如何绕过ChatGPT限制
2026/3/25


Nikolai Izoitko
Content Manager, Octo Browser
ChatGPT 已成为工作、学习和创造力的首选解决方案。然而,许多活跃用户经常遇到限制:服务报告消息限制已达,并建议等待或切换到另一个模型。
这些限制在工作时尤其令人困扰。这就是为什么用户寻找方法来延长他们访问 ChatGPT 的时间,绕过这些限制,或至少减少它们的影响。
在本文中,我们讨论了 2026 年 ChatGPT 存在的限制,为什么会存在这些限制,以及可以使用什么方法来绕过它们。
内容
同时管理多个广告账户并测试广告设置,无需执行不必要的重复操作。避免被封禁,实现营收增长。
ChatGPT 限制
ChatGPT 的限制取决于订阅、所选模型和当前系统负载。重要的是要理解,大多数限制不是固定的,可能会发生变化。
1. 消息限制(速率限制)
免费用户可以在几个小时内向更强大的模型发送有限数量的消息。在此之后,访问要么被暂时限制,要么用户被要求切换到较轻的模型。
付费订阅提供更高的限制,但仍然有限制:几个小时内数十或数百条消息。
2. 模型限制
更高级的模型(特别是那些具有增强推理能力的模型)比轻量级版本有更严格的限制。轻量级模型通常在只有最低限度限制的情况下可用。
3. 工具限制
图像生成、文件处理和其他功能有单独的配额,这些配额不直接与文本消息相关联。
4. 上下文限制(令牌)
每个模型都有一个最大上下文长度,通常达到数十万个令牌。当超过此限制时,较早的消息会被截断或发生错误。
为什么存在 ChatGPT 限制
ChatGPT 的限制不是随意的,因为它们是服务架构的一部分。它们对于 ChatGPT 的稳定运行是必要的,并且由几个因素驱动。
1. 计算约束
现代的大型语言模型需要大量的计算资源。即使是单次请求也可能涉及复杂的基础设施(GPU/TPU,分布式系统)。没有限制,这将导致服务器过载并增加延迟。
2. 负载均衡
限制有助于在用户之间均匀分配资源。没有它们,最活跃的用户或自动化系统可能会消耗不成比例的计算能力。
3. 经济模式
ChatGPT 采用免费增值模式:基本访问受限,而付费订阅提供更高的限制和优先访问。
4. 安全
速率限制有助于防止自动化攻击、大规模生成有害内容和API滥用。
5. 附加因素
在某些情况下,间接因素(如能源消耗和基础设施效率)也会被考虑。
绕过 ChatGPT 限制的方法
不可能完全绕过 ChatGPT 的限制。即使是付费订阅也包括对请求频率和访问更强大模型的限制。然而,在实践中,有几种有效的方法可以暂时绕过限制或显著减少其影响,使您可以继续工作而不会长时间暂停。
Telegram 机器人和应用程序
用户在达到限制后最明显的选择是第三方服务。包括 Telegram 机器人以及独立的 AI 平台,如 Poe、Perplexity、Grok 和 You.com。
然而,务实是重要的。全功能平台如 Poe 或 Perplexity 稳定并提供对多个模型的访问,有时具有更灵活的限制或自己的配额系统。这是一种合法和可持续的继续工作的方法,只是不能在 ChatGPT 自身内完成。
然而,Telegram 机器人则要不可预测得多。大多数通过 API 或代理操作,经常使用共享的请求池,可能会随时限制用户。此外,声称提供对顶级模型或“思考”模式的访问往往是不可靠的,因为用户通常无法验证正在使用哪个模型。
另一个需要考虑的重要方面是数据安全性。通过机器人,您几乎总是通过第三方基础设施发送请求,这可能会记录或分析您的输入。对于敏感任务,这是一个严重的风险。
因此,当您急需在达到限制后继续对话时,这些服务可以提供帮助。但是,作为主要工作流程,它们是不稳定且难以控制的。
免费试用
另一种方法是使用集成大型语言模型的服务的试用期。在这种情况下,您并不是直接绕开限制,而是暂时获得对另一个系统的访问,其自身也有其限制。
例如,Cursor 定期提供其 AI 功能的试用访问,并广泛被开发人员使用。Replit 提供内置的 AI 助手,并有限制,Codeium 和 Tabnine 是处理代码的替代工具。
技术上,这不是取消 ChatGPT 的限制,而是切换到具有免费试用或对新用户更好条件的另一个服务。最终,限制会回归,要么是限额,要么是需要支付费用。
不过,作为一种临时策略,这种方法效果不错,特别是如果任务分布在不同的解决方案上:文本生成、代码编写、搜索和分析。
Octo Browser
请记住,ChatGPT 的限制与账户有关,而不是设备。一个账户意味着一套限制。多个账户意味着合并的限制。Octo Browser,一个用于多账户操作的反检测浏览器,通过为每个账户创建单独的浏览器配置文件并为每个配置文件创建真实的数字指纹,让您管理这些账户。
这解决了核心问题:如果账户看起来像独立用户,系统不会将它们链接在一起。因此,您可以在并行会话中工作并分配负载。
如何使用 Octo Browser 绕过 ChatGPT 限制:
为每个 OpenAI 账户创建一个单独的 Octo Browser 配置文件。
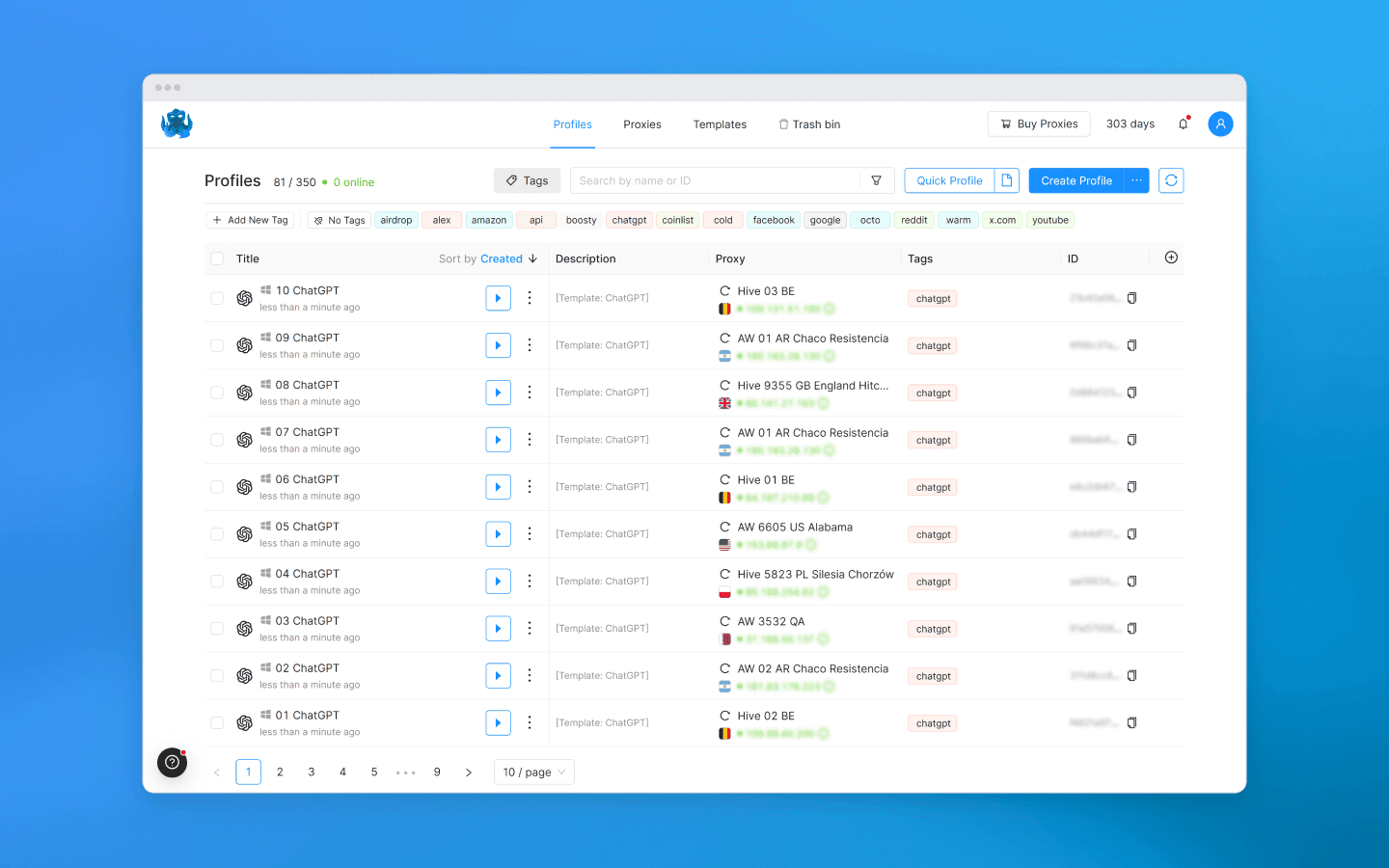
每个配置文件获得自己的数字指纹:不同的 Canvas、WebGL、字体、User-Agent、地理位置、时区、WebRTC 等等。如果您不确定选择什么,可以保留默认设置。
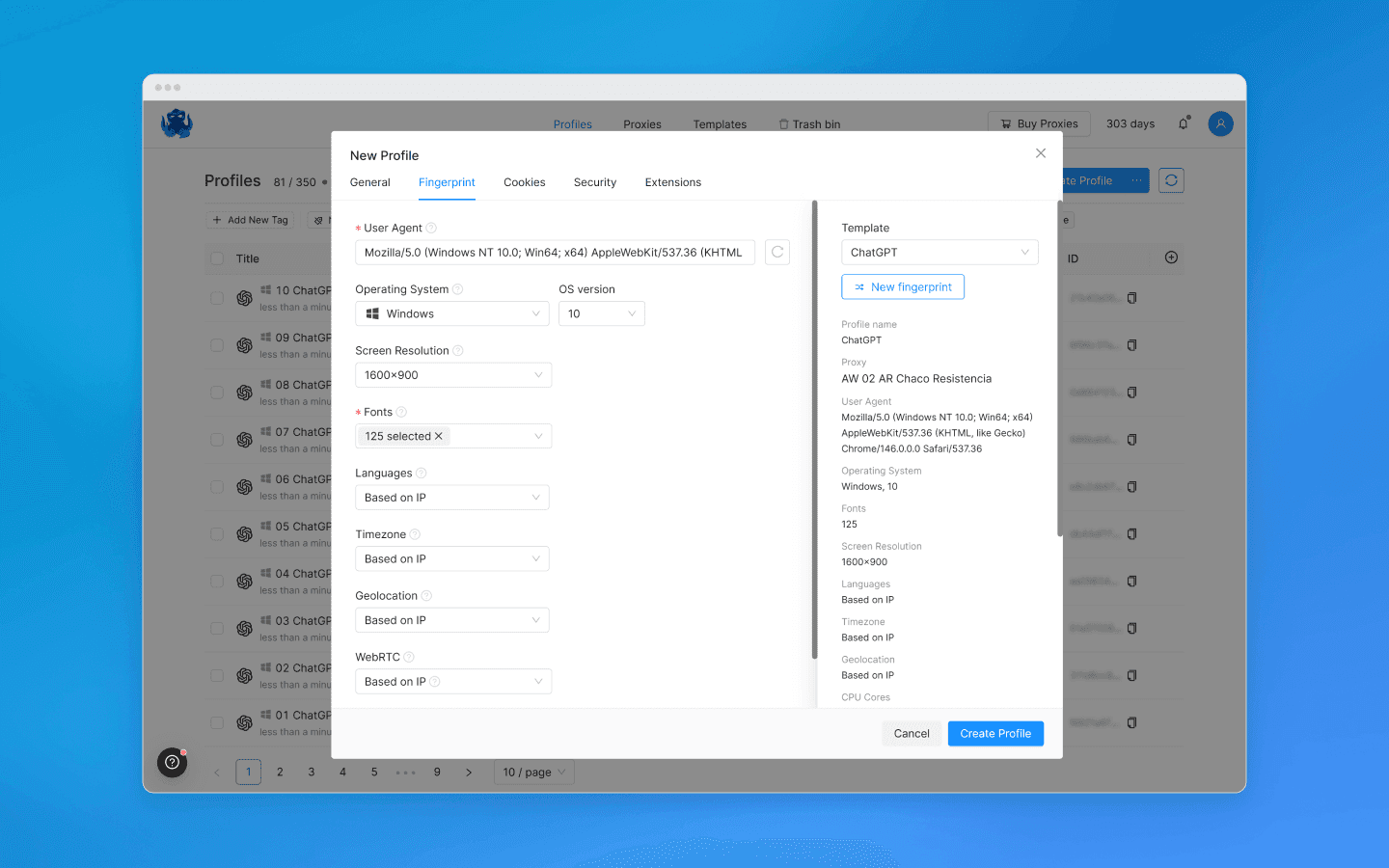
为每个配置文件分配不同的代理。
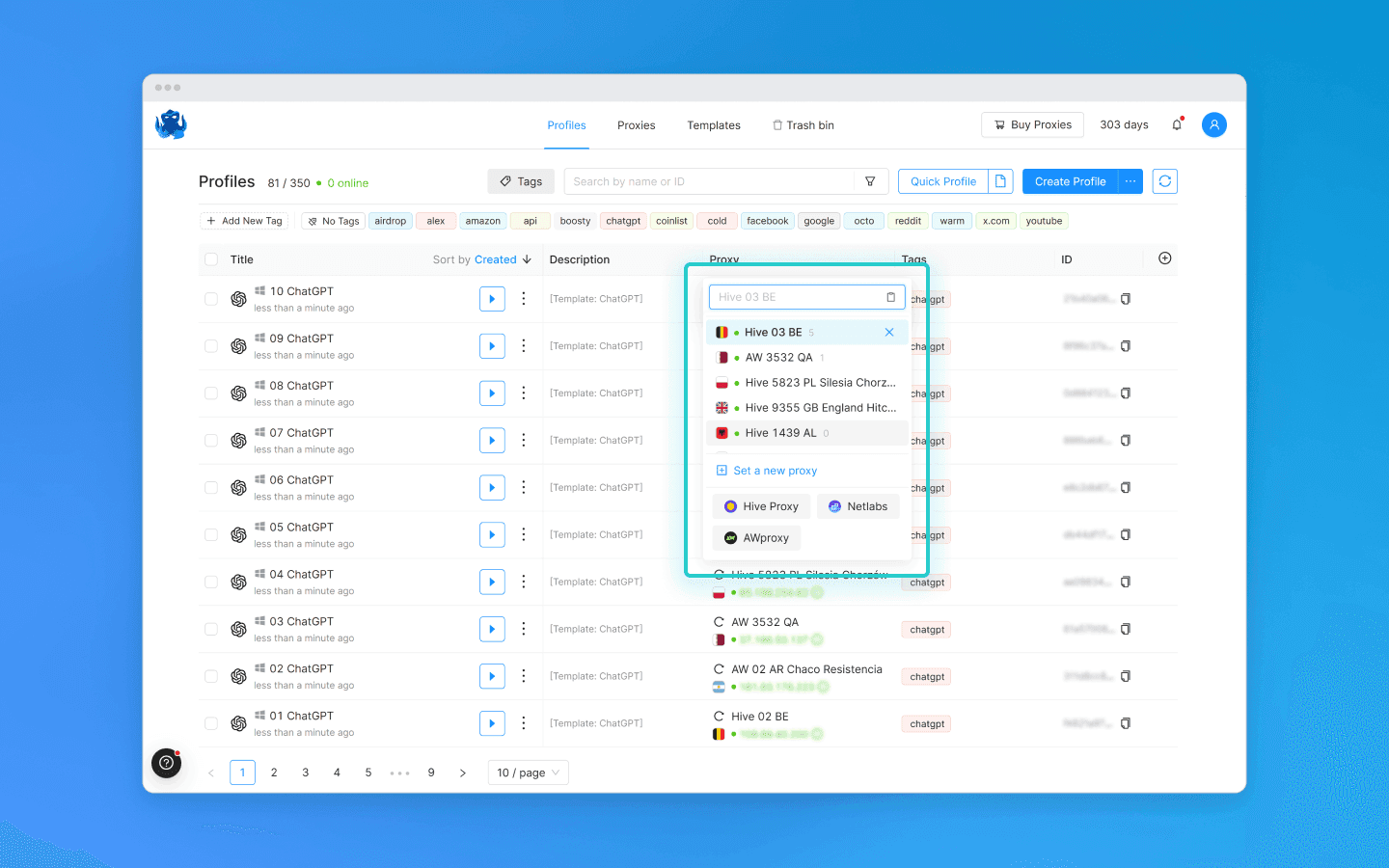
注册、购买或租用多个 ChatGPT 账户。
根据需要切换配置文件。ChatGPT 的限制是针对每个账户单独计算的。
请记住:激进的行为(大量注册、相同操作、可疑活动)仍然有被封禁的风险。
管理会话和令牌的提示
即使在单个账户内,通过更聪明地使用聊天和请求,您也可以显著提高效率。这些方法不会直接绕过 ChatGPT 的限制,但有助于减少不必要的消息。
尽可能重用上下文
继续相同的对话意味着您不需要重新输入说明、风格或数据。ChatGPT 只考虑当前上下文(根据模型不同可达数十万令牌),因此,更长的结构化聊天有助于减少冗余消息。
除非严格必要,不要在相同主题上开始新的聊天。
给聊天设置清晰的名称以便更容易导航。
仅在需要时将长对话拆分为逻辑模块。
清除上下文以管理性能
很长的聊天可能会降低回答质量并使工作变得更加困难。要避免这种情况:
使用内置功能来清除或分支聊天。
对于完全不同的主题,启动一个新的聊天,携带仅有的关键指示。
监控上下文大小以避免超载模型。
重要:清除上下文不会重置消息限制,它只是帮助管理回答质量。
将大型请求分成几个小的请求
非常大的提示通常会导致错误和不必要的澄清。最好将任务拆分为步骤:
计划;
写作单个部分;
审核和完善。
这种方法可以帮助您更快地获得更好的结果,同时保持在 ChatGPT 消息限制之内。
提示优化方法
良好的提示是保持在 ChatGPT 限制范围内的主要方式。清晰而完整的请求第一次尝试就可产生准确的答案,无需不必要的后续操作。
例如,如果您需要分析和调试 Python 代码,一种限额常常会迅速耗尽的任务,请使用以下方法:
1. 分配角色给模型
清楚地定义模型的角色。这有助于产生专家级别的答案并减少后续问题。
示例:“您是一名具有 12 年经验的高级 Python 开发人员。编写干净、惯用的代码并逐行解释更改。”
这种方法将提示转化为一组紧凑的模型指示,减少了重复纠正的需要。
2. 提供完整的上下文
不要在一条消息中发送一半的信息,然后再补充说明。如果您正在处理代码,请提前提供所有相关数据:
代码、识别的错误、编程语言及其版本,以及代码应实现的任务;
示例数据或期望的输出格式。
示例:与其说“这段代码为什么不起作用?”— 要立即提供代码、错误、Python 版本和预期结果。
3. 将任务分成步骤
采用迭代方法,让模型逐步处理每一阶段,同时您可以监控结果并及早修复问题。
示例:
分析 Python 代码并识别潜在错误或漏洞。
修复问题并建议功能优化。
添加测试用例以验证修正的代码。
这样,您可以控制过程,减少错误解决的风险,节省消息,因为每个后续都与特定步骤相关联。
4. 指定准确的输出格式
如果您需要结构化的响应,请提前定义格式,因为这可以减少修订和说明的数量。
示例:“将响应分为四个部分:问题分析、建议更改、修正后的代码和测试用例。”
5. 使用示例
向模型展示您期望得到的结果。这在处理代码、表格或格式时特别有用。
示例:
之前:
response.json()
response.json()
之后:
response.raise_for_status() data = response.json()
response.raise_for_status() data = response.json()
原因:raise_for_status() 在 HTTP 错误时引发异常,而 response.json() 仅在请求成功时返回数据。
6. 剪切不必要的措辞
提示越简单和准确,它使用的令牌和消息就越少。
示例:
不好:“请帮助我解决代码,它不起作用,我不明白为什么,现在帮助我。”
好:“分析并修复以下代码。错误:空响应上的 JSONDecodeError。添加网络和 HTTP 错误处理。”
7. 使用分隔符分块
如果您的提示包含多个部分,像 ### 这样的分隔符有助于模型区分指令,提高准确性并节省消息。
使用 API 管理限制
OpenAI API 是无需受 Web 界面限制即可使用 ChatGPT 的最灵活方式。通过 API,您可以直接访问模型(gpt-5.3、gpt-5.4、思考模式),管理自己的配额和令牌。
1. 获取您的 API 密钥和设置
要使用 API:
前往platform.openai.com并登录。
在左侧菜单中打开 API 密钥部分。
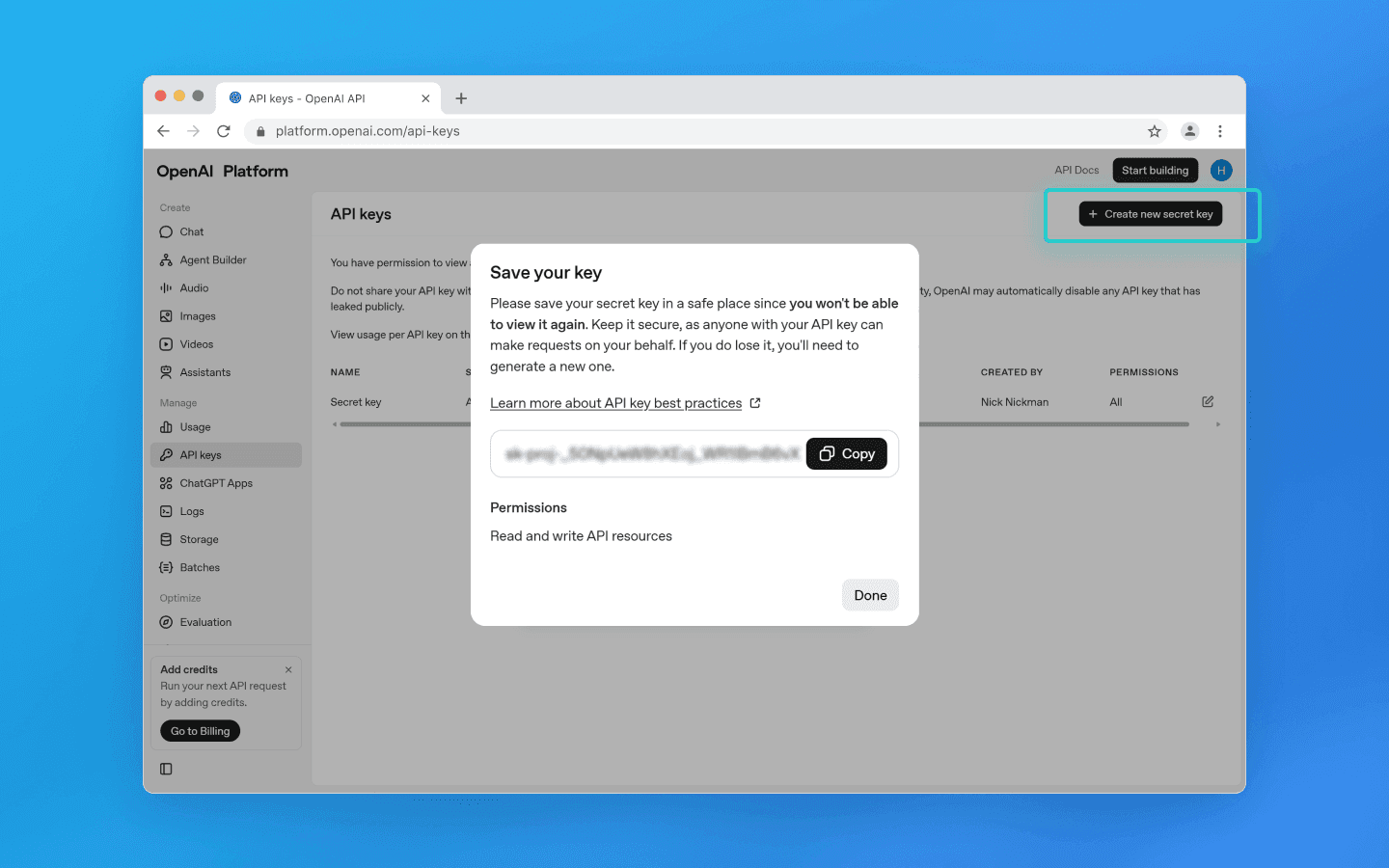
点击创建新的秘密密钥。
在弹出窗口中,如有必要输入项目名称,设定权限,然后点击创建新的秘密密钥。
复制该密钥并妥善保管,因为它提供了对您 API 账户的完整访问权限。
重要:API 密钥不与 ChatGPT Web 限制相关联。这些限制只取决于您的 API 配额。
2. API 配额和限制
OpenAI 使用一个与您的账户和账单相关的配额系统:
Tier 0(新账户):小型配额,例如每分钟 500-1,000 个请求,轻量级模型每分钟 10k 个令牌。
Tier 1+(消费超过 $5 后):每分钟成千上万的请求(RPM)和每分钟数十万个令牌(TPM)。
Tier 5(企业版):接近无限的配额,通过协议制定自定义限制。
只要没有违规行为,配额会随着稳定的支付自动增加。
与 Web 界面的区别:API 限制不是基于聊天消息,而是基于 RPM/TPM。
3. 高效使用 API
为了节省配额并提高稳定性,请使用以下最佳实践:
合理的参数:
temperature— 代码精确为 0.2-0.5,创造性任务为 0.7-1.0。max_tokens— 限制响应长度以避免不必要的令牌使用。top_p— 通常为 0.9-1.0。
缓存响应:本地存储重复的提示(文件、Redis)以避免重复发送。
批量请求:在一次请求中发送多个提示以节省时间和令牌。
使用轻量级模型进行草稿:使用
gpt-4o-mini或gpt-5.3-instant完成草稿,然后用顶级模型进行完善。流模式:
stream=true让您可以分块接收响应,节省在会话中断时的令牌。简洁的系统提示:更短的角色和核心指示可减少每次请求中的令牌使用。
4. Python 示例
调用 ChatGPT API 的简单方式:
import requests api_key = "sk-..." url = "https://api.openai.com/v1/chat/completions" headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "gpt-5.3", "messages": [ {"role": "system", "content": "You are a senior Python developer. Write clean, idiomatic code."}, {"role": "user", "content": "Please review this code and fix any errors: ..."} ], "temperature": 0.3, "max_tokens": 800 } response = requests.post(url, headers=headers, json=data) print(response.json())
import requests api_key = "sk-..." url = "https://api.openai.com/v1/chat/completions" headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "gpt-5.3", "messages": [ {"role": "system", "content": "You are a senior Python developer. Write clean, idiomatic code."}, {"role": "user", "content": "Please review this code and fix any errors: ..."} ], "temperature": 0.3, "max_tokens": 800 } response = requests.post(url, headers=headers, json=data) print(response.json())
处理速率限制的策略
ChatGPT 中的速率限制是对您在一定时间内可以发送的消息数量的限制。它通过滚动窗口原则操作。
滚动窗口原则意味着什么:
而不是在固定时间点重置(例如,正好在 3:00),系统根据每个消息发送的时间跟踪时间窗口。
示例:如果您的 Plus 计划允许在 3 小时内发送 160 条消息,并且您在 10:00 发送第一条消息,它将只在 13:00 停止计入限制。对每条消息都是如此——窗口根据发送时间连续滑动。
这意味着限制逐渐恢复,而不是一次性恢复。
为了高效管理您的速率限制,请遵循以下准则:
1. 对于简单任务使用轻量级模型
迷你或即时版本有单独的限制,适用于快速检查、草稿或简单的澄清。
2. 注意 ChatGPT 的通知
Web 界在您接近限制时显示警告。
3. 将大任务分块
不要用一条长提示,分成多条信息并给予明确指令。这有助于节省配额、改善控制,并提高回答质量。
结论
2026 年的 ChatGPT 限制不是一个暂时的问题,而是使用服务的永久部分。对于用户来说,它们常常成为瓶颈:工作停止,截止日期拖延,您不得不等待限制重置。
在本文中,我们介绍了当前的限制,背后(技术、经济和安全相关的)原因,以及实际减少其影响的方法。最有效的方法是综合使用:使用反检测浏览器创建的多个 ChatGPT 账户,适当的提示优化和上下文管理,通过 API 进行的基于配额的使用,以及合理交替暂停和轻量级模型。
不可能在没有昂贵的专业订阅的情况下完全消除 ChatGPT 的限制,但一致且正确地应用这些策略可以让您工作得更长和更高效。
常见问题
ChatGPT 中的速率限制持续多长时间?
ChatGPT 使用滚动窗口原则。这意味着限制不会在固定时刻重置,而是对每条消息进行单独计算。经过 3-5 小时,特定消息不再计入当前窗口。
不同的 ChatGPT 模型有不同的限制吗?
是的。限制取决于您的订阅。在免费计划上,访问高级模型受到限制(通常在几个小时内约 10 条消息),之后系统可能会切换到轻量级(迷你)模型。付费计划(如 Plus)在相同的时间窗口内提供显著更高的配额。
API 限制可以更改吗?
是的,但不能手动更改。OpenAI API 限制通过配额(速率限制和消费限制)管理,随着使用和支付自动增加。稳定的账单和更高的使用会导致可用限制(RPM/TPM)增加。在某些情况下,大客户的限制可以通过支持增加。
如果我使用不同的浏览器,ChatGPT 的限制会重置吗?
不会。限制与您的账户相关联,而不是浏览器。使用不同的浏览器或标签不会改变消息计数。
ChatGPT 的限制是与账户还是设备相关联?
ChatGPT 的限制是与账户相关联的。设备、浏览器和 IP 地址不影响可用消息的数量。一个账户等于一个共享限制。
令牌限制和速率限制有什么区别?
这是不同的系统。令牌限制定义了一个请求或对话上下文中可以处理的文本量(输入和输出)。速率限制定义了您可以在一定时间内发送请求的频率。您可以在不达到另一个限制的情况下达到一个限制。
同时管理多个广告账户并测试广告设置,无需执行不必要的重复操作。避免被封禁,实现营收增长。
ChatGPT 限制
ChatGPT 的限制取决于订阅、所选模型和当前系统负载。重要的是要理解,大多数限制不是固定的,可能会发生变化。
1. 消息限制(速率限制)
免费用户可以在几个小时内向更强大的模型发送有限数量的消息。在此之后,访问要么被暂时限制,要么用户被要求切换到较轻的模型。
付费订阅提供更高的限制,但仍然有限制:几个小时内数十或数百条消息。
2. 模型限制
更高级的模型(特别是那些具有增强推理能力的模型)比轻量级版本有更严格的限制。轻量级模型通常在只有最低限度限制的情况下可用。
3. 工具限制
图像生成、文件处理和其他功能有单独的配额,这些配额不直接与文本消息相关联。
4. 上下文限制(令牌)
每个模型都有一个最大上下文长度,通常达到数十万个令牌。当超过此限制时,较早的消息会被截断或发生错误。
为什么存在 ChatGPT 限制
ChatGPT 的限制不是随意的,因为它们是服务架构的一部分。它们对于 ChatGPT 的稳定运行是必要的,并且由几个因素驱动。
1. 计算约束
现代的大型语言模型需要大量的计算资源。即使是单次请求也可能涉及复杂的基础设施(GPU/TPU,分布式系统)。没有限制,这将导致服务器过载并增加延迟。
2. 负载均衡
限制有助于在用户之间均匀分配资源。没有它们,最活跃的用户或自动化系统可能会消耗不成比例的计算能力。
3. 经济模式
ChatGPT 采用免费增值模式:基本访问受限,而付费订阅提供更高的限制和优先访问。
4. 安全
速率限制有助于防止自动化攻击、大规模生成有害内容和API滥用。
5. 附加因素
在某些情况下,间接因素(如能源消耗和基础设施效率)也会被考虑。
绕过 ChatGPT 限制的方法
不可能完全绕过 ChatGPT 的限制。即使是付费订阅也包括对请求频率和访问更强大模型的限制。然而,在实践中,有几种有效的方法可以暂时绕过限制或显著减少其影响,使您可以继续工作而不会长时间暂停。
Telegram 机器人和应用程序
用户在达到限制后最明显的选择是第三方服务。包括 Telegram 机器人以及独立的 AI 平台,如 Poe、Perplexity、Grok 和 You.com。
然而,务实是重要的。全功能平台如 Poe 或 Perplexity 稳定并提供对多个模型的访问,有时具有更灵活的限制或自己的配额系统。这是一种合法和可持续的继续工作的方法,只是不能在 ChatGPT 自身内完成。
然而,Telegram 机器人则要不可预测得多。大多数通过 API 或代理操作,经常使用共享的请求池,可能会随时限制用户。此外,声称提供对顶级模型或“思考”模式的访问往往是不可靠的,因为用户通常无法验证正在使用哪个模型。
另一个需要考虑的重要方面是数据安全性。通过机器人,您几乎总是通过第三方基础设施发送请求,这可能会记录或分析您的输入。对于敏感任务,这是一个严重的风险。
因此,当您急需在达到限制后继续对话时,这些服务可以提供帮助。但是,作为主要工作流程,它们是不稳定且难以控制的。
免费试用
另一种方法是使用集成大型语言模型的服务的试用期。在这种情况下,您并不是直接绕开限制,而是暂时获得对另一个系统的访问,其自身也有其限制。
例如,Cursor 定期提供其 AI 功能的试用访问,并广泛被开发人员使用。Replit 提供内置的 AI 助手,并有限制,Codeium 和 Tabnine 是处理代码的替代工具。
技术上,这不是取消 ChatGPT 的限制,而是切换到具有免费试用或对新用户更好条件的另一个服务。最终,限制会回归,要么是限额,要么是需要支付费用。
不过,作为一种临时策略,这种方法效果不错,特别是如果任务分布在不同的解决方案上:文本生成、代码编写、搜索和分析。
Octo Browser
请记住,ChatGPT 的限制与账户有关,而不是设备。一个账户意味着一套限制。多个账户意味着合并的限制。Octo Browser,一个用于多账户操作的反检测浏览器,通过为每个账户创建单独的浏览器配置文件并为每个配置文件创建真实的数字指纹,让您管理这些账户。
这解决了核心问题:如果账户看起来像独立用户,系统不会将它们链接在一起。因此,您可以在并行会话中工作并分配负载。
如何使用 Octo Browser 绕过 ChatGPT 限制:
为每个 OpenAI 账户创建一个单独的 Octo Browser 配置文件。
每个配置文件获得自己的数字指纹:不同的 Canvas、WebGL、字体、User-Agent、地理位置、时区、WebRTC 等等。如果您不确定选择什么,可以保留默认设置。
为每个配置文件分配不同的代理。
注册、购买或租用多个 ChatGPT 账户。
根据需要切换配置文件。ChatGPT 的限制是针对每个账户单独计算的。
请记住:激进的行为(大量注册、相同操作、可疑活动)仍然有被封禁的风险。
管理会话和令牌的提示
即使在单个账户内,通过更聪明地使用聊天和请求,您也可以显著提高效率。这些方法不会直接绕过 ChatGPT 的限制,但有助于减少不必要的消息。
尽可能重用上下文
继续相同的对话意味着您不需要重新输入说明、风格或数据。ChatGPT 只考虑当前上下文(根据模型不同可达数十万令牌),因此,更长的结构化聊天有助于减少冗余消息。
除非严格必要,不要在相同主题上开始新的聊天。
给聊天设置清晰的名称以便更容易导航。
仅在需要时将长对话拆分为逻辑模块。
清除上下文以管理性能
很长的聊天可能会降低回答质量并使工作变得更加困难。要避免这种情况:
使用内置功能来清除或分支聊天。
对于完全不同的主题,启动一个新的聊天,携带仅有的关键指示。
监控上下文大小以避免超载模型。
重要:清除上下文不会重置消息限制,它只是帮助管理回答质量。
将大型请求分成几个小的请求
非常大的提示通常会导致错误和不必要的澄清。最好将任务拆分为步骤:
计划;
写作单个部分;
审核和完善。
这种方法可以帮助您更快地获得更好的结果,同时保持在 ChatGPT 消息限制之内。
提示优化方法
良好的提示是保持在 ChatGPT 限制范围内的主要方式。清晰而完整的请求第一次尝试就可产生准确的答案,无需不必要的后续操作。
例如,如果您需要分析和调试 Python 代码,一种限额常常会迅速耗尽的任务,请使用以下方法:
1. 分配角色给模型
清楚地定义模型的角色。这有助于产生专家级别的答案并减少后续问题。
示例:“您是一名具有 12 年经验的高级 Python 开发人员。编写干净、惯用的代码并逐行解释更改。”
这种方法将提示转化为一组紧凑的模型指示,减少了重复纠正的需要。
2. 提供完整的上下文
不要在一条消息中发送一半的信息,然后再补充说明。如果您正在处理代码,请提前提供所有相关数据:
代码、识别的错误、编程语言及其版本,以及代码应实现的任务;
示例数据或期望的输出格式。
示例:与其说“这段代码为什么不起作用?”— 要立即提供代码、错误、Python 版本和预期结果。
3. 将任务分成步骤
采用迭代方法,让模型逐步处理每一阶段,同时您可以监控结果并及早修复问题。
示例:
分析 Python 代码并识别潜在错误或漏洞。
修复问题并建议功能优化。
添加测试用例以验证修正的代码。
这样,您可以控制过程,减少错误解决的风险,节省消息,因为每个后续都与特定步骤相关联。
4. 指定准确的输出格式
如果您需要结构化的响应,请提前定义格式,因为这可以减少修订和说明的数量。
示例:“将响应分为四个部分:问题分析、建议更改、修正后的代码和测试用例。”
5. 使用示例
向模型展示您期望得到的结果。这在处理代码、表格或格式时特别有用。
示例:
之前:
response.json()
之后:
response.raise_for_status() data = response.json()
原因:raise_for_status() 在 HTTP 错误时引发异常,而 response.json() 仅在请求成功时返回数据。
6. 剪切不必要的措辞
提示越简单和准确,它使用的令牌和消息就越少。
示例:
不好:“请帮助我解决代码,它不起作用,我不明白为什么,现在帮助我。”
好:“分析并修复以下代码。错误:空响应上的 JSONDecodeError。添加网络和 HTTP 错误处理。”
7. 使用分隔符分块
如果您的提示包含多个部分,像 ### 这样的分隔符有助于模型区分指令,提高准确性并节省消息。
使用 API 管理限制
OpenAI API 是无需受 Web 界面限制即可使用 ChatGPT 的最灵活方式。通过 API,您可以直接访问模型(gpt-5.3、gpt-5.4、思考模式),管理自己的配额和令牌。
1. 获取您的 API 密钥和设置
要使用 API:
前往platform.openai.com并登录。
在左侧菜单中打开 API 密钥部分。
点击创建新的秘密密钥。
在弹出窗口中,如有必要输入项目名称,设定权限,然后点击创建新的秘密密钥。
复制该密钥并妥善保管,因为它提供了对您 API 账户的完整访问权限。
重要:API 密钥不与 ChatGPT Web 限制相关联。这些限制只取决于您的 API 配额。
2. API 配额和限制
OpenAI 使用一个与您的账户和账单相关的配额系统:
Tier 0(新账户):小型配额,例如每分钟 500-1,000 个请求,轻量级模型每分钟 10k 个令牌。
Tier 1+(消费超过 $5 后):每分钟成千上万的请求(RPM)和每分钟数十万个令牌(TPM)。
Tier 5(企业版):接近无限的配额,通过协议制定自定义限制。
只要没有违规行为,配额会随着稳定的支付自动增加。
与 Web 界面的区别:API 限制不是基于聊天消息,而是基于 RPM/TPM。
3. 高效使用 API
为了节省配额并提高稳定性,请使用以下最佳实践:
合理的参数:
temperature— 代码精确为 0.2-0.5,创造性任务为 0.7-1.0。max_tokens— 限制响应长度以避免不必要的令牌使用。top_p— 通常为 0.9-1.0。
缓存响应:本地存储重复的提示(文件、Redis)以避免重复发送。
批量请求:在一次请求中发送多个提示以节省时间和令牌。
使用轻量级模型进行草稿:使用
gpt-4o-mini或gpt-5.3-instant完成草稿,然后用顶级模型进行完善。流模式:
stream=true让您可以分块接收响应,节省在会话中断时的令牌。简洁的系统提示:更短的角色和核心指示可减少每次请求中的令牌使用。
4. Python 示例
调用 ChatGPT API 的简单方式:
import requests api_key = "sk-..." url = "https://api.openai.com/v1/chat/completions" headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "gpt-5.3", "messages": [ {"role": "system", "content": "You are a senior Python developer. Write clean, idiomatic code."}, {"role": "user", "content": "Please review this code and fix any errors: ..."} ], "temperature": 0.3, "max_tokens": 800 } response = requests.post(url, headers=headers, json=data) print(response.json())
处理速率限制的策略
ChatGPT 中的速率限制是对您在一定时间内可以发送的消息数量的限制。它通过滚动窗口原则操作。
滚动窗口原则意味着什么:
而不是在固定时间点重置(例如,正好在 3:00),系统根据每个消息发送的时间跟踪时间窗口。
示例:如果您的 Plus 计划允许在 3 小时内发送 160 条消息,并且您在 10:00 发送第一条消息,它将只在 13:00 停止计入限制。对每条消息都是如此——窗口根据发送时间连续滑动。
这意味着限制逐渐恢复,而不是一次性恢复。
为了高效管理您的速率限制,请遵循以下准则:
1. 对于简单任务使用轻量级模型
迷你或即时版本有单独的限制,适用于快速检查、草稿或简单的澄清。
2. 注意 ChatGPT 的通知
Web 界在您接近限制时显示警告。
3. 将大任务分块
不要用一条长提示,分成多条信息并给予明确指令。这有助于节省配额、改善控制,并提高回答质量。
结论
2026 年的 ChatGPT 限制不是一个暂时的问题,而是使用服务的永久部分。对于用户来说,它们常常成为瓶颈:工作停止,截止日期拖延,您不得不等待限制重置。
在本文中,我们介绍了当前的限制,背后(技术、经济和安全相关的)原因,以及实际减少其影响的方法。最有效的方法是综合使用:使用反检测浏览器创建的多个 ChatGPT 账户,适当的提示优化和上下文管理,通过 API 进行的基于配额的使用,以及合理交替暂停和轻量级模型。
不可能在没有昂贵的专业订阅的情况下完全消除 ChatGPT 的限制,但一致且正确地应用这些策略可以让您工作得更长和更高效。
常见问题
ChatGPT 中的速率限制持续多长时间?
ChatGPT 使用滚动窗口原则。这意味着限制不会在固定时刻重置,而是对每条消息进行单独计算。经过 3-5 小时,特定消息不再计入当前窗口。
不同的 ChatGPT 模型有不同的限制吗?
是的。限制取决于您的订阅。在免费计划上,访问高级模型受到限制(通常在几个小时内约 10 条消息),之后系统可能会切换到轻量级(迷你)模型。付费计划(如 Plus)在相同的时间窗口内提供显著更高的配额。
API 限制可以更改吗?
是的,但不能手动更改。OpenAI API 限制通过配额(速率限制和消费限制)管理,随着使用和支付自动增加。稳定的账单和更高的使用会导致可用限制(RPM/TPM)增加。在某些情况下,大客户的限制可以通过支持增加。
如果我使用不同的浏览器,ChatGPT 的限制会重置吗?
不会。限制与您的账户相关联,而不是浏览器。使用不同的浏览器或标签不会改变消息计数。
ChatGPT 的限制是与账户还是设备相关联?
ChatGPT 的限制是与账户相关联的。设备、浏览器和 IP 地址不影响可用消息的数量。一个账户等于一个共享限制。
令牌限制和速率限制有什么区别?
这是不同的系统。令牌限制定义了一个请求或对话上下文中可以处理的文本量(输入和输出)。速率限制定义了您可以在一定时间内发送请求的频率。您可以在不达到另一个限制的情况下达到一个限制。
随时获取最新的Octo Browser新闻
通过点击按钮,您同意我们的 隐私政策。
随时获取最新的Octo Browser新闻
通过点击按钮,您同意我们的 隐私政策。
随时获取最新的Octo Browser新闻
通过点击按钮,您同意我们的 隐私政策。
