Что такое анализ поведения и как его обойти автоматизатору
22.05.2026


Markus_automation
Expert in data parsing and automation
Еще недавно антифрод-системы опирались преимущественно на технические атрибуты — IP-адреса, куки и отпечатки браузеров. Однако по мере того как разработчики скриптов и парсеров научились эффективно маскировать эти параметры, фокус защиты сместился в сторону анализа поведения.
Поведенческая биометрия оценивает, как именно пользователь взаимодействует с интерфейсом, и постепенно становится ключевым элементом современных систем обнаружения автоматизации.
В этой статье разберем, какие механизмы лежат в основе этого подхода, и расскажем, как реалистично воспроизвести человеческое поведение в автоматизированных сценариях.
Содержание
Сохраняйте анонимность, используйте преимущества мультиаккаунтинга и добивайтесь своих целей с самым качественным решением на рынке антидетект-браузеров.
Хотите попробовать Octo Browser со скидкой?
По промокоду OCTOSCRAPER получите 30% скидку на любую подписку. Предложение действительно только для новых пользователей.
Почему CAPTCHA уступает место анализу поведения
Ранее главной защитой от ботов выступала CAPTCHA. Сейчас капча никуда не делась, но заметно трансформировалась. Она стала сложнее, а некоторые современные невидимые варианты (вроде reCAPTCHA v3) вобрали в себя ту самую поведенческую биометрию, о которой мы говорим.
Зачем это нужно? Традиционная CAPTCHA (светофоры и искаженные символы) ухудшает пользовательский опыт и все чаще без проблем решается обученными нейросетями. Новый подход, который работает без видимых элементов, снимает большую часть нагрузки с пользователя и не раздражает его.
Поведенческая биометрия, являясь ядром такой теневой проверки, предлагает непрерывную аутентификацию. Она работает на основе анализа того, как именно пользователь взаимодействует с устройством (пока листает страницу или заполняет форму), без необходимости ввода каких-либо дополнительных данных.
Но важно сделать оговорку — поведенческая биометрия не выступает самостоятельным способом проверки. Она всегда работает в связке с другими тестами. И, помимо биометрии, антифрод-системы по-прежнему продолжают учитывать сетевые отпечатки, IP-репутацию и куки.
Классификация поведенческой биометрии
Давайте погрузимся в теорию глубже. Поведенческие паттерны — это, по сути, цифровой отпечаток вашей нервной системы, перенесенный на устройство. Продвинутые антифрод-системы не рассматривают параметры по отдельности. Они собирают комплексный многомерный профиль, который можно разделить на следующие категории.
Взаимодействие с устройством (кинестетика)
Это самый объемный пласт данных для классического веба и мобильных приложений. Здесь анализируется физика движений пользователя.
Клавиатура. Речь не о том, какие буквы или цифры вы нажимаете. Антифрод оценивает два главных параметра: время удержания клавиши нажатой (
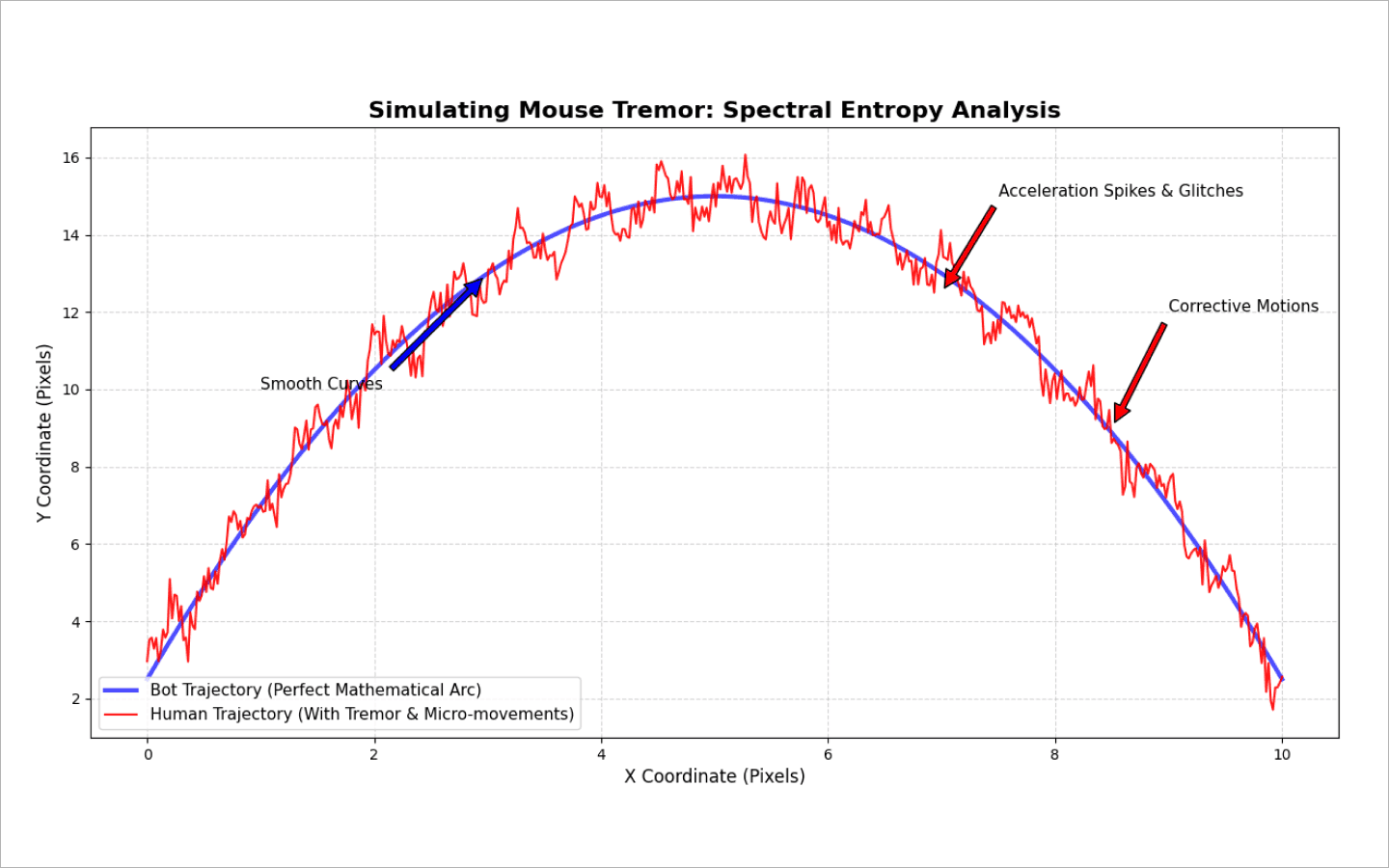
dwell time) и время перемещения пальца между клавишами (flight time). У человека есть мышечная память — привычные сочетания клавиш (например, частые окончания слов) вбиваются микросериями. Бот же либо инжектит строку целиком, либо пытается имитировать ввод через банальныйtime.sleep(random). Это формирует плоское, неестественное распределение задержек. Рандом в этом процессе подозрителен.Мышь. Курсорная аналитика. Система фиксирует координаты, вычисляя скорость, ускорение, кривизну траектории и рывки (так называемые джерки, от англ. jerk). Человек не ведет мышь по идеальной прямой. Мы целимся в кнопку, промахиваемся на пару пикселей, делаем корректирующие микродвижения и на долю секунды замираем перед кликом.
Тачскрин. Специфика мобильного веба и нативных приложений. Свайп человека — это дуга с неравномерной скоростью, определенным давлением (если API позволяет его снять) и изменяющейся площадью соприкосновения пальца с экраном. Бот, эмулирующий тач-события через Appium или JS-скрипты, часто просто «телепортирует» координаты фокуса. Написать математику полноценного свайпа сложнее, поэтому ботоводы часто экономят время.
Физические паттерны (биомеханика)
Когда пользователь заходит с мобильного устройства, в игру вступают аппаратные датчики. А так как сейчас эпоха мобильного пользователя, это важно.
Походка и микродвижения. Вы скроллите ленту на ходу, сидя в кресле или лежа на диване? Акселерометр и гироскоп смартфона постоянно улавливают микроколебания девайса. У реального пользователя телефон всегда немного колеблется в руках, даже если он старается держать его неподвижно. Серверные фермы ботов и эмуляторы по умолчанию имеют нулевой фон по сенсорам, что дает антифроду пищу для размышлений и повышает риск-скор (risk score).
Когнитивные паттерны (психология взаимодействия)
Здесь анализируется, как работает мозг пользователя при взаимодействии с UI.
Навигация и скорость принятия решений. Как быстро пользователь находит нужную кнопку? Читает ли он текст перед тем, как поставить галочку в чекбоксе? Люди часто водят курсором по тексту во время чтения, по аналогии с движением пальца по тексту книги или делают паузы на сложных формах, кто-то вообще выделяет этот текст. Скрипт-парсер не сомневается, он точно знает структуру DOM-дерева и безошибочно триггерит нужное событие ровно через заданный тайм-аут, полностью игнорируя логику визуального поиска.
В совокупности эти три уровня создают настолько сложный профиль, что подделать его целиком, просто накидав рандомных задержек в код Selenium или Puppeteer, становится математически невыполнимой задачей.
Сбор сигналов и предобработка
Базовые источники сбора данных биометрии — события mousemove, keydown, keyup, touchstart, touchend, а также DeviceOrientation API для снятия показаний акселерометра и гироскопа.
Самое сложное на этом этапе — работа с огромным объемом фрагментированных и асинхронных данных. Одно лишь событие mousemove может срабатывать сотни раз в секунду. Если на каждое движение курсора привлекать бэкенд или выполнять сложные вычисления прямо на стороне клиента, антифрод мгновенно повесит UI-поток и вызовет лаги на сайте заказчика. Ни один бизнес на такое не пойдет.
Поэтому клиентский скрипт-коллектор делается максимально примитивным и легковесным. Его единственная задача — быстро забрать координаты, поставить точную метку времени, сложить все это в локальный буфер и отправить на сервер пачкой (батчем).
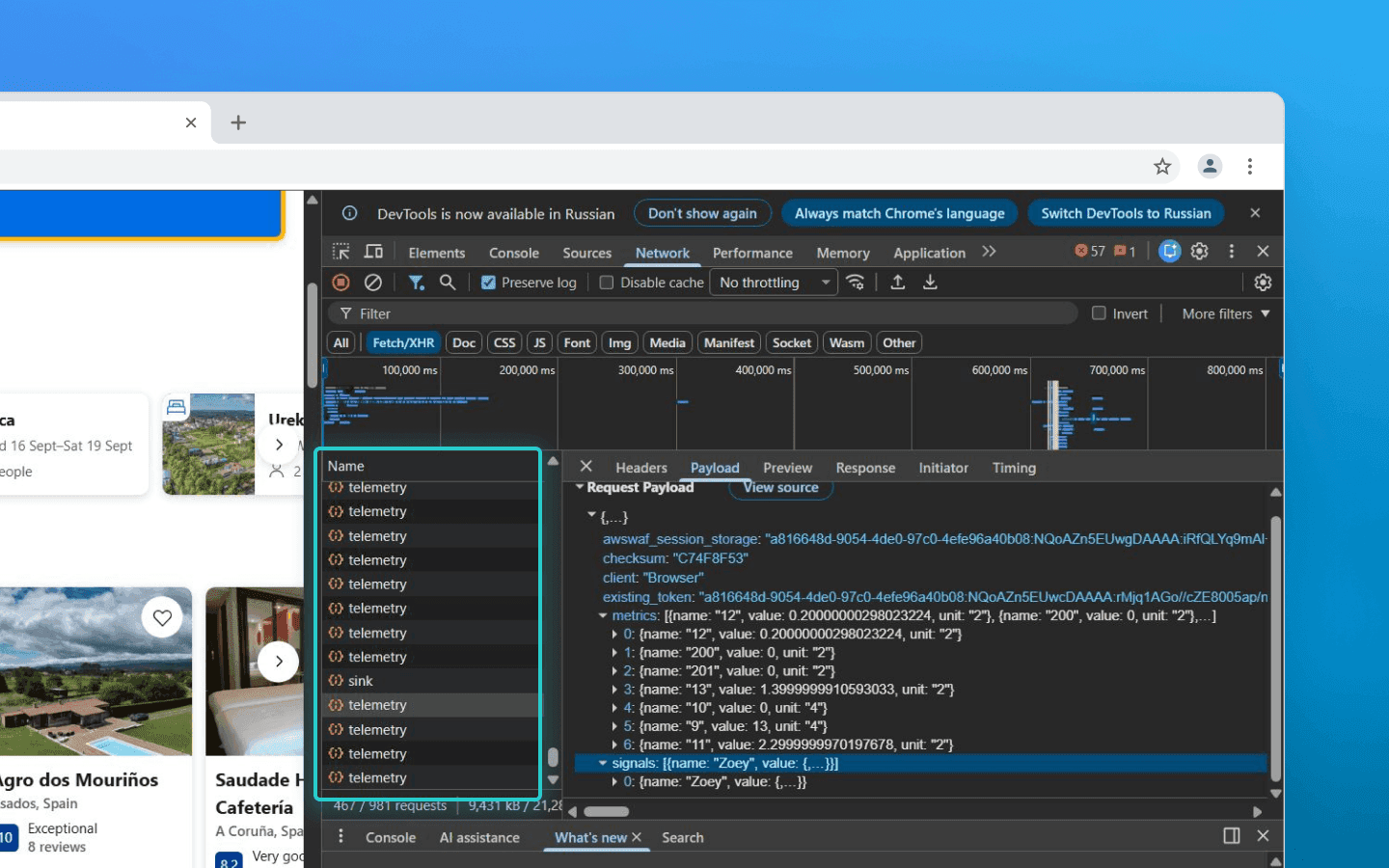
Дальше эти батчи JSON-объектов летят на бэкенд. В высоконагруженных системах они не пишутся напрямую в базу данных и не передаются ML-моделям сходу. Сначала они попадают в брокеры сообщений (Kafka или RabbitMQ). Это необходимо для сглаживания пиков нагрузки — например, когда начинается массированная бот-атака или происходит естественный наплыв обычных пользователей (в период распродажи или акции). На этом зона ответственности клиентской части заканчивается.
Признаковая инженерия и ML-модели
Итак, батчи сырых точек прилетели на сервер. Что с ними происходит дальше?
Если просто отдать этот массив пикселей в ML-модель, она не научится отличать человека от бота. Она просто заучит, где на вашем сайте находятся кнопки, и сломается при малейшем изменении верстки. Моделям машинного обучения не нужна география экрана, им нужны поведенческие абстракции.
Поэтому между очередью сообщений и нейросетями стоит отдельный микросервис — блок «Признаковая инженерия». Обычно это пайплайны на базе Pandas и NumPy, которые агрегируют логи и превращают их в данные, с которыми можно работать моделям. Они высчитывают:
евклидово расстояние между точками;
дельты времени;
мгновенные скорости;
углы поворота траектории.
На базе этих расчетов антифрод и формирует сложный профиль признаков:
Клавиатура: векторы задержек (
dwell time,flight time), их медиана, дисперсия и стандартное отклонение. Насколько стабилен ритм печати.Мышь: статистика по скоростям и ускорениям, количество микропауз, а также спектральная энтропия траектории. Этот параметр показывает, насколько движение хаотично (как у человека) или, наоборот, математически идеально (как у скрипта).
Тачскрин: градиент изменения давления и площади контакта пальца во время свайпа (там, где API браузера или ОС это отдает).
Когнитивные фичи: время бездействия (
idle time), задержки перед фокусом на целевых элементах. Например, это может быть пауза перед нажатием кнопки «Оплатить», пока человек пересчитывает сумму.
Из одной сессии извлекаются сотни таких параметров, которые очищаются от контекста верстки и отправляют в ML-модели.
Классические ML-алгоритмы (Random Forest, SVM, Gradient Boosting)
Отлично справляются с агрегированными статистическими признаками. Они работают быстро, потребляют мало серверных ресурсов и используются как первая (самая быстрая) линия обороны.
По сути, они прогоняют весь вектор статистических параметров сессии (скорость действий, разброс таймингов, энтропию) через систему выверенных математических порогов, моментально отсекая явные аномалии — например, нулевую дисперсию ускорения курсора или неестественно ровные интервалы между кликами.
Нейросети (LSTM, GRU и 1D-CNN)
Если предыдущие алгоритмы смотрят на общую картину, то рекуррентные сети анализируют саму последовательность движений курсора во времени.
Рекуррентные сети предназначены для обработки последовательных данных (текст, речь, временные ряды), где важен контекст предыдущих элементов. В отличие от обычных сетей, у рекуррентных есть «память» (обратные связи), позволяющая учитывать информацию из прошлых шагов. Следовательно, они способны обнаружить неестественные паттерны и ритмы, которые маскируются при обычном статистическом усреднении.
Автоэнкодеры и поиск аномалий
Главная проблема антифрода — ботоводы постоянно придумывают новые методы эмуляции. Обучить сеть на всех существующих ботах невозможно, зато существуют миллионы сессий реальных людей. Поэтому активно применяется обучение без учителя, а именно — автоэнкодеры. Это нейросеть, которую тренируют только на человеческом поведении. Она работает как специфический фильтр: берет входящие параметры сессии, математически сжимает их в компактный код, а затем пытается восстановить обратно в исходный вид.
Так как сеть видела только реальные сессии, она идеально выучила человеческую физику движений и восстанавливает такие данные почти со 100%-й точностью. Но если на вход подать поведение даже самого умного, но ранее неизвестного бота, модель попытается применить к нему человеческие правила сжатия. В результате на этапе восстановления алгоритм выдаст некорректный результат.
Если возникает огромная разница между исходными данными и тем, что смогла восстановить сеть, — это и есть ошибка восстановления (reconstruction error). Чем значительнее эта ошибка, тем сильнее взлетает risk score, сигнализируя об аномалии.
Монопроверки или гибридные схемы
Использование какого-то одного типа проверки малодейственно, поэтому никто не использует одну модель. Архитектура в большинстве случаев строится каскадом — легковесные ML-алгоритмы на лету могут отсекать до 90% простейших скриптов и ботов, а тяжелые нейросети включаются для пограничных случаев, когда предыдущая проверка не уверена в результате. Тем самым экономятся вычислительные мощности.
Изменение признаков и адаптация
Поведение реального человека может меняться, как и цифровой отпечаток его устройства. Пользователь купил новую мышь с другим DPI, пересел с десктопа на ноутбук с тачпадом, повредил руку, выпил двойной эспрессо или просто сильно устал к концу рабочего дня. Все это моментально меняет ритм печати, микромоторику и скорость реакций. Если антифрод-модель статична и опирается на эталонный слепок, собранный год назад, она неизбежно начнет блокировать реальных людей. Вырастет процент ложных срабатываний, конверсия начнет падать, а бизнес терять деньги и лояльность клиентов.
Следовательно, антифрод-системы должны непрерывно эволюционировать вместе с пользователем, адаптируясь к меняющимся условиям.
Обучение нейросетей в реальном времени
В отличие от классического пакетного обучения, когда модель переобучают раз в месяц на огромном массиве накопившихся данных, онлайн-обучение позволяет алгоритму корректировать веса на лету. Как только валидная сессия (подтвержденная, например, покупкой или вводом 2FA) завершается, ее признаки тут же немного сдвигают пороги принятия решений в модели. Это идеально компенсирует плавные изменения привычек пользователя.
Скользящее окно памяти
Алгоритмы используют механизм скользящего окна памяти. В эталонный поведенческий шаблон постоянно добавляются данные свежих сессий, причем им присваивается максимальный математический вес. Влияние старых записей постепенно стремится к нулю. Система всегда сравнивает ваше текущее поведение с тем, как вы вели себя в последние недели, а не в момент регистрации аккаунта три года назад.
Статистический мониторинг
Но как системе понять, что резкое изменение паттерна — это легитимная покупка новой мышки или внезапная подмена сессии умным ботом? Для этого применяется жесткий статистический мониторинг, в частности:
PCA-анализ (метод главных компонент). Позволяет спроецировать десятки признаков в 2D- или 3D-пространстве и отслеживать смещение кластеров. Если свежие сессии резко отклоняются от исторического ядра пользователя, система фиксирует дрейф.
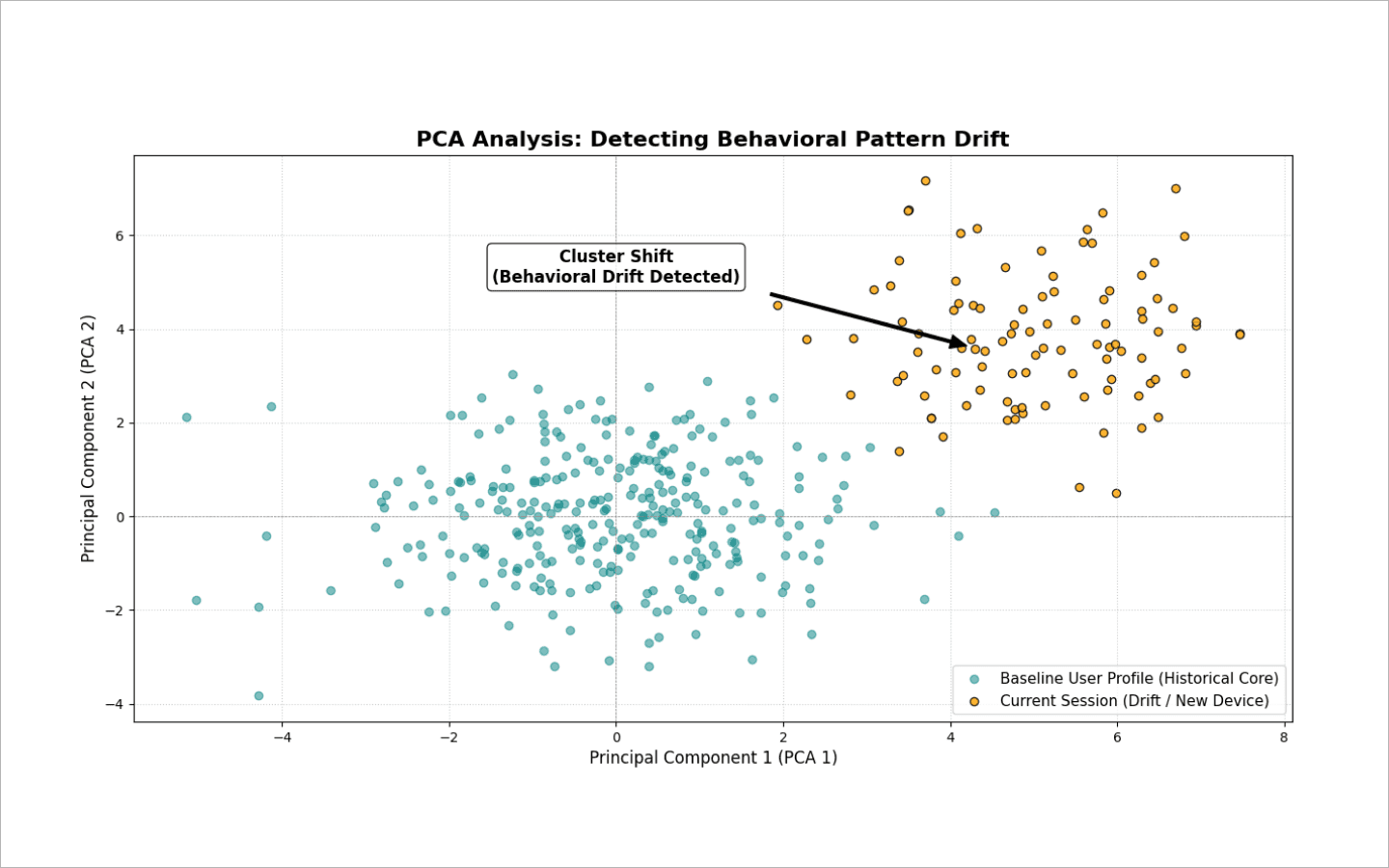
Статистические тесты (например, тест Колмогорова-Смирнова). Алгоритм непрерывно сравнивает распределение новых данных с эталонным. Если фиксируется расхождение между двумя выборками, система временно снижает доверие к профилю. В этот момент пользователя не банят, а предлагают пройти капчу. Если проверка пройдена успешно — модель воспринимает этот скачок как легитимный (например, переход на новое устройство) и обновляет эталон профиля.
Эмуляция человеческого поведения
Мы разобрались, как работают алгоритмы антифрода. Теперь же давайте выясним, как обучить бота человеческому поведению.
Простого сглаживания курсора кривыми Безье или добавления time.sleep() недостаточно — ML-модели распознают автоматизацию за пару кликов. А вот чтобы эмулятор стал действительно похожим на человека, в него необходимо интегрировать законы физиологии и биомеханики.
Инъекция джиттера
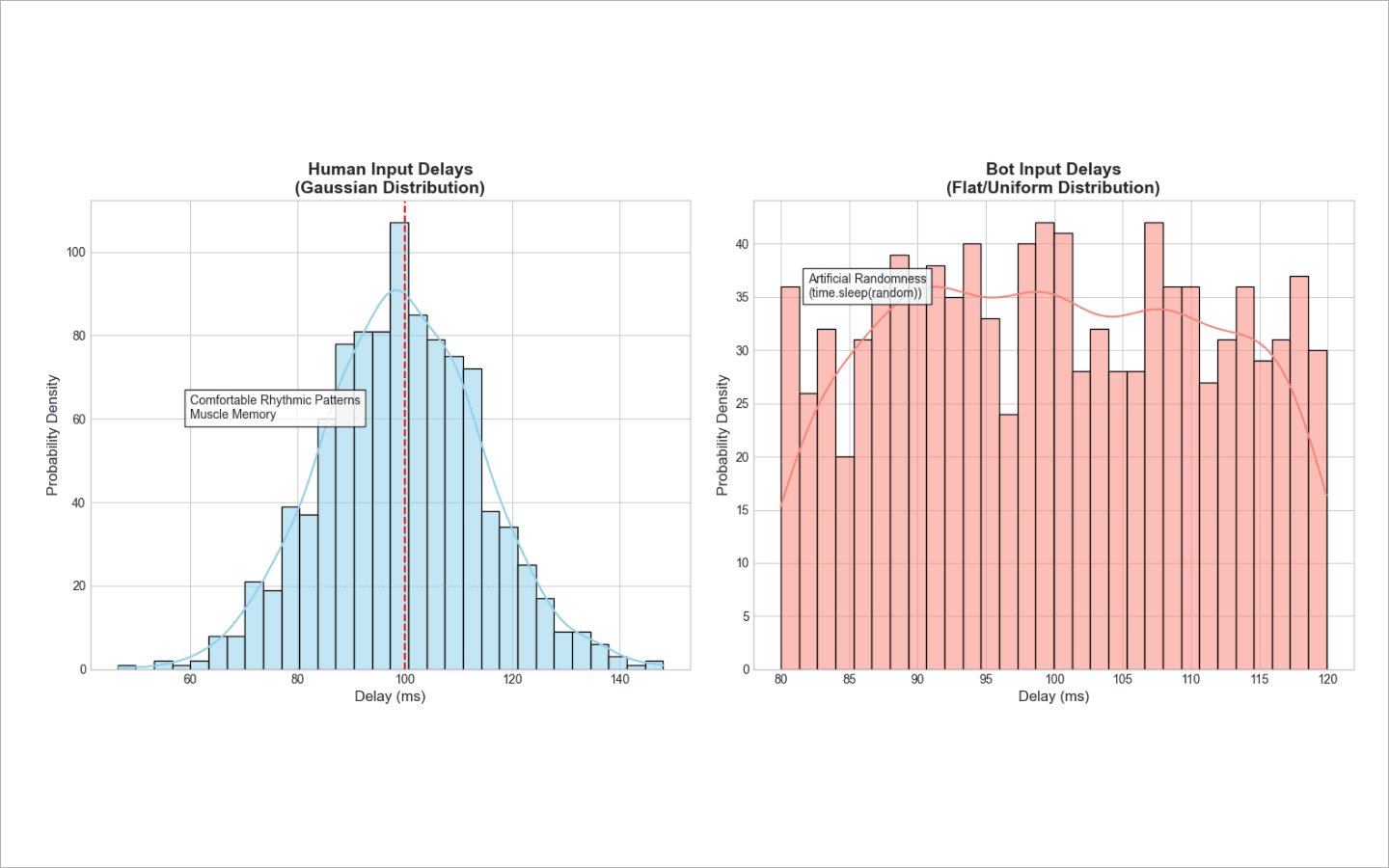
Если вы скажете скрипту делать случайные паузы от 80 до 120 миллисекунд, он будет выдавать 80, 120 и 95 мс вперемешку с одинаковой частотой.
Человек так не печатает. У нас есть свой комфортный темп, в который мы чаще всего попадаем. Иногда наши пальцы чуть ускоряются или тормозят. Поэтому задержки нужно генерировать по кривой Гаусса (диаграмма в виде колокола). Абсолютное большинство пауз бота должно кучковаться вокруг одной базовой скорости, и только единичные отклонения могут быть сильными, как в большую, так и в меньшую сторону.
Имитация тремора
Представьте, что вы пытаетесь быстро кликнуть по мелкому чекбоксу. Вы резко ведете мышь, курсор на пару пикселей пролетает мимо цели, вы это замечаете и одергиваете его назад.
Чтобы сымитировать этот эффект и естественное дрожание руки, к идеальной траектории мыши программисты примешивают математические функции (синусы и косинусы). Это и создает реалистичный микрошум, который обманывает антифрод.
Макропаузы
Самая продвинутая и редко встречающаяся техника — внедрение макропауз, имитирующих физиологические циклы. Человек не работает за компьютером непрерывно. Мы моргаем, теряя зрительный контакт с монитором, делаем вдохи и выдохи, переводим взгляд на клавиатуру или отвлекаемся на телефон.
Эмулятор должен иметь логику «потери фокуса» — периодические искусственные задержки на 1–3 секунды перед важными действиями, разрывающие машинную монотонность.
Копирование поведения
Зачем с нуля писать сложную математику, пытаясь сгенерировать идеальный скролл со всеми естественными затуханиями и рывками, если можно просто взять реальный? Этот подход называется blending, и он выводит эмуляцию на совершенно новый уровень.
Продвинутые ботоводы собирают собственные базы данных или покупают готовые. В них входят реальные сессии живых пользователей: как человек листает ленту, как водит курсором во время чтения текста, как бессознательно двигает мышь в моменты раздумий. Эти записи сохраняются в виде массивов с векторами смещений и микротаймингами.
Когда скрипту, написанному по такой технологии, нужно проскроллить страницу или довести курсор до сложной формы, он не использует window.scrollBy() или кривые Безье. Он достает из базы подходящий кусок реального человеческого лога. Дальше происходит морфинг траектории: скрипт математически деформирует этот «слепок» так, чтобы натянуть его на текущие координаты браузера. Векторы смещаются ровно настолько, чтобы курсор в итоге оказался над нужной кнопкой, после чего алгоритм бесшовно передает управление обратно боту для финального клика.
ML-модели антифрода видят в этих движениях идеальный высокочастотный шум, абсолютно естественный тремор и правильные микроостановки. И они пропускают скрипт, потому что эти данные действительно принадлежат живому человеку.
В чем подвох? Чтобы этот метод работал на масштабах, ботоводу нужна поистине гигантская библиотека таких поведенческих «слепков». Если скрипт будет использовать один и тот же кусок скролла для разных ботов, серверный антифрод быстро вычислит математический дубликат (сработает базовая защита от replay-атак) и отправит всю ферму в бан.
Уязвимость циклов
Но как бы вы ни рандомизировали тайминги и ни трясли курсором, у бота есть одна врожденная болезнь — он живет внутри программного цикла (while или for).
Сервер защиты берет тайминги вашего скрипта и прогоняет их через спектральный анализ (преобразование Фурье). Так он отсеивает весь искусственный рандомный шум и обнаруживает скрытую несущую частоту программного цикла. Человек от природы аритмичен, а бот — нет.
Можно ли победить преобразование Фурье и заставить сервер поверить, что ваш скрипт — живой человек без базовой частоты? Да, но для этого придется переписать саму архитектуру вашего парсера. Банальным Math.random() здесь уже не обойтись.
Отказ от циклов в пользу State Machines. Не используйте линейные
whileилиforс вложеннымиsleep(). Ваш бот должен представлять собой конечный автомат, управляемый событиями. У него должно быть несколько состояний — чтение, сомнение или зависание, движение, клик. Переход между этими состояниями не должен быть жестко запрограммирован — он должен определяться вероятностями. Только тогда общая ритмика сессии станет непредсказуемой, как у человека, который в любой момент может передумать нажимать на кнопку.Математика «тяжелых хвостов». Забудьте про равномерный рандом и даже про кривую Гаусса. Большинство ваших пауз должны быть короткими и кучными, но с определенной вероятностью бот может остановиться на аномально долгое время. Именно такие редкие, но сильные выбросы ломают частотный анализ Фурье, размазывая спектр и скрывая машинный ритм.
Использование энтропии операционной системы. Встроенные генераторы псевдослучайных чисел в JS или Python сами по себе имеют предсказуемые паттерны. Можно брать настоящую энтропию напрямую из операционной системы, которая собирает хаотичные шумы железа — от перепадов температуры процессора до сетевых прерываний.
Заключение: экономика парсинга и бесконечная игра
Поведенческая биометрия не стала панацеей при борьбе с ботами. Однако она существенно изменила правила игры и экономику автоматизации.
Если раньше для написания парсера достаточно было купить пачку прокси-серверов и разобраться с заголовками браузера, то теперь от автоматизатора требуются серьезные знания вплоть до изучения биомеханики и преобразования Фурье. Конечно, речь про серьезные проекты, а не про необходимость спарсить фотографии с гугл-карт.
Гонка вооружений между антифродом и ботоводами продолжается уже в новой плоскости — имитации человеческой нервной системы. Защита продолжит внедрять новые, еще более сложные проверки, а парсеры будут учиться еще правдоподобнее «дышать» и прокрастинировать.
Сохраняйте анонимность, используйте преимущества мультиаккаунтинга и добивайтесь своих целей с самым качественным решением на рынке антидетект-браузеров.
Хотите попробовать Octo Browser со скидкой?
По промокоду OCTOSCRAPER получите 30% скидку на любую подписку. Предложение действительно только для новых пользователей.
Почему CAPTCHA уступает место анализу поведения
Ранее главной защитой от ботов выступала CAPTCHA. Сейчас капча никуда не делась, но заметно трансформировалась. Она стала сложнее, а некоторые современные невидимые варианты (вроде reCAPTCHA v3) вобрали в себя ту самую поведенческую биометрию, о которой мы говорим.
Зачем это нужно? Традиционная CAPTCHA (светофоры и искаженные символы) ухудшает пользовательский опыт и все чаще без проблем решается обученными нейросетями. Новый подход, который работает без видимых элементов, снимает большую часть нагрузки с пользователя и не раздражает его.
Поведенческая биометрия, являясь ядром такой теневой проверки, предлагает непрерывную аутентификацию. Она работает на основе анализа того, как именно пользователь взаимодействует с устройством (пока листает страницу или заполняет форму), без необходимости ввода каких-либо дополнительных данных.
Но важно сделать оговорку — поведенческая биометрия не выступает самостоятельным способом проверки. Она всегда работает в связке с другими тестами. И, помимо биометрии, антифрод-системы по-прежнему продолжают учитывать сетевые отпечатки, IP-репутацию и куки.
Классификация поведенческой биометрии
Давайте погрузимся в теорию глубже. Поведенческие паттерны — это, по сути, цифровой отпечаток вашей нервной системы, перенесенный на устройство. Продвинутые антифрод-системы не рассматривают параметры по отдельности. Они собирают комплексный многомерный профиль, который можно разделить на следующие категории.
Взаимодействие с устройством (кинестетика)
Это самый объемный пласт данных для классического веба и мобильных приложений. Здесь анализируется физика движений пользователя.
Клавиатура. Речь не о том, какие буквы или цифры вы нажимаете. Антифрод оценивает два главных параметра: время удержания клавиши нажатой (
dwell time) и время перемещения пальца между клавишами (flight time). У человека есть мышечная память — привычные сочетания клавиш (например, частые окончания слов) вбиваются микросериями. Бот же либо инжектит строку целиком, либо пытается имитировать ввод через банальныйtime.sleep(random). Это формирует плоское, неестественное распределение задержек. Рандом в этом процессе подозрителен.Мышь. Курсорная аналитика. Система фиксирует координаты, вычисляя скорость, ускорение, кривизну траектории и рывки (так называемые джерки, от англ. jerk). Человек не ведет мышь по идеальной прямой. Мы целимся в кнопку, промахиваемся на пару пикселей, делаем корректирующие микродвижения и на долю секунды замираем перед кликом.
Тачскрин. Специфика мобильного веба и нативных приложений. Свайп человека — это дуга с неравномерной скоростью, определенным давлением (если API позволяет его снять) и изменяющейся площадью соприкосновения пальца с экраном. Бот, эмулирующий тач-события через Appium или JS-скрипты, часто просто «телепортирует» координаты фокуса. Написать математику полноценного свайпа сложнее, поэтому ботоводы часто экономят время.
Физические паттерны (биомеханика)
Когда пользователь заходит с мобильного устройства, в игру вступают аппаратные датчики. А так как сейчас эпоха мобильного пользователя, это важно.
Походка и микродвижения. Вы скроллите ленту на ходу, сидя в кресле или лежа на диване? Акселерометр и гироскоп смартфона постоянно улавливают микроколебания девайса. У реального пользователя телефон всегда немного колеблется в руках, даже если он старается держать его неподвижно. Серверные фермы ботов и эмуляторы по умолчанию имеют нулевой фон по сенсорам, что дает антифроду пищу для размышлений и повышает риск-скор (risk score).
Когнитивные паттерны (психология взаимодействия)
Здесь анализируется, как работает мозг пользователя при взаимодействии с UI.
Навигация и скорость принятия решений. Как быстро пользователь находит нужную кнопку? Читает ли он текст перед тем, как поставить галочку в чекбоксе? Люди часто водят курсором по тексту во время чтения, по аналогии с движением пальца по тексту книги или делают паузы на сложных формах, кто-то вообще выделяет этот текст. Скрипт-парсер не сомневается, он точно знает структуру DOM-дерева и безошибочно триггерит нужное событие ровно через заданный тайм-аут, полностью игнорируя логику визуального поиска.
В совокупности эти три уровня создают настолько сложный профиль, что подделать его целиком, просто накидав рандомных задержек в код Selenium или Puppeteer, становится математически невыполнимой задачей.
Сбор сигналов и предобработка
Базовые источники сбора данных биометрии — события mousemove, keydown, keyup, touchstart, touchend, а также DeviceOrientation API для снятия показаний акселерометра и гироскопа.
Самое сложное на этом этапе — работа с огромным объемом фрагментированных и асинхронных данных. Одно лишь событие mousemove может срабатывать сотни раз в секунду. Если на каждое движение курсора привлекать бэкенд или выполнять сложные вычисления прямо на стороне клиента, антифрод мгновенно повесит UI-поток и вызовет лаги на сайте заказчика. Ни один бизнес на такое не пойдет.
Поэтому клиентский скрипт-коллектор делается максимально примитивным и легковесным. Его единственная задача — быстро забрать координаты, поставить точную метку времени, сложить все это в локальный буфер и отправить на сервер пачкой (батчем).
Дальше эти батчи JSON-объектов летят на бэкенд. В высоконагруженных системах они не пишутся напрямую в базу данных и не передаются ML-моделям сходу. Сначала они попадают в брокеры сообщений (Kafka или RabbitMQ). Это необходимо для сглаживания пиков нагрузки — например, когда начинается массированная бот-атака или происходит естественный наплыв обычных пользователей (в период распродажи или акции). На этом зона ответственности клиентской части заканчивается.
Признаковая инженерия и ML-модели
Итак, батчи сырых точек прилетели на сервер. Что с ними происходит дальше?
Если просто отдать этот массив пикселей в ML-модель, она не научится отличать человека от бота. Она просто заучит, где на вашем сайте находятся кнопки, и сломается при малейшем изменении верстки. Моделям машинного обучения не нужна география экрана, им нужны поведенческие абстракции.
Поэтому между очередью сообщений и нейросетями стоит отдельный микросервис — блок «Признаковая инженерия». Обычно это пайплайны на базе Pandas и NumPy, которые агрегируют логи и превращают их в данные, с которыми можно работать моделям. Они высчитывают:
евклидово расстояние между точками;
дельты времени;
мгновенные скорости;
углы поворота траектории.
На базе этих расчетов антифрод и формирует сложный профиль признаков:
Клавиатура: векторы задержек (
dwell time,flight time), их медиана, дисперсия и стандартное отклонение. Насколько стабилен ритм печати.Мышь: статистика по скоростям и ускорениям, количество микропауз, а также спектральная энтропия траектории. Этот параметр показывает, насколько движение хаотично (как у человека) или, наоборот, математически идеально (как у скрипта).
Тачскрин: градиент изменения давления и площади контакта пальца во время свайпа (там, где API браузера или ОС это отдает).
Когнитивные фичи: время бездействия (
idle time), задержки перед фокусом на целевых элементах. Например, это может быть пауза перед нажатием кнопки «Оплатить», пока человек пересчитывает сумму.
Из одной сессии извлекаются сотни таких параметров, которые очищаются от контекста верстки и отправляют в ML-модели.
Классические ML-алгоритмы (Random Forest, SVM, Gradient Boosting)
Отлично справляются с агрегированными статистическими признаками. Они работают быстро, потребляют мало серверных ресурсов и используются как первая (самая быстрая) линия обороны.
По сути, они прогоняют весь вектор статистических параметров сессии (скорость действий, разброс таймингов, энтропию) через систему выверенных математических порогов, моментально отсекая явные аномалии — например, нулевую дисперсию ускорения курсора или неестественно ровные интервалы между кликами.
Нейросети (LSTM, GRU и 1D-CNN)
Если предыдущие алгоритмы смотрят на общую картину, то рекуррентные сети анализируют саму последовательность движений курсора во времени.
Рекуррентные сети предназначены для обработки последовательных данных (текст, речь, временные ряды), где важен контекст предыдущих элементов. В отличие от обычных сетей, у рекуррентных есть «память» (обратные связи), позволяющая учитывать информацию из прошлых шагов. Следовательно, они способны обнаружить неестественные паттерны и ритмы, которые маскируются при обычном статистическом усреднении.
Автоэнкодеры и поиск аномалий
Главная проблема антифрода — ботоводы постоянно придумывают новые методы эмуляции. Обучить сеть на всех существующих ботах невозможно, зато существуют миллионы сессий реальных людей. Поэтому активно применяется обучение без учителя, а именно — автоэнкодеры. Это нейросеть, которую тренируют только на человеческом поведении. Она работает как специфический фильтр: берет входящие параметры сессии, математически сжимает их в компактный код, а затем пытается восстановить обратно в исходный вид.
Так как сеть видела только реальные сессии, она идеально выучила человеческую физику движений и восстанавливает такие данные почти со 100%-й точностью. Но если на вход подать поведение даже самого умного, но ранее неизвестного бота, модель попытается применить к нему человеческие правила сжатия. В результате на этапе восстановления алгоритм выдаст некорректный результат.
Если возникает огромная разница между исходными данными и тем, что смогла восстановить сеть, — это и есть ошибка восстановления (reconstruction error). Чем значительнее эта ошибка, тем сильнее взлетает risk score, сигнализируя об аномалии.
Монопроверки или гибридные схемы
Использование какого-то одного типа проверки малодейственно, поэтому никто не использует одну модель. Архитектура в большинстве случаев строится каскадом — легковесные ML-алгоритмы на лету могут отсекать до 90% простейших скриптов и ботов, а тяжелые нейросети включаются для пограничных случаев, когда предыдущая проверка не уверена в результате. Тем самым экономятся вычислительные мощности.
Изменение признаков и адаптация
Поведение реального человека может меняться, как и цифровой отпечаток его устройства. Пользователь купил новую мышь с другим DPI, пересел с десктопа на ноутбук с тачпадом, повредил руку, выпил двойной эспрессо или просто сильно устал к концу рабочего дня. Все это моментально меняет ритм печати, микромоторику и скорость реакций. Если антифрод-модель статична и опирается на эталонный слепок, собранный год назад, она неизбежно начнет блокировать реальных людей. Вырастет процент ложных срабатываний, конверсия начнет падать, а бизнес терять деньги и лояльность клиентов.
Следовательно, антифрод-системы должны непрерывно эволюционировать вместе с пользователем, адаптируясь к меняющимся условиям.
Обучение нейросетей в реальном времени
В отличие от классического пакетного обучения, когда модель переобучают раз в месяц на огромном массиве накопившихся данных, онлайн-обучение позволяет алгоритму корректировать веса на лету. Как только валидная сессия (подтвержденная, например, покупкой или вводом 2FA) завершается, ее признаки тут же немного сдвигают пороги принятия решений в модели. Это идеально компенсирует плавные изменения привычек пользователя.
Скользящее окно памяти
Алгоритмы используют механизм скользящего окна памяти. В эталонный поведенческий шаблон постоянно добавляются данные свежих сессий, причем им присваивается максимальный математический вес. Влияние старых записей постепенно стремится к нулю. Система всегда сравнивает ваше текущее поведение с тем, как вы вели себя в последние недели, а не в момент регистрации аккаунта три года назад.
Статистический мониторинг
Но как системе понять, что резкое изменение паттерна — это легитимная покупка новой мышки или внезапная подмена сессии умным ботом? Для этого применяется жесткий статистический мониторинг, в частности:
PCA-анализ (метод главных компонент). Позволяет спроецировать десятки признаков в 2D- или 3D-пространстве и отслеживать смещение кластеров. Если свежие сессии резко отклоняются от исторического ядра пользователя, система фиксирует дрейф.
Статистические тесты (например, тест Колмогорова-Смирнова). Алгоритм непрерывно сравнивает распределение новых данных с эталонным. Если фиксируется расхождение между двумя выборками, система временно снижает доверие к профилю. В этот момент пользователя не банят, а предлагают пройти капчу. Если проверка пройдена успешно — модель воспринимает этот скачок как легитимный (например, переход на новое устройство) и обновляет эталон профиля.
Эмуляция человеческого поведения
Мы разобрались, как работают алгоритмы антифрода. Теперь же давайте выясним, как обучить бота человеческому поведению.
Простого сглаживания курсора кривыми Безье или добавления time.sleep() недостаточно — ML-модели распознают автоматизацию за пару кликов. А вот чтобы эмулятор стал действительно похожим на человека, в него необходимо интегрировать законы физиологии и биомеханики.
Инъекция джиттера
Если вы скажете скрипту делать случайные паузы от 80 до 120 миллисекунд, он будет выдавать 80, 120 и 95 мс вперемешку с одинаковой частотой.
Человек так не печатает. У нас есть свой комфортный темп, в который мы чаще всего попадаем. Иногда наши пальцы чуть ускоряются или тормозят. Поэтому задержки нужно генерировать по кривой Гаусса (диаграмма в виде колокола). Абсолютное большинство пауз бота должно кучковаться вокруг одной базовой скорости, и только единичные отклонения могут быть сильными, как в большую, так и в меньшую сторону.
Имитация тремора
Представьте, что вы пытаетесь быстро кликнуть по мелкому чекбоксу. Вы резко ведете мышь, курсор на пару пикселей пролетает мимо цели, вы это замечаете и одергиваете его назад.
Чтобы сымитировать этот эффект и естественное дрожание руки, к идеальной траектории мыши программисты примешивают математические функции (синусы и косинусы). Это и создает реалистичный микрошум, который обманывает антифрод.
Макропаузы
Самая продвинутая и редко встречающаяся техника — внедрение макропауз, имитирующих физиологические циклы. Человек не работает за компьютером непрерывно. Мы моргаем, теряя зрительный контакт с монитором, делаем вдохи и выдохи, переводим взгляд на клавиатуру или отвлекаемся на телефон.
Эмулятор должен иметь логику «потери фокуса» — периодические искусственные задержки на 1–3 секунды перед важными действиями, разрывающие машинную монотонность.
Копирование поведения
Зачем с нуля писать сложную математику, пытаясь сгенерировать идеальный скролл со всеми естественными затуханиями и рывками, если можно просто взять реальный? Этот подход называется blending, и он выводит эмуляцию на совершенно новый уровень.
Продвинутые ботоводы собирают собственные базы данных или покупают готовые. В них входят реальные сессии живых пользователей: как человек листает ленту, как водит курсором во время чтения текста, как бессознательно двигает мышь в моменты раздумий. Эти записи сохраняются в виде массивов с векторами смещений и микротаймингами.
Когда скрипту, написанному по такой технологии, нужно проскроллить страницу или довести курсор до сложной формы, он не использует window.scrollBy() или кривые Безье. Он достает из базы подходящий кусок реального человеческого лога. Дальше происходит морфинг траектории: скрипт математически деформирует этот «слепок» так, чтобы натянуть его на текущие координаты браузера. Векторы смещаются ровно настолько, чтобы курсор в итоге оказался над нужной кнопкой, после чего алгоритм бесшовно передает управление обратно боту для финального клика.
ML-модели антифрода видят в этих движениях идеальный высокочастотный шум, абсолютно естественный тремор и правильные микроостановки. И они пропускают скрипт, потому что эти данные действительно принадлежат живому человеку.
В чем подвох? Чтобы этот метод работал на масштабах, ботоводу нужна поистине гигантская библиотека таких поведенческих «слепков». Если скрипт будет использовать один и тот же кусок скролла для разных ботов, серверный антифрод быстро вычислит математический дубликат (сработает базовая защита от replay-атак) и отправит всю ферму в бан.
Уязвимость циклов
Но как бы вы ни рандомизировали тайминги и ни трясли курсором, у бота есть одна врожденная болезнь — он живет внутри программного цикла (while или for).
Сервер защиты берет тайминги вашего скрипта и прогоняет их через спектральный анализ (преобразование Фурье). Так он отсеивает весь искусственный рандомный шум и обнаруживает скрытую несущую частоту программного цикла. Человек от природы аритмичен, а бот — нет.
Можно ли победить преобразование Фурье и заставить сервер поверить, что ваш скрипт — живой человек без базовой частоты? Да, но для этого придется переписать саму архитектуру вашего парсера. Банальным Math.random() здесь уже не обойтись.
Отказ от циклов в пользу State Machines. Не используйте линейные
whileилиforс вложеннымиsleep(). Ваш бот должен представлять собой конечный автомат, управляемый событиями. У него должно быть несколько состояний — чтение, сомнение или зависание, движение, клик. Переход между этими состояниями не должен быть жестко запрограммирован — он должен определяться вероятностями. Только тогда общая ритмика сессии станет непредсказуемой, как у человека, который в любой момент может передумать нажимать на кнопку.Математика «тяжелых хвостов». Забудьте про равномерный рандом и даже про кривую Гаусса. Большинство ваших пауз должны быть короткими и кучными, но с определенной вероятностью бот может остановиться на аномально долгое время. Именно такие редкие, но сильные выбросы ломают частотный анализ Фурье, размазывая спектр и скрывая машинный ритм.
Использование энтропии операционной системы. Встроенные генераторы псевдослучайных чисел в JS или Python сами по себе имеют предсказуемые паттерны. Можно брать настоящую энтропию напрямую из операционной системы, которая собирает хаотичные шумы железа — от перепадов температуры процессора до сетевых прерываний.
Заключение: экономика парсинга и бесконечная игра
Поведенческая биометрия не стала панацеей при борьбе с ботами. Однако она существенно изменила правила игры и экономику автоматизации.
Если раньше для написания парсера достаточно было купить пачку прокси-серверов и разобраться с заголовками браузера, то теперь от автоматизатора требуются серьезные знания вплоть до изучения биомеханики и преобразования Фурье. Конечно, речь про серьезные проекты, а не про необходимость спарсить фотографии с гугл-карт.
Гонка вооружений между антифродом и ботоводами продолжается уже в новой плоскости — имитации человеческой нервной системы. Защита продолжит внедрять новые, еще более сложные проверки, а парсеры будут учиться еще правдоподобнее «дышать» и прокрастинировать.
Следите за последними новостями Octo Browser
Нажимая кнопку, вы соглашаетесь с нашей политикой конфиденциальности.
Следите за последними новостями Octo Browser
Нажимая кнопку, вы соглашаетесь с нашей политикой конфиденциальности.
Следите за последними новостями Octo Browser
Нажимая кнопку, вы соглашаетесь с нашей политикой конфиденциальности.

Присоединяйтесь к Octo Browser сейчас
Вы можете обращаться за помощью к нашим специалистам службы поддержки в чате в любое время.
Присоединяйтесь к Octo Browser сейчас
Вы можете обращаться за помощью к нашим специалистам службы поддержки в чате в любое время.
Присоединяйтесь к Octo Browser сейчас
Вы можете обращаться за помощью к нашим специалистам службы поддержки в чате в любое время.