашему аккаунту и оплате:
Tier 0 (новый аккаунт): небольшие лимиты, например 500–1 000 запросов в минуту и 10k токенов в минуту для мини-версий.
Tier 1+ (после оплаты более 5 $): тысячи запросов в минуту (RPM) и сотни тысяч токенов в минуту (TPM).
Tier 5 (Enterprise): почти безлимитные квоты, кастомные лимиты по договоренности.
Квоты растут автоматически при регулярной оплате и отсутствии нарушений.
Отличие от веб-интерфейса: лимиты API не зависят от сообщений в чате, они работают по RPM/TPM.
3. Эффективное использование API
Чтобы экономить квоту и работать стабильнее, советуем следующие лайфхаки:
Разумные параметры:
temperature— 0.2–0.5 для точного кода, 0.7–1.0 для креатива.max_tokens— ограничивайте размер ответа, чтобы не тратить лишние токены.top_p— обычно 0.9–1.0.
Кэшируйте ответы: повторные промпты можно хранить локально (файлы, Redis) и не отправлять заново.
Batch-запросы: можно отправлять несколько промптов одним запросом, экономя время и токены.
Легкие модели для черновиков: используйте
gpt-4o-miniилиgpt-5.3-instantдля подготовки черновиков, финализируйте на топ-модели.Stream-режим:
stream=trueпозволяет получать ответ частями, что экономит токены при прерванных сессиях.Экономный системный промпт: короткая роль / инструкции экономят токены на каждом запросе.
4. Пример Python-кода
Простейший способ вызвать API ChatGPT:
import requests api_key = "sk-..." url = "https://api.openai.com/v1/chat/completions" headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "gpt-5.3", "messages": [ {"role": "system", "content": "You are a senior Python developer. Write clean, idiomatic code."}, {"role": "user", "content": "Please review this code and fix any errors: ..."} ], "temperature": 0.3, "max_tokens": 800 } response = requests.post(url, headers=headers, json=data) print(response.json())
import requests api_key = "sk-..." url = "https://api.openai.com/v1/chat/completions" headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "gpt-5.3", "messages": [ {"role": "system", "content": "You are a senior Python developer. Write clean, idiomatic code."}, {"role": "user", "content": "Please review this code and fix any errors: ..."} ], "temperature": 0.3, "max_tokens": 800 } response = requests.post(url, headers=headers, json=data) print(response.json())
Стратегии работы с rate limit
Rate limit в ChatGPT — это ограничение на количество сообщений, которые можно отправить за определенный период времени. Оно работает по принципу rolling window (скользящего окна).
Что такое rolling window:
Вместо того чтобы ждать фиксированного сброса лимита по часам (например, ровно в 3:00), система учитывает временной промежуток с момента каждого отправленного сообщения.
Пример: у вас тариф Plus с лимитом 160 сообщений на 3 часа. Если вы отправили 1-е сообщение в 10:00, оно освободится для расчета лимита только в 13:00. Аналогично для всех последующих сообщений — окно всегда скользит вместе с временем отправки.
Это значит, что лимит постепенно восстанавливается, а не сбрасывается одномоментно.
Чтобы эффективно управлять вашим rate limit, следуйте проверенным правилам:
1. Используйте легкие версии моделей для простых задач
Mini- или Instant-версии имеют отдельные лимиты и подходят для быстрого уточнения информации, черновых идей или проверок.
2. Следите за уведомлениями
В веб-интерфейсе появятся предупреждения о приближении к лимиту.
3. Разделяйте большие задачи на блоки
Вместо одного длинного запроса лучше разбить задачу на несколько сообщений с ключевыми инструкциями. Это помогает экономить лимит, упрощает контроль и повышает качество ответов модели.
Заключение
Лимиты ChatGPT в 2026 году — это не временная проблема, а постоянная часть работы с сервисом. Для пользователей это часто становится барьером: работа останавливается, сроки срываются, приходится ждать восстановления лимита.
В статье мы разобрали актуальные ограничения, причины их появления — технические, экономические и этические — и реальные способы снизить влияние лимитов. Эффективнее всего использовать комбинацию методов: несколько аккаунтов через антидетект-браузер, грамотная оптимизация промптов и управление контекстом, работа через API с tier-квотами, а также разумное чередование пауз и легких версий модели.
Полностью убрать лимит ChatGPT без дорогой подписки Pro невозможно, но правильное применение этих подходов позволяет работать дольше и продуктивнее.
FAQ
Как долго действует ограничение по частоте запросов (rate limit) в ChatGPT?
ChatGPT использует механизм rolling window — скользящее окно времени. Это означает, что лимит не сбрасывается в фиксированный момент, а считается для каждого сообщения по мере его отправки. Когда прошло 3–5 часов с момента отправки конкретного сообщения, оно больше не учитывается в текущем окне.
Различаются ли лимиты у разных моделей?
Лимиты зависят от плана подписки. На тарифе Free доступ к продвинутым моделям ограничен (часто около 10 сообщений на несколько часов), после чего чат часто переключается на более легкую модель (mini‑версию). Платные планы (например, Plus) предлагают заметно большие квоты сообщений в том же 3‑часовом окне.
Можно ли изменить лимиты использования API?
Да, но не вручную. В API OpenAI лимиты задаются через систему квот (rate limits и spending limits) и автоматически увеличиваются по мере использования и оплаты. Чем стабильнее платежи и выше объем потребления, тем выше доступные лимиты (RPM/TPM). В отдельных случаях для крупных клиентов лимиты могут быть увеличены через поддержку.
Сбрасываются ли лимиты при использовании ChatGPT в разных браузерах?
Нет. Лимиты не зависят от браузера. Они привязаны к аккаунту, поэтому при использовании разных браузеров или вкладок счетчик сообщений остается общим.
Зависят ли лимиты ChatGPT от аккаунта или от устройства?
Лимиты зависят от аккаунта. Устройство, браузер или IP-адрес не влияют на количество доступных сообщений. Один аккаунт — один общий лимит.
В чем разница между лимитами по токенам и ограничением по частоте запросов?
Это разные механизмы. Лимит по токенам определяет, сколько текста (вход + ответ) может быть обработано в одном запросе или в контексте диалога. Ограничение по частоте запросов (rate limit) определяет, как часто можно отправлять запросы за определенный период времени. Можно упереться в одно ограничение, не достигнув другого.
Работайте с несколькими рекламными аккаунтами и тестируйте связки без лишней рутины. Избегайте блокировок и масштабируйте свой заработок.
Какие лимиты есть у ChatGPT
Лимиты ChatGPT зависят от тарифа, выбранной модели и текущей нагрузки на систему. При этом важно понимать: большинство ограничений не фиксированы и могут меняться.
1. Лимиты по сообщениям (rate limit)
Бесплатные пользователи могут отправлять ограниченное количество сообщений к более мощным моделям в течение нескольких часов. После этого доступ либо временно блокируется, либо предлагается перейти на более легкую модель.
В платных тарифах лимиты выше, но также остаются ограниченными: десятки или сотни сообщений за несколько часов.
2. Лимиты по моделям
Более продвинутые модели (особенно с усиленным reasoning) имеют более жесткие ограничения, чем облегченные версии. Легкие модели обычно доступны практически без строгих лимитов.
3. Лимиты по инструментам
Генерация изображений, работа с файлами и другие инструменты имеют отдельные квоты, не связанные напрямую с текстовыми сообщениями.
4. Лимиты по контексту (токены)
Каждая модель имеет ограничение на длину контекста — обычно до сотен тысяч токенов. При превышении старые сообщения обрезаются или возникает ошибка.
Почему существуют лимиты на использование ChatGPT
Лимиты в ChatGPT — это не случайное ограничение, а часть архитектуры сервиса. Они необходимы для стабильной работы системы и управляются сразу несколькими факторами.
1. Вычислительные ограничения
Современные языковые модели требуют значительных вычислительных ресурсов. Даже один запрос может задействовать сложную инфраструктуру (GPU/TPU, распределенные системы). Без ограничений это привело бы к перегрузке серверов и росту задержек.
2. Управление нагрузкой
Лимиты позволяют равномерно распределять ресурсы между пользователями. Без них наиболее активные клиенты или автоматизированные системы могли бы занять значительную часть мощности.
3. Экономическая модель
ChatGPT работает по freemium-принципу: базовый доступ ограничен, а платные тарифы предлагают более высокие лимиты и приоритетный доступ к ресурсам.
4. Безопасность
Ограничения по частоте запросов помогают предотвращать автоматизированные атаки, массовую генерацию вредоносного контента и злоупотребления API.
5. Дополнительные факторы
В некоторых случаях учитываются и косвенные аспекты, такие как энергопотребление и эффективность использования инфраструктуры.
Способы обойти лимиты ChatGPT
Полностью обойти лимиты ChatGPT нельзя — даже на платных тарифах остаются ограничения по частоте запросов и доступу к более мощным моделям. Но на практике есть несколько рабочих подходов, которые позволяют либо временно обойти лимит, либо значительно снизить его влияние и продолжить работу без долгих пауз.
Telegram-боты и приложения
Самый очевидный способ, к которому приходят пользователи после первого столкновения с лимитом, — это сторонние сервисы. В первую очередь Telegram-боты, а также отдельные AI-платформы вроде Poe, Perplexity, Grok и You.com.
Здесь важно сразу разделить ожидания и реальность. Полноценные платформы вроде Poe или Perplexity действительно работают стабильно и предоставляют доступ к разным моделям — иногда с более мягкими лимитами или собственной системой квот. Это легальный и устойчивый способ продолжить работу, просто не внутри ChatGPT, а через другой интерфейс.
А вот Telegram-боты — гораздо менее предсказуемы. Большинство из них работают через API или прокси, часто используют общий пул запросов и могут ограничивать пользователей в любой момент. Кроме того, заявления о доступе к топ-моделям или thinking-режиму в таких ботах далеко не всегда соответствуют действительности — пользователь фактически не видит, какая модель используется на самом деле.
Отдельный момент — данные. В случае с ботами вы почти всегда отправляете запросы через стороннюю инфраструктуру, которая может логировать или анализировать содержимое. Для чувствительных задач это серьезный риск.
В итоге такие сервисы действительно помогают, если нужно срочно продолжить диалог после достижения лимита. Но как основная рабочая схема они нестабильны, а контролировать их сложно.
Бесплатные пробные версии
Другой подход — использовать пробные периоды в сервисах, которые интегрируют языковые модели. Здесь вы не обходите ограничения напрямую, а временно получаете доступ к другой системе с собственными лимитами.
Например, Cursor периодически дает trial-доступ к своим AI-функциям и активно используется разработчиками. Replit предлагает встроенных AI-ассистентов с лимитами, а Codeium и Tabnine — альтернативные инструменты для работы с кодом.
Однако технически это не снятие лимита ChatGPT, а переключение на другой сервис, у которого просто есть бесплатный период или более выгодные условия для новых пользователей. Через какое-то время ограничения возвращаются — либо как лимиты, либо как необходимость оплаты.
Тем не менее как временная стратегия это работает хорошо. Особенно если задачи распределяются между разными инструментами: где-то генерация текста, где-то код, где-то поиск и анализ.
Octo Browser
Помните, что лимиты ChatGPT привязаны к аккаунту, а не к устройству. Если у вас один аккаунт — у вас один лимит. Если их несколько — лимиты суммируются. Браузер для мультиаккаунтинга Octo Browser позволяет управлять такими аккаунтами, создавая для каждого отдельный браузерный профиль с реальным цифровым отпечатком.
Это решает основную проблему: система не связывает аккаунты между собой, если они выглядят как независимые пользователи. В результате можно работать параллельно в нескольких сессиях и распределять нагрузку.
Как использовать Octo Browser для обхода лимита ChatGPT:
Создайте отдельный профиль в Octo Browser для каждого аккаунта OpenAI.
Каждый профиль получает свой цифровой отпечаток: другой Canvas, WebGL, шрифты, User-Agent, геолокацию, часовой пояс, WebRTC и т. д. Если не знаете, что выбрать, можно оставить параметры по умолчанию.
Подключите разные прокси к каждому профилю.
Зарегистрируйте/купите/арендуйте несколько аккаунтов ChatGPT.
По мере необходимости переключайтесь между профилями — лимит ChatGPT считается отдельно для каждого аккаунта.
Следует помнить: при агрессивных сценариях (массовые регистрации, одинаковые действия, подозрительная активность) риски блокировок остаются.
Советы по управлению сессиями и токенами
Даже в рамках одного аккаунта можно заметно повысить эффективность использования лимита, если грамотно работать с чатами и запросами. Эти методы не обходят лимит напрямую, но позволяют сократить количество лишних сообщений.
Повторное использование контекста, когда это возможно
Продолжение одного диалога позволяет не вводить заново инструкции, стиль и данные. ChatGPT учитывает только текущий контекст (до сотен тысяч токенов в зависимости от модели), поэтому длинные, последовательные чаты помогают сократить количество лишних сообщений.
Не создавайте новый чат по той же теме без необходимости.
Назначайте чатам понятные имена, чтобы легко ориентироваться.
Разбивайте длинный диалог на смысловые блоки только при необходимости.
Очистка контекста для сброса ограничений
Слишком длинный чат может ухудшать точность ответов и затруднять работу. Чтобы избежать этого:
Используйте встроенные функции очистки или разветвления чата (Branch in new chat в ChatGPT).
Для совершенно другой темы начинайте новый чат, перенеся только ключевые инструкции.
Следите за размером контекста, чтобы не перегружать модель.
Важно: очистка контекста не сбрасывает лимит сообщений, она помогает только управлять качеством ответов.
Разделение одного длинного запроса на несколько коротких
Огромные запросы с тысячами слов часто приводят к ошибкам и лишним уточнениям. Лучше делить задачу на шаги:
составление плана;
написание отдельных частей;
проверка и доработка.
Так вы быстрее получите качественный результат и сэкономите сообщения до лимита.
Методы оптимизации промптов
Хороший промпт — это главный способ сэкономить лимит ChatGPT. Если запрос четкий и полный, модель дает точный ответ с первого раза, без лишних уточнений.
Например, вам нужно проанализировать и отладить код на Python. Обычно именно на таких задачах лимиты быстро улетают. Вот как работать с лимитами ChatGPT экономнее.
1. Назначайте роль модели
Сразу укажите, кем модели следует себя представить. Это помогает выдавать экспертные ответы и сокращает количество уточняющих сообщений.
Пример: «Ты — senior Python-разработчик с 12-летним опытом. Пиши чистый, идиоматичный код и объясняй изменения построчно».
Такой подход превращает промпт в компактное руководство для модели, снижая количество повторных исправлений.
2. Включайте полный контекст сразу
Не отправляйте половину информации в одном сообщении, а потом уточнения. Если вы работаете с кодом, сразу давайте следующие данные:
код, выявленные ошибки, язык программирования и его версию, задачи кода;
примеры данных или желаемый формат ответа.
Пример: вместо «Почему код не работает?» — сразу: код, ошибка, версия Python, ожидаемый результат.
3. Разбейте задачу на шаги
Используйте итеративный подход, чтобы модель выполняла каждый этап отдельно, а вы могли контролировать результат и корректировать ошибки на ранних этапах.
Пример:
1. Проанализируй код на Python и найди потенциальные ошибки или уязвимости.
2. Исправь найденные ошибки и предложи оптимизацию функций.
3. Добавь тестовые примеры для проверки исправленного кода.
Так вы сохраняете контроль над процессом, уменьшаете вероятность неправильных решений и экономите сообщения, потому что каждое уточнение направлено на конкретный шаг.
4. Указывайте точный формат вывода
Если нужен структурированный ответ, пропишите формат заранее — это сокращает количество исправлений и уточнений.
Пример: «Ответ разделить на 4 блока: анализ проблемы, предложенные изменения, исправленный код, тестовые случаи».
5. Используйте примеры
Покажите модели, каким вы хотите видеть результат. Это особенно полезно при работе с кодом, таблицами или оформлением текста.
Пример:
Было:
response.json()
Стало:
response.raise_for_status() data = response.json()
Почему: raise_for_status() выбрасывает исключение при ошибочном статусе HTTP, а response.json() возвращает данные только если запрос успешен.
6. Сокращайте лишние слова
Чем проще и точнее промпт, тем меньше расходуется токенов и сообщений.
Пример:
Плохо: «Пожалуйста, помоги с кодом, он не работает, не понимаю почему, помоги срочно».
Хорошо: «Анализ + фикс кода ниже. Ошибка: JSONDecodeError на пустом ответе. Добавь обработку ошибок сети и HTTP».
7. Используйте разделители для блоков
Если промпт содержит несколько частей, разделители типа ### помогают модели не смешивать инструкции, что повышает точность и экономит сообщения.
Использование API для управления ограничениями
API OpenAI — самый гибкий способ работать с ChatGPT без лимитов веб-интерфейса. Через API вы получаете прямой доступ к моделям (gpt-5.3, gpt-5.4, Thinking-режимы) и управляете своими квотами и токенами напрямую.
1. Получение ключа и настройка
Чтобы работать с API:
Зайдите на platform.openai.com и залогиньтесь.
Перейдите в раздел API Keys в меню слева.
Нажмите Create new secret key.
В появившемся окне при необходимости введите имя проекта и задайте разрешения, а затем нажмите Create new secret key.
Скопируйте ключ и храните его в безопасном месте — он дает полный доступ к вашему аккаунту API.
Важно: ключи не привязаны к лимитам веб-версии ChatGPT. Ограничения зависят только от вашей квоты API.
2. Квоты и лимиты API
OpenAI использует систему квот, привязанную к вашему аккаунту и оплате:
Tier 0 (новый аккаунт): небольшие лимиты, например 500–1 000 запросов в минуту и 10k токенов в минуту для мини-версий.
Tier 1+ (после оплаты более 5 $): тысячи запросов в минуту (RPM) и сотни тысяч токенов в минуту (TPM).
Tier 5 (Enterprise): почти безлимитные квоты, кастомные лимиты по договоренности.
Квоты растут автоматически при регулярной оплате и отсутствии нарушений.
Отличие от веб-интерфейса: лимиты API не зависят от сообщений в чате, они работают по RPM/TPM.
3. Эффективное использование API
Чтобы экономить квоту и работать стабильнее, советуем следующие лайфхаки:
Разумные параметры:
temperature— 0.2–0.5 для точного кода, 0.7–1.0 для креатива.max_tokens— ограничивайте размер ответа, чтобы не тратить лишние токены.top_p— обычно 0.9–1.0.
Кэшируйте ответы: повторные промпты можно хранить локально (файлы, Redis) и не отправлять заново.
Batch-запросы: можно отправлять несколько промптов одним запросом, экономя время и токены.
Легкие модели для черновиков: используйте
gpt-4o-miniилиgpt-5.3-instantдля подготовки черновиков, финализируйте на топ-модели.Stream-режим:
stream=trueпозволяет получать ответ частями, что экономит токены при прерванных сессиях.Экономный системный промпт: короткая роль / инструкции экономят токены на каждом запросе.
4. Пример Python-кода
Простейший способ вызвать API ChatGPT:
import requests api_key = "sk-..." url = "https://api.openai.com/v1/chat/completions" headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "gpt-5.3", "messages": [ {"role": "system", "content": "You are a senior Python developer. Write clean, idiomatic code."}, {"role": "user", "content": "Please review this code and fix any errors: ..."} ], "temperature": 0.3, "max_tokens": 800 } response = requests.post(url, headers=headers, json=data) print(response.json())
Стратегии работы с rate limit
Rate limit в ChatGPT — это ограничение на количество сообщений, которые можно отправить за определенный период времени. Оно работает по принципу rolling window (скользящего окна).
Что такое rolling window:
Вместо того чтобы ждать фиксированного сброса лимита по часам (например, ровно в 3:00), система учитывает временной промежуток с момента каждого отправленного сообщения.
Пример: у вас тариф Plus с лимитом 160 сообщений на 3 часа. Если вы отправили 1-е сообщение в 10:00, оно освободится для расчета лимита только в 13:00. Аналогично для всех последующих сообщений — окно всегда скользит вместе с временем отправки.
Это значит, что лимит постепенно восстанавливается, а не сбрасывается одномоментно.
Чтобы эффективно управлять вашим rate limit, следуйте проверенным правилам:
1. Используйте легкие версии моделей для простых задач
Mini- или Instant-версии имеют отдельные лимиты и подходят для быстрого уточнения информации, черновых идей или проверок.
2. Следите за уведомлениями
В веб-интерфейсе появятся предупреждения о приближении к лимиту.
3. Разделяйте большие задачи на блоки
Вместо одного длинного запроса лучше разбить задачу на несколько сообщений с ключевыми инструкциями. Это помогает экономить лимит, упрощает контроль и повышает качество ответов модели.
Заключение
Лимиты ChatGPT в 2026 году — это не временная проблема, а постоянная часть работы с сервисом. Для пользователей это часто становится барьером: работа останавливается, сроки срываются, приходится ждать восстановления лимита.
В статье мы разобрали актуальные ограничения, причины их появления — технические, экономические и этические — и реальные способы снизить влияние лимитов. Эффективнее всего использовать комбинацию методов: несколько аккаунтов через антидетект-браузер, грамотная оптимизация промптов и управление контекстом, работа через API с tier-квотами, а также разумное чередование пауз и легких версий модели.
Полностью убрать лимит ChatGPT без дорогой подписки Pro невозможно, но правильное применение этих подходов позволяет работать дольше и продуктивнее.
FAQ
Как долго действует ограничение по частоте запросов (rate limit) в ChatGPT?
ChatGPT использует механизм rolling window — скользящее окно времени. Это означает, что лимит не сбрасывается в фиксированный момент, а считается для каждого сообщения по мере его отправки. Когда прошло 3–5 часов с момента отправки конкретного сообщения, оно больше не учитывается в текущем окне.
Различаются ли лимиты у разных моделей?
Лимиты зависят от плана подписки. На тарифе Free доступ к продвинутым моделям ограничен (часто около 10 сообщений на несколько часов), после чего чат часто переключается на более легкую модель (mini‑версию). Платные планы (например, Plus) предлагают заметно большие квоты сообщений в том же 3‑часовом окне.
Можно ли изменить лимиты использования API?
Да, но не вручную. В API OpenAI лимиты задаются через систему квот (rate limits и spending limits) и автоматически увеличиваются по мере использования и оплаты. Чем стабильнее платежи и выше объем потребления, тем выше доступные лимиты (RPM/TPM). В отдельных случаях для крупных клиентов лимиты могут быть увеличены через поддержку.
Сбрасываются ли лимиты при использовании ChatGPT в разных браузерах?
Нет. Лимиты не зависят от браузера. Они привязаны к аккаунту, поэтому при использовании разных браузеров или вкладок счетчик сообщений остается общим.
Зависят ли лимиты ChatGPT от аккаунта или от устройства?
Лимиты зависят от аккаунта. Устройство, браузер или IP-адрес не влияют на количество доступных сообщений. Один аккаунт — один общий лимит.
В чем разница между лимитами по токенам и ограничением по частоте запросов?
Это разные механизмы. Лимит по токенам определяет, сколько текста (вход + ответ) может быть обработано в одном запросе или в контексте диалога. Ограничение по частоте запросов (rate limit) определяет, как часто можно отправлять запросы за определенный период времени. Можно упереться в одно ограничение, не достигнув другого.
Следите за последними новостями Octo Browser
Нажимая кнопку, вы соглашаетесь с нашей политикой конфиденциальности.
Следите за последними новостями Octo Browser
Нажимая кнопку, вы соглашаетесь с нашей политикой конфиденциальности.
Следите за последними новостями Octo Browser
Нажимая кнопку, вы соглашаетесь с нашей политикой конфиденциальности.

Присоединяйтесь к Octo Browser сейчас
Вы можете обращаться за помощью к нашим специалистам службы поддержки в чате в любое время.
Присоединяйтесь к Octo Browser сейчас
Вы можете обращаться за помощью к нашим специалистам службы поддержки в чате в любое время.
Присоединяйтесь к Octo Browser сейчас
Вы можете обращаться за помощью к нашим специалистам службы поддержки в чате в любое время.