How Browser Fingerprinting Works: a Full Breakdown of Parameters


Markus_automation
Expert in data parsing and automation
Browser fingerprinting is a method of identifying a user by the combination of characteristics and parameters of their browser and device without using cookies or other stored data. When you visit a site, a special script collects information about your environment (operating system, browser version, language settings, timezone, screen resolution, list of fonts, etc.) and creates a unique identifier, the browser fingerprint. This identifier persists longer than ordinary cookies and helps sites recognize your browser on repeat visits, even if the user clears cookies or opens the site in incognito mode. Due to that, sites can track a user’s actions across different sessions and resources, linking them to one profile.
A browser fingerprint is similar to a human fingerprint, but uniqueness here is not exactly 100% and is roughly 85–90%, which is enough for sites to identify a profile. It’s important to understand that a fingerprint is a set of parameters. Changing one or two of them does not yield a significant spoofing effect: uniqueness drops by only fractions of a percent, so it’s important to work on the fingerprint comprehensively.

Let’s break down which parameters make up a browser fingerprint, how each parameter is collected, and how much it affects uniqueness.
Browser fingerprinting is a method of identifying a user by the combination of characteristics and parameters of their browser and device without using cookies or other stored data. When you visit a site, a special script collects information about your environment (operating system, browser version, language settings, timezone, screen resolution, list of fonts, etc.) and creates a unique identifier, the browser fingerprint. This identifier persists longer than ordinary cookies and helps sites recognize your browser on repeat visits, even if the user clears cookies or opens the site in incognito mode. Due to that, sites can track a user’s actions across different sessions and resources, linking them to one profile.
A browser fingerprint is similar to a human fingerprint, but uniqueness here is not exactly 100% and is roughly 85–90%, which is enough for sites to identify a profile. It’s important to understand that a fingerprint is a set of parameters. Changing one or two of them does not yield a significant spoofing effect: uniqueness drops by only fractions of a percent, so it’s important to work on the fingerprint comprehensively.
Let’s break down which parameters make up a browser fingerprint, how each parameter is collected, and how much it affects uniqueness.
Stay anonymous, take advantage of multi-accounting, and achieve your goals with the highest-quality anti-detect browser on the market.
Would you like to try Octo Browser at discount?
Use the promo code OCTOBLOG to get 30% off any subscription. This offer is valid only for new users.
Fingerprinting vs. other tracking methods
Browser fingerprinting technology emerged as a response to the limitations of classic user-tracking methods.
HTTP cookies
The best-known way to recognize users is to store a unique identifier in the browser (in a cookie file) and read it on every visit. The drawback is that the user can clear cookies, and the site loses the previously issued ID. Also, in incognito mode or when third-party cookies are blocked by the browser, this method doesn’t work. Modern browsers and extensions offer more tools to block or auto-delete cookies, reducing the effectiveness of this approach. Fingerprinting, on the other hand, does not require storing data on the client side, so it works even with cookies disabled and in incognito mode; it’s enough that the browser provides the necessary system information.
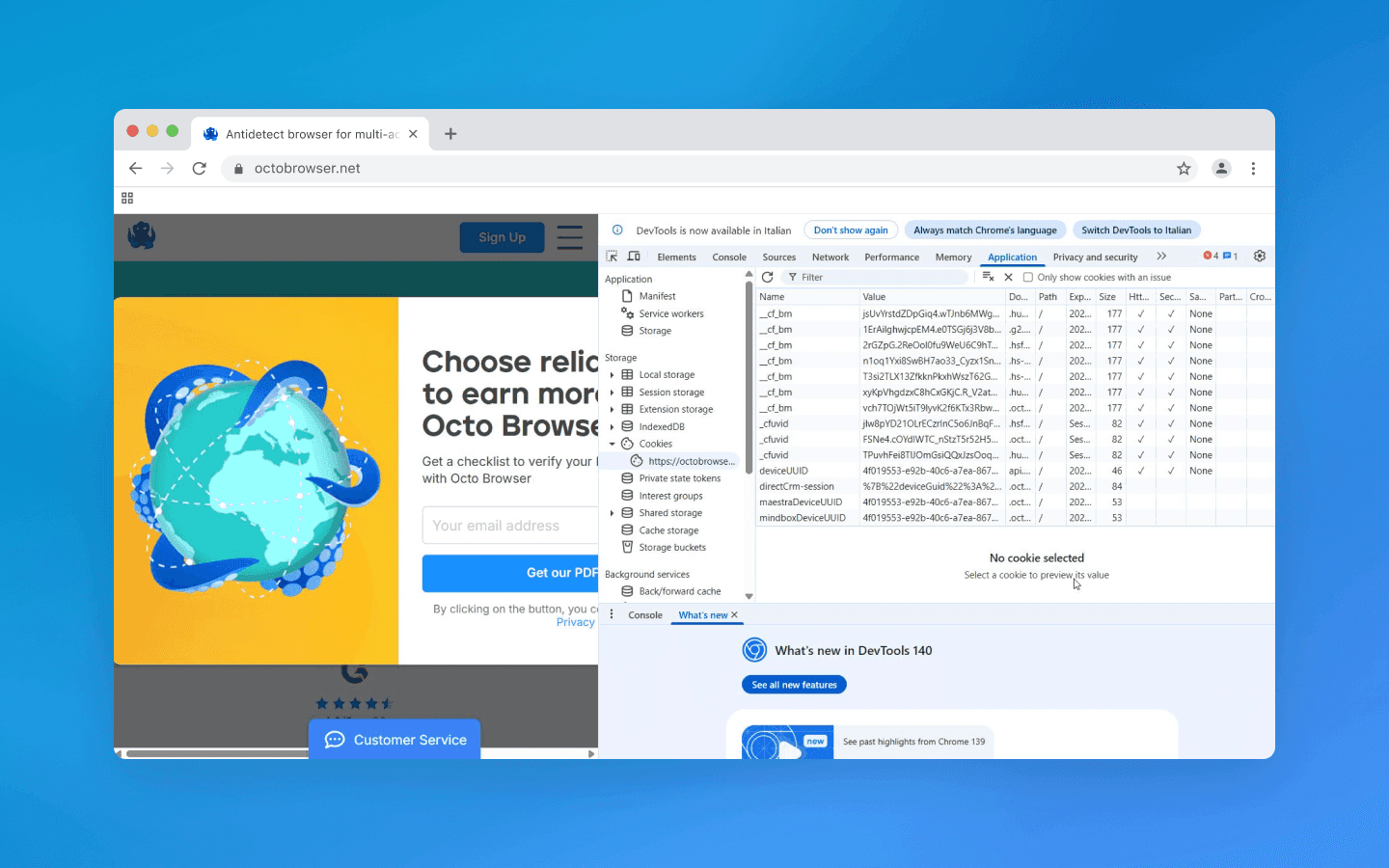
LocalStorage, SessionStorage, and other web storages
Like cookies, these technologies store data locally in the browser. Scripts can read them on repeat visits. However, the user can manually clear them, and storage is isolated by domain; moreover, SessionStorage is only available for one tab/session only.
There is also Evercookie, a technique that tries to create “undeletable” cookies by duplicating the identifier across all available storages (HTTP cookie, Flash LSO, Silverlight Isolated Storage, IndexedDB, etc.), and by using cache and other tricks. But even Evercookie isn’t omnipotent: for example, it’s useless in incognito mode, where data is not saved to the hard drive. Fingerprinting does not save anything on the device; it collects information anew on every visit, so it’s harder to stop with standard clearing methods.
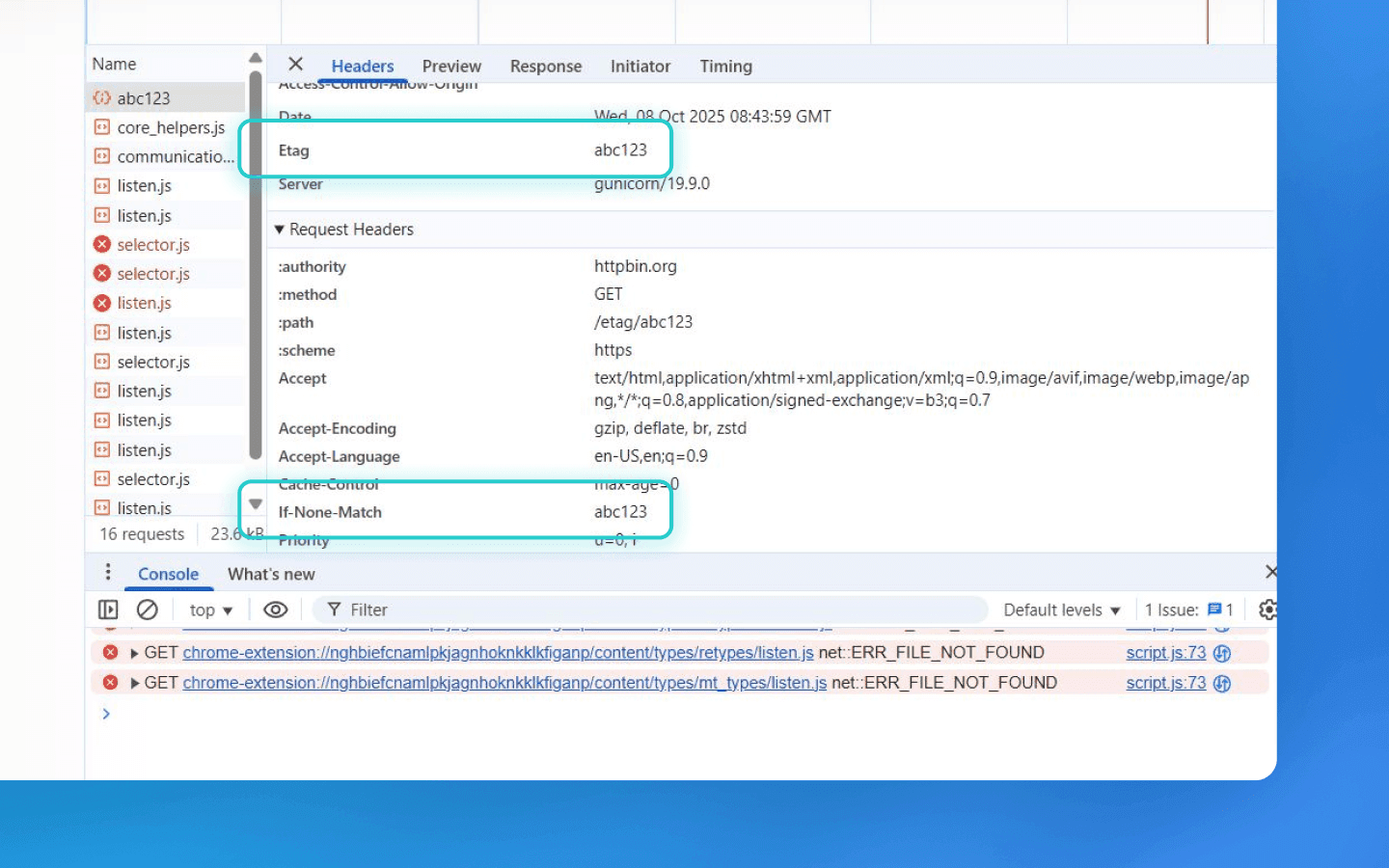
ETag tracking
Not the most common but a working method of using HTTP cache for user identification. On the first request, the server returns a resource (for example, a single pixel) with a unique ETag header. The browser stores it in the cache. On a repeat request to the same URL, the browser automatically sends If-None-Match with the previously received ETag. Thus, the server can detect the same visitor by matching the ETag even if cookies have been deleted. This is a passive tracking method that doesn’t require JavaScript — the identifier is stored in the caching mechanism. ETag tracking is hard to detect, survives cookie clearing (you’d have to clear the cache), and works even without JS. However, it too can be countered if needed (disable cache, use intermediary proxies that clear ETag headers).
CNAME cloaking
A technique that disguises a third-party tracker as a first-party domain using a DNS CNAME record. For example, instead of loading from tracker.thirdparty.com, the script loads from a subdomain like tracker.mysite.com, which points to the tracker’s server at the DNS level via CNAME. The browser treats such a request as coming from the primary resource, so ad/tracker blockers don’t detect the third-party domain — the tracker’s cookies are considered same-site. CNAME cloaking can even bypass browser protections like Safari’s Intelligent Tracking Prevention and the like. In the context of fingerprinting, this method matters because it allows a third-party script to collect a fingerprint and set cookies as if it were the site itself. In essence, CNAME cloaking hides the third party, while fingerprinting works without stored identifiers. Together they can strengthen tracking (the tracker masquerades as the website and collects maximum user data, including the fingerprint, without being blocked).
Fingerprinting
Browser fingerprinting doesn’t replace the methods described above; it’s often used together with them. For example, on the first visit a script may collect the fingerprint and try to set cookies. If cookies are later cleared, a repeat recognition is possible by matching the fingerprint. Also, the fingerprint can complement other methods: for example, supercookies stored via favicon cache can keep a unique ID, and the tracker may compare browser parameters for confirmation. Taken together, these techniques create a multi-layered system for tracking users.
Parameters that make up the browser fingerprint
A fingerprint is formed from dozens of small attributes that together produce a unique combination. Some of them are sent automatically with every HTTP request (passive signals), while others are collected on the client side via JavaScript and Web APIs (active signals).
Passive parameters (HTTP headers and connection)
IP address
The address of your device on the network, determined from each incoming request. It can indicate geolocation (country/city via WHOIS or GeoIP) and affiliation with an organization/ISP. Although an IP address is often not unique (many users may be behind a public address of a single ISP) and can change dynamically, it is included in the fingerprint as a basic network identifier. Moreover, if WebRTC is available, a script can perform a STUN request and obtain your real IP address. An IP address by itself is not permanent, but combined with other signals it increases the probability of uniqueness.
User Agent
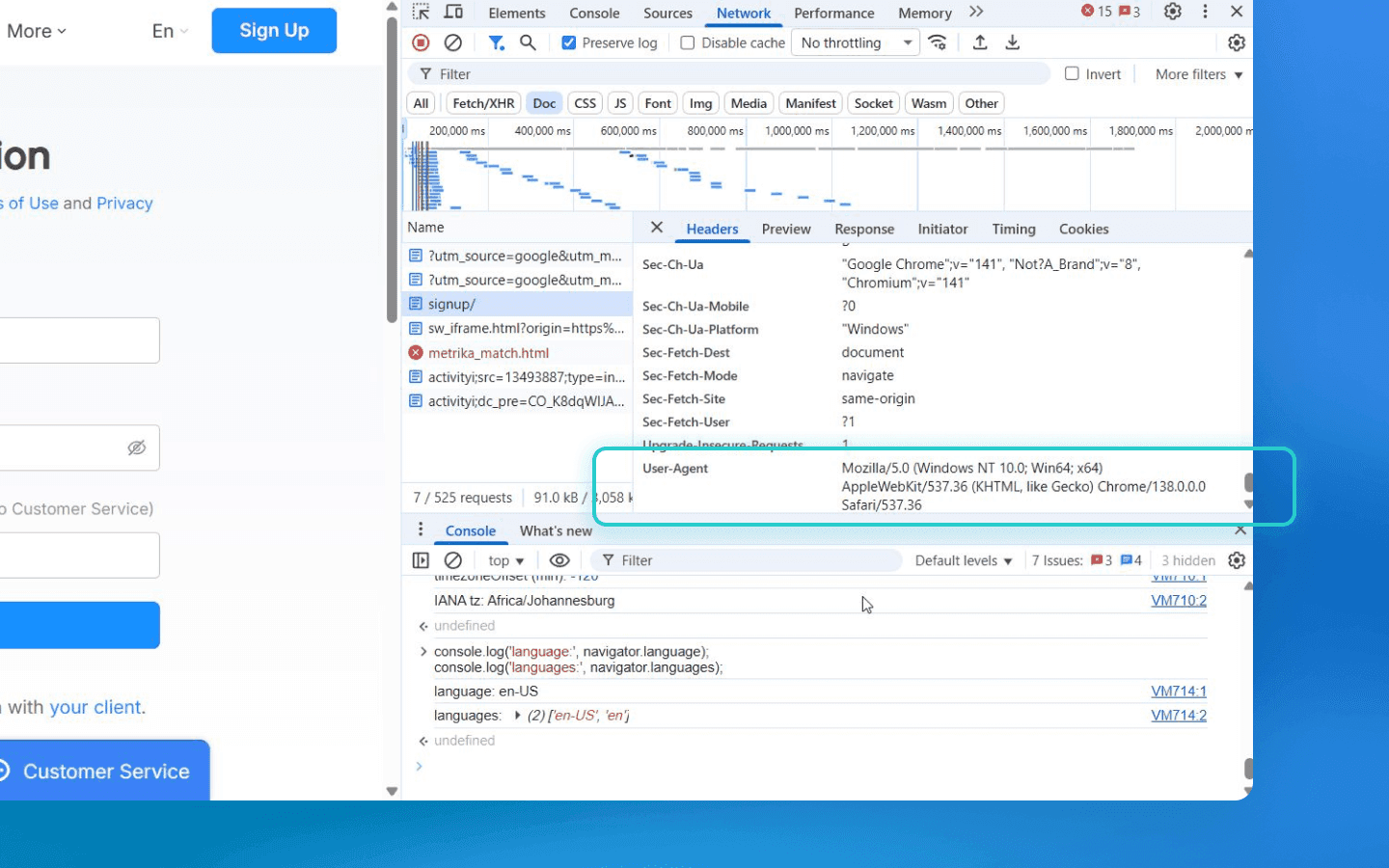
The user agent string sent in the User-Agent header by every browser. It contains information about the browser, its version, engine, OS version, architecture, and sometimes device model, e.g. Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36. Analyzing the user agent lets you distinguish, roughly, Chrome on Windows from Safari on iOS, etc. — in other words, narrow the identification down to the browser and platform.
User agent uniqueness: although the user agent is formed from a limited set of versions, the combination of OS and browser is often rare. For example, an older browser version on a specific OS will present a unique user agent. Non-standard headers added by extensions may also appear in the fingerprint; from them sites can infer installed plugins or frameworks. Overall, however, the user agent is easy to spoof, so you shouldn’t rely on it alone; it is just one aspect of the fingerprint.
Accept headers and other protocol characteristics
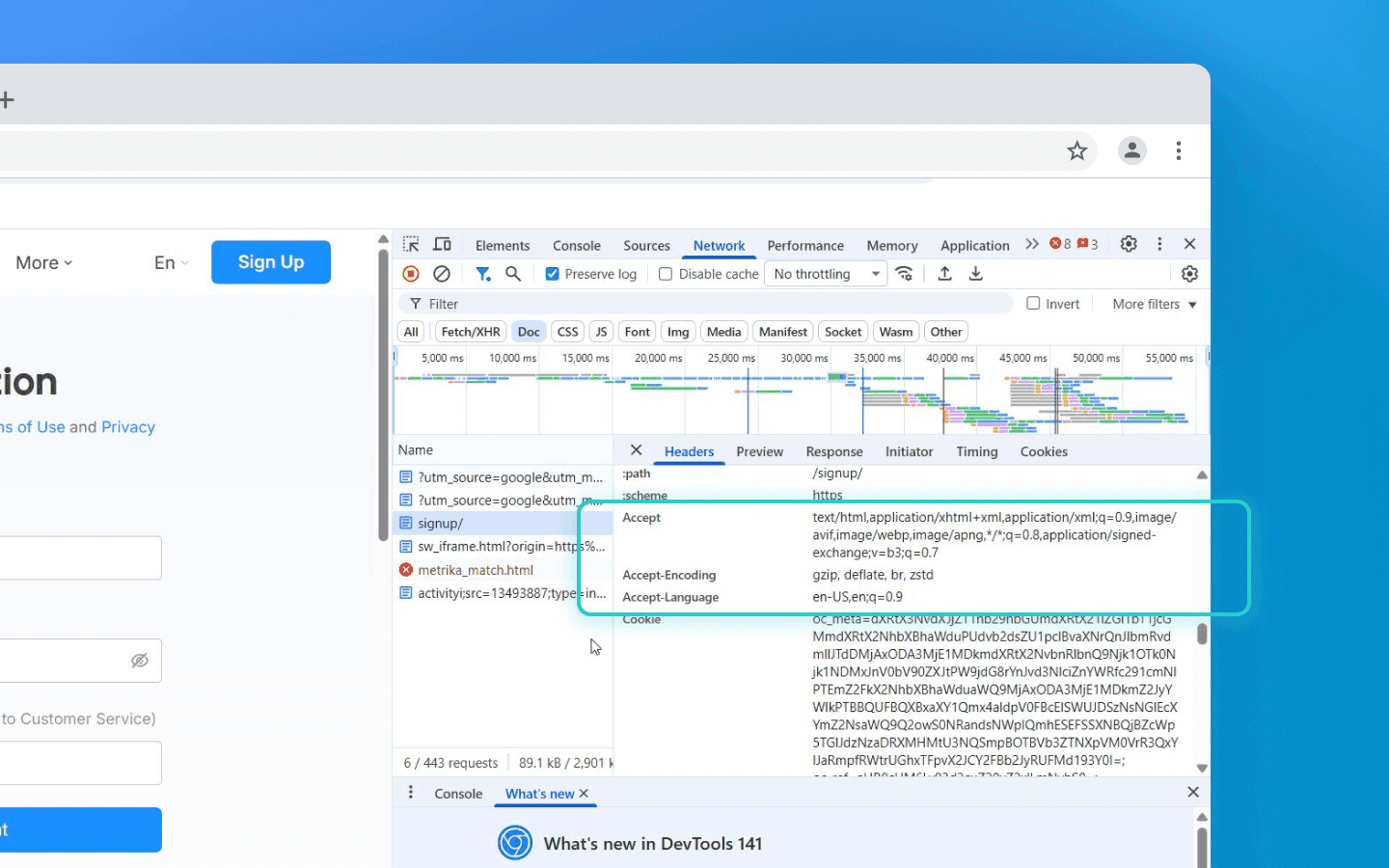
With each request the browser sends a set of headers: supported formats (Accept, Accept-Language, Accept-Encoding), referrer, caching flags, etc. The combination of these headers is also quite informative. For example, the order and contents of Accept-Language and Accept-Charset fields can differ between OS locales. Presence of Accept-Encoding: br indicates Brotli support and indirectly a relatively modern browser. The specific order in which a browser enumerates headers can serve as a browser engine signature.
HTTP-level signals are considered passive, as they are provided automatically by the browser. Without JS, the server can learn device type (via User-Agent), preferred languages (Accept-Language), the content types the client supports (e.g., WebP support in Accept reveals a Blink engine), and so on. All these small details feed into the fingerprint model.
Timezone
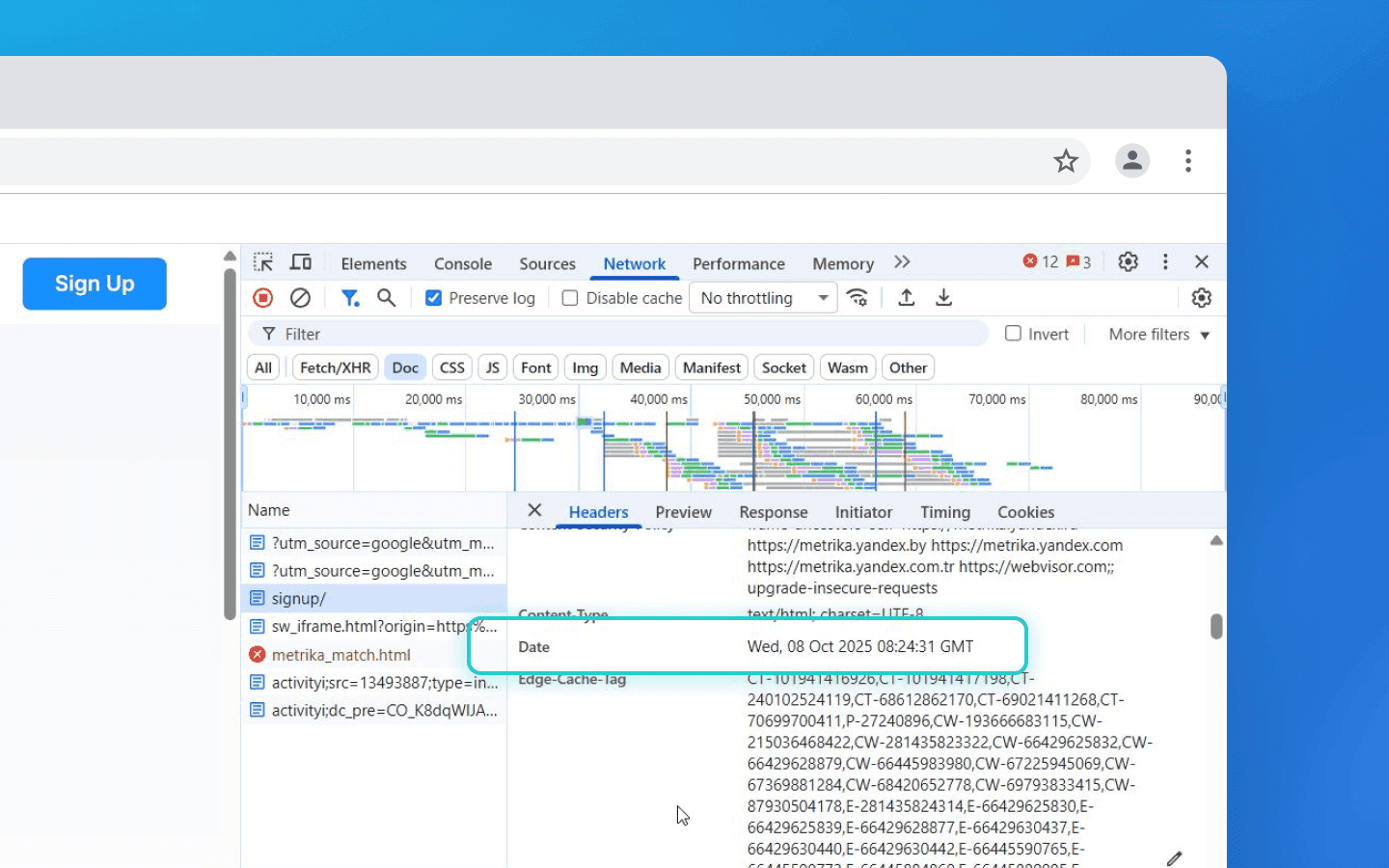
Although the user’s timezone can be determined actively (via JS), it can be approximated from headers as well. For example, the Date header in HTTP or the time in server logs can be compared with the request time on the client side (for instance, if If-Modified-Since is visible). More commonly the Timezone is obtained on the client side. However, the time offset (GMT±X) is part of the fingerprint because it differs across regions and remains stable for a user over time (unless the user travels or changes the setting manually).
Supported Technologies
Some headers or connection traits may indicate browser capabilities. For example, DNT (Do-Not-Track) is present if the user enabled “Do Not Track”; DNT: 1 then becomes part of the fingerprint (paradoxically, this flag can make you stand out because few people enable it). Another example: Upgrade-Insecure-Requests: 1 is sent by most modern browsers on first transition to HTTPS; its absence might identify an unusual client. These subtle nuances rarely appear as separate fingerprint fields but can be considered collectively.
Active parameters (JavaScript and Web API)
Screen resolution and color depth
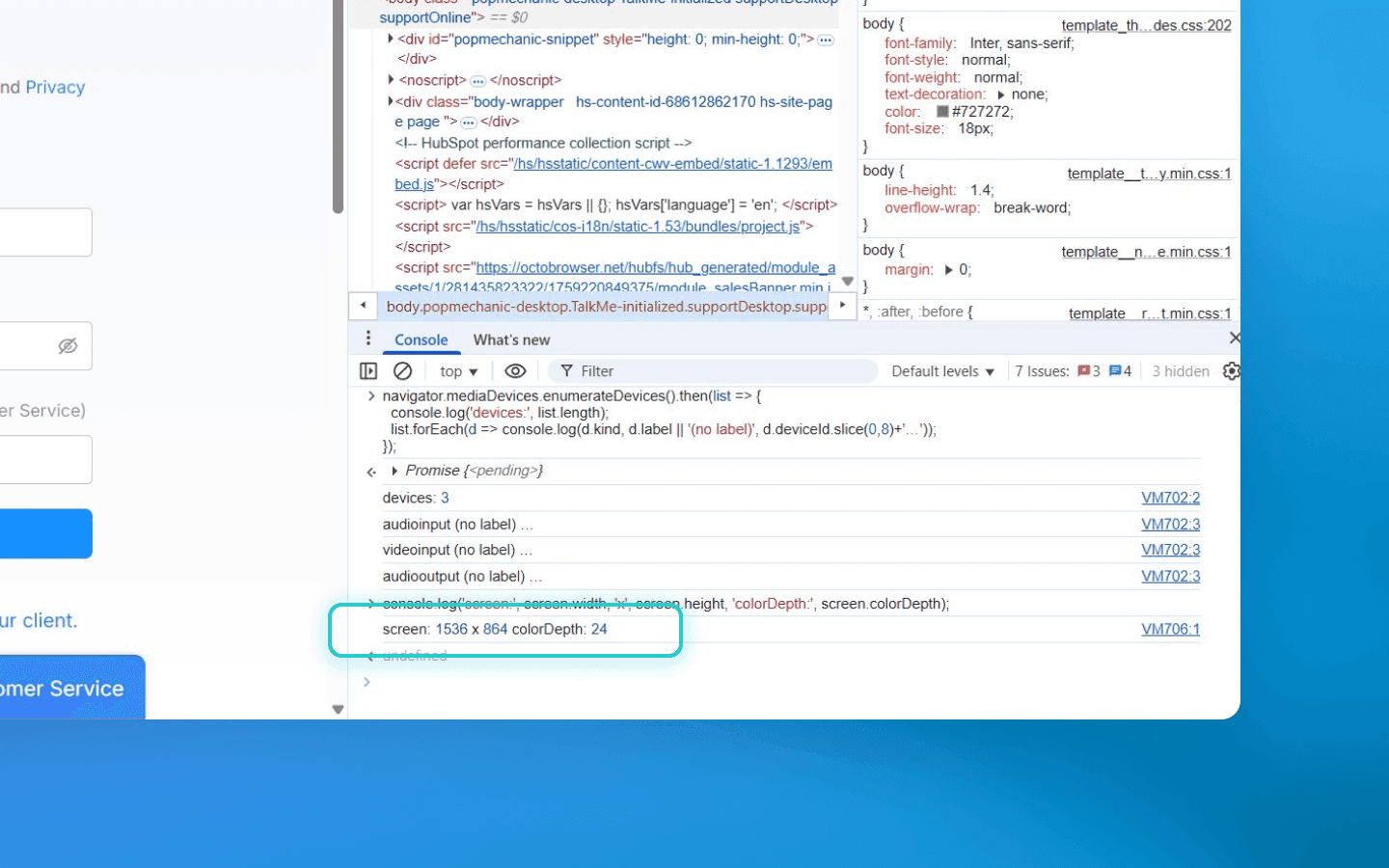
Available via window.screen objects. Properties screen.width/height return current screen resolution (sometimes accounting for display scaling), and screen.colorDepth returns color depth (usually 24 or 32 bits). These parameters are frequently included in the fingerprint because they vary widely: everyone’s screen size differs. On desktops the browser window rarely matches maximum resolution, but a fingerprint usually takes the maximum available resolution of the user, which reflects their display size. For example, 1920×1080×24 (Full HD, 24-bit color) is one configuration, 1366×768×24 is another, etc. Each resolution combined with color depth can narrow down the device group. If the user changes monitor resolution or connects a new monitor, the fingerprint will change.
Language settings
A browser exposes several related settings: interface/OS language, preferred page language(s), and locale formats for dates/numbers. JS can get navigator.language (or navigator.languages for a list) — values like “ru-RU” or “en-US.” This usually matches what the server receives in Accept-Language. Locale affects formatting functions like Date.toString() (month names in Russian or English, etc.), which can also be used for fingerprinting.
Effect on uniqueness: combinations of languages and regions are quite variable. For example, a Russian-speaking user might have locale ru-RU, or uk-UA (if their OS is Ukrainian), or even en-US (if the interface is English). These nuances add a few bits of entropy. The number of unique language-combination permutations grows every year, but language alone is not extra unique: many people use popular locales. However, combined with other parameters, language helps distinguish, say, Chrome/Windows in Russian from Chrome/Windows in German, creating two different profiles.
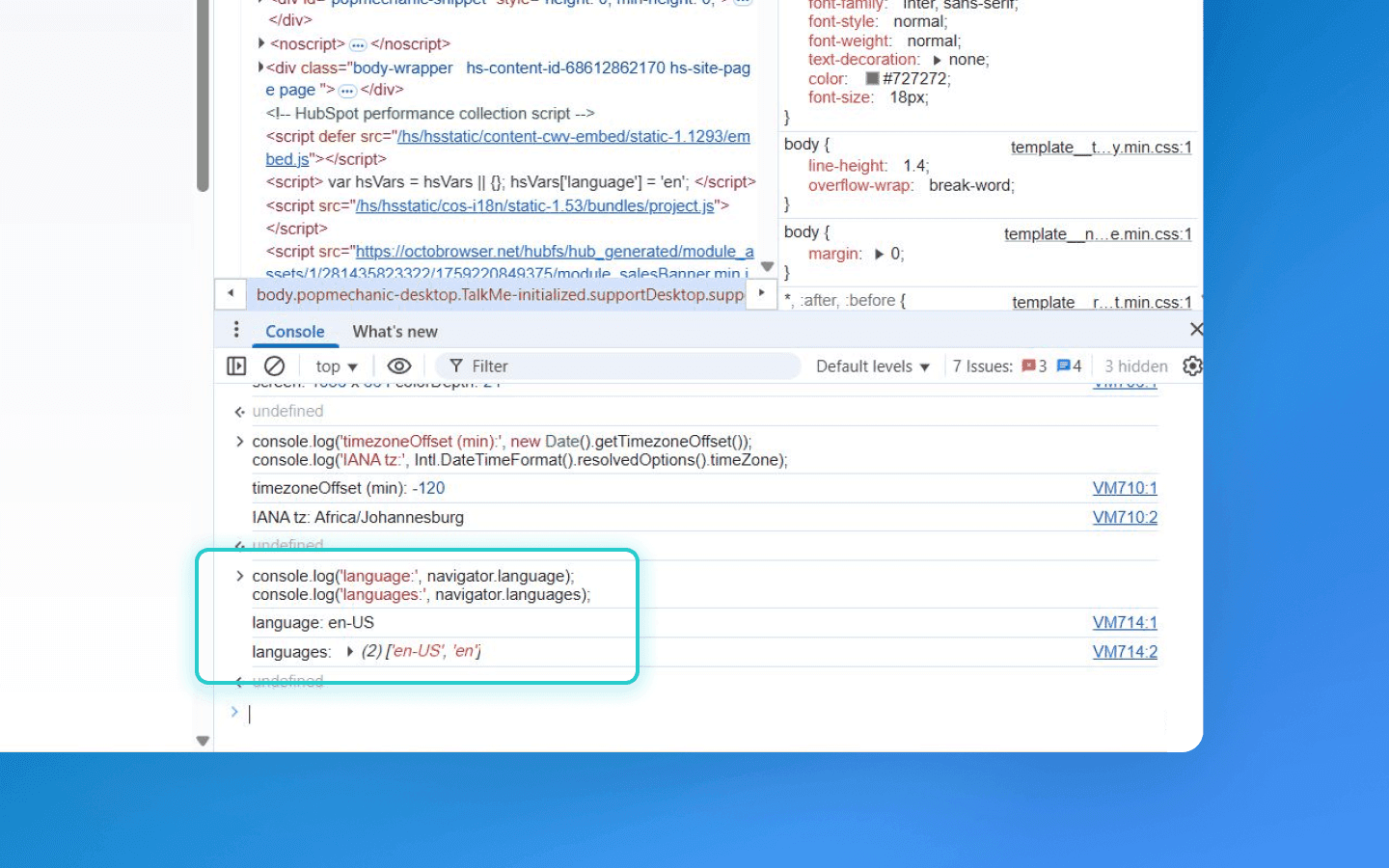
Timezone (via JS)
A more accurate way to determine the timezone is to call a new Date().getTimezoneOffset() using JS. This returns the local time offset from UTC in minutes. For example, GMT+3 yields 180 minutes. You can also get the timezone name using Intl API. This parameter is almost always included in the fingerprint because it is stable for a device and varies geographically. Two users with identical parameters but different timezones already produce different fingerprints.
Note: some advanced fingerprinters track timezone changes: this can indicate that the same browser changed context (for instance, if the user traveled or changed clock settings). However, the current offset value is normally used for a simple fingerprint.
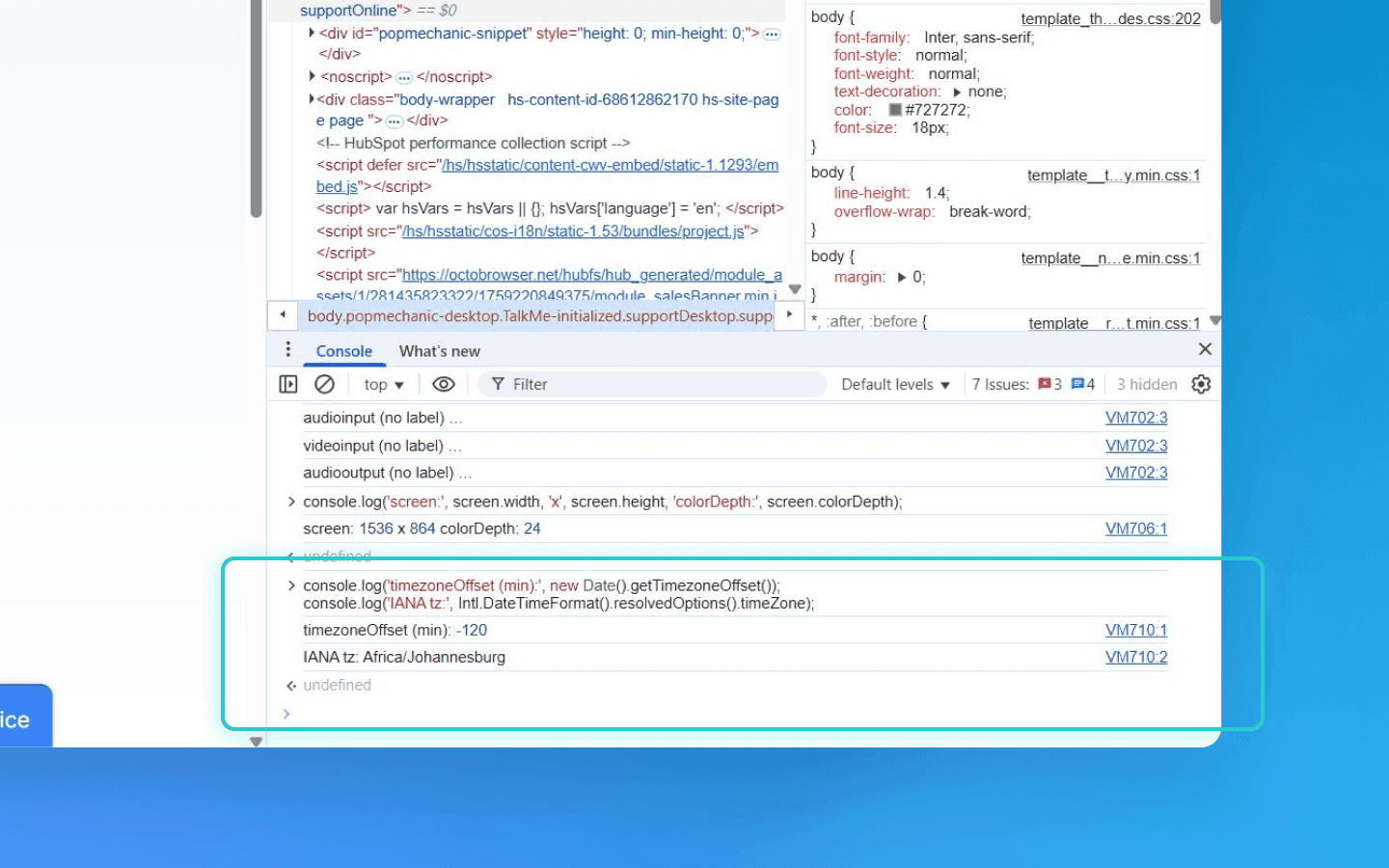
Information about the platform and CPU
The navigator object provides a number of properties related to the device platform:
navigator.platform— a string indicating the OS/architecture, for example Win32, Linux x86_64, iPhone, etc. This used to be a fairly telling parameter (distinguishing, for example, 32-bit Windows from 64-bit), but modern browsers may return truncated or unified values for privacy reasons. If the parameter is available, it is included in the fingerprint.navigator.hardwareConcurrency— the number of logical CPU threads (cores) on the device. For example, 8 (which may correspond to 4 physical cores with Hyper-Threading). This adds extra variability: mobile devices often have 4 or 8, desktops — 4, 8, 12, 16 and more cores. Not every browser reports an exact value, but under normal conditions this parameter is collected. An unusual thread count (e.g., 6 or 10) can immediately single out a device.navigator.deviceMemory— approximate RAM size in gigabytes (integer). Chrome rounds to 0.25 (a quarter) increments. For example, 8 GB givesdeviceMemory = 8. This signal is not supported in all browsers. Where present, it is included: RAM size is rarely a round number, so variability reduces overlaps.navigator.oscpu— a string with the operating system (Firefox-only API). In modern Firefox on Windows it returns something like Windows NT 10.0; Win64; x64. This parameter is rarely used because it duplicates information from the User-Agent.navigator.webdriver— a boolean indicating whether the browser is driven by automation (WebDriver). Iftrue, the site knows it’s dealing with a bot and may change behavior or factor this into the fingerprint. For fingerprinting this is less a “uniqueness” parameter and more a way to detect automation. Nevertheless,navigator.webdriver=trueclearly singles out the client (regular users have false), so indirectly it is part of the fingerprint.
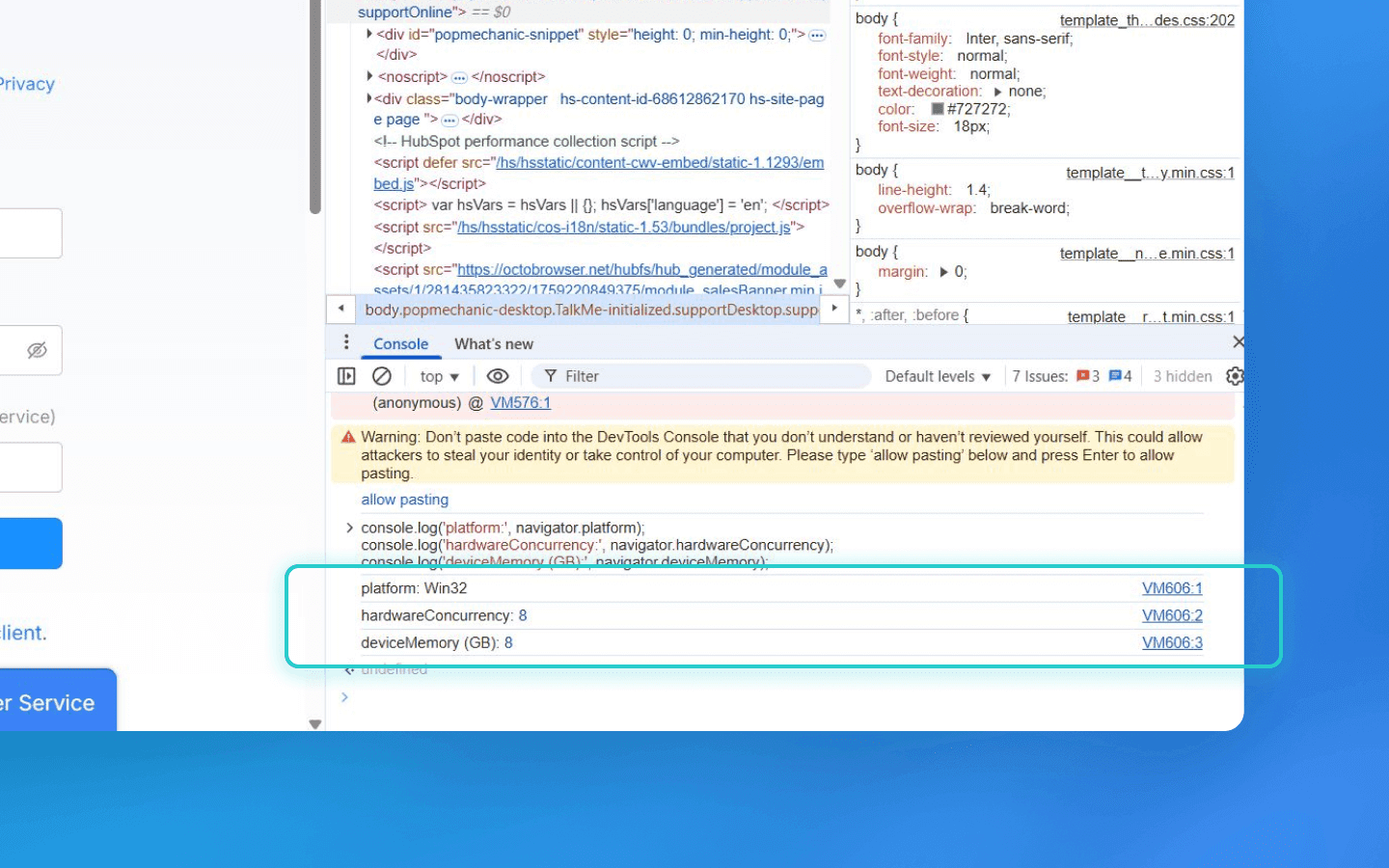
Cookies/Storage enabled state
Scripts can check whether cookies are enabled in the browser (navigator.cookieEnabled). If the user has disabled them, this distinguishes them from the majority of other users (almost everyone keeps cookies enabled) and adds uniqueness.
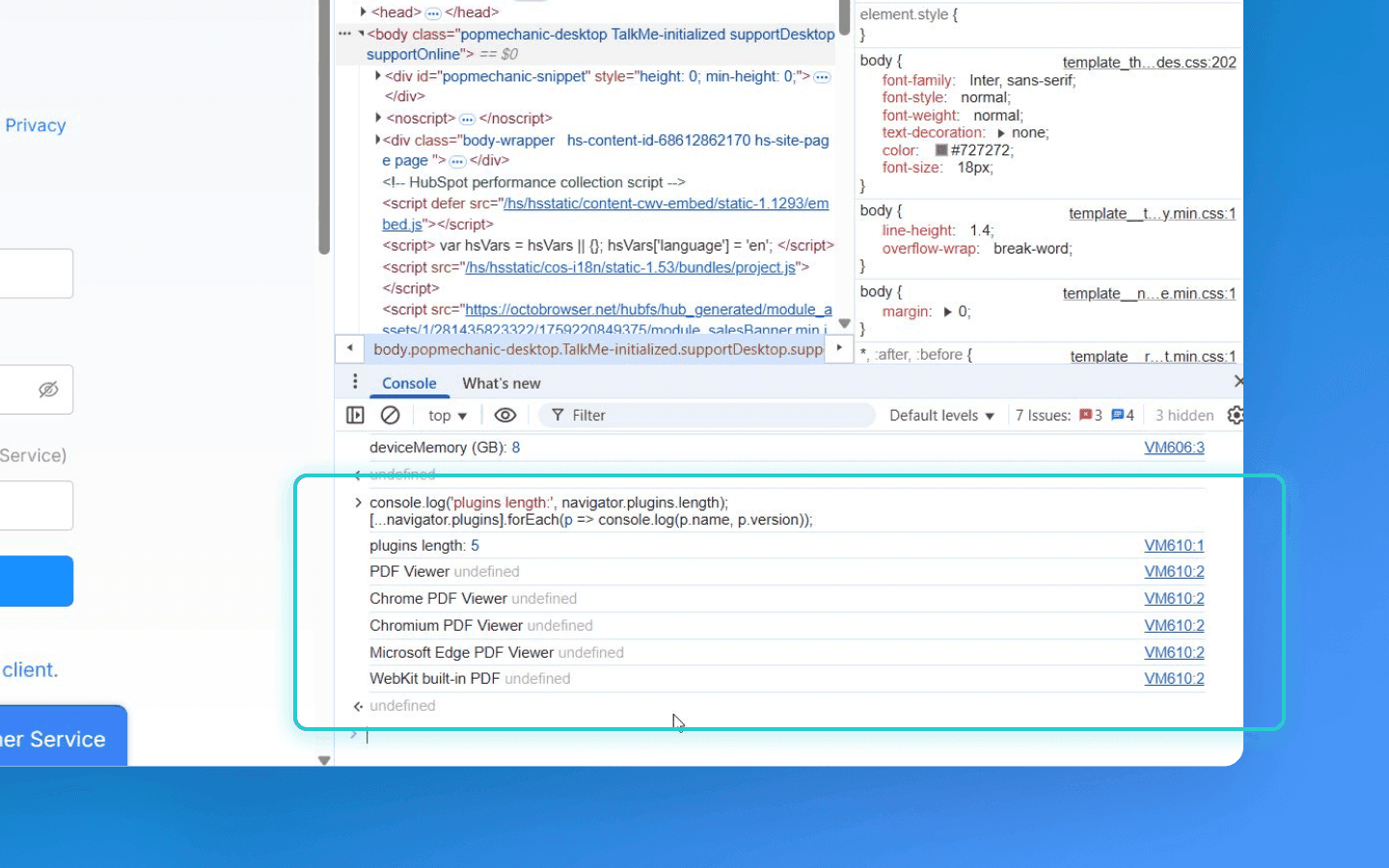
List of browser plugins
navigator.plugins can return a list of installed NPAPI plugins: Acrobat Reader, Flash, Silverlight, etc., including their versions (navigator.plugins[i].name/version), although NPAPI plugins have largely disappeared (Flash and Java are disabled or removed from modern browsers). In Chrome navigator.plugins now contains only the built-in PDF Viewer; in Firefox, likewise, there is nothing extra. Still, the API exists and some browsers may still return something. The fingerprint may include plugin names and their count. An empty list is also a signal (for example, Firefox in Tor-mode has it empty, while a regular Firefox might include a built-in OpenH264 plugin). Overall the role of plugins as a factor is declining; extensions are gaining importance instead.
Installed extensions
Ideally websites shouldn’t know which extensions a user has, but in practice some extensions can be detected indirectly. AdBlock or Adblock Plus can be detected by blocked requests or specific DOM elements they introduce. A site may try to load a known URL filtered by AdBlock — if it doesn’t load, a blocker is likely present.
Another example: extensions can add special objects to window (e.g., React Developer Tools adds __REACT_DEVTOOLS_GLOBAL_HOOK__), and a script finding such an object recognizes the extension. Dozens of small checks can build a “snapshot” of the browser environment. The approximate number of extensions can sometimes be inferred from page response time. Each installed extension can slow page processing. In any case, presence of popular blockers, password managers, or niche extensions is partially detectable and increases profile uniqueness.
List of installed fonts
One of the most variable parameters. The set of system fonts depends on the OS, installed applications (Microsoft Office adds fonts, Adobe adds its own, etc.), and system language (Chinese fonts usually aren’t present for European users). How can a web page detect which fonts you have? Historically Flash (EnumerateFonts) was used, but without it there are purely browser-side methods:
Via CSS+JS: a hidden element is created with a font-family fallback list. If the first font isn’t installed, the text renders in the next font and the element’s width/height changes. JS can measure element dimensions to infer which font applied. Iterating hundreds of popular fonts reveals which are present. This method is time-consuming, so the following method is often used.
Via Canvas: drawing text in a specific font on a canvas and comparing the pixel raster lets you determine whether the font is installed. This is essentially a case of Canvas fingerprinting (see below).
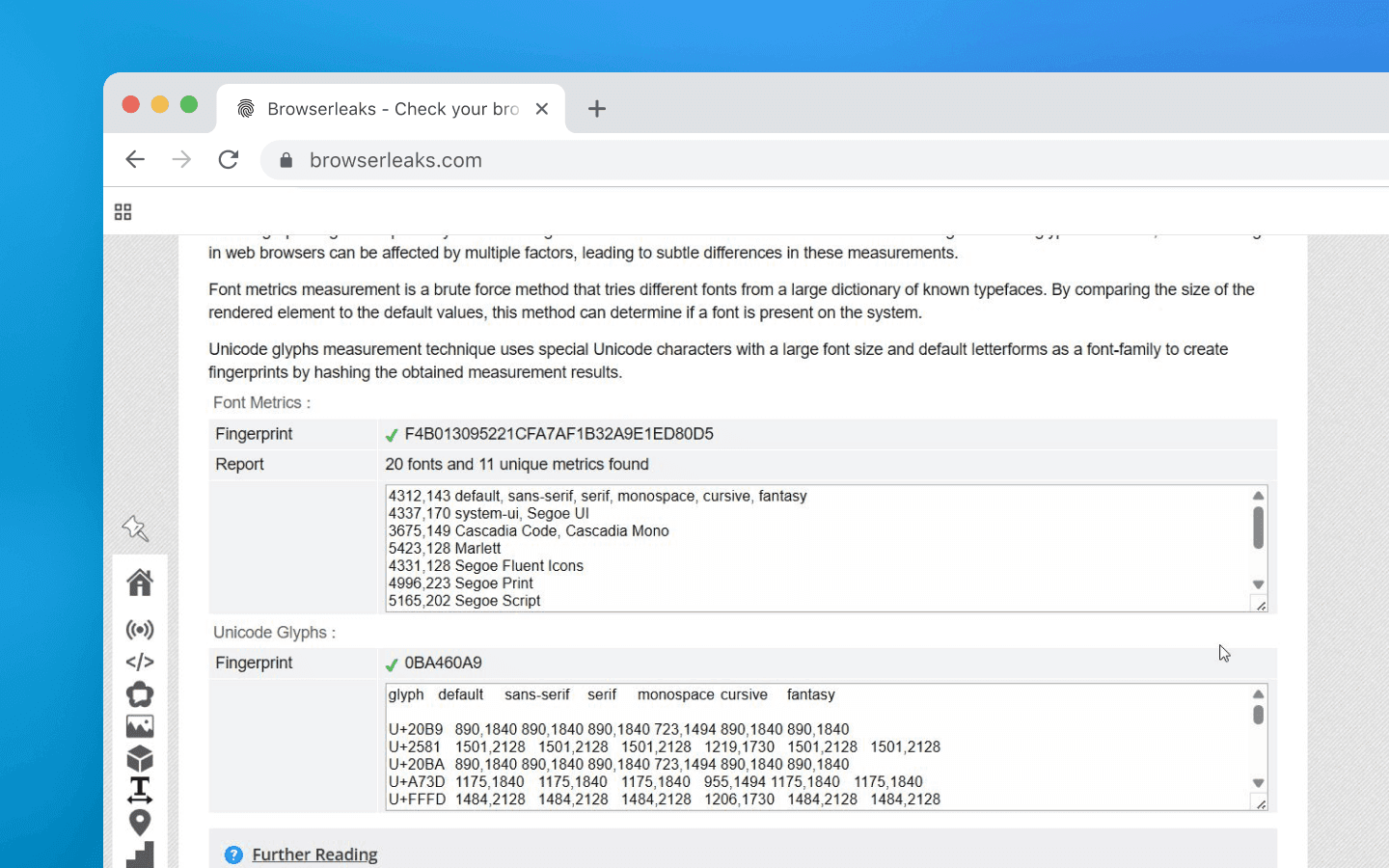
The number of possible font-set combinations is huge, because few people have identical font lists, especially across different OS versions. A rare font (e.g., design-specific fonts) immediately makes the fingerprint unique, making font data incredibly useful for fingerprinting. Font collection is not instantaneous, so some scripts cache the fingerprint result.
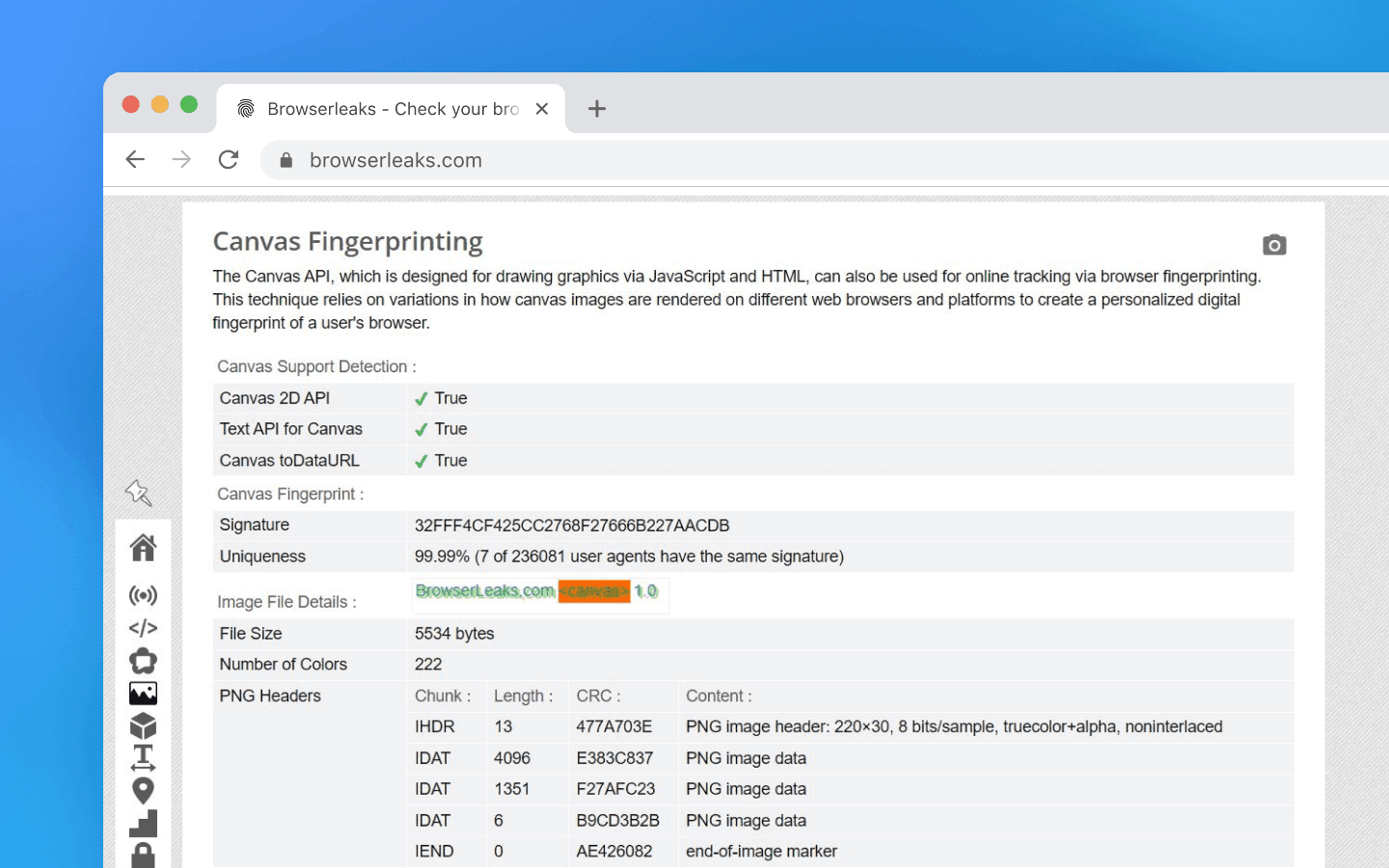
Canvas Fingerprinting
This is a well-known fingerprinting method using the HTML5 <canvas> element to obtain unique rendering characteristics. The browser draws content (usually text with a specific font and colors, sometimes geometric shapes) on a virtual canvas, then the script calls canvas.toDataURL(), getting a bitmap of the rendered content. The image is represented as a base64 string, hashed to produce a Canvas fingerprint.
Why is it unique? Tiny differences in the system — font smoothing algorithms, GPU driver versions, platform (Linux vs Windows) — produce subtle variations in the final image. Typically text with diverse characters (letters of different shapes, special symbols) is drawn to maximize smoothing effects. Scripts may also draw colored rectangles, apply transforms or shadows to exercise graphics functions. Different devices yield different images from the same drawing code. A Canvas fingerprint can change after GPU driver updates or switching from integrated to discrete graphics. Combined with WebGL, however, it becomes extremely valuable.
WebGL Fingerprinting
WebGL is an API for rendering 3D graphics in the browser (essentially providing access to OpenGL/ES capabilities). It supplies two key types of data for fingerprinting:
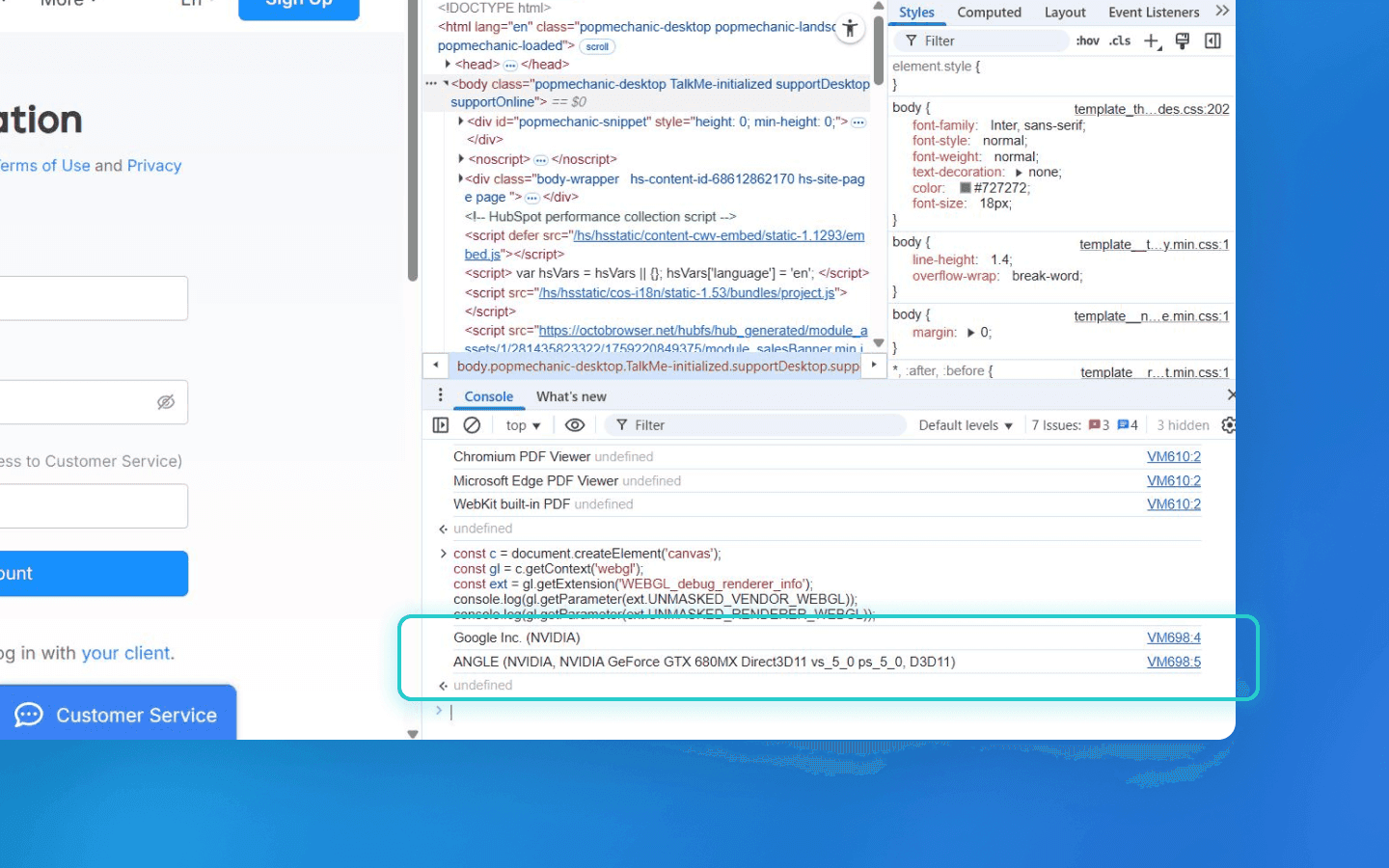
Direct GPU identifiers
The WEBGL_debug_renderer_info extension allows a script to retrieve the UNMASKED_VENDOR_WEBGL and UNMASKED_RENDERER_WEBGL strings from the WebGL context — these typically list the manufacturer and model of the GPU (e.g., Intel Inc., Intel Iris Plus Graphics 640, or NVIDIA Corporation, GeForce GTX 1070). These values effectively reveal the user’s video card model. Most browsers allow this in standard mode (except Tor). The GPU model adds significant entropy: even if two users have the same operating system and browser, one with Intel HD Graphics and the other with an RTX 3080 will have distinct fingerprints.
WebGL constants and capabilities
Even without the direct GPU name, the WebGL context holds many parameters that depend on the driver and hardware: maximum texture units, geometry size limits, shadow and anti-aliasing support, and other numeric constants. A script can sequentially call gl.getParameter(...) for various constants and collect the results. For example, MAX_VERTEX_UNIFORM_VECTORS might be 4,096 on one card and 1,024 on another, etc. The result is a long vector of numbers, a sort of profile of the graphics subsystem. Such a profile is often unique to a device and can differ even between similar GPU models.
Additionally, WebGL can be used like Canvas: that is, by rendering a complex 3D scene and obtaining its raster image. This approach can reveal even subtler differences (for example, in shader implementations). In practice, libraries such as FingerprintJS usually limit themselves to reading UNMASKED_RENDERER (since it’s simpler and more reliable), but some scripts also hash a rendered 3D shape for greater stability. WebGL data greatly increase fingerprint uniqueness, especially on mobile devices: for instance, it used to be difficult to distinguish between iPhones (all had identical Canvas output due to identical GPUs), but now the GPU version can reveal the iPhone model if WebGL is enabled. Combined with Canvas, WebGL provides a powerful source of entropy. That’s why browsers in privacy-oriented modes try to hide or spoof this data.
AudioContext Fingerprinting
Another sophisticated fingerprinting method uses the Web Audio API to derive a unique audio fingerprint of the device. It’s based on the fact that audio generation and processing vary slightly across systems (due to library implementations, SIMD instruction usage, floating-point inaccuracies, etc.). In practice, AudioContext fingerprint values differ noticeably between browsers; each “browser + OS + hardware” combination produces its own deterministic result (as long as the browser or OS aren’t significantly changed). Adding an audio fingerprint further strengthens identification: even if Canvas and WebGL outputs coincidentally match, the audio fingerprint may still distinguish the devices.
Media devices and sensors
During fingerprinting, a script can also collect information about peripheral hardware:
Via
navigator.mediaDevices.enumerateDevices(), it can obtain a list of the user’s media devices (cameras, microphones). The browser usually returns limited data, for example, “two cameras and one microphone” without names or IDs unless permission is granted. Still, the number of devices alone can serve as a distinguishing factorAPIs such as Battery Status (battery charge level) were once available and also used for fingerprinting. Battery level and remaining time produced unique combinations. Because these APIs could yield overly precise identifiers (a privacy issue), they are now either restricted or permission-based.
Sensors (Orientation, Motion): the presence of certain sensors and the format of their output may vary across devices (e.g., gyroscope refresh rate). These are relatively exotic signals but they can still theoretically supplement a fingerprint.
Overall, the more non-standard the device, the more it reveals through such APIs. If a user has no camera or microphone at all, that already distinguishes them from most laptops, which almost always have webcams.
All of the above — both active and passive attributes — form a set of browser and system characteristics. In practice, scripts collect 10–30 parameters and compile them into a structure (e.g., an object or an array of strings), which is then converted into a hash. Many libraries use fast hashing algorithms such as MurmurHash to produce a compact identifier from roughly 500 bytes of attribute data. The result is a string (e.g., a3f6e9b12d4...) that can be stored on a server as the device ID.
Protection against browser fingerprinting
Modern browsers implement various countermeasures aimed at combating fingerprinting. For example, Tor Browser aims to make all users look identical (the same User-Agent, fixed window size, uniform font set, Canvas and AudioContext disabled, etc.). It even warns users not to maximize the window if they want to remain anonymous.
Firefox includes the privacy.resistFingerprinting setting, which similarly averages out values. Brave blocks third-party trackers by default and injects noise into APIs. There are extensions such as CanvasBlocker or Privacy Badger that selectively break tracking scripts.
However, no method offers 100% protection — too many parameters are exposed by browsers. In response to the growing demand for anonymity, anti-detect browsers (such as Octo Browser, MultiLogin, and Dolphin {anty}) have appeared, allowing users to emulate different fingerprints and create dozens of “virtual” identities with distinct parameters for, e.g., affiliate marketing purposes.
The race that began years ago continues: trackers develop new techniques, and browsers devise new countermeasures. The average user clearly loses this race — if one doesn’t actively care about privacy, any site can capture their digital fingerprint and correlate it with data from other sources.
A fingerprint consists of many components, each adding a degree of uniqueness. Hopefully, this breakdown helped you understand how exactly your browser can be identified by websites — because understanding how the technology works is the first step to knowing where the line lies between the convenience of personalization and the protection of personal data.
Stay anonymous, take advantage of multi-accounting, and achieve your goals with the highest-quality anti-detect browser on the market.
Would you like to try Octo Browser at discount?
Use the promo code OCTOBLOG to get 30% off any subscription. This offer is valid only for new users.
Fingerprinting vs. other tracking methods
Browser fingerprinting technology emerged as a response to the limitations of classic user-tracking methods.
HTTP cookies
The best-known way to recognize users is to store a unique identifier in the browser (in a cookie file) and read it on every visit. The drawback is that the user can clear cookies, and the site loses the previously issued ID. Also, in incognito mode or when third-party cookies are blocked by the browser, this method doesn’t work. Modern browsers and extensions offer more tools to block or auto-delete cookies, reducing the effectiveness of this approach. Fingerprinting, on the other hand, does not require storing data on the client side, so it works even with cookies disabled and in incognito mode; it’s enough that the browser provides the necessary system information.
LocalStorage, SessionStorage, and other web storages
Like cookies, these technologies store data locally in the browser. Scripts can read them on repeat visits. However, the user can manually clear them, and storage is isolated by domain; moreover, SessionStorage is only available for one tab/session only.
There is also Evercookie, a technique that tries to create “undeletable” cookies by duplicating the identifier across all available storages (HTTP cookie, Flash LSO, Silverlight Isolated Storage, IndexedDB, etc.), and by using cache and other tricks. But even Evercookie isn’t omnipotent: for example, it’s useless in incognito mode, where data is not saved to the hard drive. Fingerprinting does not save anything on the device; it collects information anew on every visit, so it’s harder to stop with standard clearing methods.
ETag tracking
Not the most common but a working method of using HTTP cache for user identification. On the first request, the server returns a resource (for example, a single pixel) with a unique ETag header. The browser stores it in the cache. On a repeat request to the same URL, the browser automatically sends If-None-Match with the previously received ETag. Thus, the server can detect the same visitor by matching the ETag even if cookies have been deleted. This is a passive tracking method that doesn’t require JavaScript — the identifier is stored in the caching mechanism. ETag tracking is hard to detect, survives cookie clearing (you’d have to clear the cache), and works even without JS. However, it too can be countered if needed (disable cache, use intermediary proxies that clear ETag headers).
CNAME cloaking
A technique that disguises a third-party tracker as a first-party domain using a DNS CNAME record. For example, instead of loading from tracker.thirdparty.com, the script loads from a subdomain like tracker.mysite.com, which points to the tracker’s server at the DNS level via CNAME. The browser treats such a request as coming from the primary resource, so ad/tracker blockers don’t detect the third-party domain — the tracker’s cookies are considered same-site. CNAME cloaking can even bypass browser protections like Safari’s Intelligent Tracking Prevention and the like. In the context of fingerprinting, this method matters because it allows a third-party script to collect a fingerprint and set cookies as if it were the site itself. In essence, CNAME cloaking hides the third party, while fingerprinting works without stored identifiers. Together they can strengthen tracking (the tracker masquerades as the website and collects maximum user data, including the fingerprint, without being blocked).
Fingerprinting
Browser fingerprinting doesn’t replace the methods described above; it’s often used together with them. For example, on the first visit a script may collect the fingerprint and try to set cookies. If cookies are later cleared, a repeat recognition is possible by matching the fingerprint. Also, the fingerprint can complement other methods: for example, supercookies stored via favicon cache can keep a unique ID, and the tracker may compare browser parameters for confirmation. Taken together, these techniques create a multi-layered system for tracking users.
Parameters that make up the browser fingerprint
A fingerprint is formed from dozens of small attributes that together produce a unique combination. Some of them are sent automatically with every HTTP request (passive signals), while others are collected on the client side via JavaScript and Web APIs (active signals).
Passive parameters (HTTP headers and connection)
IP address
The address of your device on the network, determined from each incoming request. It can indicate geolocation (country/city via WHOIS or GeoIP) and affiliation with an organization/ISP. Although an IP address is often not unique (many users may be behind a public address of a single ISP) and can change dynamically, it is included in the fingerprint as a basic network identifier. Moreover, if WebRTC is available, a script can perform a STUN request and obtain your real IP address. An IP address by itself is not permanent, but combined with other signals it increases the probability of uniqueness.
User Agent
The user agent string sent in the User-Agent header by every browser. It contains information about the browser, its version, engine, OS version, architecture, and sometimes device model, e.g. Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36. Analyzing the user agent lets you distinguish, roughly, Chrome on Windows from Safari on iOS, etc. — in other words, narrow the identification down to the browser and platform.
User agent uniqueness: although the user agent is formed from a limited set of versions, the combination of OS and browser is often rare. For example, an older browser version on a specific OS will present a unique user agent. Non-standard headers added by extensions may also appear in the fingerprint; from them sites can infer installed plugins or frameworks. Overall, however, the user agent is easy to spoof, so you shouldn’t rely on it alone; it is just one aspect of the fingerprint.
Accept headers and other protocol characteristics
With each request the browser sends a set of headers: supported formats (Accept, Accept-Language, Accept-Encoding), referrer, caching flags, etc. The combination of these headers is also quite informative. For example, the order and contents of Accept-Language and Accept-Charset fields can differ between OS locales. Presence of Accept-Encoding: br indicates Brotli support and indirectly a relatively modern browser. The specific order in which a browser enumerates headers can serve as a browser engine signature.
HTTP-level signals are considered passive, as they are provided automatically by the browser. Without JS, the server can learn device type (via User-Agent), preferred languages (Accept-Language), the content types the client supports (e.g., WebP support in Accept reveals a Blink engine), and so on. All these small details feed into the fingerprint model.
Timezone
Although the user’s timezone can be determined actively (via JS), it can be approximated from headers as well. For example, the Date header in HTTP or the time in server logs can be compared with the request time on the client side (for instance, if If-Modified-Since is visible). More commonly the Timezone is obtained on the client side. However, the time offset (GMT±X) is part of the fingerprint because it differs across regions and remains stable for a user over time (unless the user travels or changes the setting manually).
Supported Technologies
Some headers or connection traits may indicate browser capabilities. For example, DNT (Do-Not-Track) is present if the user enabled “Do Not Track”; DNT: 1 then becomes part of the fingerprint (paradoxically, this flag can make you stand out because few people enable it). Another example: Upgrade-Insecure-Requests: 1 is sent by most modern browsers on first transition to HTTPS; its absence might identify an unusual client. These subtle nuances rarely appear as separate fingerprint fields but can be considered collectively.
Active parameters (JavaScript and Web API)
Screen resolution and color depth
Available via window.screen objects. Properties screen.width/height return current screen resolution (sometimes accounting for display scaling), and screen.colorDepth returns color depth (usually 24 or 32 bits). These parameters are frequently included in the fingerprint because they vary widely: everyone’s screen size differs. On desktops the browser window rarely matches maximum resolution, but a fingerprint usually takes the maximum available resolution of the user, which reflects their display size. For example, 1920×1080×24 (Full HD, 24-bit color) is one configuration, 1366×768×24 is another, etc. Each resolution combined with color depth can narrow down the device group. If the user changes monitor resolution or connects a new monitor, the fingerprint will change.
Language settings
A browser exposes several related settings: interface/OS language, preferred page language(s), and locale formats for dates/numbers. JS can get navigator.language (or navigator.languages for a list) — values like “ru-RU” or “en-US.” This usually matches what the server receives in Accept-Language. Locale affects formatting functions like Date.toString() (month names in Russian or English, etc.), which can also be used for fingerprinting.
Effect on uniqueness: combinations of languages and regions are quite variable. For example, a Russian-speaking user might have locale ru-RU, or uk-UA (if their OS is Ukrainian), or even en-US (if the interface is English). These nuances add a few bits of entropy. The number of unique language-combination permutations grows every year, but language alone is not extra unique: many people use popular locales. However, combined with other parameters, language helps distinguish, say, Chrome/Windows in Russian from Chrome/Windows in German, creating two different profiles.
Timezone (via JS)
A more accurate way to determine the timezone is to call a new Date().getTimezoneOffset() using JS. This returns the local time offset from UTC in minutes. For example, GMT+3 yields 180 minutes. You can also get the timezone name using Intl API. This parameter is almost always included in the fingerprint because it is stable for a device and varies geographically. Two users with identical parameters but different timezones already produce different fingerprints.
Note: some advanced fingerprinters track timezone changes: this can indicate that the same browser changed context (for instance, if the user traveled or changed clock settings). However, the current offset value is normally used for a simple fingerprint.
Information about the platform and CPU
The navigator object provides a number of properties related to the device platform:
navigator.platform— a string indicating the OS/architecture, for example Win32, Linux x86_64, iPhone, etc. This used to be a fairly telling parameter (distinguishing, for example, 32-bit Windows from 64-bit), but modern browsers may return truncated or unified values for privacy reasons. If the parameter is available, it is included in the fingerprint.navigator.hardwareConcurrency— the number of logical CPU threads (cores) on the device. For example, 8 (which may correspond to 4 physical cores with Hyper-Threading). This adds extra variability: mobile devices often have 4 or 8, desktops — 4, 8, 12, 16 and more cores. Not every browser reports an exact value, but under normal conditions this parameter is collected. An unusual thread count (e.g., 6 or 10) can immediately single out a device.navigator.deviceMemory— approximate RAM size in gigabytes (integer). Chrome rounds to 0.25 (a quarter) increments. For example, 8 GB givesdeviceMemory = 8. This signal is not supported in all browsers. Where present, it is included: RAM size is rarely a round number, so variability reduces overlaps.navigator.oscpu— a string with the operating system (Firefox-only API). In modern Firefox on Windows it returns something like Windows NT 10.0; Win64; x64. This parameter is rarely used because it duplicates information from the User-Agent.navigator.webdriver— a boolean indicating whether the browser is driven by automation (WebDriver). Iftrue, the site knows it’s dealing with a bot and may change behavior or factor this into the fingerprint. For fingerprinting this is less a “uniqueness” parameter and more a way to detect automation. Nevertheless,navigator.webdriver=trueclearly singles out the client (regular users have false), so indirectly it is part of the fingerprint.
Cookies/Storage enabled state
Scripts can check whether cookies are enabled in the browser (navigator.cookieEnabled). If the user has disabled them, this distinguishes them from the majority of other users (almost everyone keeps cookies enabled) and adds uniqueness.
List of browser plugins
navigator.plugins can return a list of installed NPAPI plugins: Acrobat Reader, Flash, Silverlight, etc., including their versions (navigator.plugins[i].name/version), although NPAPI plugins have largely disappeared (Flash and Java are disabled or removed from modern browsers). In Chrome navigator.plugins now contains only the built-in PDF Viewer; in Firefox, likewise, there is nothing extra. Still, the API exists and some browsers may still return something. The fingerprint may include plugin names and their count. An empty list is also a signal (for example, Firefox in Tor-mode has it empty, while a regular Firefox might include a built-in OpenH264 plugin). Overall the role of plugins as a factor is declining; extensions are gaining importance instead.
Installed extensions
Ideally websites shouldn’t know which extensions a user has, but in practice some extensions can be detected indirectly. AdBlock or Adblock Plus can be detected by blocked requests or specific DOM elements they introduce. A site may try to load a known URL filtered by AdBlock — if it doesn’t load, a blocker is likely present.
Another example: extensions can add special objects to window (e.g., React Developer Tools adds __REACT_DEVTOOLS_GLOBAL_HOOK__), and a script finding such an object recognizes the extension. Dozens of small checks can build a “snapshot” of the browser environment. The approximate number of extensions can sometimes be inferred from page response time. Each installed extension can slow page processing. In any case, presence of popular blockers, password managers, or niche extensions is partially detectable and increases profile uniqueness.
List of installed fonts
One of the most variable parameters. The set of system fonts depends on the OS, installed applications (Microsoft Office adds fonts, Adobe adds its own, etc.), and system language (Chinese fonts usually aren’t present for European users). How can a web page detect which fonts you have? Historically Flash (EnumerateFonts) was used, but without it there are purely browser-side methods:
Via CSS+JS: a hidden element is created with a font-family fallback list. If the first font isn’t installed, the text renders in the next font and the element’s width/height changes. JS can measure element dimensions to infer which font applied. Iterating hundreds of popular fonts reveals which are present. This method is time-consuming, so the following method is often used.
Via Canvas: drawing text in a specific font on a canvas and comparing the pixel raster lets you determine whether the font is installed. This is essentially a case of Canvas fingerprinting (see below).
The number of possible font-set combinations is huge, because few people have identical font lists, especially across different OS versions. A rare font (e.g., design-specific fonts) immediately makes the fingerprint unique, making font data incredibly useful for fingerprinting. Font collection is not instantaneous, so some scripts cache the fingerprint result.
Canvas Fingerprinting
This is a well-known fingerprinting method using the HTML5 <canvas> element to obtain unique rendering characteristics. The browser draws content (usually text with a specific font and colors, sometimes geometric shapes) on a virtual canvas, then the script calls canvas.toDataURL(), getting a bitmap of the rendered content. The image is represented as a base64 string, hashed to produce a Canvas fingerprint.
Why is it unique? Tiny differences in the system — font smoothing algorithms, GPU driver versions, platform (Linux vs Windows) — produce subtle variations in the final image. Typically text with diverse characters (letters of different shapes, special symbols) is drawn to maximize smoothing effects. Scripts may also draw colored rectangles, apply transforms or shadows to exercise graphics functions. Different devices yield different images from the same drawing code. A Canvas fingerprint can change after GPU driver updates or switching from integrated to discrete graphics. Combined with WebGL, however, it becomes extremely valuable.
WebGL Fingerprinting
WebGL is an API for rendering 3D graphics in the browser (essentially providing access to OpenGL/ES capabilities). It supplies two key types of data for fingerprinting:
Direct GPU identifiers
The WEBGL_debug_renderer_info extension allows a script to retrieve the UNMASKED_VENDOR_WEBGL and UNMASKED_RENDERER_WEBGL strings from the WebGL context — these typically list the manufacturer and model of the GPU (e.g., Intel Inc., Intel Iris Plus Graphics 640, or NVIDIA Corporation, GeForce GTX 1070). These values effectively reveal the user’s video card model. Most browsers allow this in standard mode (except Tor). The GPU model adds significant entropy: even if two users have the same operating system and browser, one with Intel HD Graphics and the other with an RTX 3080 will have distinct fingerprints.
WebGL constants and capabilities
Even without the direct GPU name, the WebGL context holds many parameters that depend on the driver and hardware: maximum texture units, geometry size limits, shadow and anti-aliasing support, and other numeric constants. A script can sequentially call gl.getParameter(...) for various constants and collect the results. For example, MAX_VERTEX_UNIFORM_VECTORS might be 4,096 on one card and 1,024 on another, etc. The result is a long vector of numbers, a sort of profile of the graphics subsystem. Such a profile is often unique to a device and can differ even between similar GPU models.
Additionally, WebGL can be used like Canvas: that is, by rendering a complex 3D scene and obtaining its raster image. This approach can reveal even subtler differences (for example, in shader implementations). In practice, libraries such as FingerprintJS usually limit themselves to reading UNMASKED_RENDERER (since it’s simpler and more reliable), but some scripts also hash a rendered 3D shape for greater stability. WebGL data greatly increase fingerprint uniqueness, especially on mobile devices: for instance, it used to be difficult to distinguish between iPhones (all had identical Canvas output due to identical GPUs), but now the GPU version can reveal the iPhone model if WebGL is enabled. Combined with Canvas, WebGL provides a powerful source of entropy. That’s why browsers in privacy-oriented modes try to hide or spoof this data.
AudioContext Fingerprinting
Another sophisticated fingerprinting method uses the Web Audio API to derive a unique audio fingerprint of the device. It’s based on the fact that audio generation and processing vary slightly across systems (due to library implementations, SIMD instruction usage, floating-point inaccuracies, etc.). In practice, AudioContext fingerprint values differ noticeably between browsers; each “browser + OS + hardware” combination produces its own deterministic result (as long as the browser or OS aren’t significantly changed). Adding an audio fingerprint further strengthens identification: even if Canvas and WebGL outputs coincidentally match, the audio fingerprint may still distinguish the devices.
Media devices and sensors
During fingerprinting, a script can also collect information about peripheral hardware:
Via
navigator.mediaDevices.enumerateDevices(), it can obtain a list of the user’s media devices (cameras, microphones). The browser usually returns limited data, for example, “two cameras and one microphone” without names or IDs unless permission is granted. Still, the number of devices alone can serve as a distinguishing factorAPIs such as Battery Status (battery charge level) were once available and also used for fingerprinting. Battery level and remaining time produced unique combinations. Because these APIs could yield overly precise identifiers (a privacy issue), they are now either restricted or permission-based.
Sensors (Orientation, Motion): the presence of certain sensors and the format of their output may vary across devices (e.g., gyroscope refresh rate). These are relatively exotic signals but they can still theoretically supplement a fingerprint.
Overall, the more non-standard the device, the more it reveals through such APIs. If a user has no camera or microphone at all, that already distinguishes them from most laptops, which almost always have webcams.
All of the above — both active and passive attributes — form a set of browser and system characteristics. In practice, scripts collect 10–30 parameters and compile them into a structure (e.g., an object or an array of strings), which is then converted into a hash. Many libraries use fast hashing algorithms such as MurmurHash to produce a compact identifier from roughly 500 bytes of attribute data. The result is a string (e.g., a3f6e9b12d4...) that can be stored on a server as the device ID.
Protection against browser fingerprinting
Modern browsers implement various countermeasures aimed at combating fingerprinting. For example, Tor Browser aims to make all users look identical (the same User-Agent, fixed window size, uniform font set, Canvas and AudioContext disabled, etc.). It even warns users not to maximize the window if they want to remain anonymous.
Firefox includes the privacy.resistFingerprinting setting, which similarly averages out values. Brave blocks third-party trackers by default and injects noise into APIs. There are extensions such as CanvasBlocker or Privacy Badger that selectively break tracking scripts.
However, no method offers 100% protection — too many parameters are exposed by browsers. In response to the growing demand for anonymity, anti-detect browsers (such as Octo Browser, MultiLogin, and Dolphin {anty}) have appeared, allowing users to emulate different fingerprints and create dozens of “virtual” identities with distinct parameters for, e.g., affiliate marketing purposes.
The race that began years ago continues: trackers develop new techniques, and browsers devise new countermeasures. The average user clearly loses this race — if one doesn’t actively care about privacy, any site can capture their digital fingerprint and correlate it with data from other sources.
A fingerprint consists of many components, each adding a degree of uniqueness. Hopefully, this breakdown helped you understand how exactly your browser can be identified by websites — because understanding how the technology works is the first step to knowing where the line lies between the convenience of personalization and the protection of personal data.
Stay up to date with the latest Octo Browser news
By clicking the button you agree to our Privacy Policy.
Stay up to date with the latest Octo Browser news
By clicking the button you agree to our Privacy Policy.
Stay up to date with the latest Octo Browser news
By clicking the button you agree to our Privacy Policy.

Join Octo Browser now
Or contact Customer Service at any time with any questions you might have.
Join Octo Browser now
Or contact Customer Service at any time with any questions you might have.
Join Octo Browser now
Or contact Customer Service at any time with any questions you might have.