Como identificar armadilhas de detecção de bots e evitá-las
27/02/2026


Markus_automation
Expert in data parsing and automation
A coleta automatizada de dados se tornou parte integrante de muitos projetos: monitoramento de preços, coleta de dados e análise de mídias sociais. No entanto, os proprietários de sites tentam proteger seus dados e reduzir a carga nos servidores, por isso não incentivam a coleta automatizada. Embora eles não possam simplesmente proibir a coleta de dados de seu site ou serviço, eles podem colocar armadilhas especiais que ajudam a determinar se um visitante é um humano ou um script. Neste artigo, examinamos as técnicas mais comuns que os sites usam para detectar bots, bem como métodos para identificar e contornar essas armadilhas.
Índice
Mantenha o anonimato, aproveite o recurso multiconta e alcance seus objetivos com o melhor navegador antidetecção do mercado.
A extração automatizada se tornou parte integrante de muitos projetos: monitoramento de preços, coleta de dados e análise de mídias sociais. No entanto, os proprietários de sites tentam proteger seus dados e reduzir a carga dos servidores, então eles não incentivam a extração. Embora eles não possam simplesmente proibir a extração de seu site ou serviço, eles podem colocar armadilhas especiais que ajudam a determinar se um visitante é humano ou um script. Neste artigo, examinamos as técnicas mais comuns que os sites usam para detectar bots, bem como métodos para identificar e contornar essas armadilhas.
Armadilhas de honeypot invisíveis: links e campos ocultos
Um dos truques mais comuns usados para capturar bots são os chamados campos honeypot — elementos de página especialmente preparados e ocultos. Uma pessoa real nunca os verá ou clicará neles, mas um bot simples pode.
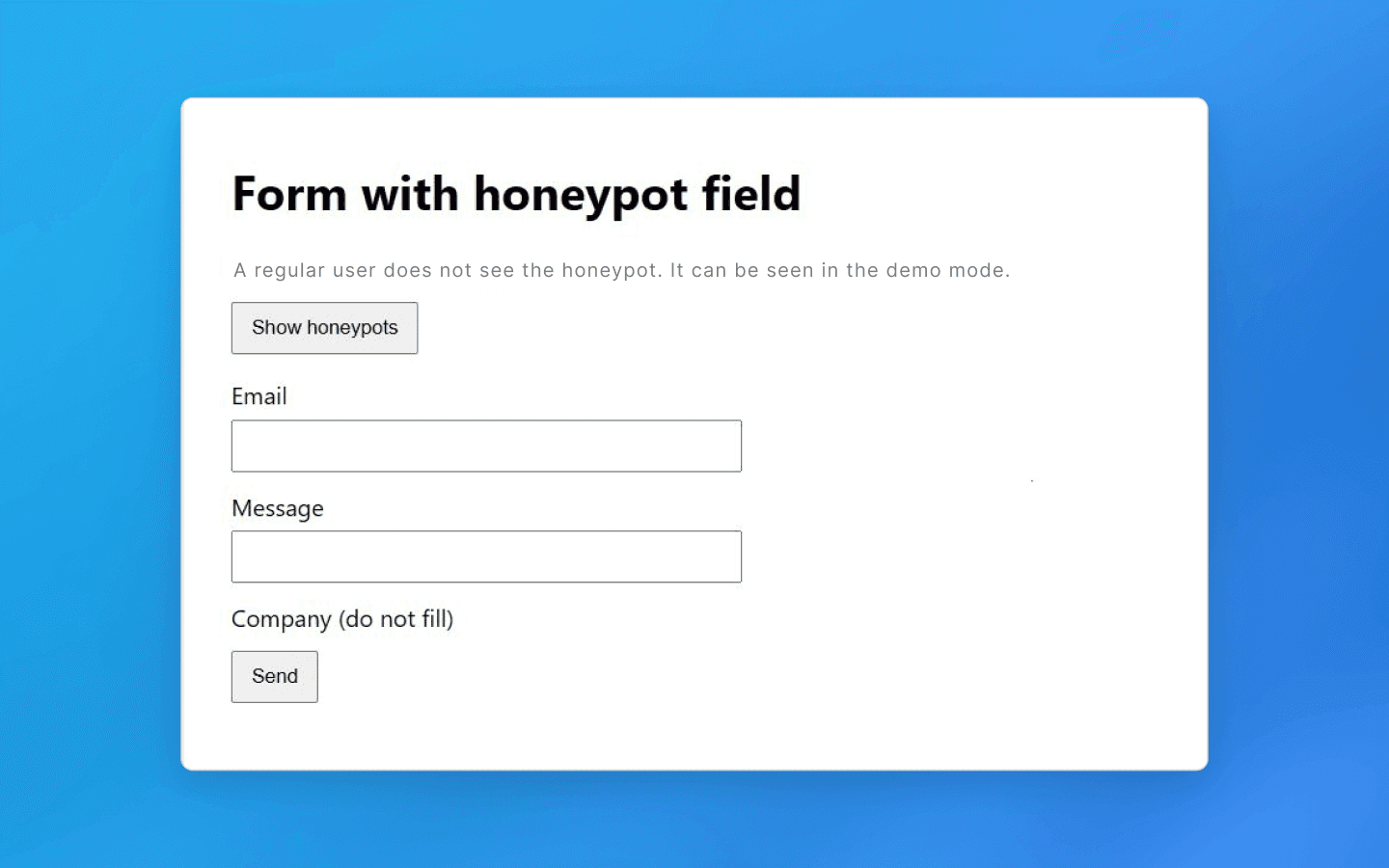
Um exemplo básico é um link invisível (criado usando estilos CSS como display: none ou posicionado fora da tela) que leva a um URL de armadilha especial. Um usuário normal não clicará em tal link porque ele nem sabe que existe, mas um scraper que rastreia sistematicamente todos os links o seguirá e se exporá. Assim que o script carregar essa página, o servidor pode adicionar seu endereço IP a uma lista negra e bloquear o acesso futuro.
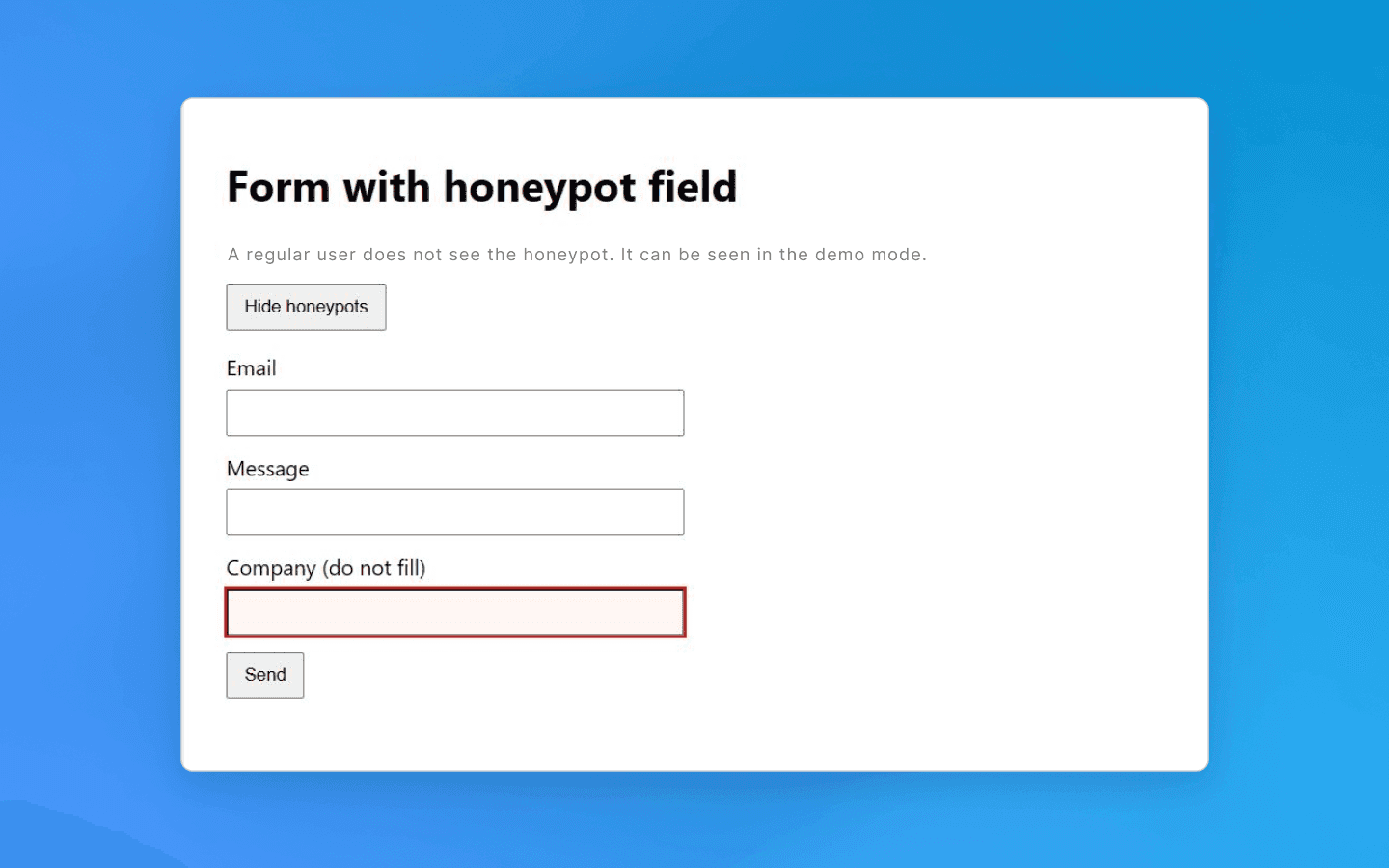
Uma ideia semelhante se aplica a formulários da web. Um campo oculto é adicionado a um formulário (por exemplo, um formulário de registro ou contato). Um humano não verá, mas um bot pode encontrá-lo e preenchê-lo. Tais campos honeypot sinalizam atividade de bot. Se um formulário enviado contiver texto em um campo oculto, isso é uma bandeira vermelha. A solicitação é rejeitada ou a sessão é sinalizada como tráfego de bot. Em ambos os casos, o trabalho futuro se torna impossível.
Como evitar: primeiro, ao rastrear páginas, analise as propriedades dos elementos antes de clicar ou navegar neles. Verifique os estilos dos links: se um link ou botão estiver marcado como invisível (display:none, opacity: 0, tamanho de 1×1 pixel, etc.), ignore-o. Da mesma forma, antes de enviar um formulário, certifique-se de não ter preenchido campos ocultos (eles podem ser identificados por nomes ou atributos incomuns, como aria-hidden, tabindex="-1", estilos ocultos, etc.). Iniciantes podem pensar que esses detalhes são insignificantes, mas essa é uma das maneiras mais fáceis de ser detectado. Um clique desnecessário em um link de armadilha é suficiente para expor seu bot.
Naturalmente, os proprietários de sites e serviços conhecem as contramedidas, e bots modernos já podem detectar elementos honeypot por características CSS suspeitas, por isso este método é frequentemente combinado com outras técnicas de proteção. Ainda assim, filtrar links e campos invisíveis é um requisito obrigatório para qualquer parser profissional.
CAPTCHAs e desafios de JavaScript
Uma maneira mais óbvia de impedir o acesso automatizado é a CAPTCHA, aqueles pop-ups irritantes com seleção de imagens, caixas de seleção "Eu não sou um robô" e variações semelhantes. Esta é uma maneira direta e eficaz de distinguir humanos de scripts ou bots. Ao contrário dos honeypots ocultos, as CAPTCHAs exigem explicitamente a conclusão de uma tarefa que se espera que um bot não consiga resolver. Na prática, CAPTCHAs simples podem ser contornadas relativamente facilmente, pois existem muitas soluções gratuitas de código aberto, enquanto as mais complexas exigem serviços de resolução de terceiros.
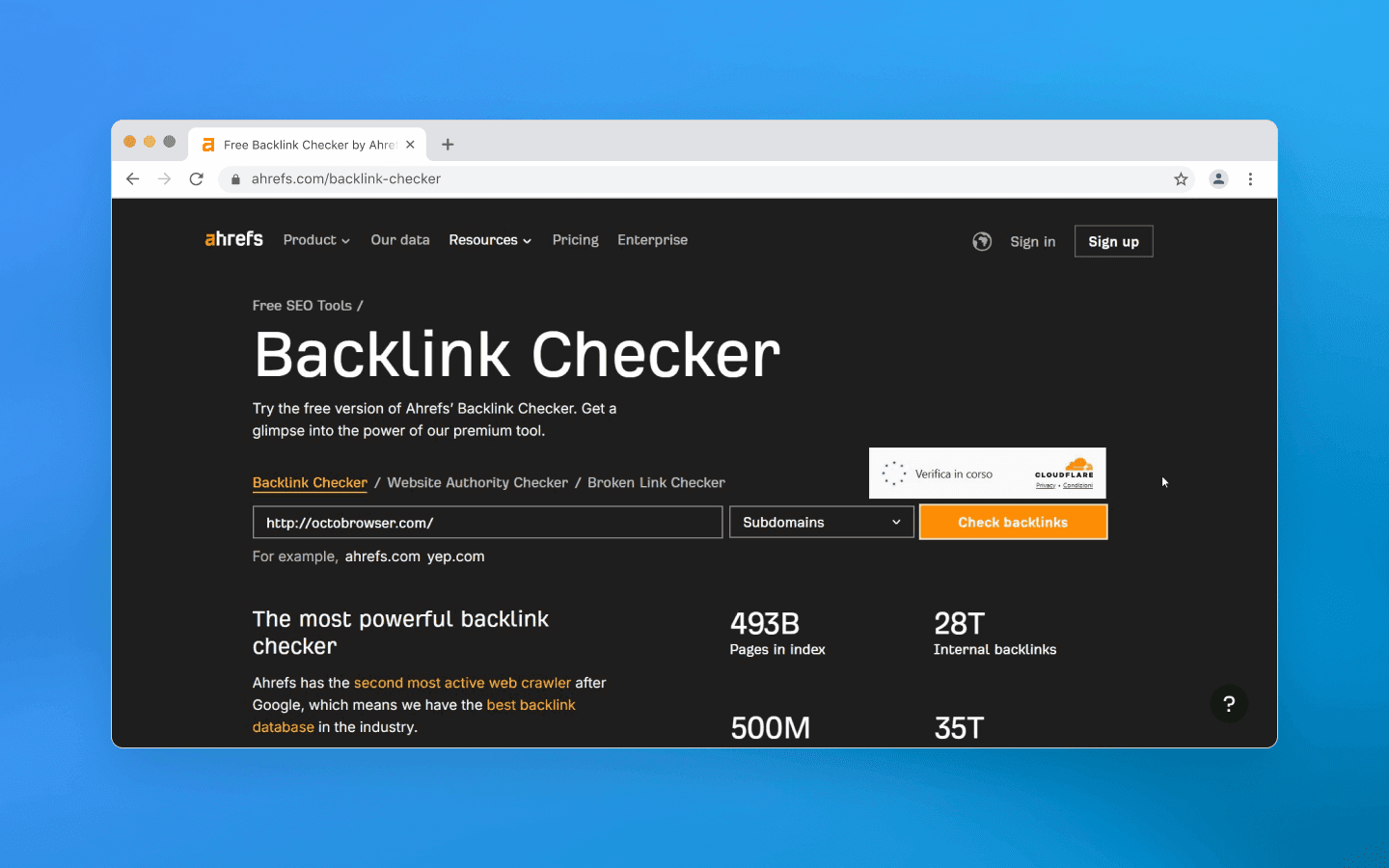
Se um bot encontrar uma CAPTCHA, há poucas opções: ou resolvê-la automaticamente por meio de um serviço de terceiros ou mudar a thread e alternar para outro perfil. A solução paga de CAPTCHAs retarda a extração e aumenta os custos. Outra estratégia é evitar acionar a CAPTCHA completamente — por exemplo, reduzindo a intensidade das solicitações para evitar ativar medidas de proteção ou usando caches de motores de busca (como o Google Cache) para obter dados.
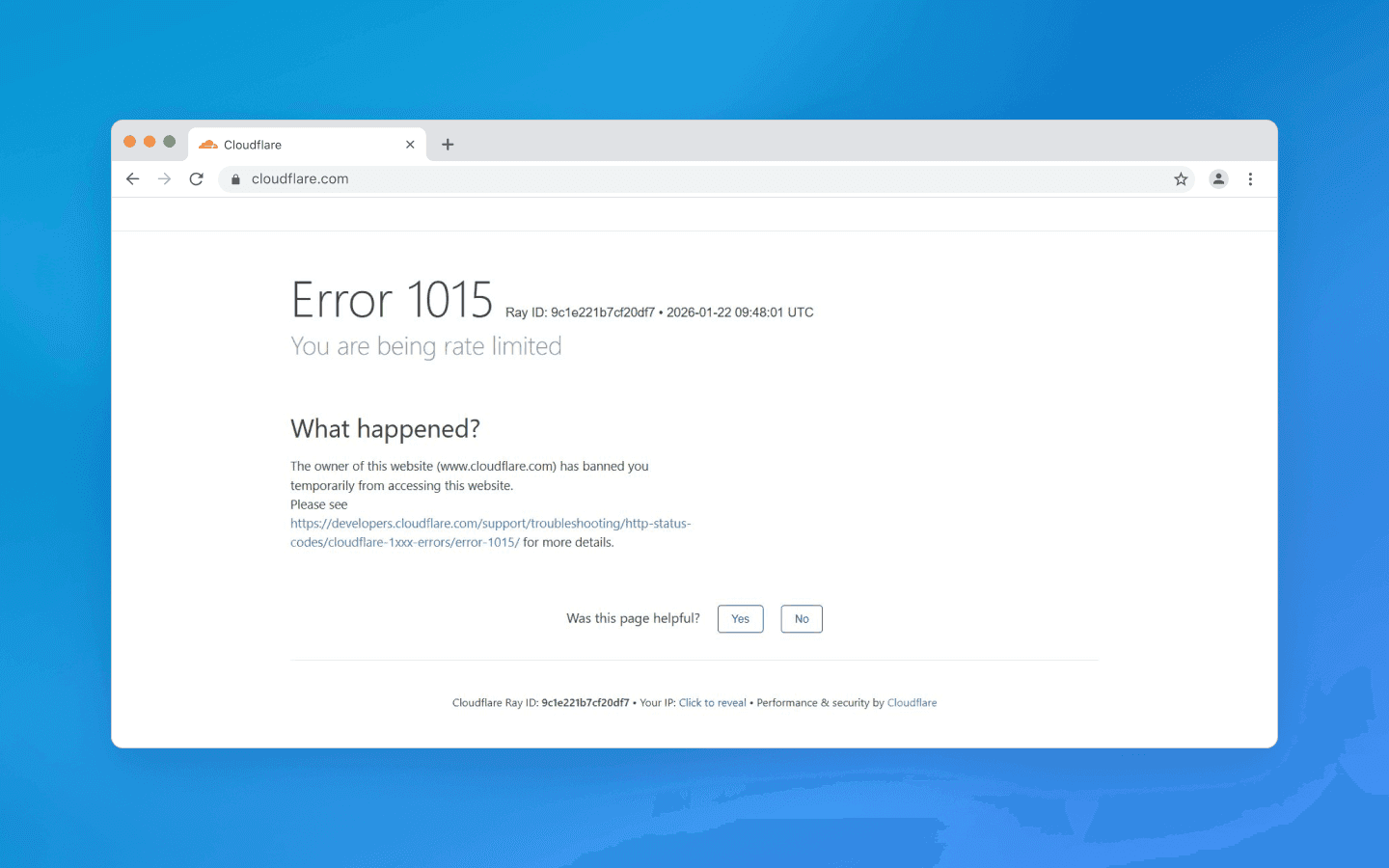
Uma categoria separada é o desafio de JavaScript. Muitos sites (especialmente aqueles protegidos por CDN, como o Cloudflare) podem retornar uma página de verificação em vez de conteúdo quando o tráfego parece suspeito. Esta página executa um código JS do lado do cliente que calcula um token, verifica o ambiente do navegador, configura cookies e só então redireciona o visitante para o conteúdo real. O objetivo é confirmar que a solicitação vem de um navegador real com suporte a JS, em vez de um cliente HTTP simples. Um bot que não consegue executar JavaScript falhará neste teste e não obterá acesso.
Como evitar: se você souber que um site-alvo exibe CAPTCHAs, decida antecipadamente como você as contornará, tanto tecnicamente quanto financeiramente. Se prevenir a CAPTCHA for impossível (alguns sites a exibem por padrão), você precisará integrar uma solução de resolução de terceiros. Para desafios de JS, a solução mais óbvia é usar um navegador sem interface que execute o cenário necessário. Ferramentas populares de automação (Puppeteer, Playwright, etc.) permitem executar um navegador em segundo plano, mas não se esqueça da falsificação, pois rastros de automação devem estar sempre ocultos.
Ignorar a verificação JS não é uma opção: se ela existir, você deve passá-la ou não obterá os dados. Certifique-se de que seu scraper carregue os scripts relacionados, os execute e armazene cookies ou tokens para solicitações subsequentes.
Análise comportamental: velocidade, sequência, interações
Mesmo se um bot contornar obstáculos diretos, como CAPTCHAs e outros métodos visíveis anti-bot, padrões de comportamento não humanos ainda podem ser fatais. Um usuário típico gasta vários segundos em uma página de produto, rola, clica nas imagens e depois navega adiante. Um script, no entanto, pode carregar páginas instantaneamente e em uma ordem perfeitamente repetível. Websites modernos rastreiam tais anomalias. Velocidades de navegação extremamente altas, intervalos regularmente suspeitos entre solicitações e padrões semelhantes indicam claramente automação.
Outro marcador é uma ordem de navegação incomum — por exemplo, rastrear URLs alfabeticamente ou seguir estritamente um mapa do site, algo que os visitantes reais raramente fazem. Um indicador simples é a ausência de interações similares às humanas. Se os logs mostrarem uma sessão visualizando 100 páginas sem uma única rolagem ou movimento do mouse, a sessão provavelmente é tráfego de bot.
Também existem armadilhas baseadas no tempo. Formulários podem exigir um tempo mínimo de preenchimento. A maioria dos humanos leva pelo menos 5–10 segundos para digitar credenciais, enquanto um bot pode enviá-las em milissegundos. Se um formulário for enviado quase instantaneamente, há uma alta probabilidade de automação, e o site pode rejeitar a solicitação. Uma abordagem semelhante se aplica à navegação: mover-se rapidamente demais para a próxima etapa — especialmente uma complexa, como pagamento — levanta suspeitas em sistemas anti-bot.
Como evitar: o principal princípio é imitar o comportamento de um usuário real. Introduza aleatoriedade e padrões naturais no fluxo de trabalho do seu scraper.
Primeiro, não tente atingir a velocidade máxima de extração. Se a velocidade não for crítica, trabalhar um pouco mais devagar, mas com mais cuidado, é mais seguro. Insira pausas entre as solicitações — não fixas, mas aleatórias dentro de um intervalo. Adicione atrasos em cada página para simular tempo de leitura.
Segundo, evite sequências de navegação rígidas. Se possível, introduza aleatoriedade na ordem de extração (por exemplo, altere a ordem das seções ou escolha aleatoriamente links em uma página em vez de iterar sequencialmente).
Terceiro, adicione sinais de interação natural em cenários sem interface. Pipelines avançados podem incluir rolagem, movimento do cursor, abertura de elementos da interface e pequenas micropausas entre etapas. Essas ações não afetam diretamente a coleta de dados, mas tornam o fluxo de trabalho mais semelhante ao humano, especialmente em páginas longas e fluxos em várias etapas (login → seleção → checkout), onde o tempo perfeitamente consistente parece não natural.
Também considere a perspectiva do site: muitos sistemas combinam análise comportamental com telemetria e análise da web. Rastreamentos em uma página podem registrar eventos de interação e tempo de sessão. Se os logs mostrarem uma sessão vazia sem sinais típicos, isso por si só parece suspeito. Portanto, é importante avaliar não apenas as ações do seu scraper, mas também quais dados de sessão estão realmente sendo gerados e como são interpretados no lado do monitoramento.
Taxa de solicitação e limites de volume
Outro critério óbvio usado para distinguir uma máquina de um humano é a frequência das solicitações. Mesmo o usuário mais rápido não consegue enviar dezenas de solicitações por segundo, mas um script pode. É por isso que limites do lado do servidor são implementados: por exemplo, não mais de N solicitações de um único endereço IP por minuto. Se o limite for excedido, um bloqueio temporário ou permanente é ativado. No nível do servidor web ou do CDN, isto é implementado rastreando o número de solicitações e filtrando picos que excedem o limite. Os números exatos dependem da política do site: em alguns lugares, 5 solicitações por segundo podem ser aceitáveis, enquanto em outros, até mesmo 1 solicitação por segundo será considerada excessiva. Isto é fácil de implementar: com Nginx, você pode configurar um limite de 1 solicitação por segundo por IP e rejeitar qualquer coisa acima disso.
Além da frequência, a concorrência também é monitorada. Um usuário comum é improvável que abra 20 páginas de um site simultaneamente em diferentes abas, enquanto um scraper pode facilmente gerar muitos threads paralelos. Isso também é monitorado: muitas sessões simultâneas de um endereço são motivo suficiente para suspeitar de um botnet ou scraper.
Como evitar: primeiro, limite o nível de concorrência em seu script. Sim, é tentador paralelizar a extração de um catálogo em 50 threads e coletar dados em um minuto, mas em 99% dos casos isso atrairá imediatamente atenção indesejada. É melhor trabalhar com alguns threads (ou até mesmo um) se você perceber que o site é sensível à carga.
Em segundo lugar, cuide da rotação do seu endereço IP. A maioria dos sites registra o IP de cada visitante e bloqueia o endereço inteiro quando uma atividade suspeita é detectada. É por isso que o uso de proxies é uma prática padrão para extração séria. Faz sentido usar rotação de IP: após um certo número de solicitações ou ao trocar de seções, altere o endereço do ponto de saída. Idealmente, sempre use proxies residenciais ou móveis. É importante configurar o scraper para que um único IP não faça muitas solicitações consecutivas. Por exemplo, envie no máximo 5–10 solicitações de um endereço e, em seguida, troque. Se o seu pool de proxies for limitado, pelo menos tente alterná-los e manter pausas.
Além disso, monitore sempre cabeçalhos de resposta e códigos de status para suas solicitações. Se você começar a receber HTTP 429 Too Many Requests ou ver algo como "Muitas solicitações, tente novamente mais tarde" no conteúdo da página, este é um sinal claro de que o limite de solicitações foi ativado. Tal situação requer reduzir a velocidade de extração, aumentar o número de proxies ou usar outras técnicas. Como opção, se o limite for definido por endereço IP e o site for acessível via HTTP e permitir alterar User-Agent e Referer sem verificações adicionais, rotacioná-los pode ajudar.
Em geral, a regra principal é não se destacar: quanto mais discretamente você se misturar ao tráfego de fundo dos usuários regulares, mais tempo seu scraper operará sem bloqueios.
Cabeçalhos e impressões digitais do navegador
Os sites podem detectar um scraper na fase de conexão analisando parâmetros técnicos da solicitação. Cada solicitação HTTP carrega um conjunto de cabeçalhos (User-Agent, Accept, Accept-Language, Cookie, etc.), que juntos formam um perfil de navegador. Para navegadores regulares, esses perfis são bastante previsíveis: por exemplo, ao visitar um site com o Chrome, você envia um conjunto característico de cabeçalhos começando com User-Agent: Mozilla/5.0 … Chrome/versão …, além de uma lista de idiomas suportados (Accept-Language), sinalizadores de busca (Sec-Fetch-* headers) e assim por diante. Um bot, no entanto, pode enviar um conjunto incomum ou incompleto de cabeçalhos. Muitos sites bloqueiam solicitações imediatamente com strings User-Agent suspeitas, como Scrapy, curl, Wget, Python e semelhantes, no nível do firewall. E mesmo que você não seja bloqueado por enviar tais strings, o fato em si será considerado como parte da pontuação de risco geral.
Ao substituir o User-Agent por uma string de um navegador comum, você ainda pode falhar em detalhes. Por exemplo, o Chrome sem interface costumava se revelar porque a string User-Agent continha a palavra HeadlessChrome. Outro exemplo: o bot não envia o cabeçalho Accept-Language (navegadores reais sempre enviam preferências de idioma).
Outro indicador: a ordem dos cabeçalhos ou seus valores não corresponde ao navegador declarado. Os sistemas anti-bot mantêm grandes bancos de dados de impressões digitais de navegadores — modelos com diferentes cabeçalhos e valores de diferentes versões do Chrome, Safari e Firefox. Se você finge ser o Chrome 120+ e envia o User-Agent correspondente, mas não inclui cabeçalhos típicos de dicas de cliente UA moderno de Chromium (Sec-CH-UA, Sec-CH-UA-Mobile, Sec-CH-UA-Platform), ou eles estão no formato errado, ou uma solicitação de navegação acionada por um clique do usuário não inclui Sec-Fetch-User: ?1 enquanto outros Sec-Fetch-* cabeçalhos estão presentes, essas pequenas inconsistências podem revelar automação (isso é apenas um exemplo ilustrativo).
Além disso, além dos cabeçalhos HTTP, o navegador pode se revelar através do objeto navigator e do ambiente JS. Modos sem interface geralmente incluem uma propriedade navigator.webdriver, que normalmente é true para navegadores automatizados. Os sites então podem executar um pequeno script do lado do cliente: if (navigator.webdriver) { /* Bot detectado */ } — e esta abordagem simples é boa o suficiente para pegar iniciantes. Outros verificam objetos específicos deixados pelo Selenium ou Playwright. Por exemplo, o Playwright insere certas variáveis de serviço no window (__playwright__binding__ e outras), e scripts na página podem procurar por esses sinais de controle externo.
Verificações mais avançadas incluem testes da API de Canvas ou WebGL, onde uma imagem oculta é renderizada e uma impressão digital de canvas é coletada que pode corresponder a uma assinatura típica de emulador.
Em resumo, existem muitas verificações disponíveis para sites, e a falsificação do ambiente pode ser detectada mesmo através de pequenas discrepâncias na implementação do JS.
Como evitar: disfarce-se o máximo possível como um dispositivo/navegador real. Sempre defina um User-Agent realista correspondente a um navegador popular e mantenha-o atualizado. Mas um cabeçalho não é suficiente: ajuste os outros também. Adicione Accept-Language (levando em consideração a região do IP), Accept com tipos de conteúdo típicos para um navegador comum, Connection, Upgrade-Insecure-Requests, cabeçalhos Sec-Fetch-* e assim por diante. A maneira mais fácil é verificar quais cabeçalhos seu navegador envia ao visitar o site-alvo (através das ferramentas do desenvolvedor ou de um proxy) e emulá-los. Preste atenção à consistência: se você alega ser o Chrome no Windows, você deve ter um User-Agent orientado para Windows e, quando necessário, um cabeçalho Sec-CH-UA-Platform: "Windows".
Se você trabalha com um navegador sem interface, use bibliotecas ou configurações que habilitem automaticamente a máscara de automação (por exemplo, o Puppeteer tem o pacote puppeteer-extra-plugin-stealth, que desativa navigator.webdriver e outros marcadores reveladores, ou versões corrigidas do playwright/puppeteer do rebrowser que ocultam muitas fraquezas padrão de tais bibliotecas). Se você está criando um scraper em baixo nível, modifique manualmente navigator via DevTools Protocol para definir propriedades que correspondam a um navegador real.
Claro, não é necessário emular absolutamente tudo até o ruído aleatório do Canvas. A melhor prática é começar com o básico — cabeçalhos e JS simples. Não envie strings obviamente suspeitas, atualize regularmente os modelos de cabeçalho para corresponder aos navegadores atuais, habilite a emulação de interações menores e, se possível, teste seu bot contra ferramentas de anti-detecção. Ferramentas como BrowserScan ou FingerprintJS podem mostrar quais sinais seu script expõe.
Outros truques: de “labirintos infinitos” a serviços de terceiros
Além do exposto, existem armadilhas mais exóticas que vale a pena conhecer. Alguns recursos deliberadamente criam estruturas de links “infinitas” — uma espécie de labirinto para um scraper.
Um exemplo clássico são páginas de calendário infinitas geradas dinamicamente ou URLs parametrizados que levam a loops. Um bot sem condições adequadas de parada pode ficar preso tentando percorrer um fluxo interminável de links. Por consequência, desperdiça seus recursos e também se revela para sistemas anti-bot através de comportamento incomum. Para usuários reais, esses links geralmente são inacessíveis, mas um bot pode cair em tal armadilha.
Como evitar: primeiro, sempre analise os dados coletados quanto à plausibilidade. Se seu scraper de repente seguiu uma cadeia de links em algum lugar onde não deveria ir e baixou toneladas de textos que parecem frases aleatórias, você pode ter entrado em um labirinto. É útil implementar lógica de detecção de loops: rastrear URLs visitados, limitar profundidade de rastreamento, verificar se novos links pertencem ao mesmo domínio ou seção de que você precisa.
Em segundo lugar, sempre considere o contexto: se você extrai, por exemplo, um site de avaliação e o bot de repente começa a baixar páginas com texto claramente não relacionado ou incoerente gerado por IA, isso é um motivo para ter cautela e encerrar essa sessão.
Além disso, lembre-se de que serviços de terceiros também ajudam sites a detectar bots. Produtos como Cloudflare Bot Management, Datadome, PerimeterX e outros se especializam em detectar tráfego automatizado. Eles usam uma combinação de métodos que vão desde análise comportamental e impressão digital até bancos de dados de bots conhecidos e até aprendizado de máquina para identificar visitantes incomuns.
Se seu bot encontrar um sistema poderoso anti-bot, a tarefa se torna mais complexa, pois a detecção pode ocorrer com base em uma combinação de pequenos sinais. Em tais casos, tudo o que foi discutido acima se aplica, e você também precisa levar em conta melhorias constantes de regras no lado escavado. Às vezes, torna-se mais barato mudar táticas de extração ou limitar o volume de solicitações a um nível que não acione os sistemas de proteção. Ao usar proxies, você pode tentar imitar diferentes usuários reais e mudar não apenas o endereço IP, mas também a geolocalização, user agents e tempo de solicitação (imitando visitas em diferentes horas do dia em vez de atividade contínua ininterrupta).
Conclusão
Como você pode ver, não há um botão mágico que elimine permanentemente o risco de bloqueio. Você precisa de uma combinação de métodos técnicos e uma execução cuidadosa para uma extração bem-sucedida:
Detecte e ignore elementos honeypot: antes de clicar em um link ou preencher um campo, certifique-se de que o elemento não está oculto da vista humana. Não siga URLs suspeitos e não preencha campos de formulário invisíveis.
Imite um usuário real: use cabeçalhos reais e valores típicos de navegadores normais (User-Agent, Accept-Language, etc.). Sempre que possível, execute a extração através do kernel do navegador de navegadores antidetecção para passar nas verificações de JS e garantir um ambiente realista (navigator, cookies, localStorage, etc.).
Limite a velocidade e a concorrência: configure atrasos e pausas entre as solicitações, use intervalos aleatórios. Não exceda os limites de solicitação, escale gradualmente e monitore as reações do site (códigos HTTP 429, CAPTCHAs e assim por diante).
Gire endereços IP e identificadores de sessão: use um pool de proxies ou VPN, alterne IPs, especialmente para extração em larga escala. Garanta que um único IP não seja usado com muita frequência. Sempre opte por IPs residenciais, pois são menos suspeitos para os sistemas anti-bot.
Introduza aleatoriedade no seu comportamento de extração: emule ações do usuário, por exemplo, pequenas rolagens, movimentos do mouse, tempo gasto lendo uma página. Evite rotas totalmente sequenciais e varie padrões de ação para não demonstrar um algoritmo rígido.
A confrontação na extração da web continua, à medida que os sites inventam novos métodos de detecção e os desenvolvedores de bots procuram formas de contorná-los. Neste jogo, o vencedor é aquele que é mais atento e inventivo. Que seu bot seja exatamente isso: cuidadoso, flexível e humanamente imprevisível.
Mantenha o anonimato, aproveite o recurso multiconta e alcance seus objetivos com o melhor navegador antidetecção do mercado.
A extração automatizada se tornou parte integrante de muitos projetos: monitoramento de preços, coleta de dados e análise de mídias sociais. No entanto, os proprietários de sites tentam proteger seus dados e reduzir a carga dos servidores, então eles não incentivam a extração. Embora eles não possam simplesmente proibir a extração de seu site ou serviço, eles podem colocar armadilhas especiais que ajudam a determinar se um visitante é humano ou um script. Neste artigo, examinamos as técnicas mais comuns que os sites usam para detectar bots, bem como métodos para identificar e contornar essas armadilhas.
Armadilhas de honeypot invisíveis: links e campos ocultos
Um dos truques mais comuns usados para capturar bots são os chamados campos honeypot — elementos de página especialmente preparados e ocultos. Uma pessoa real nunca os verá ou clicará neles, mas um bot simples pode.
Um exemplo básico é um link invisível (criado usando estilos CSS como display: none ou posicionado fora da tela) que leva a um URL de armadilha especial. Um usuário normal não clicará em tal link porque ele nem sabe que existe, mas um scraper que rastreia sistematicamente todos os links o seguirá e se exporá. Assim que o script carregar essa página, o servidor pode adicionar seu endereço IP a uma lista negra e bloquear o acesso futuro.
Uma ideia semelhante se aplica a formulários da web. Um campo oculto é adicionado a um formulário (por exemplo, um formulário de registro ou contato). Um humano não verá, mas um bot pode encontrá-lo e preenchê-lo. Tais campos honeypot sinalizam atividade de bot. Se um formulário enviado contiver texto em um campo oculto, isso é uma bandeira vermelha. A solicitação é rejeitada ou a sessão é sinalizada como tráfego de bot. Em ambos os casos, o trabalho futuro se torna impossível.
Como evitar: primeiro, ao rastrear páginas, analise as propriedades dos elementos antes de clicar ou navegar neles. Verifique os estilos dos links: se um link ou botão estiver marcado como invisível (display:none, opacity: 0, tamanho de 1×1 pixel, etc.), ignore-o. Da mesma forma, antes de enviar um formulário, certifique-se de não ter preenchido campos ocultos (eles podem ser identificados por nomes ou atributos incomuns, como aria-hidden, tabindex="-1", estilos ocultos, etc.). Iniciantes podem pensar que esses detalhes são insignificantes, mas essa é uma das maneiras mais fáceis de ser detectado. Um clique desnecessário em um link de armadilha é suficiente para expor seu bot.
Naturalmente, os proprietários de sites e serviços conhecem as contramedidas, e bots modernos já podem detectar elementos honeypot por características CSS suspeitas, por isso este método é frequentemente combinado com outras técnicas de proteção. Ainda assim, filtrar links e campos invisíveis é um requisito obrigatório para qualquer parser profissional.
CAPTCHAs e desafios de JavaScript
Uma maneira mais óbvia de impedir o acesso automatizado é a CAPTCHA, aqueles pop-ups irritantes com seleção de imagens, caixas de seleção "Eu não sou um robô" e variações semelhantes. Esta é uma maneira direta e eficaz de distinguir humanos de scripts ou bots. Ao contrário dos honeypots ocultos, as CAPTCHAs exigem explicitamente a conclusão de uma tarefa que se espera que um bot não consiga resolver. Na prática, CAPTCHAs simples podem ser contornadas relativamente facilmente, pois existem muitas soluções gratuitas de código aberto, enquanto as mais complexas exigem serviços de resolução de terceiros.
Se um bot encontrar uma CAPTCHA, há poucas opções: ou resolvê-la automaticamente por meio de um serviço de terceiros ou mudar a thread e alternar para outro perfil. A solução paga de CAPTCHAs retarda a extração e aumenta os custos. Outra estratégia é evitar acionar a CAPTCHA completamente — por exemplo, reduzindo a intensidade das solicitações para evitar ativar medidas de proteção ou usando caches de motores de busca (como o Google Cache) para obter dados.
Uma categoria separada é o desafio de JavaScript. Muitos sites (especialmente aqueles protegidos por CDN, como o Cloudflare) podem retornar uma página de verificação em vez de conteúdo quando o tráfego parece suspeito. Esta página executa um código JS do lado do cliente que calcula um token, verifica o ambiente do navegador, configura cookies e só então redireciona o visitante para o conteúdo real. O objetivo é confirmar que a solicitação vem de um navegador real com suporte a JS, em vez de um cliente HTTP simples. Um bot que não consegue executar JavaScript falhará neste teste e não obterá acesso.
Como evitar: se você souber que um site-alvo exibe CAPTCHAs, decida antecipadamente como você as contornará, tanto tecnicamente quanto financeiramente. Se prevenir a CAPTCHA for impossível (alguns sites a exibem por padrão), você precisará integrar uma solução de resolução de terceiros. Para desafios de JS, a solução mais óbvia é usar um navegador sem interface que execute o cenário necessário. Ferramentas populares de automação (Puppeteer, Playwright, etc.) permitem executar um navegador em segundo plano, mas não se esqueça da falsificação, pois rastros de automação devem estar sempre ocultos.
Ignorar a verificação JS não é uma opção: se ela existir, você deve passá-la ou não obterá os dados. Certifique-se de que seu scraper carregue os scripts relacionados, os execute e armazene cookies ou tokens para solicitações subsequentes.
Análise comportamental: velocidade, sequência, interações
Mesmo se um bot contornar obstáculos diretos, como CAPTCHAs e outros métodos visíveis anti-bot, padrões de comportamento não humanos ainda podem ser fatais. Um usuário típico gasta vários segundos em uma página de produto, rola, clica nas imagens e depois navega adiante. Um script, no entanto, pode carregar páginas instantaneamente e em uma ordem perfeitamente repetível. Websites modernos rastreiam tais anomalias. Velocidades de navegação extremamente altas, intervalos regularmente suspeitos entre solicitações e padrões semelhantes indicam claramente automação.
Outro marcador é uma ordem de navegação incomum — por exemplo, rastrear URLs alfabeticamente ou seguir estritamente um mapa do site, algo que os visitantes reais raramente fazem. Um indicador simples é a ausência de interações similares às humanas. Se os logs mostrarem uma sessão visualizando 100 páginas sem uma única rolagem ou movimento do mouse, a sessão provavelmente é tráfego de bot.
Também existem armadilhas baseadas no tempo. Formulários podem exigir um tempo mínimo de preenchimento. A maioria dos humanos leva pelo menos 5–10 segundos para digitar credenciais, enquanto um bot pode enviá-las em milissegundos. Se um formulário for enviado quase instantaneamente, há uma alta probabilidade de automação, e o site pode rejeitar a solicitação. Uma abordagem semelhante se aplica à navegação: mover-se rapidamente demais para a próxima etapa — especialmente uma complexa, como pagamento — levanta suspeitas em sistemas anti-bot.
Como evitar: o principal princípio é imitar o comportamento de um usuário real. Introduza aleatoriedade e padrões naturais no fluxo de trabalho do seu scraper.
Primeiro, não tente atingir a velocidade máxima de extração. Se a velocidade não for crítica, trabalhar um pouco mais devagar, mas com mais cuidado, é mais seguro. Insira pausas entre as solicitações — não fixas, mas aleatórias dentro de um intervalo. Adicione atrasos em cada página para simular tempo de leitura.
Segundo, evite sequências de navegação rígidas. Se possível, introduza aleatoriedade na ordem de extração (por exemplo, altere a ordem das seções ou escolha aleatoriamente links em uma página em vez de iterar sequencialmente).
Terceiro, adicione sinais de interação natural em cenários sem interface. Pipelines avançados podem incluir rolagem, movimento do cursor, abertura de elementos da interface e pequenas micropausas entre etapas. Essas ações não afetam diretamente a coleta de dados, mas tornam o fluxo de trabalho mais semelhante ao humano, especialmente em páginas longas e fluxos em várias etapas (login → seleção → checkout), onde o tempo perfeitamente consistente parece não natural.
Também considere a perspectiva do site: muitos sistemas combinam análise comportamental com telemetria e análise da web. Rastreamentos em uma página podem registrar eventos de interação e tempo de sessão. Se os logs mostrarem uma sessão vazia sem sinais típicos, isso por si só parece suspeito. Portanto, é importante avaliar não apenas as ações do seu scraper, mas também quais dados de sessão estão realmente sendo gerados e como são interpretados no lado do monitoramento.
Taxa de solicitação e limites de volume
Outro critério óbvio usado para distinguir uma máquina de um humano é a frequência das solicitações. Mesmo o usuário mais rápido não consegue enviar dezenas de solicitações por segundo, mas um script pode. É por isso que limites do lado do servidor são implementados: por exemplo, não mais de N solicitações de um único endereço IP por minuto. Se o limite for excedido, um bloqueio temporário ou permanente é ativado. No nível do servidor web ou do CDN, isto é implementado rastreando o número de solicitações e filtrando picos que excedem o limite. Os números exatos dependem da política do site: em alguns lugares, 5 solicitações por segundo podem ser aceitáveis, enquanto em outros, até mesmo 1 solicitação por segundo será considerada excessiva. Isto é fácil de implementar: com Nginx, você pode configurar um limite de 1 solicitação por segundo por IP e rejeitar qualquer coisa acima disso.
Além da frequência, a concorrência também é monitorada. Um usuário comum é improvável que abra 20 páginas de um site simultaneamente em diferentes abas, enquanto um scraper pode facilmente gerar muitos threads paralelos. Isso também é monitorado: muitas sessões simultâneas de um endereço são motivo suficiente para suspeitar de um botnet ou scraper.
Como evitar: primeiro, limite o nível de concorrência em seu script. Sim, é tentador paralelizar a extração de um catálogo em 50 threads e coletar dados em um minuto, mas em 99% dos casos isso atrairá imediatamente atenção indesejada. É melhor trabalhar com alguns threads (ou até mesmo um) se você perceber que o site é sensível à carga.
Em segundo lugar, cuide da rotação do seu endereço IP. A maioria dos sites registra o IP de cada visitante e bloqueia o endereço inteiro quando uma atividade suspeita é detectada. É por isso que o uso de proxies é uma prática padrão para extração séria. Faz sentido usar rotação de IP: após um certo número de solicitações ou ao trocar de seções, altere o endereço do ponto de saída. Idealmente, sempre use proxies residenciais ou móveis. É importante configurar o scraper para que um único IP não faça muitas solicitações consecutivas. Por exemplo, envie no máximo 5–10 solicitações de um endereço e, em seguida, troque. Se o seu pool de proxies for limitado, pelo menos tente alterná-los e manter pausas.
Além disso, monitore sempre cabeçalhos de resposta e códigos de status para suas solicitações. Se você começar a receber HTTP 429 Too Many Requests ou ver algo como "Muitas solicitações, tente novamente mais tarde" no conteúdo da página, este é um sinal claro de que o limite de solicitações foi ativado. Tal situação requer reduzir a velocidade de extração, aumentar o número de proxies ou usar outras técnicas. Como opção, se o limite for definido por endereço IP e o site for acessível via HTTP e permitir alterar User-Agent e Referer sem verificações adicionais, rotacioná-los pode ajudar.
Em geral, a regra principal é não se destacar: quanto mais discretamente você se misturar ao tráfego de fundo dos usuários regulares, mais tempo seu scraper operará sem bloqueios.
Cabeçalhos e impressões digitais do navegador
Os sites podem detectar um scraper na fase de conexão analisando parâmetros técnicos da solicitação. Cada solicitação HTTP carrega um conjunto de cabeçalhos (User-Agent, Accept, Accept-Language, Cookie, etc.), que juntos formam um perfil de navegador. Para navegadores regulares, esses perfis são bastante previsíveis: por exemplo, ao visitar um site com o Chrome, você envia um conjunto característico de cabeçalhos começando com User-Agent: Mozilla/5.0 … Chrome/versão …, além de uma lista de idiomas suportados (Accept-Language), sinalizadores de busca (Sec-Fetch-* headers) e assim por diante. Um bot, no entanto, pode enviar um conjunto incomum ou incompleto de cabeçalhos. Muitos sites bloqueiam solicitações imediatamente com strings User-Agent suspeitas, como Scrapy, curl, Wget, Python e semelhantes, no nível do firewall. E mesmo que você não seja bloqueado por enviar tais strings, o fato em si será considerado como parte da pontuação de risco geral.
Ao substituir o User-Agent por uma string de um navegador comum, você ainda pode falhar em detalhes. Por exemplo, o Chrome sem interface costumava se revelar porque a string User-Agent continha a palavra HeadlessChrome. Outro exemplo: o bot não envia o cabeçalho Accept-Language (navegadores reais sempre enviam preferências de idioma).
Outro indicador: a ordem dos cabeçalhos ou seus valores não corresponde ao navegador declarado. Os sistemas anti-bot mantêm grandes bancos de dados de impressões digitais de navegadores — modelos com diferentes cabeçalhos e valores de diferentes versões do Chrome, Safari e Firefox. Se você finge ser o Chrome 120+ e envia o User-Agent correspondente, mas não inclui cabeçalhos típicos de dicas de cliente UA moderno de Chromium (Sec-CH-UA, Sec-CH-UA-Mobile, Sec-CH-UA-Platform), ou eles estão no formato errado, ou uma solicitação de navegação acionada por um clique do usuário não inclui Sec-Fetch-User: ?1 enquanto outros Sec-Fetch-* cabeçalhos estão presentes, essas pequenas inconsistências podem revelar automação (isso é apenas um exemplo ilustrativo).
Além disso, além dos cabeçalhos HTTP, o navegador pode se revelar através do objeto navigator e do ambiente JS. Modos sem interface geralmente incluem uma propriedade navigator.webdriver, que normalmente é true para navegadores automatizados. Os sites então podem executar um pequeno script do lado do cliente: if (navigator.webdriver) { /* Bot detectado */ } — e esta abordagem simples é boa o suficiente para pegar iniciantes. Outros verificam objetos específicos deixados pelo Selenium ou Playwright. Por exemplo, o Playwright insere certas variáveis de serviço no window (__playwright__binding__ e outras), e scripts na página podem procurar por esses sinais de controle externo.
Verificações mais avançadas incluem testes da API de Canvas ou WebGL, onde uma imagem oculta é renderizada e uma impressão digital de canvas é coletada que pode corresponder a uma assinatura típica de emulador.
Em resumo, existem muitas verificações disponíveis para sites, e a falsificação do ambiente pode ser detectada mesmo através de pequenas discrepâncias na implementação do JS.
Como evitar: disfarce-se o máximo possível como um dispositivo/navegador real. Sempre defina um User-Agent realista correspondente a um navegador popular e mantenha-o atualizado. Mas um cabeçalho não é suficiente: ajuste os outros também. Adicione Accept-Language (levando em consideração a região do IP), Accept com tipos de conteúdo típicos para um navegador comum, Connection, Upgrade-Insecure-Requests, cabeçalhos Sec-Fetch-* e assim por diante. A maneira mais fácil é verificar quais cabeçalhos seu navegador envia ao visitar o site-alvo (através das ferramentas do desenvolvedor ou de um proxy) e emulá-los. Preste atenção à consistência: se você alega ser o Chrome no Windows, você deve ter um User-Agent orientado para Windows e, quando necessário, um cabeçalho Sec-CH-UA-Platform: "Windows".
Se você trabalha com um navegador sem interface, use bibliotecas ou configurações que habilitem automaticamente a máscara de automação (por exemplo, o Puppeteer tem o pacote puppeteer-extra-plugin-stealth, que desativa navigator.webdriver e outros marcadores reveladores, ou versões corrigidas do playwright/puppeteer do rebrowser que ocultam muitas fraquezas padrão de tais bibliotecas). Se você está criando um scraper em baixo nível, modifique manualmente navigator via DevTools Protocol para definir propriedades que correspondam a um navegador real.
Claro, não é necessário emular absolutamente tudo até o ruído aleatório do Canvas. A melhor prática é começar com o básico — cabeçalhos e JS simples. Não envie strings obviamente suspeitas, atualize regularmente os modelos de cabeçalho para corresponder aos navegadores atuais, habilite a emulação de interações menores e, se possível, teste seu bot contra ferramentas de anti-detecção. Ferramentas como BrowserScan ou FingerprintJS podem mostrar quais sinais seu script expõe.
Outros truques: de “labirintos infinitos” a serviços de terceiros
Além do exposto, existem armadilhas mais exóticas que vale a pena conhecer. Alguns recursos deliberadamente criam estruturas de links “infinitas” — uma espécie de labirinto para um scraper.
Um exemplo clássico são páginas de calendário infinitas geradas dinamicamente ou URLs parametrizados que levam a loops. Um bot sem condições adequadas de parada pode ficar preso tentando percorrer um fluxo interminável de links. Por consequência, desperdiça seus recursos e também se revela para sistemas anti-bot através de comportamento incomum. Para usuários reais, esses links geralmente são inacessíveis, mas um bot pode cair em tal armadilha.
Como evitar: primeiro, sempre analise os dados coletados quanto à plausibilidade. Se seu scraper de repente seguiu uma cadeia de links em algum lugar onde não deveria ir e baixou toneladas de textos que parecem frases aleatórias, você pode ter entrado em um labirinto. É útil implementar lógica de detecção de loops: rastrear URLs visitados, limitar profundidade de rastreamento, verificar se novos links pertencem ao mesmo domínio ou seção de que você precisa.
Em segundo lugar, sempre considere o contexto: se você extrai, por exemplo, um site de avaliação e o bot de repente começa a baixar páginas com texto claramente não relacionado ou incoerente gerado por IA, isso é um motivo para ter cautela e encerrar essa sessão.
Além disso, lembre-se de que serviços de terceiros também ajudam sites a detectar bots. Produtos como Cloudflare Bot Management, Datadome, PerimeterX e outros se especializam em detectar tráfego automatizado. Eles usam uma combinação de métodos que vão desde análise comportamental e impressão digital até bancos de dados de bots conhecidos e até aprendizado de máquina para identificar visitantes incomuns.
Se seu bot encontrar um sistema poderoso anti-bot, a tarefa se torna mais complexa, pois a detecção pode ocorrer com base em uma combinação de pequenos sinais. Em tais casos, tudo o que foi discutido acima se aplica, e você também precisa levar em conta melhorias constantes de regras no lado escavado. Às vezes, torna-se mais barato mudar táticas de extração ou limitar o volume de solicitações a um nível que não acione os sistemas de proteção. Ao usar proxies, você pode tentar imitar diferentes usuários reais e mudar não apenas o endereço IP, mas também a geolocalização, user agents e tempo de solicitação (imitando visitas em diferentes horas do dia em vez de atividade contínua ininterrupta).
Conclusão
Como você pode ver, não há um botão mágico que elimine permanentemente o risco de bloqueio. Você precisa de uma combinação de métodos técnicos e uma execução cuidadosa para uma extração bem-sucedida:
Detecte e ignore elementos honeypot: antes de clicar em um link ou preencher um campo, certifique-se de que o elemento não está oculto da vista humana. Não siga URLs suspeitos e não preencha campos de formulário invisíveis.
Imite um usuário real: use cabeçalhos reais e valores típicos de navegadores normais (User-Agent, Accept-Language, etc.). Sempre que possível, execute a extração através do kernel do navegador de navegadores antidetecção para passar nas verificações de JS e garantir um ambiente realista (navigator, cookies, localStorage, etc.).
Limite a velocidade e a concorrência: configure atrasos e pausas entre as solicitações, use intervalos aleatórios. Não exceda os limites de solicitação, escale gradualmente e monitore as reações do site (códigos HTTP 429, CAPTCHAs e assim por diante).
Gire endereços IP e identificadores de sessão: use um pool de proxies ou VPN, alterne IPs, especialmente para extração em larga escala. Garanta que um único IP não seja usado com muita frequência. Sempre opte por IPs residenciais, pois são menos suspeitos para os sistemas anti-bot.
Introduza aleatoriedade no seu comportamento de extração: emule ações do usuário, por exemplo, pequenas rolagens, movimentos do mouse, tempo gasto lendo uma página. Evite rotas totalmente sequenciais e varie padrões de ação para não demonstrar um algoritmo rígido.
A confrontação na extração da web continua, à medida que os sites inventam novos métodos de detecção e os desenvolvedores de bots procuram formas de contorná-los. Neste jogo, o vencedor é aquele que é mais atento e inventivo. Que seu bot seja exatamente isso: cuidadoso, flexível e humanamente imprevisível.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.
Mantenha-se atualizado com as últimas notícias do Octo Browser
Ao clicar no botão, você concorda com a nossa Política de Privacidade.

Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.
Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.
Junte-se ao Octo Browser agora mesmo
Ou entre em contato com a equipe de suporte no chat para tirar dúvidas a qualquer momento.