反机器人系统:它们如何工作以及如何绕过它们


Infatica
Infatica is a global platform offering effective proxy solutions for web scraping and affiliate marketing.
反机器人系统保护网站免受有害的自动化交互,例如垃圾邮件或DDoS攻击。然而,并非所有的自动化活动都是有害的。机器人通常对安全测试、构建搜索索引和收集公共数据至关重要。Infatica团队解释了反机器人系统的工作原理,并分享了绕过这些系统以进行网络抓取的有效方法。
内容
使用Octo Browser维护您的在线匿名性。您真实的数字指纹无法被追踪。
您想以折扣价格尝试 Octo 浏览器吗?
使用促销代码 OCTOSCRAPER 获得任何订阅 30% 的折扣。此优惠仅适用于新用户。
反机器人系统如何检测机器人
反机器人系统收集每位访客的广泛数据,以识别非人类的行为模式。假如访客的行为、网络或设备设置的任何方面似乎不正常,他们可能会被阻止,或者面临 CAPTCHA 来确认他们是人类。反机器人检测通常在三个层次上工作:
网络层:反机器人系统分析访客的 IP 地址,检查其是否与垃圾邮件、数据中心或Tor 网络相关联。他们还会检查数据包头部和大小。处于“黑名单”上的 IP 地址或者高垃圾邮件评分的 IP 地址通常会触发 CAPTCHA。例如,使用免费的 VPN 有时会导致 Google 的 CAPTCHA 挑战。
浏览器指纹层:这些系统收集有关访客的浏览器和设备的详细信息,建立数字指纹。该指纹可以包括浏览器类型、版本、语言设置、屏幕分辨率、窗口大小、硬件配置、系统字体等。
行为层:高级反机器人系统分析用户行为,比如鼠标移动和滚动模式,将其与常规访客活动进行比较。
有许多反机器人系统,每种系统的具体细节可能相差甚远并随时间而变化。流行的解决方案包括:
Akamai
Cloudflare
Datadome
Incapsula
Casada
Perimeterx
了解网站使用的反机器人系统类型可以帮助您找到绕过它的最佳方法。您可以在论坛和 Discord 频道(如网络爬虫俱乐部)找到关于避免特定反机器人系统的有用技巧和方法。
要查看网站的反机器人保护,您可以使用Wappalyzer 浏览器扩展工具。Wappalyzer 显示网站的不同技术,包括反机器人系统,使您能够更轻松地计划如何有效地抓取该网站。
如何绕过反机器人系统?
要绕过反机器人系统,您必须在每个检测层级上掩盖自己的行为。以下是一些实际的方法:
构建自定义解决方案:创建您自己的工具并自行管理基础设施。这让您拥有完全的控制权,但需要技术技能。
使用付费服务:像 Apify、Scrapingbee、Browserless 或 Surfsky 等平台提供现成的抓取解决方案,可以避免检测。
结合解决方案:使用高质量的代理、CAPTCHA 解决器和反检测浏览器的组合,以降低被标记为机器人的风险。
无头反检测浏览器:以无头模式运行浏览器。此解决方案多功能,通常适用于更简单的抓取任务。
探索其他解决方案:有许多方法可以绕过反机器人系统,从简单设置到复杂的多层次方法。选择适合您任务复杂性和预算的方案。但请记住:任务越复杂,所需的伪装、掩盖和整体保护水平就越高。
网络层伪装
要在网络层保持机器人的隐蔽,使用高质量的代理。对于较小的任务,您可能可以使用自己的 IP 地址,但对于大规模数据收集,这种方法将不起作用。在这种情况下,可靠的住宅或移动代理是必不可少的。高质量的代理降低了被阻止的风险,并帮助您稳定地发送成千上万的请求而无需被标记。避免使用可能被列入黑名单的便宜、低质量的代理,因为它们可能会迅速暴露机器人的活动。
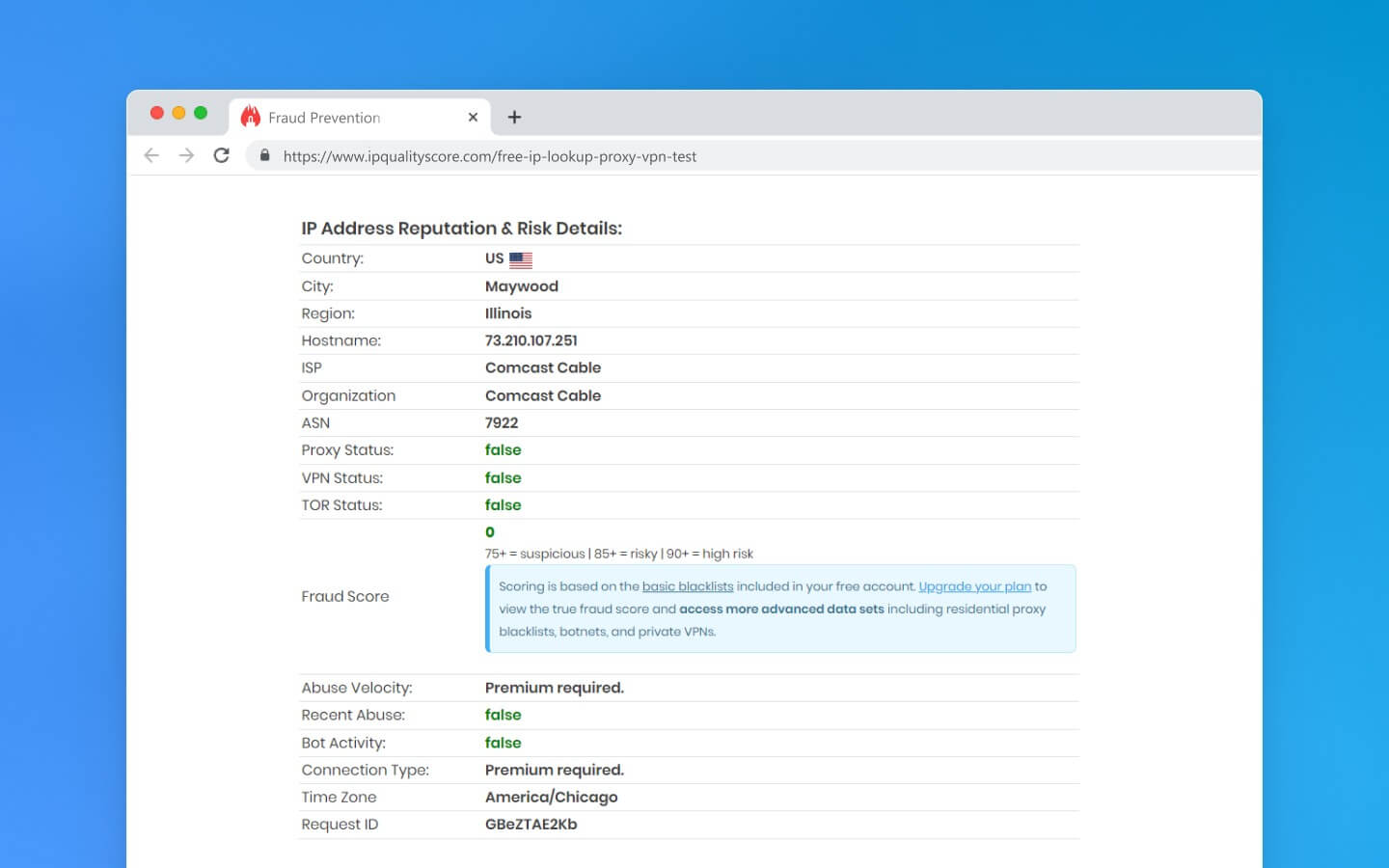
选择抓取用的代理时,请牢记以下关键点:
检查垃圾邮件数据库:使用 PixelScan 或 Firehol(iplists.firehol.org)等工具确认代理的 IP 地址没有被标记为垃圾邮件。这有助于确保 IP 不会看起来可疑。
避免 DNS 泄漏:进行DNS 泄漏测试,以确保代理不会泄露您的真实地址。服务器列表上应仅出现代理的 IP 地址。
使用可靠的代理类型:来自 ISP 的代理看起来更合规,相比于数据中心代理不容易引起警觉。
考虑使用轮换代理:这些代理提供访问 IP 池,每个请求或定期自动更换 IP。这减少了被阻止的风险,使网站更难以检测您机器人的活动模式。
这些步骤将帮助确保您的代理适合于大型数据收集,而不会引起不必要的反机器人注意。
轮换代理在网页抓取中特别有用。它们提供多种 IP 访问,而不是使用单一 IP 地址,有助于掩盖机器人的活动。通过频繁更换 IP 地址,轮换代理使得网站更难以检测您请求中的模式,从而降低被阻止的风险。这在机器人需要发送大量请求时尤为重要,因为它将请求分散到不同的 IP 上,而不是让单个 IP 过载。
指纹层伪装
多账户(反检测)浏览器非常适合伪装浏览器指纹,而像 Octo Browser 这样的高质量浏览器进一步提供了浏览器内核层面的伪装。它们允许您创建多个浏览器配置文件,每个配置文件看起来都是一个独立的用户。
使用反检测浏览器,抓取数据变得灵活,可以使用自动化库或框架。您可以设置多个配置文件,配备所需的指纹设置、代理和 Cookie,无需打开浏览器。这些配置文件可以在自动化或手动模式下使用。
使用多账户浏览器与在无头模式下使用标准浏览器没有太大区别。Octo Browser 甚至提供详细文档,包括流行编程语言的 API 连接指南,使设置易于跟随。
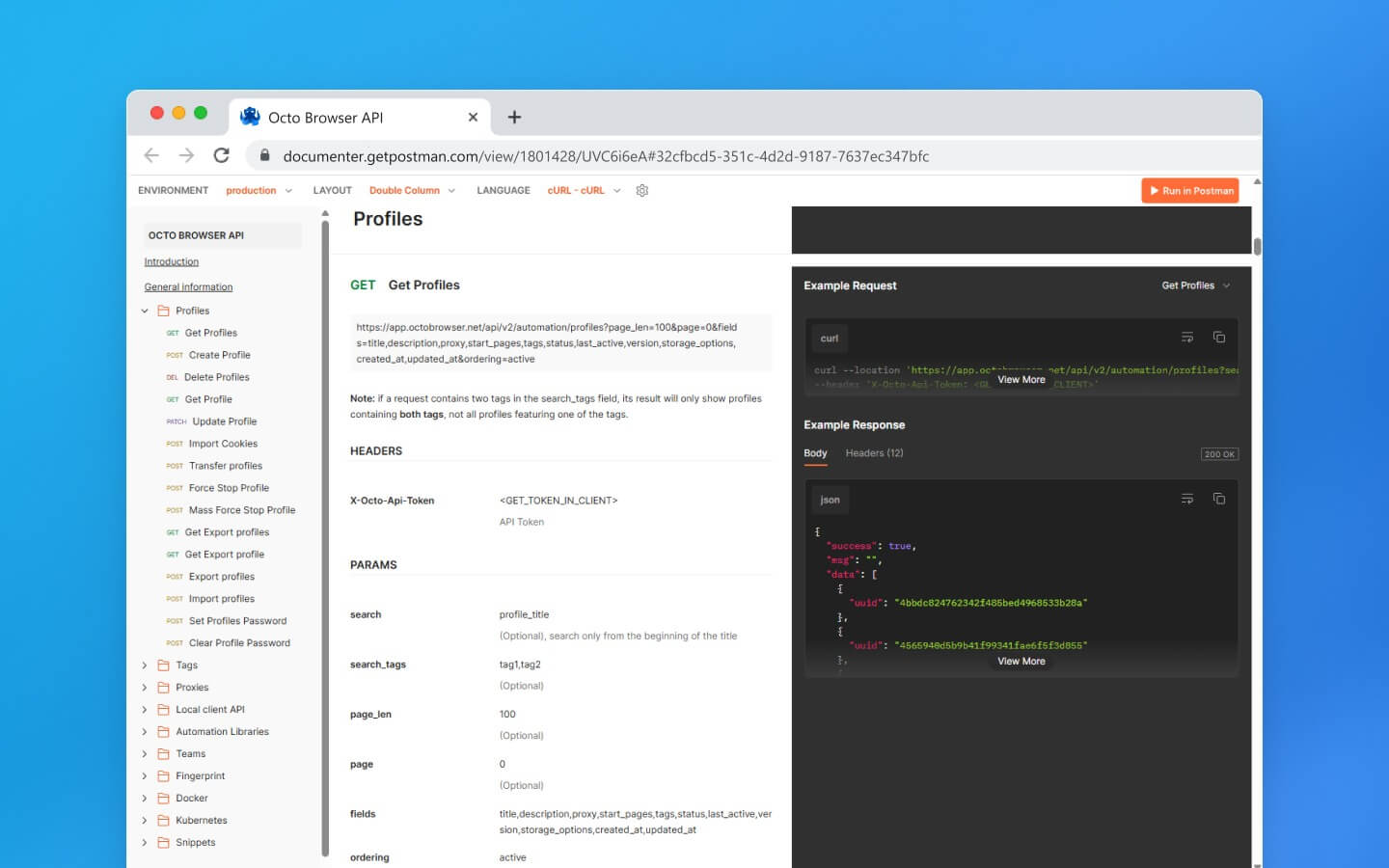
专业的反检测浏览器使管理多个配置文件、连接代理以及访问标准抓取工具无法到达的数据变得简单,得益于先进的数字指纹伪装。
模拟真实用户行为
要有效地绕过反机器人系统,模拟真实用户的行为至关重要。这包括延迟、自然移动光标、节奏打字、随机暂停以及显示不规则行为。日常模拟行为包括登录、点击“阅读更多”、导航链接、填写表单和滚动浏览内容。
您可以使用流行的开源自动化工具(如 Selenium 或其他工具,例如 MechanicalSoup 和 Nightmare.js)来模拟这些行为。通过在请求之间添加随机间隔的延迟,使抓取看起来更自然是非常有帮助的。
结论
反机器人系统分析网络、浏览器和行为数据以封锁机器人。要有效绕过它们,必须在每个层级上进行伪装:
网络层:始终使用高质量的轮换代理来逃避检测。
Infatica 提供道德来源的代理解决方案,具备企业级性能——使用优惠代码OCTO10可享受独家折扣。
浏览器指纹:使用像 Octo Browser 这样的反检测浏览器来逃避基于指纹的封锁。
行为模拟:部署浏览器自动化解决方案,如 Selenium,增强不规则延迟和真实交互,以模仿常规人类用户。
这些策略共同构成了安全可靠的网页抓取的坚实、可扩展基础。
使用Octo Browser维护您的在线匿名性。您真实的数字指纹无法被追踪。
您想以折扣价格尝试 Octo 浏览器吗?
使用促销代码 OCTOSCRAPER 获得任何订阅 30% 的折扣。此优惠仅适用于新用户。
反机器人系统如何检测机器人
反机器人系统收集每位访客的广泛数据,以识别非人类的行为模式。假如访客的行为、网络或设备设置的任何方面似乎不正常,他们可能会被阻止,或者面临 CAPTCHA 来确认他们是人类。反机器人检测通常在三个层次上工作:
网络层:反机器人系统分析访客的 IP 地址,检查其是否与垃圾邮件、数据中心或Tor 网络相关联。他们还会检查数据包头部和大小。处于“黑名单”上的 IP 地址或者高垃圾邮件评分的 IP 地址通常会触发 CAPTCHA。例如,使用免费的 VPN 有时会导致 Google 的 CAPTCHA 挑战。
浏览器指纹层:这些系统收集有关访客的浏览器和设备的详细信息,建立数字指纹。该指纹可以包括浏览器类型、版本、语言设置、屏幕分辨率、窗口大小、硬件配置、系统字体等。
行为层:高级反机器人系统分析用户行为,比如鼠标移动和滚动模式,将其与常规访客活动进行比较。
有许多反机器人系统,每种系统的具体细节可能相差甚远并随时间而变化。流行的解决方案包括:
Akamai
Cloudflare
Datadome
Incapsula
Casada
Perimeterx
了解网站使用的反机器人系统类型可以帮助您找到绕过它的最佳方法。您可以在论坛和 Discord 频道(如网络爬虫俱乐部)找到关于避免特定反机器人系统的有用技巧和方法。
要查看网站的反机器人保护,您可以使用Wappalyzer 浏览器扩展工具。Wappalyzer 显示网站的不同技术,包括反机器人系统,使您能够更轻松地计划如何有效地抓取该网站。
如何绕过反机器人系统?
要绕过反机器人系统,您必须在每个检测层级上掩盖自己的行为。以下是一些实际的方法:
构建自定义解决方案:创建您自己的工具并自行管理基础设施。这让您拥有完全的控制权,但需要技术技能。
使用付费服务:像 Apify、Scrapingbee、Browserless 或 Surfsky 等平台提供现成的抓取解决方案,可以避免检测。
结合解决方案:使用高质量的代理、CAPTCHA 解决器和反检测浏览器的组合,以降低被标记为机器人的风险。
无头反检测浏览器:以无头模式运行浏览器。此解决方案多功能,通常适用于更简单的抓取任务。
探索其他解决方案:有许多方法可以绕过反机器人系统,从简单设置到复杂的多层次方法。选择适合您任务复杂性和预算的方案。但请记住:任务越复杂,所需的伪装、掩盖和整体保护水平就越高。
网络层伪装
要在网络层保持机器人的隐蔽,使用高质量的代理。对于较小的任务,您可能可以使用自己的 IP 地址,但对于大规模数据收集,这种方法将不起作用。在这种情况下,可靠的住宅或移动代理是必不可少的。高质量的代理降低了被阻止的风险,并帮助您稳定地发送成千上万的请求而无需被标记。避免使用可能被列入黑名单的便宜、低质量的代理,因为它们可能会迅速暴露机器人的活动。
选择抓取用的代理时,请牢记以下关键点:
检查垃圾邮件数据库:使用 PixelScan 或 Firehol(iplists.firehol.org)等工具确认代理的 IP 地址没有被标记为垃圾邮件。这有助于确保 IP 不会看起来可疑。
避免 DNS 泄漏:进行DNS 泄漏测试,以确保代理不会泄露您的真实地址。服务器列表上应仅出现代理的 IP 地址。
使用可靠的代理类型:来自 ISP 的代理看起来更合规,相比于数据中心代理不容易引起警觉。
考虑使用轮换代理:这些代理提供访问 IP 池,每个请求或定期自动更换 IP。这减少了被阻止的风险,使网站更难以检测您机器人的活动模式。
这些步骤将帮助确保您的代理适合于大型数据收集,而不会引起不必要的反机器人注意。
轮换代理在网页抓取中特别有用。它们提供多种 IP 访问,而不是使用单一 IP 地址,有助于掩盖机器人的活动。通过频繁更换 IP 地址,轮换代理使得网站更难以检测您请求中的模式,从而降低被阻止的风险。这在机器人需要发送大量请求时尤为重要,因为它将请求分散到不同的 IP 上,而不是让单个 IP 过载。
指纹层伪装
多账户(反检测)浏览器非常适合伪装浏览器指纹,而像 Octo Browser 这样的高质量浏览器进一步提供了浏览器内核层面的伪装。它们允许您创建多个浏览器配置文件,每个配置文件看起来都是一个独立的用户。
使用反检测浏览器,抓取数据变得灵活,可以使用自动化库或框架。您可以设置多个配置文件,配备所需的指纹设置、代理和 Cookie,无需打开浏览器。这些配置文件可以在自动化或手动模式下使用。
使用多账户浏览器与在无头模式下使用标准浏览器没有太大区别。Octo Browser 甚至提供详细文档,包括流行编程语言的 API 连接指南,使设置易于跟随。
专业的反检测浏览器使管理多个配置文件、连接代理以及访问标准抓取工具无法到达的数据变得简单,得益于先进的数字指纹伪装。
模拟真实用户行为
要有效地绕过反机器人系统,模拟真实用户的行为至关重要。这包括延迟、自然移动光标、节奏打字、随机暂停以及显示不规则行为。日常模拟行为包括登录、点击“阅读更多”、导航链接、填写表单和滚动浏览内容。
您可以使用流行的开源自动化工具(如 Selenium 或其他工具,例如 MechanicalSoup 和 Nightmare.js)来模拟这些行为。通过在请求之间添加随机间隔的延迟,使抓取看起来更自然是非常有帮助的。
结论
反机器人系统分析网络、浏览器和行为数据以封锁机器人。要有效绕过它们,必须在每个层级上进行伪装:
网络层:始终使用高质量的轮换代理来逃避检测。
Infatica 提供道德来源的代理解决方案,具备企业级性能——使用优惠代码OCTO10可享受独家折扣。
浏览器指纹:使用像 Octo Browser 这样的反检测浏览器来逃避基于指纹的封锁。
行为模拟:部署浏览器自动化解决方案,如 Selenium,增强不规则延迟和真实交互,以模仿常规人类用户。
这些策略共同构成了安全可靠的网页抓取的坚实、可扩展基础。
随时获取最新的Octo Browser新闻
通过点击按钮,您同意我们的 隐私政策。
随时获取最新的Octo Browser新闻
通过点击按钮,您同意我们的 隐私政策。
随时获取最新的Octo Browser新闻
通过点击按钮,您同意我们的 隐私政策。
