Web Scraping là gì và nó hoạt động như thế nào?


Palina Zabela
Content Manager, Octo Browser
Thu thập dữ liệu web là một cách nhanh chóng để thu thập thông tin trực tuyến. Bots quét các trang web và trích xuất giá sản phẩm, danh mục của các cửa hàng trực tuyến, liên hệ của khách hàng tiềm năng và còn nhiều hơn thế nữa. Thông tin này sau đó được bán hoặc sử dụng cho phát triển kinh doanh. Ngoài ra, mạng nơ-ron cũng được huấn luyện trên dữ liệu được thu thập bởi các trình thu thập dữ liệu web. Làm thế nào để thu thập thông tin từ các trang web một cách tự động? Công cụ nào được sử dụng trong quá trình này? Làm thế nào để truy cập thông tin được bảo vệ? Đội ngũ Octo Browser đã chuẩn bị một hướng dẫn chi tiết với các câu trả lời.
Nội dung
Giữ kín danh tính, tận dụng tính năng nhiều tài khoản và đạt được mục tiêu của bạn với trình duyệt chống phát hiện chất lượng cao nhất trên thị trường.
Bạn có muốn thử Octo Browser với giá giảm không?
Sử dụng mã khuyến mãi OCTOSCRAPER để được giảm giá 30% cho bất kỳ gói đăng ký nào. Ưu đãi này chỉ dành cho người dùng mới.
Web Scraping là gì?
Web scraping là quá trình thu thập lượng lớn thông tin từ web bằng cách sử dụng bot. Quá trình này bao gồm hai giai đoạn: tìm kiếm thông tin cần thiết và cấu trúc nó. Khi bạn sao chép dữ liệu văn bản từ một trang web và sau đó dán nó vào một tài liệu, về cơ bản bạn cũng đang thực hiện web scraping. Sự khác biệt là các script làm việc nhanh hơn, tránh được lỗi, và trích xuất thông tin từ mã HTML thay vì các thành phần trực quan của trang. Web scrapers thu thập cơ sở dữ liệu được sử dụng cho so sánh giá, phân tích thị trường, tạo khách hàng tiềm năng, và theo dõi tin tức.
Các Web Scrapers hoạt động như thế nào?
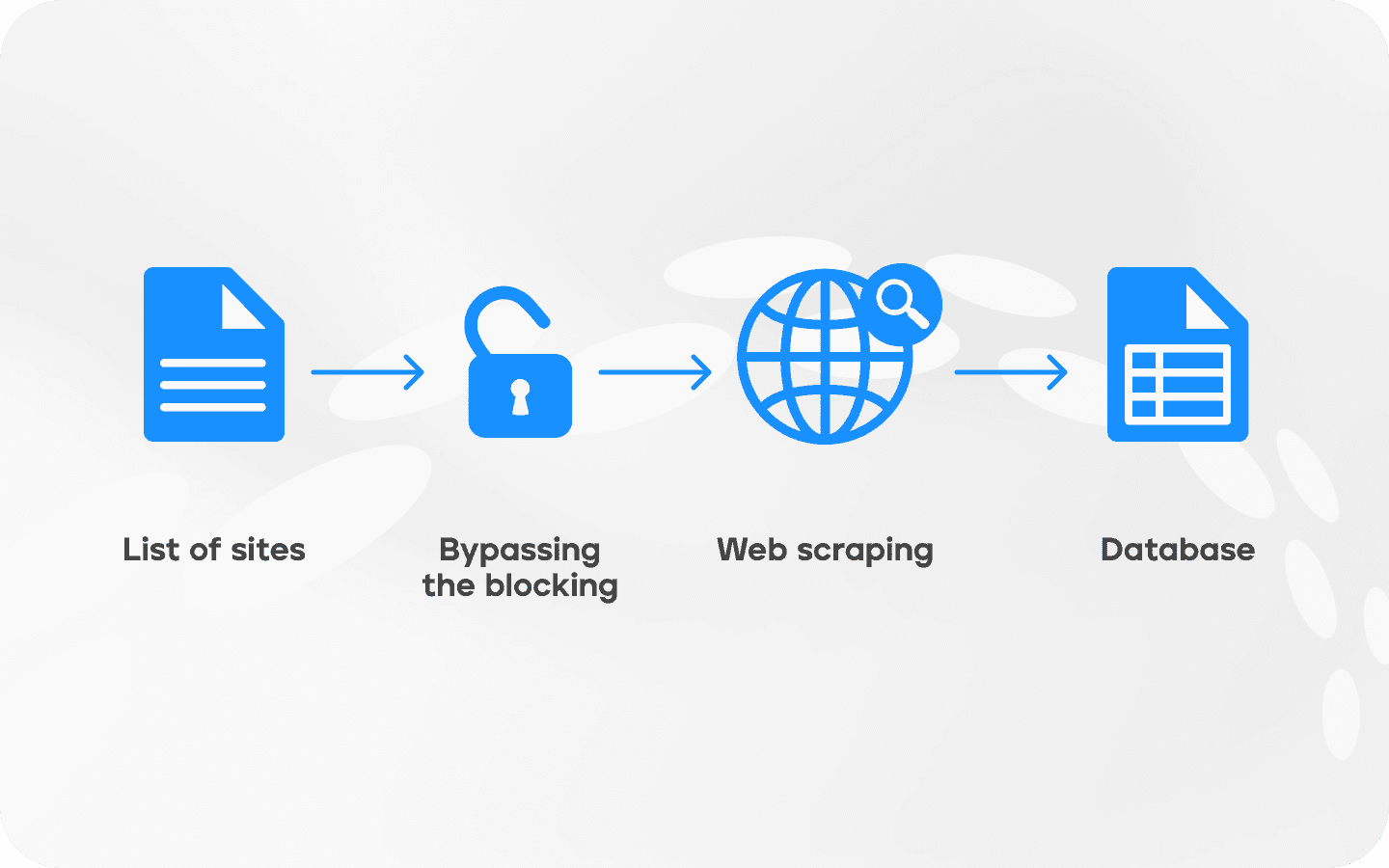
Các script, bot, API, và dịch vụ GUI cho web scraping thường theo một mô hình chung. Đầu tiên, bạn biên soạn danh sách các trang web mà robot sẽ truy cập và quyết định thông tin nào nó sẽ trích xuất. Ví dụ, để so sánh giá, bạn cần tên sản phẩm, liên kết cửa hàng và giá cả. Đối với phân tích cạnh tranh, bạn cũng cần thông số kỹ thuật sản phẩm, phương pháp vận chuyển và đánh giá. Càng ít chi tiết bạn yêu cầu, script sẽ thu thập chúng càng nhanh.
Một khi nhiệm vụ được hình thành, bot truy cập vào các trang, tải mã HTML, và trích xuất thông tin. Các script phức tạp hơn cũng có thể phân tích CSS và JavaScript.
Đôi khi cần phải đăng nhập vào tài khoản trên nền tảng để thu thập dữ liệu, ví dụ khi bạn cần thu thập dữ liệu liên lạc của chuyên gia trên LinkedIn. Trong những trường hợp như vậy, thuật toán để vượt qua các biện pháp bảo vệ của trang web được thêm vào thuật toán thu thập thông tin.
Bước cuối cùng là cấu trúc thông tin thu thập được dưới dạng bảng hoặc bảng tính (CSV hoặc Excel), cơ sở dữ liệu, hoặc định dạng JSON, thích hợp cho API.
Công cụ Web Scraping

Để thu thập dữ liệu, bạn cần một web scraper sẽ truy cập vào trang đích và truy xuất thông tin cần thiết từ nó. Có một số tùy chọn để bạn lựa chọn:
Phần mềm mã nguồn mở được tạo ra đặc biệt cho web scraping: Scrapy, Crawlee, Mechanize;
Các HTTP client: Requests, HTTPX, Axios để trích xuất dữ liệu từ HTML, XML, RSS, ví dụ như Beautiful Soup, lxml, Cheerio;
Giải pháp tự động hóa trình duyệt: Puppeteer, Playwright, Selenium và các dịch vụ khác có thể kết nối với trình duyệt, truy xuất HTML/XML và phân tích tài liệu;
Các dịch vụ như Zyte, Apify, Surfsky, Browserless, Scrapingbee, Import.io, cung cấp API hoặc CDP và hoạt động như một trung gian giữa script khách hàng và dịch vụ đích.
Chúng tôi đã thảo luận về những dịch vụ này chi tiết hơn ở đây.
Để thực hiện web scraping thành công, ngoài một parser, bạn sẽ cần:
Một công cụ để vượt qua CAPTCHAs;
Các proxy;
Một trình duyệt cho việc quản lý tài khoản nhiều.
Các chủ sở hữu trang web áp dụng các biện pháp bảo vệ khỏi web scraping bằng cách theo dõi địa chỉ IP và các định danh thiết bị duy nhất gọi là vân tay số. Nếu hệ thống bảo vệ phát hiện hoạt động đáng ngờ, chẳng hạn như yêu cầu quá thường xuyên từ một thiết bị, chúng sẽ chặn truy cập vào trang web.
Một số trang web thêm CAPTCHA để ngăn chặn web scrapers thu thập dữ liệu. Các dịch vụ đặc biệt, như 2Captcha, CapSolver, Death By Captcha, và BypassCaptcha có thể giải CAPTCHA. Bạn cần tích hợp dịch vụ vào ứng dụng, gọi nó thông qua API, vượt qua CAPTCHA, và nhận giải pháp trong vài giây. Công cụ giải CAPTCHA hỗ trợ các ngôn ngữ lập trình phổ biến, như PHP, JavaScript, C#, Java, và Python.
Vấn đề bị chặn bởi địa chỉ IP được giải quyết bằng cách sử dụng một số máy chủ proxy động. Hãy chắc chắn theo dõi tần suất yêu cầu để tránh quá tải các tài nguyên trực tuyến. Bằng cách này, bot sẽ ít bị nghi ngờ hơn, giảm nguy cơ bị cấm.
Theo dõi bằng vân tay số được vượt qua với sự giúp đỡ của Octo Browser, được thiết kế đặc biệt cho việc quản lý tài khoản nhiều. Phần mềm này thay thế vân tay của thiết bị bạn bằng vân tay khác của người dùng thực. Hồ sơ chống phát hiện của trình duyệt cho quản lý tài khoản nhiều không thể phân biệt được với các khách truy cập thông thường khác, vì vậy chúng không bị chặn hoặc bị buộc phải giải CAPTCHA.
Ngoài việc giả lập vân tay, Octo còn cung cấp các tính năng hữu ích khác đơn giản hóa việc web scraping, như:
Thêm proxy hàng loạt để tiết kiệm thời gian;
API cho tự động hóa;
Một trình duyệt headless giúp giảm tải thiết bị và tiêu thụ tài nguyên.
Ngôn ngữ Lập trình cho Web Scraping
Bạn có thể tìm thấy các framework, thư viện và công cụ cho web scraping trong nhiều ngôn ngữ khác nhau. Bright Data nổi bật năm ngôn ngữ phổ biến nhất:
Python có một hệ sinh thái phong phú về thư viện. Cú pháp đơn giản và các công cụ sẵn sàng như Beautiful Soup và Scrapy khiến nó trở thành lựa chọn lý tưởng cho web scraping. Tuy nhiên, Python có thể hoạt động kém hơn so với các ngôn ngữ biên dịch.
JavaScript được sử dụng trong phát triển front-end, vì vậy nó hỗ trợ các tính năng trình duyệt tích hợp. JavaScript có khả năng không đồng bộ và xử lý HTML trên các trang web. Bạn có thể sử dụng các thư viện như Axios, Cheerio, Puppeteer, và Playwright cho các mục đích này; tuy nhiên, khả năng của ngôn ngữ này bị giới hạn trong môi trường trình duyệt.
Ruby thu hút các nhà phát triển với cú pháp đơn giản, tính linh hoạt, đa dạng các thư viện web scraping (như Nokogiri, Mechanize, httparty, selenium-webdriver, OpenURI, và Wati), và cộng đồng tích cực. Tuy nhiên, Ruby tụt hậu so với các ngôn ngữ khác về hiệu suất.
PHP phù hợp với phát triển phía server và tích hợp với cơ sở dữ liệu. Cộng đồng tích cực và đa dạng các công cụ có sẵn là những lợi thế chính của PHP, và các thư viện như PHP Simple HTML DOM Parser, Guzzle, Panther, Httpful, và cURL phù hợp với web scraping. Tuy nhiên, hiệu suất và độ linh hoạt của PHP có thể thấp hơn một chút so với các ngôn ngữ khác.
C++ nổi bật với hiệu suất cao và kiểm soát hoàn toàn tài nguyên. Một lựa chọn phong phú các thư viện, bao gồm libcurl, Boost.Asio, htmlcxx, và libtidy, cùng với sự hỗ trợ từ cộng đồng, làm cho nó hấp dẫn đối với web scraping. Tuy nhiên, cú pháp của C++ phức tạp hơn so với các ngôn ngữ phổ biến khác. Bạn cũng cần có khả năng biên dịch mã, điều này có thể khiến một số nhà phát triển chùn bước.
Các loại Web Scrapers
Có bốn thông số chính để chọn công cụ scraping phù hợp.
Tự phát triển hoặc có sẵn
Bạn có thể tự tạo một web scraper nếu bạn biết lập trình. Càng muốn thêm nhiều tính năng, bạn càng cần nhiều kiến thức để viết bot. Mặt khác, bạn có thể tìm thấy các chương trình có sẵn trên mạng mà ngay cả những người không biết lập trình cũng có thể hiểu được. Một số trong số chúng thậm chí còn có các tính năng bổ sung, như lập lịch, xuất JSON, và tích hợp với Google Sheets.
Tiện ích mở rộng trình duyệt so với phần mềm
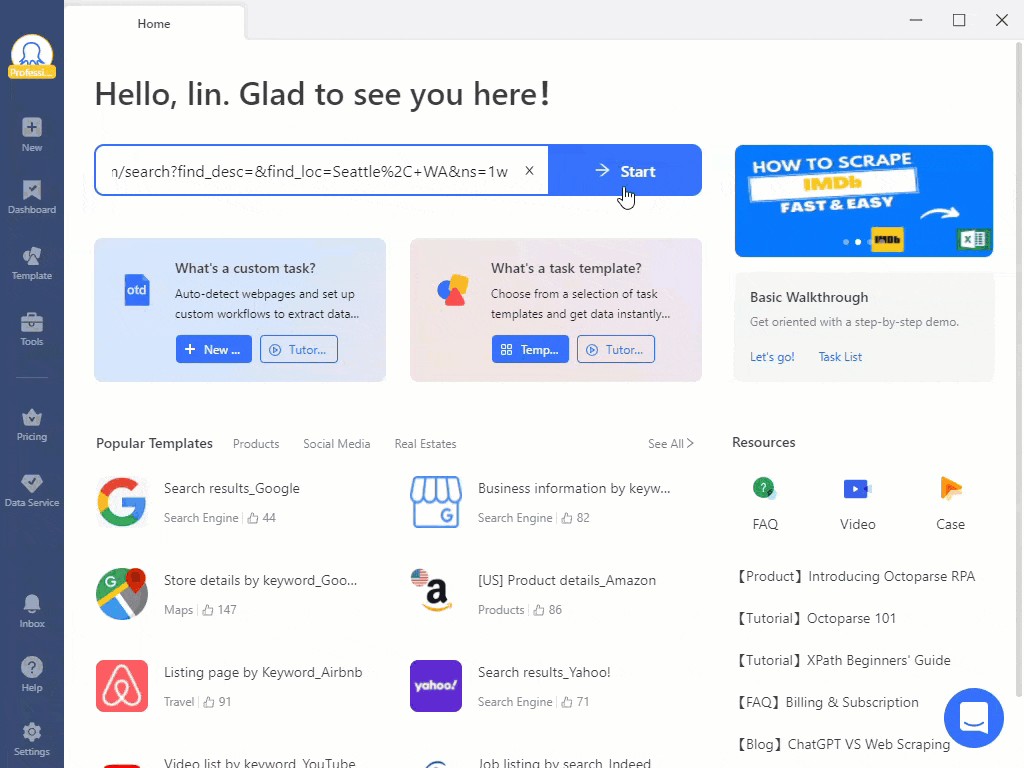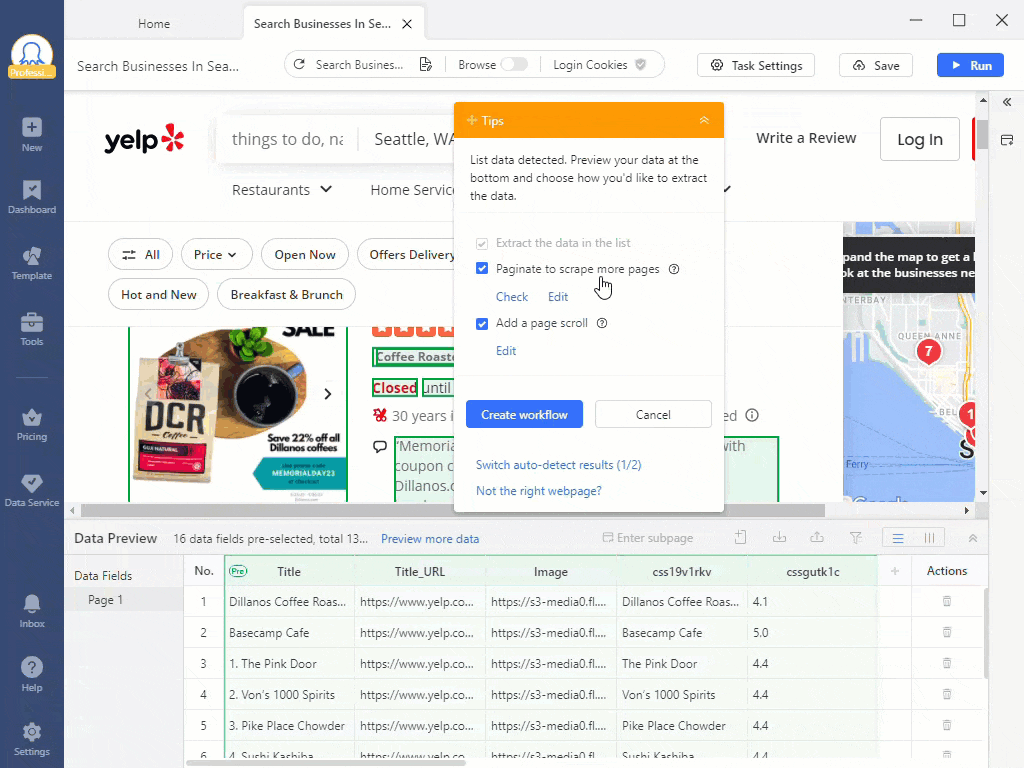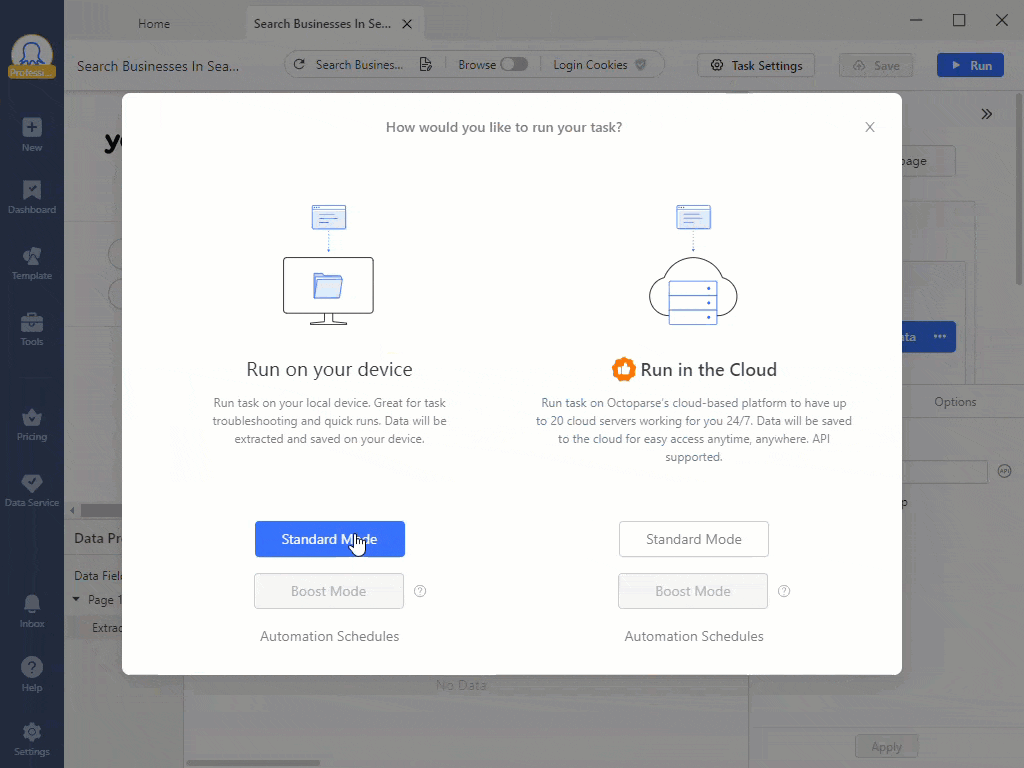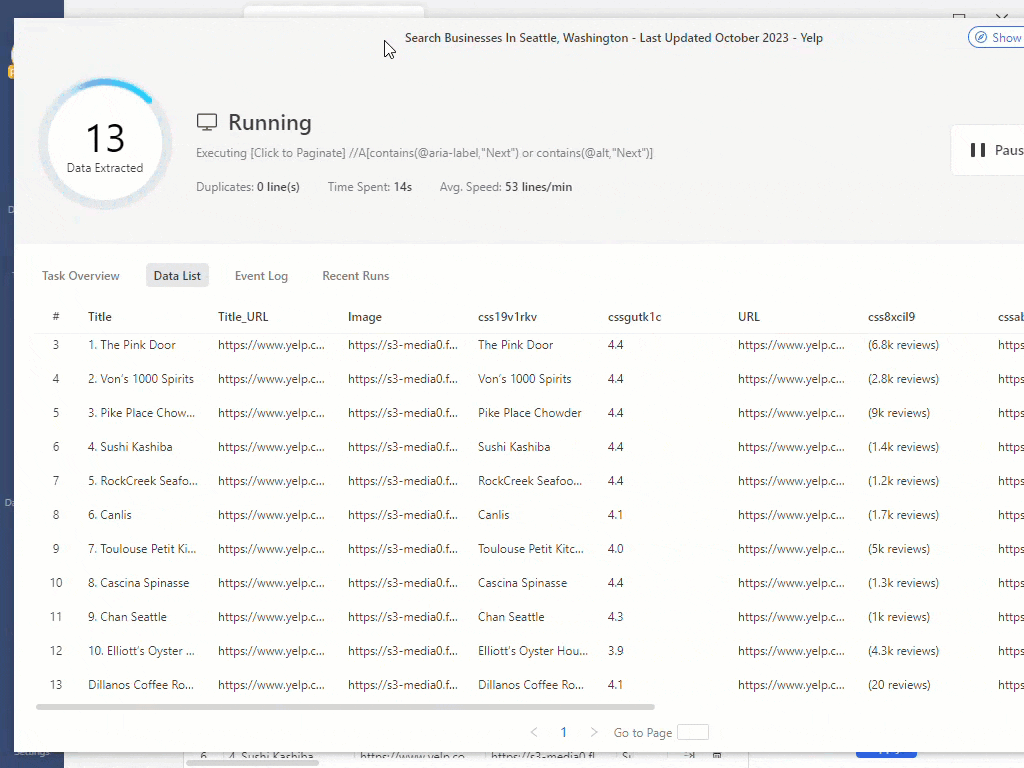
Làm việc với một tiện ích mở rộng được cài đặt trong trình duyệt là lựa chọn dễ nhất, nhưng khả năng của nó bị giới hạn. Ví dụ, xoay IP có thể không khả dụng. Trong khi đó, các chương trình phần mềm độc lập phức tạp hơn nhưng cung cấp nhiều tính năng hơn. Ví dụ, trong Octoparse bạn có thể tạo web scraper của riêng mình, sẽ quét các trang theo lịch trình, cung cấp hướng dẫn trong quá trình và giải CAPTCHA.
Giao diện người dùng
Một số giải pháp web scraping chỉ có giao diện dòng lệnh và tối thiểu UI, trong khi những giải pháp khác hiển thị trang web, cho phép bạn chọn thông tin muốn thu thập. Một số dịch vụ thậm chí bao gồm các lời nhắc giúp người dùng hiểu từng chức năng.
Đám mây so với cục bộ
Web scrapers cục bộ sử dụng RAM của thiết bị cục bộ, vì vậy bạn không thể thực hiện các quy trình khác cùng lúc. Các công cụ dựa trên đám mây hoạt động trên một máy chủ từ xa. Trong khi parser thu thập dữ liệu, bạn có thể thực hiện các tác vụ khác trên thiết bị của mình. Dịch vụ dựa trên đám mây cũng bao gồm các tính năng bổ sung, như xoay IP.
Web Scraping được sử dụng cho những gì?
Các bảng tính được tạo ra bởi web scrapers được các chuyên viên marketing, phân tích, và doanh nhân sử dụng. Những cách phổ biến để sử dụng cơ sở dữ liệu thu thập từ Internet là:
Nghiên cứu thị trường
Các chuyên viên marketing phân tích ưu và nhược điểm của sản phẩm, giá cả, phương thức giao hàng, và chiến lược của đối thủ. Thông qua web scraping, các nhà tiếp thị thu được lượng lớn dữ liệu chính xác, giúp cải thiện độ chính xác của dự báo và tối ưu hóa chiến lược marketing.
Theo dõi giá cả
Các trang tổng hợp so sánh giá và tìm kiếm sản phẩm rẻ nhất, và các dịch vụ chuyên biệt phân tích biến động giá. Một số công ty liên tục theo dõi giá của đối thủ và điều chỉnh giá của chính mình để duy trì mức giá thấp nhất. Tất cả chúng đều lấy thông tin cần thiết thông qua web scraping.
Tự động hóa kinh doanh
Nhân viên công ty tiêu tốn rất nhiều thời gian để thu thập và xử lý lượng lớn thông tin. Ví dụ, nghiên cứu 10 trang web của đối thủ có thể mất đến vài ngày. Một script có thể làm công việc đó trong vài giờ và tiết kiệm nguồn lực của nhân viên.
Tạo khách hàng tiềm năng
Tìm kiếm khách hàng là nhiệm vụ chính của các nhà tiếp thị. Để làm điều này, họ nghiên cứu nhu cầu của người dùng, vấn đề, sở thích và hành vi. Web scraping đẩy nhanh việc tìm kiếm khách hàng tiềm năng. Phương pháp này đặc biệt tiện lợi cho lĩnh vực B2B, vì các công ty thường không giấu thông tin trực tuyến về họ.
Theo dõi tin tức & nội dung
Danh tiếng của công ty ảnh hưởng đến lòng tin của khách hàng và doanh thu. Để phản ứng kịp thời với những đề cập tiêu cực, các quản lý PR theo dõi tin tức thông qua Brand Analytics hàng ngày và theo dõi tin tức về đối thủ. Các trang web như vậy thu thập các đề cập đến thương hiệu bằng cách sử dụng web scrapers.
Web Scraping có hợp pháp không?
Một phần lớn thông tin trực tuyến có sẵn cho tất cả người dùng. Ví dụ, bạn có thể truy cập Wikipedia, đọc một bài viết, và sao chép văn bản của nó. Không có gì là bất hợp pháp khi làm điều tương tự tự động. Bị cấm trích xuất nội dung mà:
được bảo vệ bởi bản quyền;
chứa dữ liệu cá nhân;
chỉ được truy cập bởi người dùng đã đăng ký của dịch vụ.
Một vấn đề khác là tải trọng lên các trang web do bot tạo ra. Nếu có quá nhiều yêu cầu từ các robot, người dùng sẽ không thể truy cập tài nguyên. Để tuân thủ pháp luật, hãy giám sát thông tin bạn thu thập và tần suất gửi yêu cầu.
Mọi điều bạn cần biết về Web Scraping
Web scraping là quá trình thu thập dữ liệu từ Internet, được sử dụng trong phân tích marketing, giám sát giá cả và tin tức, và tự động hóa các quy trình thường xuyên. Bạn có thể trích xuất thông tin từ các trang web thủ công hoặc thông qua các công cụ đặc biệt gọi là web scrapers. Thông thường, chúng được chia thành bốn loại: phần mềm mã nguồn mở, tiện ích mở rộng trình duyệt, HTTP client, và dịch vụ dựa trên API và CDP.
Trong quá trình web scraping, scrapers có thể gặp phải các biện pháp bảo vệ của trang web: CAPTCHA, các bẫy khác nhau, chặn dựa trên địa chỉ IP và vân tay. Những điều này được vượt qua hoặc tránh được với sự giúp đỡ của ba dịch vụ bổ sung: công cụ giải CAPTCHA, proxy, và trình duyệt quản lý tài khoản nhiều.
Giữ kín danh tính, tận dụng tính năng nhiều tài khoản và đạt được mục tiêu của bạn với trình duyệt chống phát hiện chất lượng cao nhất trên thị trường.
Bạn có muốn thử Octo Browser với giá giảm không?
Sử dụng mã khuyến mãi OCTOSCRAPER để được giảm giá 30% cho bất kỳ gói đăng ký nào. Ưu đãi này chỉ dành cho người dùng mới.
Web Scraping là gì?
Web scraping là quá trình thu thập lượng lớn thông tin từ web bằng cách sử dụng bot. Quá trình này bao gồm hai giai đoạn: tìm kiếm thông tin cần thiết và cấu trúc nó. Khi bạn sao chép dữ liệu văn bản từ một trang web và sau đó dán nó vào một tài liệu, về cơ bản bạn cũng đang thực hiện web scraping. Sự khác biệt là các script làm việc nhanh hơn, tránh được lỗi, và trích xuất thông tin từ mã HTML thay vì các thành phần trực quan của trang. Web scrapers thu thập cơ sở dữ liệu được sử dụng cho so sánh giá, phân tích thị trường, tạo khách hàng tiềm năng, và theo dõi tin tức.
Các Web Scrapers hoạt động như thế nào?
Các script, bot, API, và dịch vụ GUI cho web scraping thường theo một mô hình chung. Đầu tiên, bạn biên soạn danh sách các trang web mà robot sẽ truy cập và quyết định thông tin nào nó sẽ trích xuất. Ví dụ, để so sánh giá, bạn cần tên sản phẩm, liên kết cửa hàng và giá cả. Đối với phân tích cạnh tranh, bạn cũng cần thông số kỹ thuật sản phẩm, phương pháp vận chuyển và đánh giá. Càng ít chi tiết bạn yêu cầu, script sẽ thu thập chúng càng nhanh.
Một khi nhiệm vụ được hình thành, bot truy cập vào các trang, tải mã HTML, và trích xuất thông tin. Các script phức tạp hơn cũng có thể phân tích CSS và JavaScript.
Đôi khi cần phải đăng nhập vào tài khoản trên nền tảng để thu thập dữ liệu, ví dụ khi bạn cần thu thập dữ liệu liên lạc của chuyên gia trên LinkedIn. Trong những trường hợp như vậy, thuật toán để vượt qua các biện pháp bảo vệ của trang web được thêm vào thuật toán thu thập thông tin.
Bước cuối cùng là cấu trúc thông tin thu thập được dưới dạng bảng hoặc bảng tính (CSV hoặc Excel), cơ sở dữ liệu, hoặc định dạng JSON, thích hợp cho API.
Công cụ Web Scraping
Để thu thập dữ liệu, bạn cần một web scraper sẽ truy cập vào trang đích và truy xuất thông tin cần thiết từ nó. Có một số tùy chọn để bạn lựa chọn:
Phần mềm mã nguồn mở được tạo ra đặc biệt cho web scraping: Scrapy, Crawlee, Mechanize;
Các HTTP client: Requests, HTTPX, Axios để trích xuất dữ liệu từ HTML, XML, RSS, ví dụ như Beautiful Soup, lxml, Cheerio;
Giải pháp tự động hóa trình duyệt: Puppeteer, Playwright, Selenium và các dịch vụ khác có thể kết nối với trình duyệt, truy xuất HTML/XML và phân tích tài liệu;
Các dịch vụ như Zyte, Apify, Surfsky, Browserless, Scrapingbee, Import.io, cung cấp API hoặc CDP và hoạt động như một trung gian giữa script khách hàng và dịch vụ đích.
Chúng tôi đã thảo luận về những dịch vụ này chi tiết hơn ở đây.
Để thực hiện web scraping thành công, ngoài một parser, bạn sẽ cần:
Một công cụ để vượt qua CAPTCHAs;
Các proxy;
Một trình duyệt cho việc quản lý tài khoản nhiều.
Các chủ sở hữu trang web áp dụng các biện pháp bảo vệ khỏi web scraping bằng cách theo dõi địa chỉ IP và các định danh thiết bị duy nhất gọi là vân tay số. Nếu hệ thống bảo vệ phát hiện hoạt động đáng ngờ, chẳng hạn như yêu cầu quá thường xuyên từ một thiết bị, chúng sẽ chặn truy cập vào trang web.
Một số trang web thêm CAPTCHA để ngăn chặn web scrapers thu thập dữ liệu. Các dịch vụ đặc biệt, như 2Captcha, CapSolver, Death By Captcha, và BypassCaptcha có thể giải CAPTCHA. Bạn cần tích hợp dịch vụ vào ứng dụng, gọi nó thông qua API, vượt qua CAPTCHA, và nhận giải pháp trong vài giây. Công cụ giải CAPTCHA hỗ trợ các ngôn ngữ lập trình phổ biến, như PHP, JavaScript, C#, Java, và Python.
Vấn đề bị chặn bởi địa chỉ IP được giải quyết bằng cách sử dụng một số máy chủ proxy động. Hãy chắc chắn theo dõi tần suất yêu cầu để tránh quá tải các tài nguyên trực tuyến. Bằng cách này, bot sẽ ít bị nghi ngờ hơn, giảm nguy cơ bị cấm.
Theo dõi bằng vân tay số được vượt qua với sự giúp đỡ của Octo Browser, được thiết kế đặc biệt cho việc quản lý tài khoản nhiều. Phần mềm này thay thế vân tay của thiết bị bạn bằng vân tay khác của người dùng thực. Hồ sơ chống phát hiện của trình duyệt cho quản lý tài khoản nhiều không thể phân biệt được với các khách truy cập thông thường khác, vì vậy chúng không bị chặn hoặc bị buộc phải giải CAPTCHA.
Ngoài việc giả lập vân tay, Octo còn cung cấp các tính năng hữu ích khác đơn giản hóa việc web scraping, như:
Thêm proxy hàng loạt để tiết kiệm thời gian;
API cho tự động hóa;
Một trình duyệt headless giúp giảm tải thiết bị và tiêu thụ tài nguyên.
Ngôn ngữ Lập trình cho Web Scraping
Bạn có thể tìm thấy các framework, thư viện và công cụ cho web scraping trong nhiều ngôn ngữ khác nhau. Bright Data nổi bật năm ngôn ngữ phổ biến nhất:
Python có một hệ sinh thái phong phú về thư viện. Cú pháp đơn giản và các công cụ sẵn sàng như Beautiful Soup và Scrapy khiến nó trở thành lựa chọn lý tưởng cho web scraping. Tuy nhiên, Python có thể hoạt động kém hơn so với các ngôn ngữ biên dịch.
JavaScript được sử dụng trong phát triển front-end, vì vậy nó hỗ trợ các tính năng trình duyệt tích hợp. JavaScript có khả năng không đồng bộ và xử lý HTML trên các trang web. Bạn có thể sử dụng các thư viện như Axios, Cheerio, Puppeteer, và Playwright cho các mục đích này; tuy nhiên, khả năng của ngôn ngữ này bị giới hạn trong môi trường trình duyệt.
Ruby thu hút các nhà phát triển với cú pháp đơn giản, tính linh hoạt, đa dạng các thư viện web scraping (như Nokogiri, Mechanize, httparty, selenium-webdriver, OpenURI, và Wati), và cộng đồng tích cực. Tuy nhiên, Ruby tụt hậu so với các ngôn ngữ khác về hiệu suất.
PHP phù hợp với phát triển phía server và tích hợp với cơ sở dữ liệu. Cộng đồng tích cực và đa dạng các công cụ có sẵn là những lợi thế chính của PHP, và các thư viện như PHP Simple HTML DOM Parser, Guzzle, Panther, Httpful, và cURL phù hợp với web scraping. Tuy nhiên, hiệu suất và độ linh hoạt của PHP có thể thấp hơn một chút so với các ngôn ngữ khác.
C++ nổi bật với hiệu suất cao và kiểm soát hoàn toàn tài nguyên. Một lựa chọn phong phú các thư viện, bao gồm libcurl, Boost.Asio, htmlcxx, và libtidy, cùng với sự hỗ trợ từ cộng đồng, làm cho nó hấp dẫn đối với web scraping. Tuy nhiên, cú pháp của C++ phức tạp hơn so với các ngôn ngữ phổ biến khác. Bạn cũng cần có khả năng biên dịch mã, điều này có thể khiến một số nhà phát triển chùn bước.
Các loại Web Scrapers
Có bốn thông số chính để chọn công cụ scraping phù hợp.
Tự phát triển hoặc có sẵn
Bạn có thể tự tạo một web scraper nếu bạn biết lập trình. Càng muốn thêm nhiều tính năng, bạn càng cần nhiều kiến thức để viết bot. Mặt khác, bạn có thể tìm thấy các chương trình có sẵn trên mạng mà ngay cả những người không biết lập trình cũng có thể hiểu được. Một số trong số chúng thậm chí còn có các tính năng bổ sung, như lập lịch, xuất JSON, và tích hợp với Google Sheets.
Tiện ích mở rộng trình duyệt so với phần mềm
Làm việc với một tiện ích mở rộng được cài đặt trong trình duyệt là lựa chọn dễ nhất, nhưng khả năng của nó bị giới hạn. Ví dụ, xoay IP có thể không khả dụng. Trong khi đó, các chương trình phần mềm độc lập phức tạp hơn nhưng cung cấp nhiều tính năng hơn. Ví dụ, trong Octoparse bạn có thể tạo web scraper của riêng mình, sẽ quét các trang theo lịch trình, cung cấp hướng dẫn trong quá trình và giải CAPTCHA.
Giao diện người dùng
Một số giải pháp web scraping chỉ có giao diện dòng lệnh và tối thiểu UI, trong khi những giải pháp khác hiển thị trang web, cho phép bạn chọn thông tin muốn thu thập. Một số dịch vụ thậm chí bao gồm các lời nhắc giúp người dùng hiểu từng chức năng.
Đám mây so với cục bộ
Web scrapers cục bộ sử dụng RAM của thiết bị cục bộ, vì vậy bạn không thể thực hiện các quy trình khác cùng lúc. Các công cụ dựa trên đám mây hoạt động trên một máy chủ từ xa. Trong khi parser thu thập dữ liệu, bạn có thể thực hiện các tác vụ khác trên thiết bị của mình. Dịch vụ dựa trên đám mây cũng bao gồm các tính năng bổ sung, như xoay IP.
Web Scraping được sử dụng cho những gì?
Các bảng tính được tạo ra bởi web scrapers được các chuyên viên marketing, phân tích, và doanh nhân sử dụng. Những cách phổ biến để sử dụng cơ sở dữ liệu thu thập từ Internet là:
Nghiên cứu thị trường
Các chuyên viên marketing phân tích ưu và nhược điểm của sản phẩm, giá cả, phương thức giao hàng, và chiến lược của đối thủ. Thông qua web scraping, các nhà tiếp thị thu được lượng lớn dữ liệu chính xác, giúp cải thiện độ chính xác của dự báo và tối ưu hóa chiến lược marketing.
Theo dõi giá cả
Các trang tổng hợp so sánh giá và tìm kiếm sản phẩm rẻ nhất, và các dịch vụ chuyên biệt phân tích biến động giá. Một số công ty liên tục theo dõi giá của đối thủ và điều chỉnh giá của chính mình để duy trì mức giá thấp nhất. Tất cả chúng đều lấy thông tin cần thiết thông qua web scraping.
Tự động hóa kinh doanh
Nhân viên công ty tiêu tốn rất nhiều thời gian để thu thập và xử lý lượng lớn thông tin. Ví dụ, nghiên cứu 10 trang web của đối thủ có thể mất đến vài ngày. Một script có thể làm công việc đó trong vài giờ và tiết kiệm nguồn lực của nhân viên.
Tạo khách hàng tiềm năng
Tìm kiếm khách hàng là nhiệm vụ chính của các nhà tiếp thị. Để làm điều này, họ nghiên cứu nhu cầu của người dùng, vấn đề, sở thích và hành vi. Web scraping đẩy nhanh việc tìm kiếm khách hàng tiềm năng. Phương pháp này đặc biệt tiện lợi cho lĩnh vực B2B, vì các công ty thường không giấu thông tin trực tuyến về họ.
Theo dõi tin tức & nội dung
Danh tiếng của công ty ảnh hưởng đến lòng tin của khách hàng và doanh thu. Để phản ứng kịp thời với những đề cập tiêu cực, các quản lý PR theo dõi tin tức thông qua Brand Analytics hàng ngày và theo dõi tin tức về đối thủ. Các trang web như vậy thu thập các đề cập đến thương hiệu bằng cách sử dụng web scrapers.
Web Scraping có hợp pháp không?
Một phần lớn thông tin trực tuyến có sẵn cho tất cả người dùng. Ví dụ, bạn có thể truy cập Wikipedia, đọc một bài viết, và sao chép văn bản của nó. Không có gì là bất hợp pháp khi làm điều tương tự tự động. Bị cấm trích xuất nội dung mà:
được bảo vệ bởi bản quyền;
chứa dữ liệu cá nhân;
chỉ được truy cập bởi người dùng đã đăng ký của dịch vụ.
Một vấn đề khác là tải trọng lên các trang web do bot tạo ra. Nếu có quá nhiều yêu cầu từ các robot, người dùng sẽ không thể truy cập tài nguyên. Để tuân thủ pháp luật, hãy giám sát thông tin bạn thu thập và tần suất gửi yêu cầu.
Mọi điều bạn cần biết về Web Scraping
Web scraping là quá trình thu thập dữ liệu từ Internet, được sử dụng trong phân tích marketing, giám sát giá cả và tin tức, và tự động hóa các quy trình thường xuyên. Bạn có thể trích xuất thông tin từ các trang web thủ công hoặc thông qua các công cụ đặc biệt gọi là web scrapers. Thông thường, chúng được chia thành bốn loại: phần mềm mã nguồn mở, tiện ích mở rộng trình duyệt, HTTP client, và dịch vụ dựa trên API và CDP.
Trong quá trình web scraping, scrapers có thể gặp phải các biện pháp bảo vệ của trang web: CAPTCHA, các bẫy khác nhau, chặn dựa trên địa chỉ IP và vân tay. Những điều này được vượt qua hoặc tránh được với sự giúp đỡ của ba dịch vụ bổ sung: công cụ giải CAPTCHA, proxy, và trình duyệt quản lý tài khoản nhiều.
Cập nhật với các tin tức Octo Browser mới nhất
Khi nhấp vào nút này, bạn sẽ đồng ý với Chính sách Quyền riêng tư của chúng tôi.
Cập nhật với các tin tức Octo Browser mới nhất
Khi nhấp vào nút này, bạn sẽ đồng ý với Chính sách Quyền riêng tư của chúng tôi.
Cập nhật với các tin tức Octo Browser mới nhất
Khi nhấp vào nút này, bạn sẽ đồng ý với Chính sách Quyền riêng tư của chúng tôi.

Tham gia Octo Browser ngay
Hoặc liên hệ với Dịch vụ khách hàng bất kì lúc nào nếu bạn có bất cứ thắc mắc nào.
Tham gia Octo Browser ngay
Hoặc liên hệ với Dịch vụ khách hàng bất kì lúc nào nếu bạn có bất cứ thắc mắc nào.
Tham gia Octo Browser ngay
Hoặc liên hệ với Dịch vụ khách hàng bất kì lúc nào nếu bạn có bất cứ thắc mắc nào.