Cách cạo dữ liệu từ Amazon


Artur Hvalei
Technical Support Specialist, Octo Browser
Amazon là một trong những nền tảng thương mại điện tử lớn nhất thế giới và là nguồn dữ liệu quý giá rộng lớn. Việc trích xuất và sử dụng hiệu quả thông tin về sản phẩm, giá cả và đánh giá của khách hàng là rất quan trọng cho sự phát triển kinh doanh. Cho dù bạn đang quảng bá sản phẩm của mình hay theo dõi đối thủ cạnh tranh, bạn sẽ cần các công cụ thu thập dữ liệu để phân tích thị trường. Tuy nhiên, việc khai thác dữ liệu trên Amazon có những đặc thù mà bạn cần lưu ý. Trong bài viết này, chúng tôi sẽ thảo luận về các bước cần thiết bạn cần thực hiện để tạo một công cụ thu thập dữ liệu web, và một chuyên gia từ Đội ngũ Octo sẽ cung cấp một mã ví dụ cho việc khai thác dữ liệu trên Amazon.
Nội dung
Giữ kín danh tính, tận dụng tính năng nhiều tài khoản và đạt được mục tiêu của bạn với trình duyệt chống phát hiện chất lượng cao nhất trên thị trường.
Bạn có muốn thử Octo Browser với giá giảm không?
Sử dụng mã khuyến mãi OCTOSCRAPER để được giảm giá 30% cho bất kỳ gói đăng ký nào. Ưu đãi này chỉ dành cho người dùng mới.
Web Scraping là gì?
Web scraping là quá trình thu thập dữ liệu tự động từ các trang web. Các chương trình hoặc script đặc biệt, gọi là scrapers, sẽ trích xuất thông tin từ các trang web và chuyển đổi nó thành định dạng dữ liệu có cấu trúc, thuận tiện cho việc phân tích và sử dụng tiếp theo. Các định dạng phổ biến nhất để lưu trữ và xử lý dữ liệu là CSV, JSON, SQL, hoặc Excel.
Ngày nay, web scraping được sử dụng rộng rãi trong Khoa học Dữ liệu, marketing và thương mại điện tử. Các công cụ web scraper thu thập lượng lớn thông tin vì mục đích cá nhân và công việc. Hơn nữa, các tập đoàn công nghệ hiện đại dựa vào phương pháp web scraping để theo dõi và phân tích xu hướng.
Công cụ và Công nghệ cho Web Scraping
Python và Thư viện
Python là một trong những ngôn ngữ lập trình phổ biến nhất cho web scraping. Nó nổi tiếng với cú pháp đơn giản và rõ ràng, làm cho nó trở thành lựa chọn lý tưởng cho cả người mới bắt đầu và người lập trình có kinh nghiệm. Một ưu điểm khác là phạm vi rộng các thư viện có sẵn cho web scraping, chẳng hạn như Beautiful Soup, Scrapy, Requests và Selenium. Những thư viện này cho phép bạn dễ dàng gửi yêu cầu HTTP, xử lý tài liệu HTML, và tương tác với các trang web.
API
Amazon cung cấp API để truy cập dữ liệu của nó, chẳng hạn như Amazon Product Advertising API. Điều này cho phép bạn yêu cầu thông tin cụ thể trong định dạng có cấu trúc mà không phải phân tích toàn bộ trang HTML.
Dịch vụ Đám mây
Các nền tảng đám mây như AWS Lambda và Google Cloud Functions có thể được sử dụng để tự động hóa và mở rộng các quy trình web scraping. Chúng cung cấp hiệu suất cao và khả năng xử lý các khối lượng dữ liệu lớn.
Các Công cụ Chuyên Dụng
Có thêm các công cụ cho web scraping, chẳng hạn như trình duyệt đa tài khoản và proxy. Vai trò của chúng là giả mạo dấu vân tay kỹ thuật số để vượt qua các giới hạn bảo mật của trang web. Những công cụ này tăng tốc thu thập dữ liệu.
Ứng dụng của Amazon Web Scraping
Phân Tích Thị Trường và Cạnh Tranh
Web scraping cho phép bạn thu thập dữ liệu về sản phẩm và giá cả của đối thủ, phân tích phạm vi sản phẩm và xác định xu hướng. Điều này giúp các công ty điều chỉnh chiến lược của mình và duy trì khả năng cạnh tranh.
Giám Sát Giá
Thu thập dữ liệu về giá cho các sản phẩm tương tự giúp các công ty đặt giá cạnh tranh và phản ứng kịp thời với sự thay đổi của thị trường. Điều này đặc biệt quan trọng trong bối cảnh giá động và khuyến mãi.
Thu thập Đánh Giá và Xếp Hạng
Đánh giá và xếp hạng là một nguồn thông tin quan trọng về cách người tiêu dùng nhận thức sản phẩm. Phân tích dữ liệu này giúp xác định điểm mạnh và điểm yếu của sản phẩm, cũng như đưa ra ý tưởng cho việc cải tiến chúng.
Nghiên Cứu Sản Phẩm
Sử dụng web scraping, bạn có thể phân tích phạm vi sản phẩm trên Amazon, xác định các danh mục phổ biến và từ đó đưa ra quyết định về việc mở rộng hoặc thay đổi danh mục sản phẩm.
Theo Dõi Sản Phẩm Mới
Web scraping có thể giúp bạn nhanh chóng biết về sự xuất hiện của sản phẩm mới trên nền tảng, điều này có thể hữu ích cho các nhà sản xuất, nhà phân phối và nhà phân tích thị trường.
Điều Hướng Các Thành Phần Giao Diện Của Amazon
Trước khi bạn bắt đầu scraping, điều quan trọng là phải hiểu cách trang web được cấu trúc. Hầu hết các trang web được viết bằng HTML và chứa các yếu tố như thẻ, thuộc tính và lớp. Biết về HTML sẽ giúp bạn xác định và trích xuất chính xác dữ liệu cần thiết.
Trên trang chủ của Amazon, người mua sử dụng thanh tìm kiếm để nhập các từ khóa liên quan đến sản phẩm mong muốn. Kết quả là họ nhận được một danh sách với tên sản phẩm, giá cả, xếp hạng và các thuộc tính cần thiết khác. Ngoài ra, sản phẩm có thể được lọc theo các tham số khác nhau như phạm vi giá, danh mục sản phẩm và đánh giá khách hàng. Điều hướng các thành phần này giúp người dùng dễ dàng tìm kiếm sản phẩm họ quan tâm, so sánh các lựa chọn thay thế, xem thông tin bổ sung và thận tiện mua sản phẩm trên Amazon.
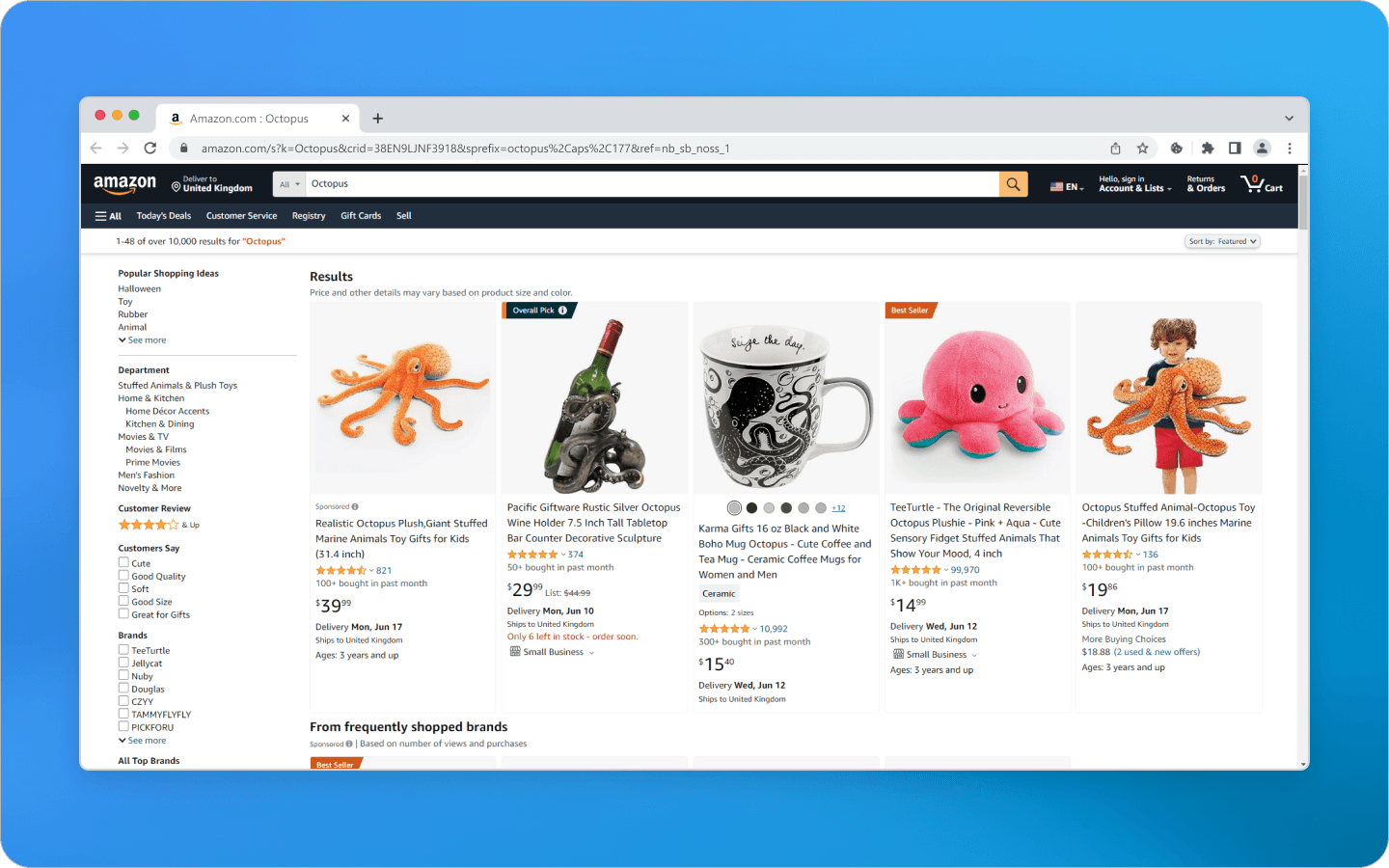
Trang chủ Amazon với một truy vấn tìm kiếm cho Octopus
Để có danh sách kết quả phong phú hơn, bạn có thể sử dụng các nút phân trang nằm dưới cùng trang. Mỗi trang thường chứa một lượng lớn danh sách, cho phép bạn duyệt thêm nhiều sản phẩm. Các bộ lọc ở đầu trang cho phép bạn tinh chỉnh tìm kiếm theo yêu cầu của mình.
Để hiểu cấu trúc HTML của Amazon, hãy làm theo các bước sau:
Truy cập vào trang web.
Tìm kiếm sản phẩm mong muốn bằng thanh tìm kiếm hoặc chọn danh mục từ danh sách sản phẩm.
Mở công cụ phát triển bằng cách nhấp chuột phải vào sản phẩm và chọn Inspect từ menu thả xuống.
Khám phá bố cục HTML để xác định các thẻ và thuộc tính của dữ liệu bạn dự định trích xuất.
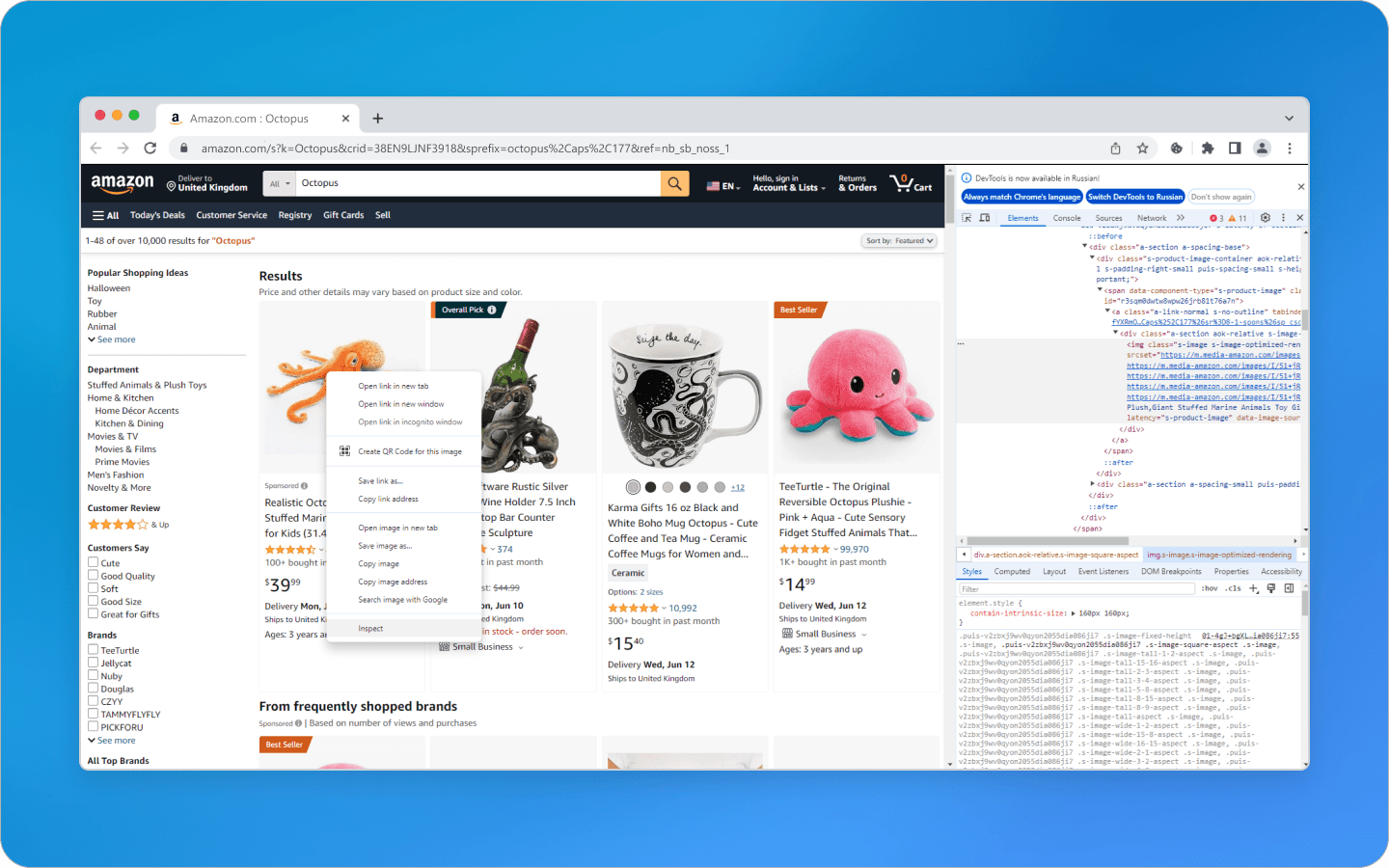
Các Bước Chính Để Bắt Đầu Scraping
Web scraping bao gồm hai bước chính: tìm kiếm thông tin cần thiết và cấu trúc lại nó. Sau khi nghiên cứu cấu trúc của trang web, chúng ta hãy thiết lập các thành phần cần thiết để tự động hóa quá trình scraping.
Đối với nhiệm vụ này, chúng ta sẽ sử dụng Python và các thư viện của nó:
HTTPX là một thư viện Python HTTP đồng bộ hoàn toàn và cũng hỗ trợ thực hiện các yêu cầu không đồng bộ. HTTPX cung cấp giao diện chuẩn HTTP giống với thư viện yêu cầu phổ biến nhưng bổ sung hỗ trợ cho không đồng bộ, các giao thức HTTP/1.1, HTTP/2, HTTP/3, và các kết nối SOCKS.
BeautifulSoup: Thư viện này được thiết kế để phân tích HTML và tài liệu XML một cách dễ dàng và nhanh chóng. Nó cung cấp giao diện đơn giản để điều hướng, tìm kiếm và sửa đổi cây tài liệu, làm cho quá trình web scraping trở nên trực quan hơn. Nó cho phép bạn trích xuất thông tin từ một trang bằng cách tìm kiếm các thẻ, thuộc tính hoặc văn bản cụ thể.
Selenium: Để tương tác với các trang web động.
Pandas: Đây là một thư viện mạnh mẽ và đáng tin cậy để xử lý và làm sạch dữ liệu. Chẳng hạn, sau khi trích xuất dữ liệu từ các trang web, bạn có thể sử dụng Pandas để xử lý các giá trị thiếu, chuyển đổi dữ liệu sang định dạng yêu cầu và loại bỏ các bản sao.
Playwright: Cho phép tương tác hiệu quả với các trang web sử dụng JavaScript để cập nhật nội dung động. Điều này đặc biệt hữu ích cho scraping các trang web như Amazon, nơi mà nhiều yếu tố tải không đồng bộ.
Scrapy: Để xử lý các nhiệm vụ web scraping phức tạp hơn.
Một khi bạn đã chuẩn bị Python, mở terminal hoặc shell và tạo một thư mục dự án mới bằng cách sử dụng các lệnh sau:
mkdir scraping-amazon-python cd scraping-amazon-python
mkdir scraping-amazon-python cd scraping-amazon-python
Để cài đặt các thư viện, mở terminal hoặc shell và chạy các lệnh sau:
pip install httpx pip3 install pandas pip3 install playwright playwright install
pip install httpx pip3 install pandas pip3 install playwright playwright install
Lưu ý: Lệnh cuối cùng (playwright install) rất quan trọng vì nó đảm bảo cài đặt đúng các tệp trình duyệt cần thiết.
Hãy đảm bảo rằng quá trình cài đặt hoàn tất mà không gặp bất kỳ vấn đề nào trước khi tiến hành bước tiếp theo. Nếu bạn gặp khó khăn trong việc thiết lập môi trường, bạn có thể tham khảo các dịch vụ AI như ChatGPT, Mistral AI, và các dịch vụ khác. Các dịch vụ này có thể giúp xử lý lỗi và cung cấp hướng dẫn từng bước để giải quyết chúng.
Sử Dụng Python và Thư Viện Cho Web Scraping
Trong thư mục dự án của bạn, tạo một tập lệnh Python mới có tên là amazon_scraper.py và thêm mã sau:
import httpx from playwright.async_api import async_playwright import asyncio import pandas as pd # Profile's uuid from Octo PROFILE_UUID = "UUID_SHOULD_BE_HERE" # searching request SEARCH_REQUEST = "fashion" async def main(): async with async_playwright() as p: async with httpx.AsyncClient() as client: response = await client.post( 'http://127.0.0.1:58888/api/profiles/start', json={ 'uuid': PROFILE_UUID, 'headless': False, 'debug_port': True } ) if not response.is_success: print(f'Start response is not successful: {response.json()}') return start_response = response.json() ws_endpoint = start_response.get('ws_endpoint') browser = await p.chromium.connect_over_cdp(ws_endpoint) page = browser.contexts[0].pages[0] # Opening Amazon await page.goto(f'https://www.amazon.com/s?k={SEARCH_REQUEST}') # Extract information results = [] listings = await page.query_selector_all('div.a-section.a-spacing-small') for listing in listings: result = {} # Product name name_element = await listing.query_selector('h2.a-size-mini > a > span') result['product_name'] = await name_element.inner_text() if name_element else 'N/A' # Rating rating_element = await listing.query_selector('span[aria-label*="out of 5 stars"] > span.a-size-base') result['rating'] = (await rating_element.inner_text())[0:3] if rating_element else 'N/A' # Number of reviews reviews_element = await listing.query_selector('span[aria-label*="stars"] + span > a > span') result['number_of_reviews'] = await reviews_element.inner_text() if reviews_element else 'N/A' # Price price_element = await listing.query_selector('span.a-price > span.a-offscreen') result['price'] = await price_element.inner_text() if price_element else 'N/A' if(result['product_name']=='N/A' and result['rating']=='N/A' and result['number_of_reviews']=='N/A' and result['price']=='N/A'): pass else: results.append(result) # Close browser await browser.close() return results # Run the scraper and save results to a CSV file results = asyncio.run(main()) df = pd.DataFrame(results) df.to_csv('amazon_products_listings.csv', index=False)
import httpx from playwright.async_api import async_playwright import asyncio import pandas as pd # Profile's uuid from Octo PROFILE_UUID = "UUID_SHOULD_BE_HERE" # searching request SEARCH_REQUEST = "fashion" async def main(): async with async_playwright() as p: async with httpx.AsyncClient() as client: response = await client.post( 'http://127.0.0.1:58888/api/profiles/start', json={ 'uuid': PROFILE_UUID, 'headless': False, 'debug_port': True } ) if not response.is_success: print(f'Start response is not successful: {response.json()}') return start_response = response.json() ws_endpoint = start_response.get('ws_endpoint') browser = await p.chromium.connect_over_cdp(ws_endpoint) page = browser.contexts[0].pages[0] # Opening Amazon await page.goto(f'https://www.amazon.com/s?k={SEARCH_REQUEST}') # Extract information results = [] listings = await page.query_selector_all('div.a-section.a-spacing-small') for listing in listings: result = {} # Product name name_element = await listing.query_selector('h2.a-size-mini > a > span') result['product_name'] = await name_element.inner_text() if name_element else 'N/A' # Rating rating_element = await listing.query_selector('span[aria-label*="out of 5 stars"] > span.a-size-base') result['rating'] = (await rating_element.inner_text())[0:3] if rating_element else 'N/A' # Number of reviews reviews_element = await listing.query_selector('span[aria-label*="stars"] + span > a > span') result['number_of_reviews'] = await reviews_element.inner_text() if reviews_element else 'N/A' # Price price_element = await listing.query_selector('span.a-price > span.a-offscreen') result['price'] = await price_element.inner_text() if price_element else 'N/A' if(result['product_name']=='N/A' and result['rating']=='N/A' and result['number_of_reviews']=='N/A' and result['price']=='N/A'): pass else: results.append(result) # Close browser await browser.close() return results # Run the scraper and save results to a CSV file results = asyncio.run(main()) df = pd.DataFrame(results) df.to_csv('amazon_products_listings.csv', index=False)
Trong mã này, chúng ta sử dụng khả năng không đồng bộ của Python với thư viện Playwright để trích xuất các danh sách sản phẩm từ một trang Amazon cụ thể. Chúng ta mở một hồ sơ Octo Browser, sau đó kết nối nó qua thư viện Playwright. Tập lệnh mở một URL với một truy vấn tìm kiếm cụ thể, có thể được chỉnh sửa ở đầu tập lệnh trong biến SEARCH_REQUEST.
Bằng cách khởi chạy trình duyệt và điều hướng đến URL Amazon mục tiêu, bạn sẽ trích xuất thông tin sản phẩm: tên, xếp hạng, số lượng đánh giá và giá cả. Sau khi duyệt qua từng danh sách trên trang, bạn có thể lọc ra các danh sách thiếu dữ liệu, mà tập lệnh sẽ đánh dấu là "N/A." Kết quả tìm kiếm sẽ được lưu trong một Pandas DataFrame và sau đó xuất sang tệp CSV có tên là amazon_products_listings.csv.
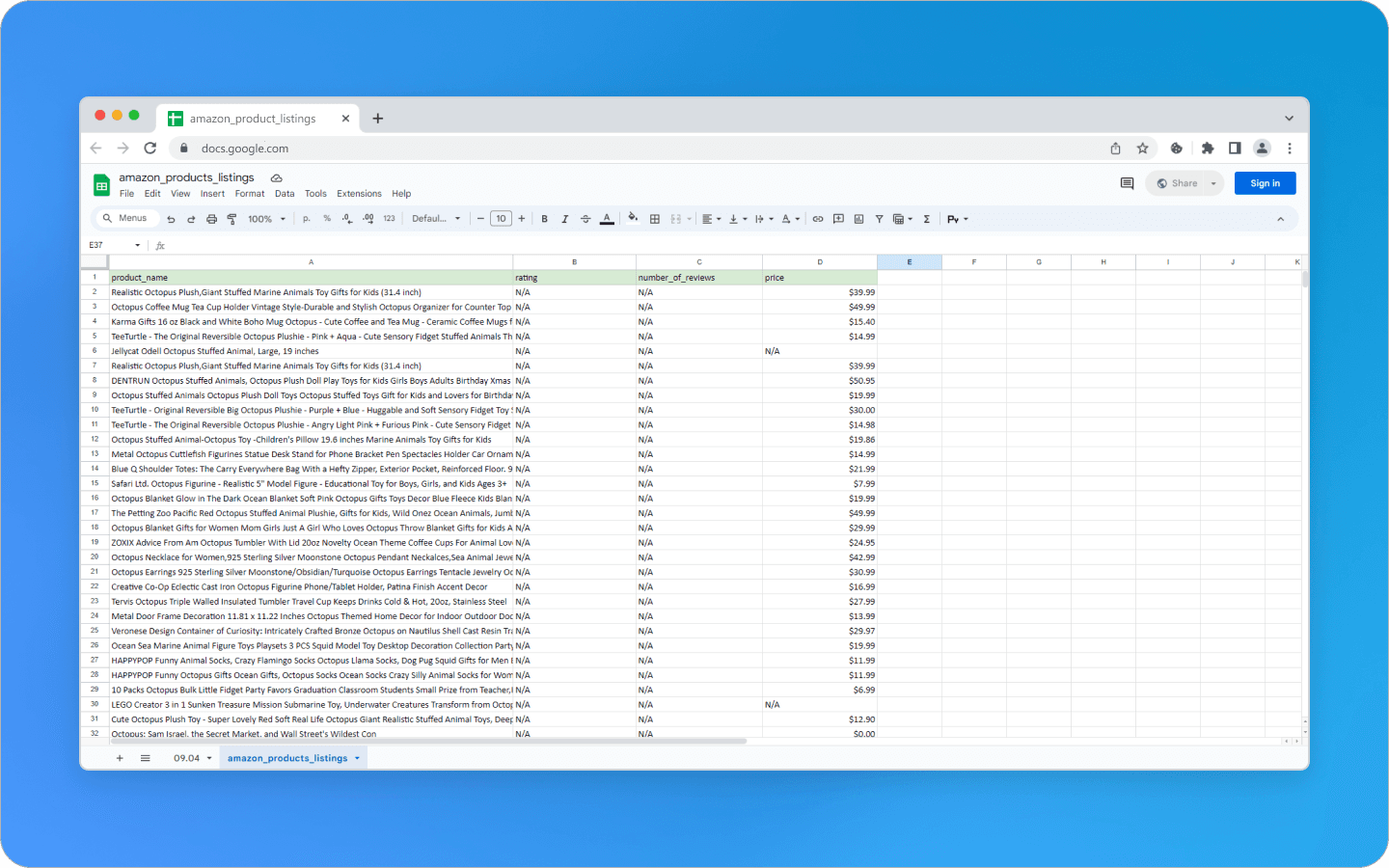
Cần Gì Khác Để Web Scraping Hiệu Quả?
Web scraping trên Amazon mà không có proxy và các công cụ scraping đặc biệt đi kèm rất nhiều thách thức. Giống như nhiều nền tảng phổ biến khác, Amazon có giới hạn tốc độ yêu cầu, nghĩa là nó có thể chặn địa chỉ IP của bạn nếu bạn vượt quá giới hạn yêu cầu đã đặt. Ngoài ra, Amazon sử dụng các thuật toán phát hiện bot để nhận dạng dấu vân tay kỹ thuật số của bạn khi bạn truy cập các trang của trang web. Vì vậy, nên tuân theo các thực tiễn tốt được sử dụng rộng rãi để tránh bị phát hiện và chặn bởi Amazon. Dưới đây là một số mẹo và thủ thuật hữu ích nhất:
Mô Phỏng Hành Vi Tự Nhiên
Amazon có thể chặn hoặc tạm ngừng các hoạt động mà họ cho là tự động hoặc đáng ngờ. Việc quan trọng là trình scraper của bạn phải trông giống con người nhất có thể.
Để phát triển một mô hình crawler thành công, hãy nghĩ về cách một người dùng trung bình sẽ hành động khi khám phá một trang, và thêm các click, cuộn và di chuyển chuột tương ứng. Để tránh bị chặn, hãy thêm độ trễ hoặc khoảng thời gian ngẫu nhiên giữa các yêu cầu bằng các hàm như asyncio.sleep(random.uniform(1, 5)). Điều này sẽ làm cho mô hình của bạn trông ít tự động hơn.
Một Dấu Vân Tay Thực Tế
Sử dụng một trình duyệt đa tài khoản để giả mạo dấu vân tay kỹ thuật số của bạn với dấu vân tay của một thiết bị thực. Các nền tảng như Amazon thu thập các thông số vân tay khác nhau để xác định bot. Để tránh bị phát hiện, đảm bảo rằng các thông số vân tay của bạn và sự kết hợp của chúng luôn hợp lý.
Thêm vào đó, để giảm nguy cơ bị phát hiện, bạn nên xoay vòng các địa chỉ IP. Các proxy chất lượng cao đóng vai trò quan trọng khi làm việc với trình duyệt đa tài khoản. Chọn chỉ các nhà cung cấp uy tín với giá tốt nhất. Proxy nên được chọn theo chiến lược scraping và xem xét địa lý của chúng, vì Amazon cung cấp nội dung khác nhau cho các khu vực khác nhau. Đảm bảo rằng các proxy của bạn có điểm số spam/lạm dụng/gian lận thấp. Bạn cũng nên xem xét tốc độ của proxy. Ví dụ, các proxy dân dụng có thể có độ trễ cao, điều này sẽ ảnh hưởng đến tốc độ scraping.
Dịch Vụ Giải Mã CAPTCHA
Bên cạnh một trình duyệt đa tài khoản, các proxy chất lượng cao và một kịch bản được suy nghĩ kỹ lưỡng mô phỏng hành vi của con người, một giải pháp tự động giải CAPTCHA cũng có thể hữu ích. Để làm điều này, bạn có thể sử dụng các giải pháp OSS, các dịch vụ giải mã thủ công như 2captcha và anti-captcha, hoặc các giải pháp tự động như Capmonster.
Tại Sao Sử Dụng Trình Duyệt Đa Tài Khoản Cho Web Scraping?
Nhiều trang web, nền tảng và dịch vụ sử dụng thông tin về thiết bị của người dùng, trình duyệt và kết nối để nhận dạng họ. Các tập hợp dữ liệu này được gọi là dấu vân tay kỹ thuật số. Dựa trên thông tin dấu vân tay, các hệ thống bảo mật của trang web xác định liệu một người dùng có đáng ngờ không.
Bộ các thông số được phân tích có thể thay đổi tùy theo hệ thống bảo mật của trang web. Để kết nối và hiển thị nội dung đúng cách, một trình duyệt cung cấp hơn 50 tham số khác nhau liên quan đến thiết bị của bạn, mỗi tham số có thể là một phần của dấu vân tay kỹ thuật số.
Thêm vào đó, một trình duyệt có thể được giao nhiệm vụ tạo một hình ảnh 2D hoặc 3D đơn giản, và dựa vào cách thiết bị thực hiện nhiệm vụ này, một mã băm có thể được tạo ra. Mã băm này sẽ phân biệt thiết bị này với những người truy cập khác. Đây là cách mà động tác dấu vân tay thông qua Canvas và WebGL hoạt động.
Các thay đổi nhỏ đối với một số đặc điểm, thông tin về những gì trình duyệt truyền đến các hệ thống bảo mật của trang web, sẽ không ngăn cản việc nhận diện một người dùng đã từng quen thuộc. Bạn có thể thay đổi trình duyệt, múi giờ hoặc độ phân giải màn hình, nhưng ngay cả khi bạn làm tất cả những điều này cùng lúc, khả năng bị nhận diện vẫn cao.
Dấu vân tay, cùng với các công nghệ chống scraping khác như giới hạn tốc độ, định vị địa lý, WAF, thử thách và CAPTCHA, tồn tại để bảo vệ các trang web khỏi tương tác tự động. Một trình duyệt đa tài khoản với hệ thống giả mạo dấu vân tay chất lượng cao sẽ giúp vượt qua các hệ thống bảo mật của trang web. Kết quả là, hiệu quả của web scraping sẽ tăng lên, vì việc thu thập dữ liệu trở nên nhanh hơn và đáng tin cậy hơn.
Trình Duyệt Đa Tài Khoản Hoạt Động Như Thế Nào?
Vai trò của trình duyệt đa tài khoản trong việc vượt qua các hệ thống bảo mật của trang web là giả mạo dấu vân tay kỹ thuật số. Sử dụng một trình duyệt đa tài khoản, bạn có thể tạo nhiều hồ sơ trình duyệt, là các bản sao ảo của trình duyệt, tách biệt với nhau và có bộ đặc điểm và cài đặt riêng: cookies, lịch sử duyệt web, tiện ích mở rộng, proxy, thông số dấu vân tay. Mỗi hồ sơ trình duyệt đa tài khoản xuất hiện với hệ thống bảo mật của trang web như một người dùng riêng biệt.
Làm Thế Nào Để Scrape Bằng Trình Duyệt Đa Tài Khoản
Các trình duyệt đa tài khoản thường cung cấp khả năng tự động hóa thông qua giao thức Chrome Dev Tools. Nó cho phép bạn tự động hóa các hành động scraping cần thiết thông qua các giao diện phần mềm. Để làm việc thuận tiện, bạn có thể sử dụng các thư viện OSS như Puppeteer, Playwright, Selenium, v.v.
Trong Octo Browser, tất cả các tài liệu cần thiết để bắt đầu có sẵn tại đây, và hướng dẫn chi tiết về API có thể được tìm thấy tại đây.
Trình Duyệt Đa Tài Khoản Có Giúp Giảm Chi Phí Scraping Không?
Các trình duyệt đa tài khoản có thể làm tăng hoặc giảm chi phí scraping, tùy thuộc vào nguồn lực và điều kiện làm việc.
Chi phí có thể được giảm bằng cách giảm nguy cơ bị chặn và tự động hóa các tác vụ thủ công. Các trình duyệt đa tài khoản cung cấp trình quản lý hồ sơ và tính năng tự động đồng bộ hóa dữ liệu hồ sơ cho điều này.
Chi phí có thể tăng chủ yếu do việc mua giấy phép cho số lượng hồ sơ cần thiết.
Mọi thứ khác là cố định, trong thời gian dài việc sử dụng trình duyệt đa tài khoản tạo điều kiện tiết kiệm ngân sách và giảm chi phí scraping.
Có Đáng Để Tự Động Hóa Quá Trình Web Scraping Không?
Web scraping là một công cụ mạnh mẽ cho việc thu thập và phân tích dữ liệu tự động. Các công ty sử dụng nó để thu thập thông tin cần thiết và đưa ra quyết định có kiến thức trong lĩnh vực thương mại điện tử.
Sử dụng Python để tìm kiếm sản phẩm, đánh giá, mô tả và giá cả trên Amazon một cách hiệu quả. Viết mã cần thiết có thể mất một chút thời gian và công sức, nhưng kết quả sẽ vượt qua mọi kỳ vọng. Để tránh sự chú ý của các hệ thống bảo mật, hãy mô phỏng hành vi người dùng tự nhiên, sử dụng địa chỉ IP của bên thứ ba, và thay đổi dấu vân tay kỹ thuật số thường xuyên. Các công cụ chuyên dụng như trình duyệt đa tài khoản và máy chủ proxy sẽ cho phép bạn xoay vòng dấu vân tay trình duyệt và địa chỉ IP để vượt qua các hạn chế và tăng tốc độ scraping.
Câu Hỏi Thường Gặp
Những loại dữ liệu nào có thể được trích xuất bằng web scraping?
Web scraping có thể trích xuất văn bản, hình ảnh, bảng, siêu dữ liệu, và hơn thế nữa.
Có thể phát hiện scraping không?
Có, việc phân tích dữ liệu có thể bị các hệ thống chống bot phát hiện, có thể kiểm tra địa chỉ IP của bạn, liệu các thông số dấu vân tay kỹ thuật số của bạn có khớp và các mẫu hành vi của bạn. Nếu kiểm tra thất bại, truy cập vào các trang của trang web từ địa chỉ IP và thiết bị của bạn sẽ bị chặn.
Làm thế nào để tránh bị chặn trong quá trình web scraping?
Sử dụng máy chủ proxy, mô phỏng các hành động của người dùng thực, và thêm độ trễ giữa các yêu cầu.
Những khía cạnh pháp lý nào của web scraping cần được xem xét?
Các khía cạnh pháp lý của web scraping được điều chỉnh bởi luật bảo vệ dữ liệu và quyền sở hữu trí tuệ. Việc trích xuất dữ liệu công khai trên trang web không được coi là bất hợp pháp nếu hành động của bạn không vi phạm Quy tắc của chúng. Hãy tuân thủ các quy tắc của nền tảng và luôn xem xét các khía cạnh pháp lý của web scraping.
Amazon có cho phép scraping không?
Việc phân tích dữ liệu công khai trên Amazon không được coi là bất hợp pháp miễn là hành động của bạn không vi phạm Quy tắc Sử dụng của nó.
Những sai lầm chính có thể xảy ra trong quá trình web scraping, và làm thế nào để tránh chúng?
Các lỗi điển hình bao gồm các vấn đề với phân tích HTML, theo dõi sự thay đổi trong cấu trúc trang web, và vượt quá giới hạn tốc độ yêu cầu. Để tránh chúng, kiểm tra và cập nhật mã của bạn thường xuyên.
Làm thế nào để giảm thiểu sự xuất hiện của CAPTCHA khi scraping Amazon?
Sử dụng máy chủ proxy đáng tin cậy và xoay vòng địa chỉ IP của bạn. Giảm tốc độ scraping bằng cách thêm các khoảng thời gian ngẫu nhiên giữa các yêu cầu và hành động. Đảm bảo rằng các thông số dấu vân tay kỹ thuật số của bạn khớp với các thiết bị thực và không gây nghi ngờ cho các hệ thống chống bot.
Giữ kín danh tính, tận dụng tính năng nhiều tài khoản và đạt được mục tiêu của bạn với trình duyệt chống phát hiện chất lượng cao nhất trên thị trường.
Bạn có muốn thử Octo Browser với giá giảm không?
Sử dụng mã khuyến mãi OCTOSCRAPER để được giảm giá 30% cho bất kỳ gói đăng ký nào. Ưu đãi này chỉ dành cho người dùng mới.
Web Scraping là gì?
Web scraping là quá trình thu thập dữ liệu tự động từ các trang web. Các chương trình hoặc script đặc biệt, gọi là scrapers, sẽ trích xuất thông tin từ các trang web và chuyển đổi nó thành định dạng dữ liệu có cấu trúc, thuận tiện cho việc phân tích và sử dụng tiếp theo. Các định dạng phổ biến nhất để lưu trữ và xử lý dữ liệu là CSV, JSON, SQL, hoặc Excel.
Ngày nay, web scraping được sử dụng rộng rãi trong Khoa học Dữ liệu, marketing và thương mại điện tử. Các công cụ web scraper thu thập lượng lớn thông tin vì mục đích cá nhân và công việc. Hơn nữa, các tập đoàn công nghệ hiện đại dựa vào phương pháp web scraping để theo dõi và phân tích xu hướng.
Công cụ và Công nghệ cho Web Scraping
Python và Thư viện
Python là một trong những ngôn ngữ lập trình phổ biến nhất cho web scraping. Nó nổi tiếng với cú pháp đơn giản và rõ ràng, làm cho nó trở thành lựa chọn lý tưởng cho cả người mới bắt đầu và người lập trình có kinh nghiệm. Một ưu điểm khác là phạm vi rộng các thư viện có sẵn cho web scraping, chẳng hạn như Beautiful Soup, Scrapy, Requests và Selenium. Những thư viện này cho phép bạn dễ dàng gửi yêu cầu HTTP, xử lý tài liệu HTML, và tương tác với các trang web.
API
Amazon cung cấp API để truy cập dữ liệu của nó, chẳng hạn như Amazon Product Advertising API. Điều này cho phép bạn yêu cầu thông tin cụ thể trong định dạng có cấu trúc mà không phải phân tích toàn bộ trang HTML.
Dịch vụ Đám mây
Các nền tảng đám mây như AWS Lambda và Google Cloud Functions có thể được sử dụng để tự động hóa và mở rộng các quy trình web scraping. Chúng cung cấp hiệu suất cao và khả năng xử lý các khối lượng dữ liệu lớn.
Các Công cụ Chuyên Dụng
Có thêm các công cụ cho web scraping, chẳng hạn như trình duyệt đa tài khoản và proxy. Vai trò của chúng là giả mạo dấu vân tay kỹ thuật số để vượt qua các giới hạn bảo mật của trang web. Những công cụ này tăng tốc thu thập dữ liệu.
Ứng dụng của Amazon Web Scraping
Phân Tích Thị Trường và Cạnh Tranh
Web scraping cho phép bạn thu thập dữ liệu về sản phẩm và giá cả của đối thủ, phân tích phạm vi sản phẩm và xác định xu hướng. Điều này giúp các công ty điều chỉnh chiến lược của mình và duy trì khả năng cạnh tranh.
Giám Sát Giá
Thu thập dữ liệu về giá cho các sản phẩm tương tự giúp các công ty đặt giá cạnh tranh và phản ứng kịp thời với sự thay đổi của thị trường. Điều này đặc biệt quan trọng trong bối cảnh giá động và khuyến mãi.
Thu thập Đánh Giá và Xếp Hạng
Đánh giá và xếp hạng là một nguồn thông tin quan trọng về cách người tiêu dùng nhận thức sản phẩm. Phân tích dữ liệu này giúp xác định điểm mạnh và điểm yếu của sản phẩm, cũng như đưa ra ý tưởng cho việc cải tiến chúng.
Nghiên Cứu Sản Phẩm
Sử dụng web scraping, bạn có thể phân tích phạm vi sản phẩm trên Amazon, xác định các danh mục phổ biến và từ đó đưa ra quyết định về việc mở rộng hoặc thay đổi danh mục sản phẩm.
Theo Dõi Sản Phẩm Mới
Web scraping có thể giúp bạn nhanh chóng biết về sự xuất hiện của sản phẩm mới trên nền tảng, điều này có thể hữu ích cho các nhà sản xuất, nhà phân phối và nhà phân tích thị trường.
Điều Hướng Các Thành Phần Giao Diện Của Amazon
Trước khi bạn bắt đầu scraping, điều quan trọng là phải hiểu cách trang web được cấu trúc. Hầu hết các trang web được viết bằng HTML và chứa các yếu tố như thẻ, thuộc tính và lớp. Biết về HTML sẽ giúp bạn xác định và trích xuất chính xác dữ liệu cần thiết.
Trên trang chủ của Amazon, người mua sử dụng thanh tìm kiếm để nhập các từ khóa liên quan đến sản phẩm mong muốn. Kết quả là họ nhận được một danh sách với tên sản phẩm, giá cả, xếp hạng và các thuộc tính cần thiết khác. Ngoài ra, sản phẩm có thể được lọc theo các tham số khác nhau như phạm vi giá, danh mục sản phẩm và đánh giá khách hàng. Điều hướng các thành phần này giúp người dùng dễ dàng tìm kiếm sản phẩm họ quan tâm, so sánh các lựa chọn thay thế, xem thông tin bổ sung và thận tiện mua sản phẩm trên Amazon.
Trang chủ Amazon với một truy vấn tìm kiếm cho Octopus
Để có danh sách kết quả phong phú hơn, bạn có thể sử dụng các nút phân trang nằm dưới cùng trang. Mỗi trang thường chứa một lượng lớn danh sách, cho phép bạn duyệt thêm nhiều sản phẩm. Các bộ lọc ở đầu trang cho phép bạn tinh chỉnh tìm kiếm theo yêu cầu của mình.
Để hiểu cấu trúc HTML của Amazon, hãy làm theo các bước sau:
Truy cập vào trang web.
Tìm kiếm sản phẩm mong muốn bằng thanh tìm kiếm hoặc chọn danh mục từ danh sách sản phẩm.
Mở công cụ phát triển bằng cách nhấp chuột phải vào sản phẩm và chọn Inspect từ menu thả xuống.
Khám phá bố cục HTML để xác định các thẻ và thuộc tính của dữ liệu bạn dự định trích xuất.
Các Bước Chính Để Bắt Đầu Scraping
Web scraping bao gồm hai bước chính: tìm kiếm thông tin cần thiết và cấu trúc lại nó. Sau khi nghiên cứu cấu trúc của trang web, chúng ta hãy thiết lập các thành phần cần thiết để tự động hóa quá trình scraping.
Đối với nhiệm vụ này, chúng ta sẽ sử dụng Python và các thư viện của nó:
HTTPX là một thư viện Python HTTP đồng bộ hoàn toàn và cũng hỗ trợ thực hiện các yêu cầu không đồng bộ. HTTPX cung cấp giao diện chuẩn HTTP giống với thư viện yêu cầu phổ biến nhưng bổ sung hỗ trợ cho không đồng bộ, các giao thức HTTP/1.1, HTTP/2, HTTP/3, và các kết nối SOCKS.
BeautifulSoup: Thư viện này được thiết kế để phân tích HTML và tài liệu XML một cách dễ dàng và nhanh chóng. Nó cung cấp giao diện đơn giản để điều hướng, tìm kiếm và sửa đổi cây tài liệu, làm cho quá trình web scraping trở nên trực quan hơn. Nó cho phép bạn trích xuất thông tin từ một trang bằng cách tìm kiếm các thẻ, thuộc tính hoặc văn bản cụ thể.
Selenium: Để tương tác với các trang web động.
Pandas: Đây là một thư viện mạnh mẽ và đáng tin cậy để xử lý và làm sạch dữ liệu. Chẳng hạn, sau khi trích xuất dữ liệu từ các trang web, bạn có thể sử dụng Pandas để xử lý các giá trị thiếu, chuyển đổi dữ liệu sang định dạng yêu cầu và loại bỏ các bản sao.
Playwright: Cho phép tương tác hiệu quả với các trang web sử dụng JavaScript để cập nhật nội dung động. Điều này đặc biệt hữu ích cho scraping các trang web như Amazon, nơi mà nhiều yếu tố tải không đồng bộ.
Scrapy: Để xử lý các nhiệm vụ web scraping phức tạp hơn.
Một khi bạn đã chuẩn bị Python, mở terminal hoặc shell và tạo một thư mục dự án mới bằng cách sử dụng các lệnh sau:
mkdir scraping-amazon-python cd scraping-amazon-python
Để cài đặt các thư viện, mở terminal hoặc shell và chạy các lệnh sau:
pip install httpx pip3 install pandas pip3 install playwright playwright install
Lưu ý: Lệnh cuối cùng (playwright install) rất quan trọng vì nó đảm bảo cài đặt đúng các tệp trình duyệt cần thiết.
Hãy đảm bảo rằng quá trình cài đặt hoàn tất mà không gặp bất kỳ vấn đề nào trước khi tiến hành bước tiếp theo. Nếu bạn gặp khó khăn trong việc thiết lập môi trường, bạn có thể tham khảo các dịch vụ AI như ChatGPT, Mistral AI, và các dịch vụ khác. Các dịch vụ này có thể giúp xử lý lỗi và cung cấp hướng dẫn từng bước để giải quyết chúng.
Sử Dụng Python và Thư Viện Cho Web Scraping
Trong thư mục dự án của bạn, tạo một tập lệnh Python mới có tên là amazon_scraper.py và thêm mã sau:
import httpx from playwright.async_api import async_playwright import asyncio import pandas as pd # Profile's uuid from Octo PROFILE_UUID = "UUID_SHOULD_BE_HERE" # searching request SEARCH_REQUEST = "fashion" async def main(): async with async_playwright() as p: async with httpx.AsyncClient() as client: response = await client.post( 'http://127.0.0.1:58888/api/profiles/start', json={ 'uuid': PROFILE_UUID, 'headless': False, 'debug_port': True } ) if not response.is_success: print(f'Start response is not successful: {response.json()}') return start_response = response.json() ws_endpoint = start_response.get('ws_endpoint') browser = await p.chromium.connect_over_cdp(ws_endpoint) page = browser.contexts[0].pages[0] # Opening Amazon await page.goto(f'https://www.amazon.com/s?k={SEARCH_REQUEST}') # Extract information results = [] listings = await page.query_selector_all('div.a-section.a-spacing-small') for listing in listings: result = {} # Product name name_element = await listing.query_selector('h2.a-size-mini > a > span') result['product_name'] = await name_element.inner_text() if name_element else 'N/A' # Rating rating_element = await listing.query_selector('span[aria-label*="out of 5 stars"] > span.a-size-base') result['rating'] = (await rating_element.inner_text())[0:3] if rating_element else 'N/A' # Number of reviews reviews_element = await listing.query_selector('span[aria-label*="stars"] + span > a > span') result['number_of_reviews'] = await reviews_element.inner_text() if reviews_element else 'N/A' # Price price_element = await listing.query_selector('span.a-price > span.a-offscreen') result['price'] = await price_element.inner_text() if price_element else 'N/A' if(result['product_name']=='N/A' and result['rating']=='N/A' and result['number_of_reviews']=='N/A' and result['price']=='N/A'): pass else: results.append(result) # Close browser await browser.close() return results # Run the scraper and save results to a CSV file results = asyncio.run(main()) df = pd.DataFrame(results) df.to_csv('amazon_products_listings.csv', index=False)
Trong mã này, chúng ta sử dụng khả năng không đồng bộ của Python với thư viện Playwright để trích xuất các danh sách sản phẩm từ một trang Amazon cụ thể. Chúng ta mở một hồ sơ Octo Browser, sau đó kết nối nó qua thư viện Playwright. Tập lệnh mở một URL với một truy vấn tìm kiếm cụ thể, có thể được chỉnh sửa ở đầu tập lệnh trong biến SEARCH_REQUEST.
Bằng cách khởi chạy trình duyệt và điều hướng đến URL Amazon mục tiêu, bạn sẽ trích xuất thông tin sản phẩm: tên, xếp hạng, số lượng đánh giá và giá cả. Sau khi duyệt qua từng danh sách trên trang, bạn có thể lọc ra các danh sách thiếu dữ liệu, mà tập lệnh sẽ đánh dấu là "N/A." Kết quả tìm kiếm sẽ được lưu trong một Pandas DataFrame và sau đó xuất sang tệp CSV có tên là amazon_products_listings.csv.
Cần Gì Khác Để Web Scraping Hiệu Quả?
Web scraping trên Amazon mà không có proxy và các công cụ scraping đặc biệt đi kèm rất nhiều thách thức. Giống như nhiều nền tảng phổ biến khác, Amazon có giới hạn tốc độ yêu cầu, nghĩa là nó có thể chặn địa chỉ IP của bạn nếu bạn vượt quá giới hạn yêu cầu đã đặt. Ngoài ra, Amazon sử dụng các thuật toán phát hiện bot để nhận dạng dấu vân tay kỹ thuật số của bạn khi bạn truy cập các trang của trang web. Vì vậy, nên tuân theo các thực tiễn tốt được sử dụng rộng rãi để tránh bị phát hiện và chặn bởi Amazon. Dưới đây là một số mẹo và thủ thuật hữu ích nhất:
Mô Phỏng Hành Vi Tự Nhiên
Amazon có thể chặn hoặc tạm ngừng các hoạt động mà họ cho là tự động hoặc đáng ngờ. Việc quan trọng là trình scraper của bạn phải trông giống con người nhất có thể.
Để phát triển một mô hình crawler thành công, hãy nghĩ về cách một người dùng trung bình sẽ hành động khi khám phá một trang, và thêm các click, cuộn và di chuyển chuột tương ứng. Để tránh bị chặn, hãy thêm độ trễ hoặc khoảng thời gian ngẫu nhiên giữa các yêu cầu bằng các hàm như asyncio.sleep(random.uniform(1, 5)). Điều này sẽ làm cho mô hình của bạn trông ít tự động hơn.
Một Dấu Vân Tay Thực Tế
Sử dụng một trình duyệt đa tài khoản để giả mạo dấu vân tay kỹ thuật số của bạn với dấu vân tay của một thiết bị thực. Các nền tảng như Amazon thu thập các thông số vân tay khác nhau để xác định bot. Để tránh bị phát hiện, đảm bảo rằng các thông số vân tay của bạn và sự kết hợp của chúng luôn hợp lý.
Thêm vào đó, để giảm nguy cơ bị phát hiện, bạn nên xoay vòng các địa chỉ IP. Các proxy chất lượng cao đóng vai trò quan trọng khi làm việc với trình duyệt đa tài khoản. Chọn chỉ các nhà cung cấp uy tín với giá tốt nhất. Proxy nên được chọn theo chiến lược scraping và xem xét địa lý của chúng, vì Amazon cung cấp nội dung khác nhau cho các khu vực khác nhau. Đảm bảo rằng các proxy của bạn có điểm số spam/lạm dụng/gian lận thấp. Bạn cũng nên xem xét tốc độ của proxy. Ví dụ, các proxy dân dụng có thể có độ trễ cao, điều này sẽ ảnh hưởng đến tốc độ scraping.
Dịch Vụ Giải Mã CAPTCHA
Bên cạnh một trình duyệt đa tài khoản, các proxy chất lượng cao và một kịch bản được suy nghĩ kỹ lưỡng mô phỏng hành vi của con người, một giải pháp tự động giải CAPTCHA cũng có thể hữu ích. Để làm điều này, bạn có thể sử dụng các giải pháp OSS, các dịch vụ giải mã thủ công như 2captcha và anti-captcha, hoặc các giải pháp tự động như Capmonster.
Tại Sao Sử Dụng Trình Duyệt Đa Tài Khoản Cho Web Scraping?
Nhiều trang web, nền tảng và dịch vụ sử dụng thông tin về thiết bị của người dùng, trình duyệt và kết nối để nhận dạng họ. Các tập hợp dữ liệu này được gọi là dấu vân tay kỹ thuật số. Dựa trên thông tin dấu vân tay, các hệ thống bảo mật của trang web xác định liệu một người dùng có đáng ngờ không.
Bộ các thông số được phân tích có thể thay đổi tùy theo hệ thống bảo mật của trang web. Để kết nối và hiển thị nội dung đúng cách, một trình duyệt cung cấp hơn 50 tham số khác nhau liên quan đến thiết bị của bạn, mỗi tham số có thể là một phần của dấu vân tay kỹ thuật số.
Thêm vào đó, một trình duyệt có thể được giao nhiệm vụ tạo một hình ảnh 2D hoặc 3D đơn giản, và dựa vào cách thiết bị thực hiện nhiệm vụ này, một mã băm có thể được tạo ra. Mã băm này sẽ phân biệt thiết bị này với những người truy cập khác. Đây là cách mà động tác dấu vân tay thông qua Canvas và WebGL hoạt động.
Các thay đổi nhỏ đối với một số đặc điểm, thông tin về những gì trình duyệt truyền đến các hệ thống bảo mật của trang web, sẽ không ngăn cản việc nhận diện một người dùng đã từng quen thuộc. Bạn có thể thay đổi trình duyệt, múi giờ hoặc độ phân giải màn hình, nhưng ngay cả khi bạn làm tất cả những điều này cùng lúc, khả năng bị nhận diện vẫn cao.
Dấu vân tay, cùng với các công nghệ chống scraping khác như giới hạn tốc độ, định vị địa lý, WAF, thử thách và CAPTCHA, tồn tại để bảo vệ các trang web khỏi tương tác tự động. Một trình duyệt đa tài khoản với hệ thống giả mạo dấu vân tay chất lượng cao sẽ giúp vượt qua các hệ thống bảo mật của trang web. Kết quả là, hiệu quả của web scraping sẽ tăng lên, vì việc thu thập dữ liệu trở nên nhanh hơn và đáng tin cậy hơn.
Trình Duyệt Đa Tài Khoản Hoạt Động Như Thế Nào?
Vai trò của trình duyệt đa tài khoản trong việc vượt qua các hệ thống bảo mật của trang web là giả mạo dấu vân tay kỹ thuật số. Sử dụng một trình duyệt đa tài khoản, bạn có thể tạo nhiều hồ sơ trình duyệt, là các bản sao ảo của trình duyệt, tách biệt với nhau và có bộ đặc điểm và cài đặt riêng: cookies, lịch sử duyệt web, tiện ích mở rộng, proxy, thông số dấu vân tay. Mỗi hồ sơ trình duyệt đa tài khoản xuất hiện với hệ thống bảo mật của trang web như một người dùng riêng biệt.
Làm Thế Nào Để Scrape Bằng Trình Duyệt Đa Tài Khoản
Các trình duyệt đa tài khoản thường cung cấp khả năng tự động hóa thông qua giao thức Chrome Dev Tools. Nó cho phép bạn tự động hóa các hành động scraping cần thiết thông qua các giao diện phần mềm. Để làm việc thuận tiện, bạn có thể sử dụng các thư viện OSS như Puppeteer, Playwright, Selenium, v.v.
Trong Octo Browser, tất cả các tài liệu cần thiết để bắt đầu có sẵn tại đây, và hướng dẫn chi tiết về API có thể được tìm thấy tại đây.
Trình Duyệt Đa Tài Khoản Có Giúp Giảm Chi Phí Scraping Không?
Các trình duyệt đa tài khoản có thể làm tăng hoặc giảm chi phí scraping, tùy thuộc vào nguồn lực và điều kiện làm việc.
Chi phí có thể được giảm bằng cách giảm nguy cơ bị chặn và tự động hóa các tác vụ thủ công. Các trình duyệt đa tài khoản cung cấp trình quản lý hồ sơ và tính năng tự động đồng bộ hóa dữ liệu hồ sơ cho điều này.
Chi phí có thể tăng chủ yếu do việc mua giấy phép cho số lượng hồ sơ cần thiết.
Mọi thứ khác là cố định, trong thời gian dài việc sử dụng trình duyệt đa tài khoản tạo điều kiện tiết kiệm ngân sách và giảm chi phí scraping.
Có Đáng Để Tự Động Hóa Quá Trình Web Scraping Không?
Web scraping là một công cụ mạnh mẽ cho việc thu thập và phân tích dữ liệu tự động. Các công ty sử dụng nó để thu thập thông tin cần thiết và đưa ra quyết định có kiến thức trong lĩnh vực thương mại điện tử.
Sử dụng Python để tìm kiếm sản phẩm, đánh giá, mô tả và giá cả trên Amazon một cách hiệu quả. Viết mã cần thiết có thể mất một chút thời gian và công sức, nhưng kết quả sẽ vượt qua mọi kỳ vọng. Để tránh sự chú ý của các hệ thống bảo mật, hãy mô phỏng hành vi người dùng tự nhiên, sử dụng địa chỉ IP của bên thứ ba, và thay đổi dấu vân tay kỹ thuật số thường xuyên. Các công cụ chuyên dụng như trình duyệt đa tài khoản và máy chủ proxy sẽ cho phép bạn xoay vòng dấu vân tay trình duyệt và địa chỉ IP để vượt qua các hạn chế và tăng tốc độ scraping.
Câu Hỏi Thường Gặp
Những loại dữ liệu nào có thể được trích xuất bằng web scraping?
Web scraping có thể trích xuất văn bản, hình ảnh, bảng, siêu dữ liệu, và hơn thế nữa.
Có thể phát hiện scraping không?
Có, việc phân tích dữ liệu có thể bị các hệ thống chống bot phát hiện, có thể kiểm tra địa chỉ IP của bạn, liệu các thông số dấu vân tay kỹ thuật số của bạn có khớp và các mẫu hành vi của bạn. Nếu kiểm tra thất bại, truy cập vào các trang của trang web từ địa chỉ IP và thiết bị của bạn sẽ bị chặn.
Làm thế nào để tránh bị chặn trong quá trình web scraping?
Sử dụng máy chủ proxy, mô phỏng các hành động của người dùng thực, và thêm độ trễ giữa các yêu cầu.
Những khía cạnh pháp lý nào của web scraping cần được xem xét?
Các khía cạnh pháp lý của web scraping được điều chỉnh bởi luật bảo vệ dữ liệu và quyền sở hữu trí tuệ. Việc trích xuất dữ liệu công khai trên trang web không được coi là bất hợp pháp nếu hành động của bạn không vi phạm Quy tắc của chúng. Hãy tuân thủ các quy tắc của nền tảng và luôn xem xét các khía cạnh pháp lý của web scraping.
Amazon có cho phép scraping không?
Việc phân tích dữ liệu công khai trên Amazon không được coi là bất hợp pháp miễn là hành động của bạn không vi phạm Quy tắc Sử dụng của nó.
Những sai lầm chính có thể xảy ra trong quá trình web scraping, và làm thế nào để tránh chúng?
Các lỗi điển hình bao gồm các vấn đề với phân tích HTML, theo dõi sự thay đổi trong cấu trúc trang web, và vượt quá giới hạn tốc độ yêu cầu. Để tránh chúng, kiểm tra và cập nhật mã của bạn thường xuyên.
Làm thế nào để giảm thiểu sự xuất hiện của CAPTCHA khi scraping Amazon?
Sử dụng máy chủ proxy đáng tin cậy và xoay vòng địa chỉ IP của bạn. Giảm tốc độ scraping bằng cách thêm các khoảng thời gian ngẫu nhiên giữa các yêu cầu và hành động. Đảm bảo rằng các thông số dấu vân tay kỹ thuật số của bạn khớp với các thiết bị thực và không gây nghi ngờ cho các hệ thống chống bot.
Cập nhật với các tin tức Octo Browser mới nhất
Khi nhấp vào nút này, bạn sẽ đồng ý với Chính sách Quyền riêng tư của chúng tôi.
Cập nhật với các tin tức Octo Browser mới nhất
Khi nhấp vào nút này, bạn sẽ đồng ý với Chính sách Quyền riêng tư của chúng tôi.
Cập nhật với các tin tức Octo Browser mới nhất
Khi nhấp vào nút này, bạn sẽ đồng ý với Chính sách Quyền riêng tư của chúng tôi.

Tham gia Octo Browser ngay
Hoặc liên hệ với Dịch vụ khách hàng bất kì lúc nào nếu bạn có bất cứ thắc mắc nào.
Tham gia Octo Browser ngay
Hoặc liên hệ với Dịch vụ khách hàng bất kì lúc nào nếu bạn có bất cứ thắc mắc nào.
Tham gia Octo Browser ngay
Hoặc liên hệ với Dịch vụ khách hàng bất kì lúc nào nếu bạn có bất cứ thắc mắc nào.