TCP 指纹如何让 your scraper 爬虫暴露


Markus_automation
Expert in data parsing and automation
将浏览器自动化从 Windows 迁移到 Linux 通常会带来意想不到的问题,即使脚本逻辑完全相同也是如此。爬虫可能会成功启动,打开所需的页面,但仍然会在没有任何明显错误的情况下停止收集数据。原因往往不隐藏在代码、代理或浏览器设置中,而是隐藏得更深——在操作系统的网络协议栈层面。
现代反欺诈系统不仅分析基于 JavaScript 的浏览器指纹,还分析低层级的网络通信特征。因此,浏览器在 Web 界面和 API 层面可能看起来是在 Windows 上运行,但通过 TCP/IP、TLS 和网络数据包显露出 Linux 特征。这种应用层和传输层之间的不匹配成为了自动化的另一个指标。
在本文中,我们将探讨这些不一致是如何产生的,为什么它们会影响爬取稳定性,以及反欺诈系统如何利用网络签名来识别自动化流量。
内容
保持匿名,充分利用多账户功能,借助市面上最优质的反检测浏览器实现您的目标。
您想以折扣价格尝试 Octo 浏览器吗?
使用促销代码 OCTOSCRAPER 获得任何订阅 30% 的折扣。此优惠仅适用于新用户。
为什么即使是完美的反检测浏览器也依然不够
为了理解问题的真实规模,让我们首先回顾一下标准的防封锁设置是如何工作的。
从历史上看,抓取是一场在 HTTP 和 JavaScript 层面展开的军备竞赛。当服务器开始封锁 python-requests 等默认请求头时,开发人员开始使用真实浏览器的 User-Agent 字符串。当反欺诈系统开始检查 navigator 属性时,我们转向了通过 Chrome DevTools Protocol (CDP) 修改的无头浏览器或现成的反检测解决方案。
我们已经习惯于控制 应用层(第 7 层)。这是 HTTP 运行、传输 cookie 和请求头以及执行 JavaScript 的层级。
问题在于,HTTP 请求并不是独立发送的。它被封装在传输协议(TCP——第 4 层)中,进而又被封装在网络协议(IP——第 3 层)中。这就是主要的架构陷阱所在:
L7(应用层)完全由您的应用程序控制——包括您的脚本、Puppeteer 或反检测浏览器。
L3 和 L4(网络和传输层)由物理运行代码(或流量通过的)操作系统内核控制。套接字
connect()调用只是将控制权交给了 Linux 或 Windows 网络栈,之后操作系统便根据其内部硬编码的规则构建数据包。
现代反欺诈系统深谙此道,并使用被动指纹技术,在发送第一个 HTTP 请求之前,分析 TCP 连接是如何建立的。
如果您的 L7 层 User-Agent 声称是 Windows 上的 Chrome,但服务器在 L4 层看到了 Linux 特有的 TCP SYN 数据包结构,反欺诈系统就会认为这是一个明显的异常。从服务器的角度来看,一台真实的 Windows 机器在物理上是不可能生成这样的网络数据包的。因此,这是一个伪装成普通用户的运行在 Linux 服务器上的机器人。接着反欺诈系统会根据其自身的策略做出反应:例如,Google Maps 可能会返回一个简化版页面、要求进行身份验证,并向您弹出 CAPTCHA 验证码。
TCP SYN 数据包的解剖:服务器如何识别您的真实操作系统
每个 HTTP(S) 连接都始于建立 TCP 连接——即所谓的三次握手。发送到目标资源的首个数据包是一个设置了 SYN 标志的网络数据包。这个微小的数据包包含了进行被动操作系统指纹识别所需的一切信息。安全系统甚至不需要等待您的 HTTP 请求头,它们通过检查 SYN 数据包内的服务字段,就能极其准确地确定是哪个操作系统内核创建了它。
主要有三个标记:
1. 生存时间 (TTL)
TTL 是一个计数器,数据包在前往服务器的途中每经过一个路由器,该值就会减 1。不同的操作系统使用不同的默认起始值:
Linux 和 macOS:默认 TTL 为 64。
Windows:默认 TTL 为 128。
如果 Google 的反欺诈系统收到一个 TTL 为 54 的数据包,便可以自信地断定源头是 Linux 或 macOS。如果收到的值是 115,那极有可能是 Windows。
2. TCP 窗口大小 (TCP Window Size)
这基本上就是接收缓冲区的大小。它表示一台设备一次准备接受多少数据。
由于数据是以大约 1460 字节的碎片形式传输的,操作系统通常会以该大小的倍数分配内存。然而,每个操作系统的分配机制不尽相同。
Linux 通常根据固定数量的数据包来分配初始窗口:
5840 = 4 个数据包 × 1460
14600 = 10 个数据包 × 1460
29200 = 20 个数据包 × 1460
当反欺诈系统看到 29200 时,它们能识别出这是 Linux 内核的典型特征。
Windows 则倾向于使用 2 的幂或最大值:
8192 = 8 KB
65535 = 能够装入 16 位窗口大小字段的最大值
64240 = 现代 Windows 版本使用的一种混合方法(44 个数据包 × 1460)
反欺诈系统会将这些值与您的 User-Agent 进行对比。如果您声称是 Windows 上的 Chrome,但您的窗口大小是 29200,这种不匹配就显而易见了。
3. TCP 选项顺序 (TCP Options order)
这是最强大的指纹识别机制。
SYN 数据包包含一些附加参数,如 MSS、Window Scaling、SACK Permitted、Timestamps 等。尽管这些值本身可能有所不同,但它们出现的顺序是硬编码在操作系统内核中的。
例如:
典型的 Windows 指纹:
MSS → NOP → Window Scaling → NOP → NOP → SACK Permitted
典型的 Linux 指纹:
MSS → SACK Permitted → Timestamps → NOP → Window Scaling
这些细节看似微不足道,但任何先进的反欺诈系统都会识别出这些不一致,从而限制会话并阻止稳定的抓取。
数据中心代理陷阱:为什么您的本地操作系统不再重要
如果 TCP/IP 指纹是个问题,那么一个显而易见的解决方案似乎是在 Windows Server 上运行爬虫。
假设您在一个干净的 Windows 机器上启动爬虫。操作系统会生成具有 TTL=128、合适窗口大小以及正确选项顺序的 TCP SYN 数据包。然而,CAPTCHA 验证码和会话中断依然会出现。原因在于代理服务器的工作方式。
严肃的抓取业务几乎总是依赖代理。在大多数自动化设置中,由于数据中心代理价格便宜、速度快且稳定,往往会被优先采用。但问题是,这些代理服务器绝大多数运行的是 Linux 发行版,如 Ubuntu、Debian 或 CentOS。
当您使用代理时,您的设备与 Google 的服务器之间并没有直接的网络连接。整个过程被分割为两个独立的连接:
连接 A(您的电脑 → 代理服务器)
您的 Windows 机器与代理建立 TCP 连接。
连接 B(代理服务器 → Google)
在收到您的请求后,代理会代表您向目标服务器创建一条全新的 TCP 连接。
由于代理服务器运行的是 Linux,因此发送给 Google 的 SYN 数据包实际上是由 Linux 网络栈生成的。
结果,Google 的反欺诈系统看到的是一个明显由 Linux 创建的 TCP 连接(TTL 64、Linux 样式的窗口大小、Linux 系统的 TCP 选项顺序)。然而,在该连接内部(L7 层),它看到的 HTTP 请求头却声称自己是 Windows 上的 Chrome。
数据中心代理会暴露您的本地传输层指纹。即使您运行着昂贵的 Windows 真机集群,通过标准的基于 Linux 的数据中心代理路由流量,也会导致目标服务器将您所有的流量都识别为 Linux。
这也是为什么住宅代理更适合做抓取的原因之一。
如何检查您的指纹
始终在真实环境下测试您的脚本。试着从反欺诈系统的角度来评估您的爬虫。
通过 BrowserLeaks 路由您爬虫的流量,并向下滚动到 TCP/IP 指纹部分。如果您的 Puppeteer 配置使用 Windows User-Agent,但该服务却报告 OS Fingerprint: Linux/Android,那么您面临的正是本文所讨论的不匹配问题。
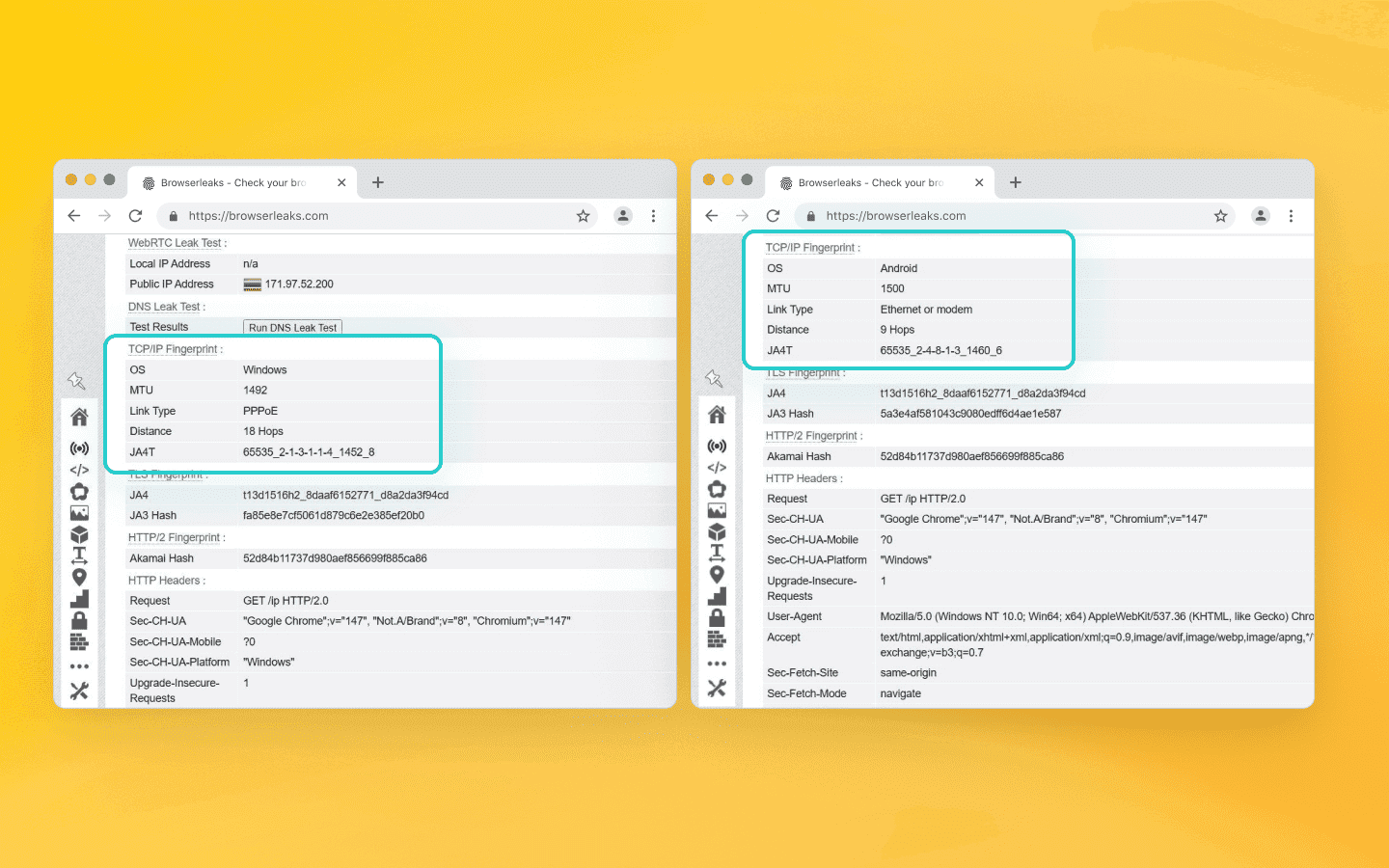
可行的解决方案:如何伪装 Linux
那么,如何才能让您的爬虫通过严格的反欺诈保护呢?
选择 1. 更改代理类型
既然数据中心代理凭借其 Linux 内核会破坏您的指纹,那么最可靠的解决方案就是停止使用它们,改为使用住宅代理。
住宅代理通过真实的用户设备(运行 Windows 或 macOS 的家用电脑、家用路由器)路由流量。与 Google 服务器建立 TCP 连接的端点不再是数据中心里的 Linux 服务器,而是一台真实的电脑。
当流量通过这些设备时,目标服务器会看到一个来自真实消费级设备、且与您的 L7 层指纹完美契合的合法 TCP 指纹。不匹配的问题随之迎刃而解。
如果您购买的是移动代理(通过真实 4G 智能手机集群运行),端点就会变成 Android 或 iOS 设备。Android 是基于 Linux 内核的。如果您通过移动代理运行带有 Windows 11 User-Agent 的桌面端爬虫,反欺诈系统就会接收到来自 Android 的数据包,并检测到这一不一致性。
您在反检测浏览器中的 L7 配置文件类型必须与代理端点类型严格一致。使用移动代理时,请启用移动端 Chrome 模拟;使用住宅代理时,请寻找提供桌面端 Windows IP 的代理池。
选择 2. 优化 Linux 内核
如果您直接从 Linux 服务器运行脚本,不使用任何代理(或者运行您可以完全控制的自有代理),您就需要伪装操作系统的网络栈。
第 1 阶段:基础调整 (TTL)
您可以通过单一的 iptables 命令来修改默认 TTL,使其与 Windows 一致。内核会在数据包发送前立即重写其 TTL 值:
iptables -t mangle -A POSTROUTING -j TTL --ttl-set 128
第 2 阶段:深度修改(窗口大小和 TCP 选项)
伪造初始窗口大小和 TCP 选项顺序要困难得多。基本的 sysctl 设置并不能解决问题,因为数据包结构是硬编码在 Linux 内核源码中的。
要在 TCP 选项级别将 Linux 伪装成 Windows,您可以使用 NFQueue 机制。其工作原理如下:
发出数据包被内核拦截,并转发给用户空间。
一个特殊的实用程序(利用
Scapy库基于 C 或 Python 编写)会捕获它们。该程序会解析 TCP 报头,将窗口大小修改为 65535 或 64240,将选项(
MSS、NOP、Window Scale等)重新排列为所需的顺序,重新计算校验和,然后将数据包返回给内核发送出去。
有一些现成的工具(如 p0f-obfuscator 以及来自 DPI-evasion 项目的模块)可以实现这些即时修改。这种设置较为复杂,并且可能会降低网络性能,但它能让您的 Linux 服务器在被动指纹技术面前隐形。
选择 3. 迁移至 Windows 基础设施
最简单的办法根本用不着去隐藏 Linux,而是直接在 Windows Server 上运行您的整个抓取基础设施。
您可以将代码迁移到 Windows 机器上直接发送流量。在这样的情况下,Microsoft 原生的网络栈便会生成天然的数据包,其中带有:
TTL 128,
合适的窗口大小,
以及标准的 Windows TCP 选项顺序。
然而,这种做法也有弊端:
成本。 租用 Windows 服务器总是更为昂贵。
资源消耗。 操作系统本身会为后台进程消耗大量的内存和 CPU 资源。
可扩展性。 在 Windows 上部署、更新和扩展一整套爬虫集群,难度要远高于在 Ubuntu 上启动几十个轻量级的 Docker 容器。
总结
仅仅伪造 User-Agent、Canvas、WebGL 和 navigator.platform 已经不足以保证成功,尤其是在面对 Google、Cloudflare、Akamai 或 DataDome 等具有强力保护的平台时。现代反欺诈系统不仅学会了分析您发送的数据,还学会了分析您在底层网络上是如何传输这些数据的。
如果您遇到了抓取问题且无法确定原因,那么是时候去检查 OSI 模型各层之间的一致性了。如果您的应用层与传输层和网络层(L3/L4)在逻辑或数学层面上无法匹配,问题可能就出在这里。
如果您精心配置的方案(配备了优质反检测浏览器和昂贵的代理)开始出现不明原因的 403 错误、返回简化版页面或频繁触发 CAPTCHA 验证码,请停止无休止地修改 JavaScript 指纹。试着往更深的一层看看。
保持匿名,充分利用多账户功能,借助市面上最优质的反检测浏览器实现您的目标。
您想以折扣价格尝试 Octo 浏览器吗?
使用促销代码 OCTOSCRAPER 获得任何订阅 30% 的折扣。此优惠仅适用于新用户。
为什么即使是完美的反检测浏览器也依然不够
为了理解问题的真实规模,让我们首先回顾一下标准的防封锁设置是如何工作的。
从历史上看,抓取是一场在 HTTP 和 JavaScript 层面展开的军备竞赛。当服务器开始封锁 python-requests 等默认请求头时,开发人员开始使用真实浏览器的 User-Agent 字符串。当反欺诈系统开始检查 navigator 属性时,我们转向了通过 Chrome DevTools Protocol (CDP) 修改的无头浏览器或现成的反检测解决方案。
我们已经习惯于控制 应用层(第 7 层)。这是 HTTP 运行、传输 cookie 和请求头以及执行 JavaScript 的层级。
问题在于,HTTP 请求并不是独立发送的。它被封装在传输协议(TCP——第 4 层)中,进而又被封装在网络协议(IP——第 3 层)中。这就是主要的架构陷阱所在:
L7(应用层)完全由您的应用程序控制——包括您的脚本、Puppeteer 或反检测浏览器。
L3 和 L4(网络和传输层)由物理运行代码(或流量通过的)操作系统内核控制。套接字
connect()调用只是将控制权交给了 Linux 或 Windows 网络栈,之后操作系统便根据其内部硬编码的规则构建数据包。
现代反欺诈系统深谙此道,并使用被动指纹技术,在发送第一个 HTTP 请求之前,分析 TCP 连接是如何建立的。
如果您的 L7 层 User-Agent 声称是 Windows 上的 Chrome,但服务器在 L4 层看到了 Linux 特有的 TCP SYN 数据包结构,反欺诈系统就会认为这是一个明显的异常。从服务器的角度来看,一台真实的 Windows 机器在物理上是不可能生成这样的网络数据包的。因此,这是一个伪装成普通用户的运行在 Linux 服务器上的机器人。接着反欺诈系统会根据其自身的策略做出反应:例如,Google Maps 可能会返回一个简化版页面、要求进行身份验证,并向您弹出 CAPTCHA 验证码。
TCP SYN 数据包的解剖:服务器如何识别您的真实操作系统
每个 HTTP(S) 连接都始于建立 TCP 连接——即所谓的三次握手。发送到目标资源的首个数据包是一个设置了 SYN 标志的网络数据包。这个微小的数据包包含了进行被动操作系统指纹识别所需的一切信息。安全系统甚至不需要等待您的 HTTP 请求头,它们通过检查 SYN 数据包内的服务字段,就能极其准确地确定是哪个操作系统内核创建了它。
主要有三个标记:
1. 生存时间 (TTL)
TTL 是一个计数器,数据包在前往服务器的途中每经过一个路由器,该值就会减 1。不同的操作系统使用不同的默认起始值:
Linux 和 macOS:默认 TTL 为 64。
Windows:默认 TTL 为 128。
如果 Google 的反欺诈系统收到一个 TTL 为 54 的数据包,便可以自信地断定源头是 Linux 或 macOS。如果收到的值是 115,那极有可能是 Windows。
2. TCP 窗口大小 (TCP Window Size)
这基本上就是接收缓冲区的大小。它表示一台设备一次准备接受多少数据。
由于数据是以大约 1460 字节的碎片形式传输的,操作系统通常会以该大小的倍数分配内存。然而,每个操作系统的分配机制不尽相同。
Linux 通常根据固定数量的数据包来分配初始窗口:
5840 = 4 个数据包 × 1460
14600 = 10 个数据包 × 1460
29200 = 20 个数据包 × 1460
当反欺诈系统看到 29200 时,它们能识别出这是 Linux 内核的典型特征。
Windows 则倾向于使用 2 的幂或最大值:
8192 = 8 KB
65535 = 能够装入 16 位窗口大小字段的最大值
64240 = 现代 Windows 版本使用的一种混合方法(44 个数据包 × 1460)
反欺诈系统会将这些值与您的 User-Agent 进行对比。如果您声称是 Windows 上的 Chrome,但您的窗口大小是 29200,这种不匹配就显而易见了。
3. TCP 选项顺序 (TCP Options order)
这是最强大的指纹识别机制。
SYN 数据包包含一些附加参数,如 MSS、Window Scaling、SACK Permitted、Timestamps 等。尽管这些值本身可能有所不同,但它们出现的顺序是硬编码在操作系统内核中的。
例如:
典型的 Windows 指纹:
MSS → NOP → Window Scaling → NOP → NOP → SACK Permitted
典型的 Linux 指纹:
MSS → SACK Permitted → Timestamps → NOP → Window Scaling
这些细节看似微不足道,但任何先进的反欺诈系统都会识别出这些不一致,从而限制会话并阻止稳定的抓取。
数据中心代理陷阱:为什么您的本地操作系统不再重要
如果 TCP/IP 指纹是个问题,那么一个显而易见的解决方案似乎是在 Windows Server 上运行爬虫。
假设您在一个干净的 Windows 机器上启动爬虫。操作系统会生成具有 TTL=128、合适窗口大小以及正确选项顺序的 TCP SYN 数据包。然而,CAPTCHA 验证码和会话中断依然会出现。原因在于代理服务器的工作方式。
严肃的抓取业务几乎总是依赖代理。在大多数自动化设置中,由于数据中心代理价格便宜、速度快且稳定,往往会被优先采用。但问题是,这些代理服务器绝大多数运行的是 Linux 发行版,如 Ubuntu、Debian 或 CentOS。
当您使用代理时,您的设备与 Google 的服务器之间并没有直接的网络连接。整个过程被分割为两个独立的连接:
连接 A(您的电脑 → 代理服务器)
您的 Windows 机器与代理建立 TCP 连接。
连接 B(代理服务器 → Google)
在收到您的请求后,代理会代表您向目标服务器创建一条全新的 TCP 连接。
由于代理服务器运行的是 Linux,因此发送给 Google 的 SYN 数据包实际上是由 Linux 网络栈生成的。
结果,Google 的反欺诈系统看到的是一个明显由 Linux 创建的 TCP 连接(TTL 64、Linux 样式的窗口大小、Linux 系统的 TCP 选项顺序)。然而,在该连接内部(L7 层),它看到的 HTTP 请求头却声称自己是 Windows 上的 Chrome。
数据中心代理会暴露您的本地传输层指纹。即使您运行着昂贵的 Windows 真机集群,通过标准的基于 Linux 的数据中心代理路由流量,也会导致目标服务器将您所有的流量都识别为 Linux。
这也是为什么住宅代理更适合做抓取的原因之一。
如何检查您的指纹
始终在真实环境下测试您的脚本。试着从反欺诈系统的角度来评估您的爬虫。
通过 BrowserLeaks 路由您爬虫的流量,并向下滚动到 TCP/IP 指纹部分。如果您的 Puppeteer 配置使用 Windows User-Agent,但该服务却报告 OS Fingerprint: Linux/Android,那么您面临的正是本文所讨论的不匹配问题。
可行的解决方案:如何伪装 Linux
那么,如何才能让您的爬虫通过严格的反欺诈保护呢?
选择 1. 更改代理类型
既然数据中心代理凭借其 Linux 内核会破坏您的指纹,那么最可靠的解决方案就是停止使用它们,改为使用住宅代理。
住宅代理通过真实的用户设备(运行 Windows 或 macOS 的家用电脑、家用路由器)路由流量。与 Google 服务器建立 TCP 连接的端点不再是数据中心里的 Linux 服务器,而是一台真实的电脑。
当流量通过这些设备时,目标服务器会看到一个来自真实消费级设备、且与您的 L7 层指纹完美契合的合法 TCP 指纹。不匹配的问题随之迎刃而解。
如果您购买的是移动代理(通过真实 4G 智能手机集群运行),端点就会变成 Android 或 iOS 设备。Android 是基于 Linux 内核的。如果您通过移动代理运行带有 Windows 11 User-Agent 的桌面端爬虫,反欺诈系统就会接收到来自 Android 的数据包,并检测到这一不一致性。
您在反检测浏览器中的 L7 配置文件类型必须与代理端点类型严格一致。使用移动代理时,请启用移动端 Chrome 模拟;使用住宅代理时,请寻找提供桌面端 Windows IP 的代理池。
选择 2. 优化 Linux 内核
如果您直接从 Linux 服务器运行脚本,不使用任何代理(或者运行您可以完全控制的自有代理),您就需要伪装操作系统的网络栈。
第 1 阶段:基础调整 (TTL)
您可以通过单一的 iptables 命令来修改默认 TTL,使其与 Windows 一致。内核会在数据包发送前立即重写其 TTL 值:
iptables -t mangle -A POSTROUTING -j TTL --ttl-set 128
第 2 阶段:深度修改(窗口大小和 TCP 选项)
伪造初始窗口大小和 TCP 选项顺序要困难得多。基本的 sysctl 设置并不能解决问题,因为数据包结构是硬编码在 Linux 内核源码中的。
要在 TCP 选项级别将 Linux 伪装成 Windows,您可以使用 NFQueue 机制。其工作原理如下:
发出数据包被内核拦截,并转发给用户空间。
一个特殊的实用程序(利用
Scapy库基于 C 或 Python 编写)会捕获它们。该程序会解析 TCP 报头,将窗口大小修改为 65535 或 64240,将选项(
MSS、NOP、Window Scale等)重新排列为所需的顺序,重新计算校验和,然后将数据包返回给内核发送出去。
有一些现成的工具(如 p0f-obfuscator 以及来自 DPI-evasion 项目的模块)可以实现这些即时修改。这种设置较为复杂,并且可能会降低网络性能,但它能让您的 Linux 服务器在被动指纹技术面前隐形。
选择 3. 迁移至 Windows 基础设施
最简单的办法根本用不着去隐藏 Linux,而是直接在 Windows Server 上运行您的整个抓取基础设施。
您可以将代码迁移到 Windows 机器上直接发送流量。在这样的情况下,Microsoft 原生的网络栈便会生成天然的数据包,其中带有:
TTL 128,
合适的窗口大小,
以及标准的 Windows TCP 选项顺序。
然而,这种做法也有弊端:
成本。 租用 Windows 服务器总是更为昂贵。
资源消耗。 操作系统本身会为后台进程消耗大量的内存和 CPU 资源。
可扩展性。 在 Windows 上部署、更新和扩展一整套爬虫集群,难度要远高于在 Ubuntu 上启动几十个轻量级的 Docker 容器。
总结
仅仅伪造 User-Agent、Canvas、WebGL 和 navigator.platform 已经不足以保证成功,尤其是在面对 Google、Cloudflare、Akamai 或 DataDome 等具有强力保护的平台时。现代反欺诈系统不仅学会了分析您发送的数据,还学会了分析您在底层网络上是如何传输这些数据的。
如果您遇到了抓取问题且无法确定原因,那么是时候去检查 OSI 模型各层之间的一致性了。如果您的应用层与传输层和网络层(L3/L4)在逻辑或数学层面上无法匹配,问题可能就出在这里。
如果您精心配置的方案(配备了优质反检测浏览器和昂贵的代理)开始出现不明原因的 403 错误、返回简化版页面或频繁触发 CAPTCHA 验证码,请停止无休止地修改 JavaScript 指纹。试着往更深的一层看看。
随时获取最新的Octo Browser新闻
通过点击按钮,您同意我们的 隐私政策。
随时获取最新的Octo Browser新闻
通过点击按钮,您同意我们的 隐私政策。
随时获取最新的Octo Browser新闻
通过点击按钮,您同意我们的 隐私政策。
