什么是网络爬虫,它是如何工作的?


Palina Zabela
Content Manager, Octo Browser
网络爬虫是一种快速收集在线信息的方法。机器人扫描网站并提取产品价格、在线商店的商品种类、潜在客户的联系信息等等。这些信息随后被出售或用于业务发展。此外,神经网络还会在网络爬虫收集的数据上进行训练。如何自动从网站收集信息?在这个过程中使用了哪些工具?如何访问受保护的信息?Octo浏览器团队准备了一份详细的指南来解答这些问题。
内容
保持匿名,充分利用多账户功能,借助市面上最优质的反检测浏览器实现您的目标。
您想以折扣价格尝试 Octo 浏览器吗?
使用促销代码 OCTOSCRAPER 获得任何订阅 30% 的折扣。此优惠仅适用于新用户。
什么是网页抓取?
网页抓取是使用机器人从网络收集大量信息的过程。此过程包括两个阶段:查找必要的信息和结构化信息。当您从网站复制文本数据并粘贴到文档中时,您实际上也是在进行网页抓取。其不同之处在于,脚本的工作速度更快,避免错误,并且从HTML代码中提取信息,而不是页面的视觉组件。网页抓取程序收集用于价格比较、市场分析、潜在客户生成和新闻监测的数据库。
网页抓取工具如何工作?
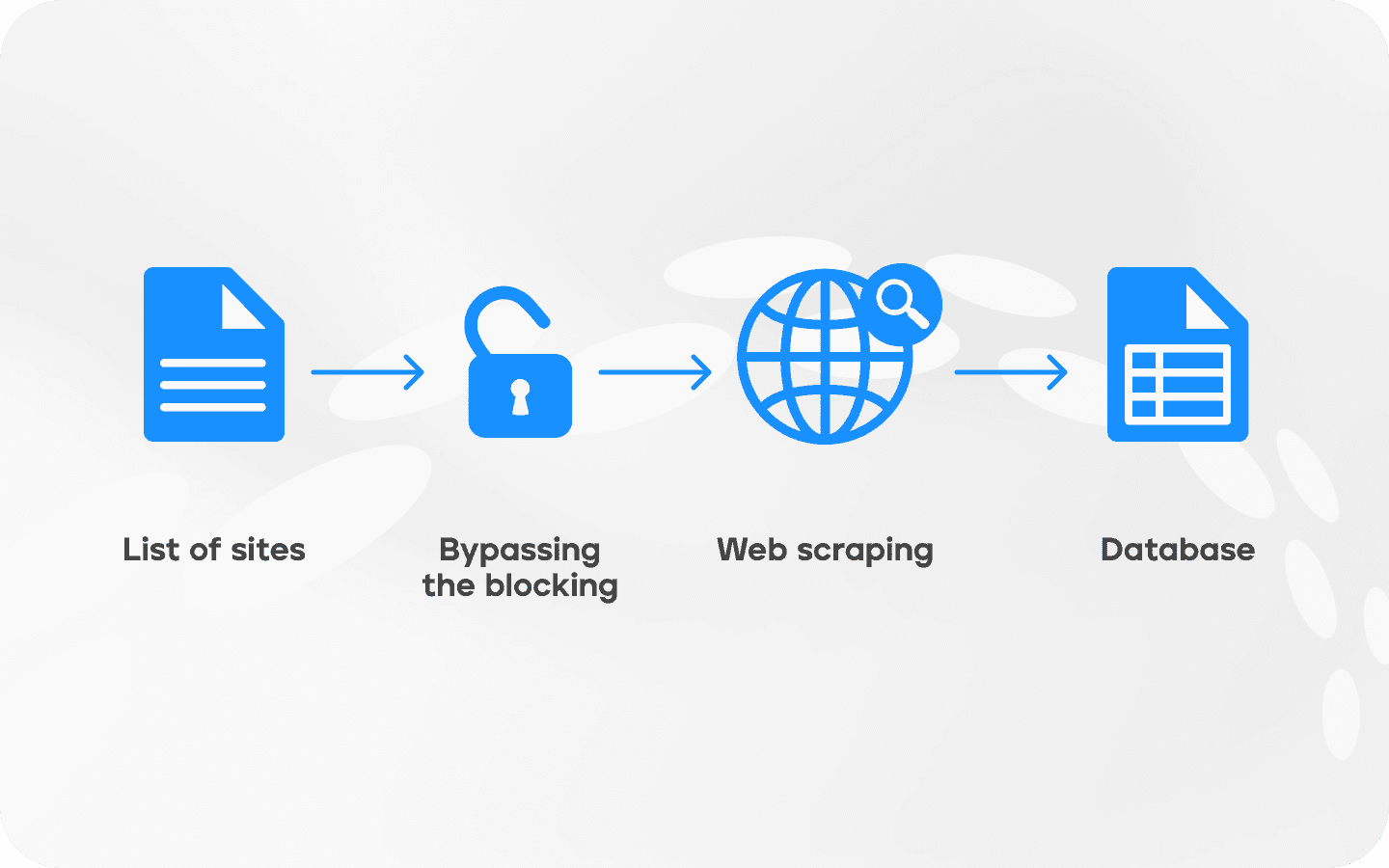
脚本、机器人、API和基于GUI的网页抓取服务本质上遵循相同的模式。首先,您需要编制一个机器人将访问的网站列表,并决定要提取哪些信息。例如,对于价格比较,您需要产品名称、商店链接和价格本身。对于竞争分析,您还需要产品规格、运输方式和评价。您请求的细节越少,脚本收集它们的速度就会越快。
一旦任务被制定,机器人就会访问页面,加载HTML代码并提取信息。更复杂的脚本也能够分析CSS和JavaScript。
有时,需要登录平台账户才能收集数据,例如,当您需要在LinkedIn上收集专门人士的联系方式时。在这种情况下,会在信息收集算法中加入绕过网站保护措施的算法。
最后一步是将收集到的信息结构化,形成表格或电子表格(CSV或Excel)、数据库或JSON格式,适合API使用。
网页抓取工具

要收集数据,您需要一个网页抓取程序去访问目标网站并从中获取必要的信息。有几种选项可供选择:
专门为网页抓取创建的开源软件:Scrapy、Crawlee、Mechanize;
HTTP客户端:Requests、HTTPX、Axios,用于从HTML、XML、RSS中提取数据,例如,Beautiful Soup、lxml、Cheerio;
浏览器自动化解决方案:Puppeteer、Playwright、Selenium及其他可以连接到浏览器、检索HTML/XML并解析文档的服务;
像Zyte、Apify、Surfsky、Browserless、Scrapingbee、Import.io这样的服务,提供API或CDP,并充当客户端脚本与目标服务之间的中介。
我们对此类服务进行了更详细的讨论在这里。
为了成功进行网页抓取,除了解析器外,您还需要以下内容:
一个能够绕过CAPTCHA的工具;
代理;
用于多账户操作的浏览器。
网站所有者通过追踪IP地址和称为数字指纹的唯一设备标识符来实施针对网页抓取的保护措施。如果保护系统检测到可疑活动,例如来自同一设备的请求过于频繁,它们会阻止访问该网站。
一些网站添加CAPTCHA以防止网页抓取程序收集数据。特殊服务,如2Captcha、CapSolver、Death By Captcha和BypassCaptcha能够解决CAPTCHA。您需要将服务集成到应用中,通过API调用它,传递CAPTCHA,并在几秒钟内获得解决方案。CAPTCHA解决工具支持流行的编程语言,如PHP、JavaScript、C#、Java和Python。
通过使用几个动态代理服务器,可以解决IP地址被阻止的问题。务必监控请求的频率,以避免过载在线资源。这样,机器人将吸引较少的怀疑,降低被封禁的可能性。
通过数字指纹的追踪可通过Octo Browser来绕过,该浏览器专为多账户操作而设计。这款软件用真实用户的设备替换您设备的指纹。多账户浏览器的反检测配置文件与其他普通访客没有区别,因此不会被阻止或强制解决CAPTCHA。
除了指纹伪装外,Octo还提供其他有用功能,使网页抓取更简单,例如:
批量添加代理以节省时间;
用于自动化的API;
减轻设备负荷和资源消耗的无头浏览器。
用于网页抓取的编程语言
您可以在多种语言中找到用于网页抓取的框架、库和工具。Bright Data强调了五种最流行的语言:
Python拥有丰富的库生态系统。其简单的语法和现成的工具,如Beautiful Soup和Scrapy,使其成为网页抓取的理想选择。然而,与编译语言相比,Python的性能可能稍差。
JavaScript用于前端开发,因此支持内置的浏览器功能。JavaScript具有异步能力,能够处理网页上的HTML。您可以使用Axios、Cheerio、Puppeteer和Playwright等库来实现这些目的;然而,该语言的功能仅局限于浏览器环境。
Ruby因其简单的语法、灵活性、多种网页抓取库(如Nokogiri、Mechanize、httparty、selenium-webdriver、OpenURI和Wati)和活跃的社区而吸引开发者。然而,Ruby的性能落后于其他语言。
PHP适合服务器端开发以及与数据库的集成。活跃的社区和各种可用工具是PHP的主要优势,像PHP Simple HTML DOM Parser、Guzzle、Panther、Httpful和cURL这样的库适合用于网页抓取。然而,PHP的性能和灵活性可能稍低于其他语言。
C++以高性能和对资源的完全控制著称。丰富的库选择,包括libcurl、Boost.Asio、htmlcxx和libtidy,以及社区支持,使其在网页抓取中具有吸引力。然而,C++的语法比其他流行语言更复杂。您还需要能够编译代码,这可能会让某些开发者却步。
网页抓取器的类型
选择合适的抓取工具有四个关键参数。
自制或预制
如果您会编码,可以自己创建一个网页抓取器。您希望添加的功能越多,编写机器人所需的知识就越多。另一方面,您可以在网上找到现成的程序,这些程序即使是对于不会编程的人也易于理解。其中一些甚至具有额外的功能,如调度、JSON导出和与Google Sheets的集成。
浏览器扩展与软件
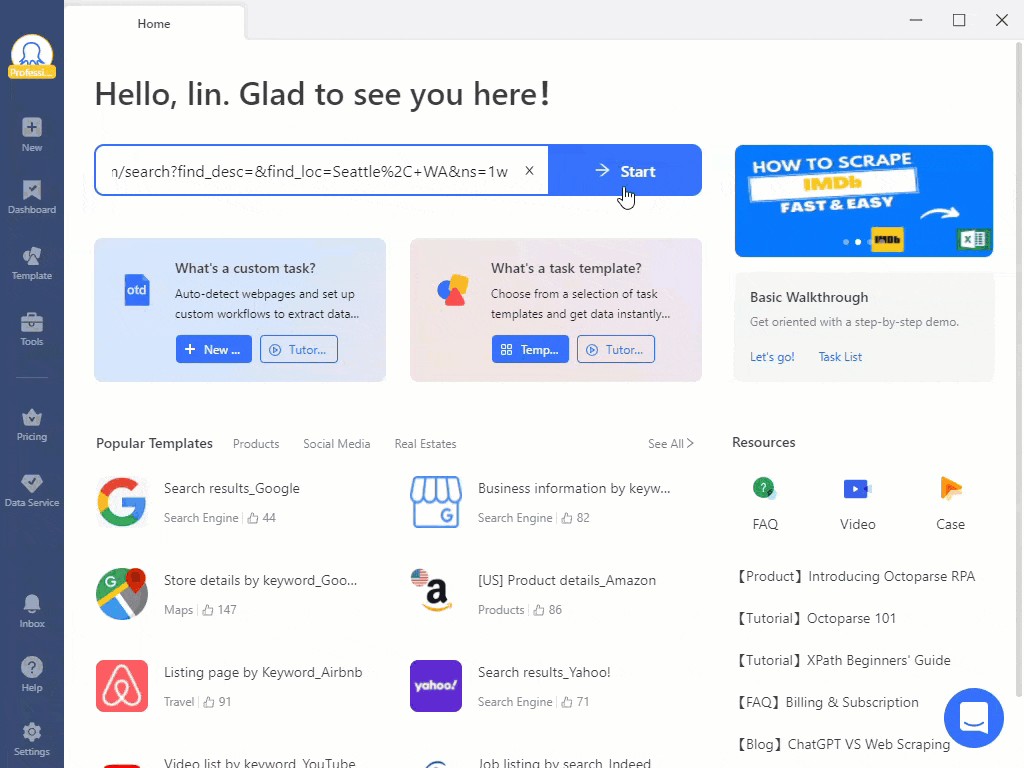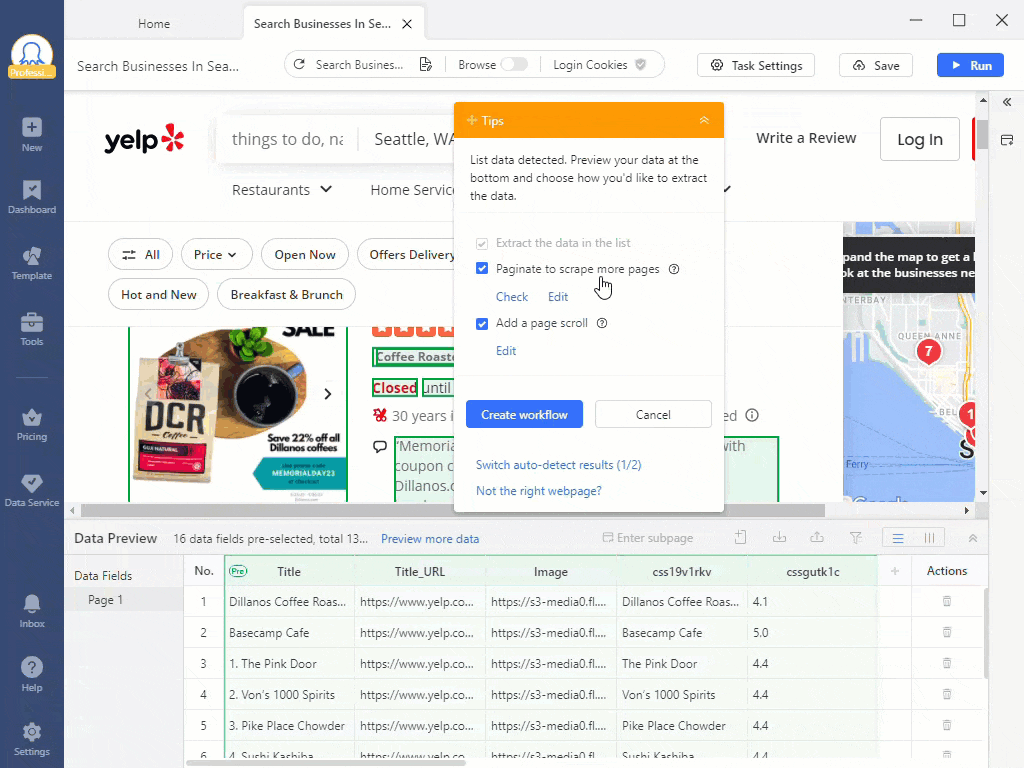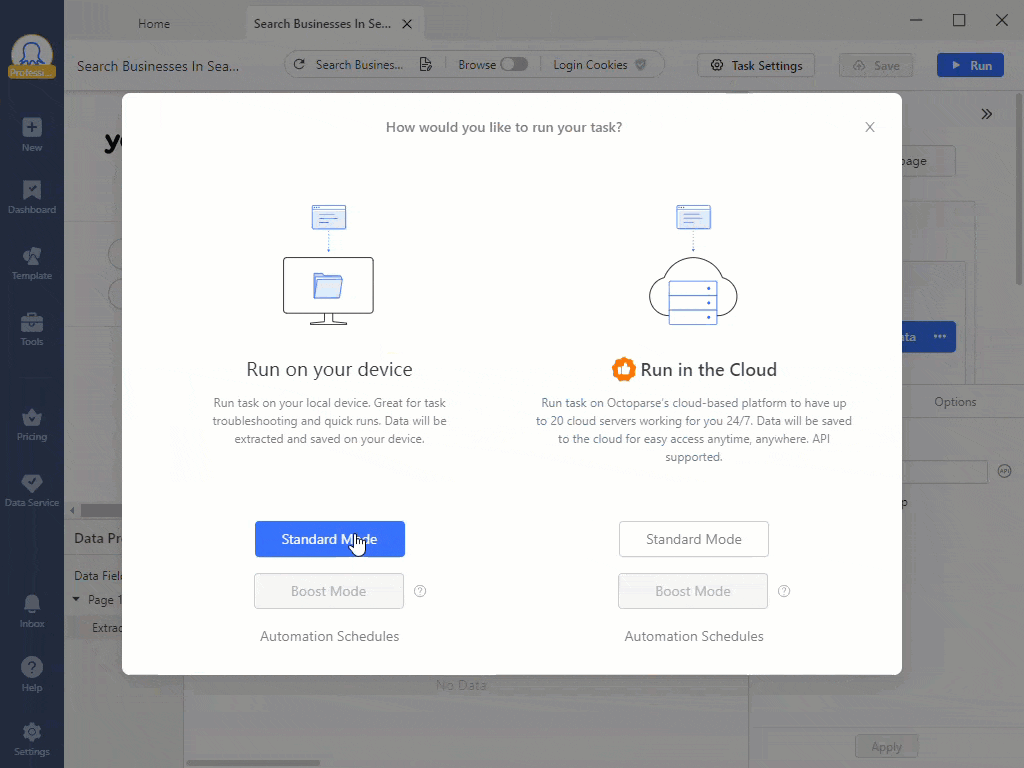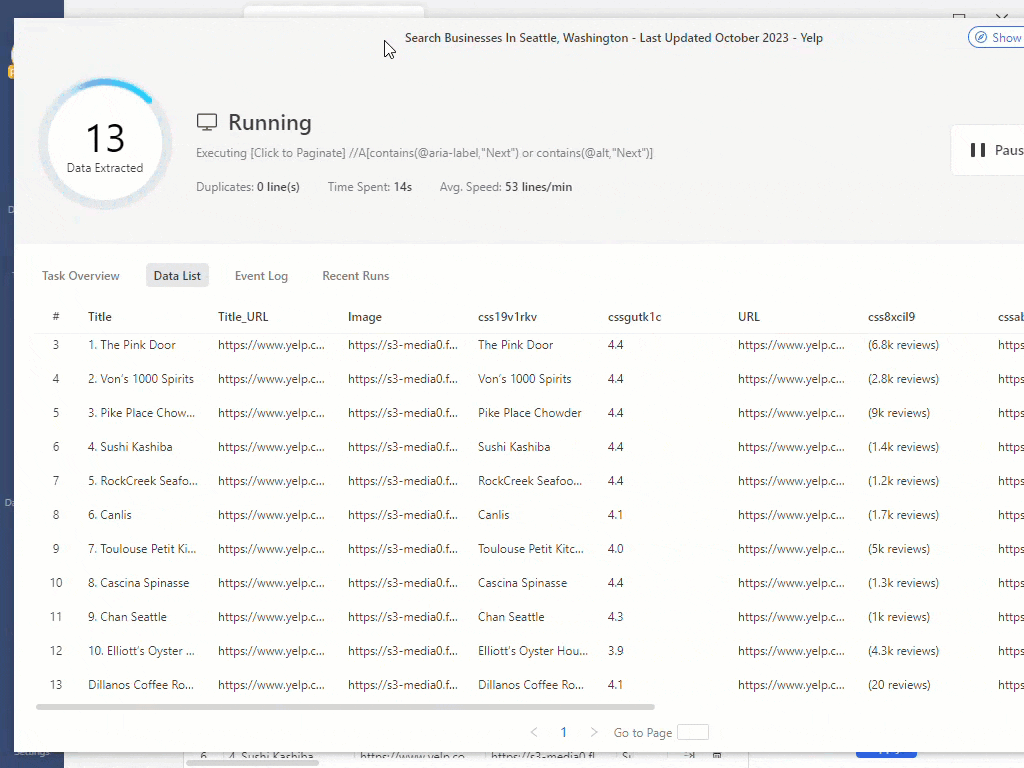
在浏览器中安装的扩展程序是最简单的选项,但其功能有限。例如,IP轮换可能不可用。与此同时,独立的软件程序更复杂,但提供更多功能。例如,您可以在Octoparse中创建自己的网页抓取器,该程序将按计划扫描网站,提供过程指导并解决CAPTCHA。
用户界面
一些网页抓取解决方案只有命令行界面和最小的用户界面,而其他解决方案则显示网站,允许您选择想要收集的信息。有些服务甚至包括工具提示,以帮助用户理解每个功能的目的。
云与本地
本地网页抓取器利用本地设备的内存,因此您无法同时运行其他进程。基于云的工具在远程服务器上工作。当解析器收集数据时,您可以在设备上执行其他任务。云服务还包括其他功能,如IP轮换。
网页抓取的用途是什么?
网页抓取程序创建的电子表格被市场专员、分析师和企业人士使用。从互联网收集的数据库的流行用途有:
市场研究
市场专员分析产品的优缺点、价格、交货方式和竞争对手的策略。通过网页抓取,市场营销人员获取大量准确数据,这有助于提高预测准确性并优化市场营销策略。
价格跟踪
聚合器比较价格并寻找最便宜的产品,专业服务分析价格变动。一些公司不断监控竞争对手的价格并调整自己的价格以保持最低。所有这些信息都通过网页抓取获得。
业务自动化
公司员工花费大量时间收集和处理大量信息。例如,研究10个竞争对手网站可能需要几天时间。而脚本可以在几个小时内完成同样的工作,节省员工的资源。
潜在客户生成
寻找客户是市场专员的主要任务。为此,他们研究用户的需求、问题、兴趣和行为。网页抓取加快了潜在客户的搜索。这种方法对于B2B领域尤为方便,因为公司并不隐藏关于自己的在线信息。
新闻与内容监测
公司声誉会影响客户信任和收入。为了及时对负面提及作出反应,公关经理每天通过品牌分析监测新闻,并跟踪竞争对手的新闻。这类网站使用网页抓取程序收集品牌提及。
网页抓取合法吗?
大量在线信息对所有用户开放。例如,您可以访问维基百科,阅读一篇文章并复制其文本。以自动化方式进行相同操作并没有什么非法。抓取以下内容是被禁止的:
受版权保护的内容;
包含个人数据的内容;
仅向注册用户提供的内容。
另一个问题是由机器人造成的网站负载。如果机器人发送的请求过多,用户将无法访问该资源。为了遵守法律,请监控您收集的信息以及发送请求的频率。
关于网页抓取您需要知道的一切
网页抓取是从互联网上收集数据的过程,所收集的数据用于市场分析、价格和新闻监测以及例行过程的自动化。您可以手动提取信息或通过称为网页抓取器的特殊工具进行提取。通常,它们分为四种类型:开源软件、浏览器扩展、HTTP客户端以及基于API和CDP的服务。
在进行网页抓取时,抓取程序可能会遇到网站的保护措施:CAPTCHA、各种陷阱、基于IP地址和指纹的阻塞。通过使用三种额外服务:CAPTCHA解决工具、代理和多账户浏览器,可以绕过或避免这些问题。
保持匿名,充分利用多账户功能,借助市面上最优质的反检测浏览器实现您的目标。
您想以折扣价格尝试 Octo 浏览器吗?
使用促销代码 OCTOSCRAPER 获得任何订阅 30% 的折扣。此优惠仅适用于新用户。
什么是网页抓取?
网页抓取是使用机器人从网络收集大量信息的过程。此过程包括两个阶段:查找必要的信息和结构化信息。当您从网站复制文本数据并粘贴到文档中时,您实际上也是在进行网页抓取。其不同之处在于,脚本的工作速度更快,避免错误,并且从HTML代码中提取信息,而不是页面的视觉组件。网页抓取程序收集用于价格比较、市场分析、潜在客户生成和新闻监测的数据库。
网页抓取工具如何工作?
脚本、机器人、API和基于GUI的网页抓取服务本质上遵循相同的模式。首先,您需要编制一个机器人将访问的网站列表,并决定要提取哪些信息。例如,对于价格比较,您需要产品名称、商店链接和价格本身。对于竞争分析,您还需要产品规格、运输方式和评价。您请求的细节越少,脚本收集它们的速度就会越快。
一旦任务被制定,机器人就会访问页面,加载HTML代码并提取信息。更复杂的脚本也能够分析CSS和JavaScript。
有时,需要登录平台账户才能收集数据,例如,当您需要在LinkedIn上收集专门人士的联系方式时。在这种情况下,会在信息收集算法中加入绕过网站保护措施的算法。
最后一步是将收集到的信息结构化,形成表格或电子表格(CSV或Excel)、数据库或JSON格式,适合API使用。
网页抓取工具
要收集数据,您需要一个网页抓取程序去访问目标网站并从中获取必要的信息。有几种选项可供选择:
专门为网页抓取创建的开源软件:Scrapy、Crawlee、Mechanize;
HTTP客户端:Requests、HTTPX、Axios,用于从HTML、XML、RSS中提取数据,例如,Beautiful Soup、lxml、Cheerio;
浏览器自动化解决方案:Puppeteer、Playwright、Selenium及其他可以连接到浏览器、检索HTML/XML并解析文档的服务;
像Zyte、Apify、Surfsky、Browserless、Scrapingbee、Import.io这样的服务,提供API或CDP,并充当客户端脚本与目标服务之间的中介。
我们对此类服务进行了更详细的讨论在这里。
为了成功进行网页抓取,除了解析器外,您还需要以下内容:
一个能够绕过CAPTCHA的工具;
代理;
用于多账户操作的浏览器。
网站所有者通过追踪IP地址和称为数字指纹的唯一设备标识符来实施针对网页抓取的保护措施。如果保护系统检测到可疑活动,例如来自同一设备的请求过于频繁,它们会阻止访问该网站。
一些网站添加CAPTCHA以防止网页抓取程序收集数据。特殊服务,如2Captcha、CapSolver、Death By Captcha和BypassCaptcha能够解决CAPTCHA。您需要将服务集成到应用中,通过API调用它,传递CAPTCHA,并在几秒钟内获得解决方案。CAPTCHA解决工具支持流行的编程语言,如PHP、JavaScript、C#、Java和Python。
通过使用几个动态代理服务器,可以解决IP地址被阻止的问题。务必监控请求的频率,以避免过载在线资源。这样,机器人将吸引较少的怀疑,降低被封禁的可能性。
通过数字指纹的追踪可通过Octo Browser来绕过,该浏览器专为多账户操作而设计。这款软件用真实用户的设备替换您设备的指纹。多账户浏览器的反检测配置文件与其他普通访客没有区别,因此不会被阻止或强制解决CAPTCHA。
除了指纹伪装外,Octo还提供其他有用功能,使网页抓取更简单,例如:
批量添加代理以节省时间;
用于自动化的API;
减轻设备负荷和资源消耗的无头浏览器。
用于网页抓取的编程语言
您可以在多种语言中找到用于网页抓取的框架、库和工具。Bright Data强调了五种最流行的语言:
Python拥有丰富的库生态系统。其简单的语法和现成的工具,如Beautiful Soup和Scrapy,使其成为网页抓取的理想选择。然而,与编译语言相比,Python的性能可能稍差。
JavaScript用于前端开发,因此支持内置的浏览器功能。JavaScript具有异步能力,能够处理网页上的HTML。您可以使用Axios、Cheerio、Puppeteer和Playwright等库来实现这些目的;然而,该语言的功能仅局限于浏览器环境。
Ruby因其简单的语法、灵活性、多种网页抓取库(如Nokogiri、Mechanize、httparty、selenium-webdriver、OpenURI和Wati)和活跃的社区而吸引开发者。然而,Ruby的性能落后于其他语言。
PHP适合服务器端开发以及与数据库的集成。活跃的社区和各种可用工具是PHP的主要优势,像PHP Simple HTML DOM Parser、Guzzle、Panther、Httpful和cURL这样的库适合用于网页抓取。然而,PHP的性能和灵活性可能稍低于其他语言。
C++以高性能和对资源的完全控制著称。丰富的库选择,包括libcurl、Boost.Asio、htmlcxx和libtidy,以及社区支持,使其在网页抓取中具有吸引力。然而,C++的语法比其他流行语言更复杂。您还需要能够编译代码,这可能会让某些开发者却步。
网页抓取器的类型
选择合适的抓取工具有四个关键参数。
自制或预制
如果您会编码,可以自己创建一个网页抓取器。您希望添加的功能越多,编写机器人所需的知识就越多。另一方面,您可以在网上找到现成的程序,这些程序即使是对于不会编程的人也易于理解。其中一些甚至具有额外的功能,如调度、JSON导出和与Google Sheets的集成。
浏览器扩展与软件
在浏览器中安装的扩展程序是最简单的选项,但其功能有限。例如,IP轮换可能不可用。与此同时,独立的软件程序更复杂,但提供更多功能。例如,您可以在Octoparse中创建自己的网页抓取器,该程序将按计划扫描网站,提供过程指导并解决CAPTCHA。
用户界面
一些网页抓取解决方案只有命令行界面和最小的用户界面,而其他解决方案则显示网站,允许您选择想要收集的信息。有些服务甚至包括工具提示,以帮助用户理解每个功能的目的。
云与本地
本地网页抓取器利用本地设备的内存,因此您无法同时运行其他进程。基于云的工具在远程服务器上工作。当解析器收集数据时,您可以在设备上执行其他任务。云服务还包括其他功能,如IP轮换。
网页抓取的用途是什么?
网页抓取程序创建的电子表格被市场专员、分析师和企业人士使用。从互联网收集的数据库的流行用途有:
市场研究
市场专员分析产品的优缺点、价格、交货方式和竞争对手的策略。通过网页抓取,市场营销人员获取大量准确数据,这有助于提高预测准确性并优化市场营销策略。
价格跟踪
聚合器比较价格并寻找最便宜的产品,专业服务分析价格变动。一些公司不断监控竞争对手的价格并调整自己的价格以保持最低。所有这些信息都通过网页抓取获得。
业务自动化
公司员工花费大量时间收集和处理大量信息。例如,研究10个竞争对手网站可能需要几天时间。而脚本可以在几个小时内完成同样的工作,节省员工的资源。
潜在客户生成
寻找客户是市场专员的主要任务。为此,他们研究用户的需求、问题、兴趣和行为。网页抓取加快了潜在客户的搜索。这种方法对于B2B领域尤为方便,因为公司并不隐藏关于自己的在线信息。
新闻与内容监测
公司声誉会影响客户信任和收入。为了及时对负面提及作出反应,公关经理每天通过品牌分析监测新闻,并跟踪竞争对手的新闻。这类网站使用网页抓取程序收集品牌提及。
网页抓取合法吗?
大量在线信息对所有用户开放。例如,您可以访问维基百科,阅读一篇文章并复制其文本。以自动化方式进行相同操作并没有什么非法。抓取以下内容是被禁止的:
受版权保护的内容;
包含个人数据的内容;
仅向注册用户提供的内容。
另一个问题是由机器人造成的网站负载。如果机器人发送的请求过多,用户将无法访问该资源。为了遵守法律,请监控您收集的信息以及发送请求的频率。
关于网页抓取您需要知道的一切
网页抓取是从互联网上收集数据的过程,所收集的数据用于市场分析、价格和新闻监测以及例行过程的自动化。您可以手动提取信息或通过称为网页抓取器的特殊工具进行提取。通常,它们分为四种类型:开源软件、浏览器扩展、HTTP客户端以及基于API和CDP的服务。
在进行网页抓取时,抓取程序可能会遇到网站的保护措施:CAPTCHA、各种陷阱、基于IP地址和指纹的阻塞。通过使用三种额外服务:CAPTCHA解决工具、代理和多账户浏览器,可以绕过或避免这些问题。
随时获取最新的Octo Browser新闻
通过点击按钮,您同意我们的 隐私政策。
随时获取最新的Octo Browser新闻
通过点击按钮,您同意我们的 隐私政策。
随时获取最新的Octo Browser新闻
通过点击按钮,您同意我们的 隐私政策。
