Как парсить данные с Amazon: советы и инструменты для веб-скрейпинга


Artur Hvalei
Technical Support Specialist, Octo Browser
Amazon — одна из крупнейших в мире платформ электронной коммерции и обширный источник ценных данных. Эффективное извлечение и использование информации о товарах, ценах и отзывах покупателей крайне важно для развития бизнеса. Независимо от того, продвигаете ли вы собственные продукты или отслеживаете конкурентов, для анализа рынка вам потребуются инструменты для сбора данных. Однако скрейпинг на Amazon имеет свои особенности. В этой статье мы рассмотрим необходимые шаги для создания веб-скрапера, а эксперт из команды Octo предложит свой базовый вариант кода.
Содержание
Сохраняйте анонимность, используйте преимущества мультиаккаунтинга и добивайтесь своих целей с самым качественным решением на рынке антидетект-браузеров.
Хотите попробовать Octo Browser со скидкой?
По промокоду OCTOSCRAPER получите 30% скидку на любую подписку. Предложение действительно только для новых пользователей.
Что такое веб-скрейпинг
Веб-скрейпинг (web scraping) — это процесс автоматизированного сбора данных с сайтов. Специальные программы или скрипты, называемые скрейперами, извлекают информацию из веб-страниц и преобразуют ее в структурированный формат данных, удобный для дальнейшего анализа и использования. Наиболее распространенные форматы для хранения и последующей обработки данных — CSV, JSON, SQL или Excel.
В настоящее время веб-скрейпинг широко применяется в области Data Science, маркетинге и электронной коммерции. Веб-скрейперы собирают огромные объемы информации для личных и профессиональных целей. Более того, современные технологические гиганты полагаются на методы веб-скрейпинга, чтобы отслеживать и анализировать тренды.
Инструменты и технологии для веб-скрейпинга
Python и библиотеки
Python является одним из наиболее популярных языков программирования для веб-скрейпинга. Он известен своей простой и понятной синтаксической структурой, что делает его идеальным выбором как для начинающих, так и для опытных программистов. Еще одним преимуществом является широкий выбор библиотек для работы с веб-скрейпингом, таких как Beautiful Soup, Scrapy, Requests и Selenium. Эти библиотеки позволяют легко отправлять HTTP-запросы, обрабатывать HTML-документы и взаимодействовать с веб-страницами.
API-интерфейсы
Amazon предоставляет API для доступа к своим данным, такие как Amazon Product Advertising API. Это позволяет запрашивать определенные сведения в структурированном формате без необходимости парсинга всей HTML-страницы.
Облачные сервисы
Облачные платформы, такие как AWS Lambda и Google Cloud Functions, могут использоваться для автоматизации и масштабирования процессов веб-скрейпинга. Они обеспечивают высокую производительность и возможность обработки больших объемов данных.
Специализированные инструменты
Существуют дополнительные инструменты для веб-скрейпинга, такие как антидетект-браузеры и прокси. Их роль состоит в подмене цифрового отпечатка для обхода ограничений систем безопасности сайтов. Эти инструменты ускоряют сбор данных.
Применение веб-скрейпинга для Amazon
Анализ рынка и конкурентов
Веб-скрейпинг позволяет собирать данные о товарах и ценах конкурентов, анализировать их ассортимент и выявлять тренды. Это помогает компаниям адаптировать свои стратегии и оставаться конкурентоспособными.
Мониторинг цен
Сбор данных о ценах на аналогичные товары помогает компаниям устанавливать конкурентные цены и оперативно реагировать на изменения рынка. Это особенно важно в условиях динамичных цен и промоакций.
Сбор отзывов и рейтингов
Отзывы и рейтинги являются важным источником информации о восприятии товаров потребителями. Анализ этих данных позволяет выявлять сильные и слабые стороны продуктов, а также получать идеи для их улучшения.
Исследование ассортимента
С помощью веб-скрейпинга можно анализировать ассортимент товаров на Amazon, выявлять популярные категории и на основе этого принимать решения о расширении или изменении товарного портфеля.
Отслеживание новых товаров
Веб-скрейпинг помогает оперативно узнавать о появлении новых товаров на платформе, что может быть полезно для производителей, дистрибьюторов и аналитиков рынка.
Навигация по элементам интерфейса Amazon
Перед тем, как начать скрейпинг, важно понять, как структурированы веб-страницы. Большинство веб-страниц написаны на HTML и содержат элементы, такие как теги, атрибуты и классы. Знание HTML поможет вам правильно идентифицировать и извлекать нужные данные.
На домашней странице Amazon покупатели используют поисковую строку для ввода ключевых слов, связанных с желаемым продуктом. В результате они получают список с названиями товаров, ценами, рейтингами и другими существенными атрибутами. Дополнительно товары могут быть отфильтрованы по различным параметрам, таким как ценовой диапазон, категория товара и отзывы покупателей. Навигация по этим компонентам помогает пользователям легко находить интересующие их товары, сравнивать альтернативные варианты, просматривать дополнительную информацию и удобно осуществлять покупки на платформе Amazon.
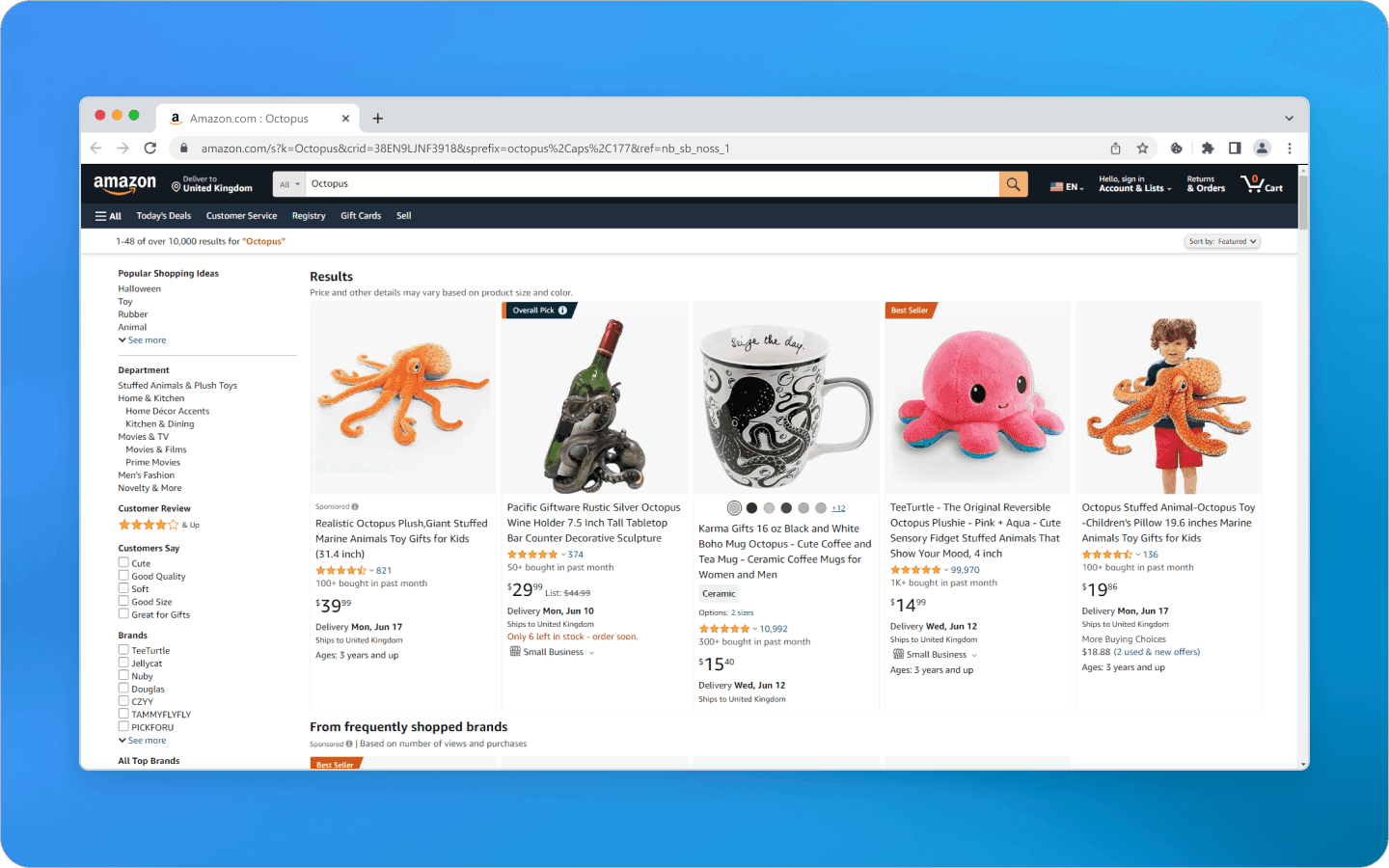
Главная страница Amazon с запросом Octopus
Для получения более обширного списка результатов вы можете воспользоваться кнопками пагинации, расположенными в нижней части страницы. На каждой странице обычно размещается большое количество объявлений, что позволяет вам просматривать дополнительные товары. Фильтры, находящиеся в верхней части страницы, позволяют уточнить поиск в соответствии с вашими требованиями.
Чтобы получить представление об HTML-структуре Amazon, выполните следующие действия:
Зайдите на сайт.
Введите нужный товар в строку поиска или выберите категорию из списка товаров.
Откройте инструменты разработчика браузера, нажав правой кнопкой мыши на товаре и выбрав пункт «Посмотреть код» из выпадающего меню.
Изучите HTML-макет, чтобы определить теги и атрибуты данных, которые вы собираетесь извлечь.

Основные шаги для начала скрейпинга
Веб-скрейпинг сводится к двум основным этапам: поиску необходимых сведений и их структурированию. После изучения структуры сайта переходим к установке компонентов для автоматизации скрейпинга.
Итак, для работы мы используем Python и библиотеки:
HTTPX: это полностью асинхронная HTTP-библиотека для Python, которая поддерживает синхронное выполнение запросов. Библиотека HTTPX предоставляет стандартный интерфейс для HTTP, аналогичный популярной библиотеке requests, но также поддерживает асинхронность, протоколы HTTP/1.1, HTTP/2, HTTP/3 и подключение через SOCKS.
BeautifulSoup: библиотека разработана для удобного и быстрого парсинга HTML- и XML-документов. Она предоставляет простой интерфейс для навигации, поиска и модификации дерева документа, что делает процесс веб-скрейпинга более интуитивным. Это позволяет извлекать информацию со страницы путем поиска тегов, атрибутов или определенного текста.
Selenium: для взаимодействия с динамическими веб-страницами.
Pandas: это мощная и надежная библиотека для обработки и очистки данных. Например, после извлечения данных с веб-страниц вы можете использовать Pandas для устранения пропусков, преобразования данных в нужный формат и удаления дубликатов.
Playwright: позволяет эффективно взаимодействовать с веб-страницами, которые используют JavaScript для динамического обновления контента. Это делает его особенно полезным для скрейпинга таких сайтов, как Amazon, где многие элементы загружаются асинхронно.
Scrapy: для более сложных задач веб-скрейпинга.
После того, как вы подготовили Python, откройте терминал или оболочку и создайте новый каталог проекта с помощью следующих команд:
mkdir scraping-amazon-python cd scraping-amazon-python
mkdir scraping-amazon-python cd scraping-amazon-python
Чтобы установить библиотеки, откройте терминал или оболочку и выполните следующие команды:
pip install httpx pip3 install pandas pip3 install playwright playwright install
pip install httpx pip3 install pandas pip3 install playwright playwright install
Обратите внимание: последняя команда (playwright install) имеет решающее значение, поскольку она обеспечивает правильную установку необходимых файлов браузера.
Убедитесь, что процесс установки завершился без каких-либо проблем, прежде чем переходить к следующему шагу. Если у вас возникают трудности при настройке окружения, вы можете обратиться к ИИ-сервисам, таким как ChatGPT, Mistral AI и другим. Эти сервисы могут помочь с запросами о возникших ошибках и предоставить пошаговые инструкции для их устранения.
Использование Python и библиотек для веб-скрейпинга
В каталоге вашего проекта создайте новый Python-скрипт amazon_scraper.py и добавьте код, приведенный в версии статьи на сайте.
import httpx from playwright.async_api import async_playwright import asyncio import pandas as pd # Profile's uuid from Octo PROFILE_UUID = "UUID_SHOULD_BE_HERE" # searching request SEARCH_REQUEST = "fashion" async def main(): async with async_playwright() as p: async with httpx.AsyncClient() as client: response = await client.post( 'http://127.0.0.1:58888/api/profiles/start', json={ 'uuid': PROFILE_UUID, 'headless': False, 'debug_port': True } ) if not response.is_success: print(f'Start response is not successful: {response.json()}') return start_response = response.json() ws_endpoint = start_response.get('ws_endpoint') browser = await p.chromium.connect_over_cdp(ws_endpoint) page = browser.contexts[0].pages[0] # Opening Amazon await page.goto(f'https://www.amazon.com/s?k={SEARCH_REQUEST}') # Extract information results = [] listings = await page.query_selector_all('div.a-section.a-spacing-small') for listing in listings: result = {} # Product name name_element = await listing.query_selector('h2.a-size-mini > a > span') result['product_name'] = await name_element.inner_text() if name_element else 'N/A' # Rating rating_element = await listing.query_selector('span[aria-label*="out of 5 stars"] > span.a-size-base') result['rating'] = (await rating_element.inner_text())[0:3] if rating_element else 'N/A' # Number of reviews reviews_element = await listing.query_selector('span[aria-label*="stars"] + span > a > span') result['number_of_reviews'] = await reviews_element.inner_text() if reviews_element else 'N/A' # Price price_element = await listing.query_selector('span.a-price > span.a-offscreen') result['price'] = await price_element.inner_text() if price_element else 'N/A' if(result['product_name']=='N/A' and result['rating']=='N/A' and result['number_of_reviews']=='N/A' and result['price']=='N/A'): pass else: results.append(result) # Close browser await browser.close() return results # Run the scraper and save results to a CSV file results = asyncio.run(main()) df = pd.DataFrame(results) df.to_csv('amazon_products_listings.csv', index=False)
import httpx from playwright.async_api import async_playwright import asyncio import pandas as pd # Profile's uuid from Octo PROFILE_UUID = "UUID_SHOULD_BE_HERE" # searching request SEARCH_REQUEST = "fashion" async def main(): async with async_playwright() as p: async with httpx.AsyncClient() as client: response = await client.post( 'http://127.0.0.1:58888/api/profiles/start', json={ 'uuid': PROFILE_UUID, 'headless': False, 'debug_port': True } ) if not response.is_success: print(f'Start response is not successful: {response.json()}') return start_response = response.json() ws_endpoint = start_response.get('ws_endpoint') browser = await p.chromium.connect_over_cdp(ws_endpoint) page = browser.contexts[0].pages[0] # Opening Amazon await page.goto(f'https://www.amazon.com/s?k={SEARCH_REQUEST}') # Extract information results = [] listings = await page.query_selector_all('div.a-section.a-spacing-small') for listing in listings: result = {} # Product name name_element = await listing.query_selector('h2.a-size-mini > a > span') result['product_name'] = await name_element.inner_text() if name_element else 'N/A' # Rating rating_element = await listing.query_selector('span[aria-label*="out of 5 stars"] > span.a-size-base') result['rating'] = (await rating_element.inner_text())[0:3] if rating_element else 'N/A' # Number of reviews reviews_element = await listing.query_selector('span[aria-label*="stars"] + span > a > span') result['number_of_reviews'] = await reviews_element.inner_text() if reviews_element else 'N/A' # Price price_element = await listing.query_selector('span.a-price > span.a-offscreen') result['price'] = await price_element.inner_text() if price_element else 'N/A' if(result['product_name']=='N/A' and result['rating']=='N/A' and result['number_of_reviews']=='N/A' and result['price']=='N/A'): pass else: results.append(result) # Close browser await browser.close() return results # Run the scraper and save results to a CSV file results = asyncio.run(main()) df = pd.DataFrame(results) df.to_csv('amazon_products_listings.csv', index=False)
В этом коде мы используем асинхронные возможности Python с библиотекой Playwright, чтобы извлечь списки товаров с определенной страницы Amazon. Мы запускаем профиль в Octo Browser, и далее происходит подключение к нему через библиотеку Playwright. После открывается URL c определенным поисковым запросом, который можно отредактировать вверху скрипта в переменной «SEARCH_REQUEST».
Запустив браузер и перейдя на целевой URL-адрес Amazon, вы извлечете информацию о товаре: его название, рейтинг, количество отзывов и цену. После итераций по каждому объявлению на странице вы можете отфильтровать объявления, в которых нет данных. Скрипт пометит их как «N/A». Результаты поиска сохраняются в Pandas DataFrame, а затем экспортируются в CSV-файл amazon_products_listings.csv.
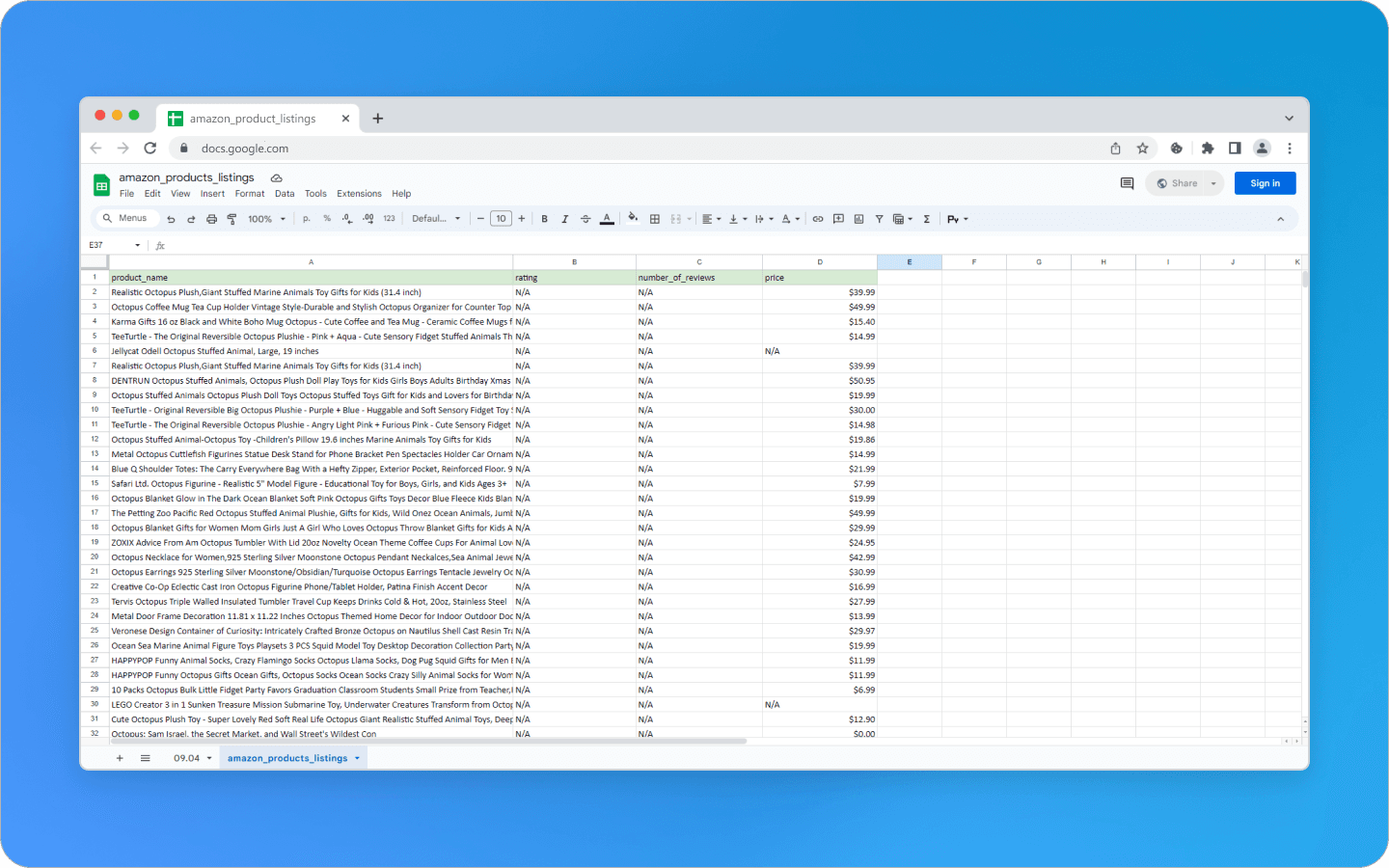
Что еще нужно для эффективного веб-скрейпинга
Веб-скрейпинг Amazon без прокси-серверов и специальных инструментов для скрейпинга сопряжен со множеством препятствий. Как и на многих других популярных платформах, на Amazon действует ограничение частоты запросов, то есть он может заблокировать ваш IP-адрес, если вы превысите установленный лимит. Кроме того, Amazon использует алгоритмы обнаружения ботов, которые идентифицируют ваш цифровой отпечаток при обращении к страницам сайта.
Учитывая эти факторы, рекомендуется следовать некоторым общепринятым практикам, чтобы избежать обнаружения и блокировки со стороны Amazon. Вот некоторые из наиболее полезных советов:
Имитация естественного поведения
Amazon может блокировать или временно приостанавливать деятельность, которую он сочтет роботизированной или подозрительной. Очень важно, чтобы ваш парсер выглядел как можно более человекоподобным.
Чтобы разработать успешный шаблон краулинга, подумайте о том, как будет вести себя обычный пользователь при изучении страницы, и добавьте клики, прокрутки и движения мыши в соответствии с этим. Чтобы избежать блокировки, нужно вводить задержки или случайные интервалы между запросами с помощью функций вроде asyncio.sleep(random.uniform(1, 5)). Так ваш шаблон будет выглядеть менее роботизированным.
Правдоподобный фингерпринт
Используйте антидетект-браузер, чтобы имитировать цифровой отпечаток реального устройства. Такие платформы, как Amazon, собирают различные параметры фингерпринта для обнаружения ботов. Чтобы не попасть впросак, необходимо следить за тем, чтобы параметры фингерпринта всегда были правдоподобными.
Кроме того, для снижения риска обнаружения следует чередовать IP-адреса. Очень важную роль при работе с антидетект-браузером играют качественные прокси. Нужно выбирать провайдеров с хорошей репутацией и самой низкой ценой. Прокси следует подбирать в соответствии со стратегией скрейпинга и учитывать ГЕО, так как платформа предоставляет разный контент для разных регионов, и проверять прокси на низкий spam/abuse/fraud score. Также следует учитывать скорость прокси. Например, резидентные прокси могут иметь высокую задержку, что скажется на скорости скрейпинга.
Сервисы для решения CAPTCHA
Кроме антидетекта, качественных прокси и продуманного скрипта с имитацией человеческого поведения, также может быть полезным авторешатель CAPTCHA. Для этого подойдут OSS-решения, сервисы по ручному решению вроде 2captcha и anti-captcha и автоматические солверы, такие как Capmonster.
Как антидетект-браузеры помогают в веб-скрейпинге
Для идентификации пользователей многие сайты и сервисы используют информацию об устройстве, браузере и подключении. Набор таких сведений называется цифровым фингерпринтом. На основе информации о фингерпринте системы защиты сайтов определяют, является ли пользователь подозрительным.
Конкретный набор анализируемых параметров может отличаться в зависимости от системы защиты сайта. Для подключения и правильного отображения контента браузер предоставляет более 50 различных параметров, связанных с вашим устройством, каждый из которых может быть частью цифрового отпечатка.
Также можно дать браузеру задачу на создание примитивного 2D- или 3D-изображения и на основе информации о том, как устройство выполняло эту задачу, сформировать хэш. Он будет отличать это устройство от других посетителей сайта. Так работает аппаратный фингерпринтинг по Canvas и WebGL.
Незначительные изменения некоторых признаков, информацию о которых браузер передает системе безопасности сайта, не помешают опознать уже знакомого пользователя. Можно сменить браузер, часовой пояс или разрешение экрана, но даже если сделать все это одновременно, вероятность идентификации останется высокой.
Фингерпринтинг, наряду с другими техниками анти-скрейпинга, такими как рейт-лимитинг, геолокация, WAF, челленджи и капчи, существует для защиты сайтов от автоматизированного взаимодействия с ними. Антидетект-браузер с качественной системой подмены фингерпринтов помогает обходить системы защиты сайтов. В результате повышается эффективность веб-скрейпинга: сбор данных становится более быстрым и надежным.
Как работают антидетект-браузеры
Роль антидетект-браузеров в обходе систем безопасности сайтов состоит в подмене цифрового отпечатка. С помощью антидетекта можно создавать множество браузерных профилей — виртуальных копий браузера, изолированных друг от друга и обладающих своим собственным набором характеристик и настроек: куки, историей браузера, расширениями, прокси, параметрами фингерпринта. Каждый браузерный профиль выглядит для систем безопасности сайтов как отдельный пользователь.
Как заниматься скрейпингом с помощью антидетект-браузера
В антидетект-браузерах обычно есть возможность автоматизации с помощью протокола Chrome Dev Tools. Он позволяет автоматизировать необходимые для скрейпинга действия через программные интерфейсы. Для удобной работы существуют OSS-библиотеки, такие как Puppeteer, Playwright, Selenium и т.п.
В Octo Browser вся необходимая документация для начала работы находится здесь, а подробные инструкции по работе с API можно найти здесь.
Поможет ли антидетект-браузер снизить стоимость скрейпинга
Антидетект-браузеры могут как увеличивать, так и уменьшать расходы на скрейпинг в зависимости от ресурса и условий.
Снижению расходов может способствовать уменьшение риска блокировок и автоматизация ручных задач. Для этого в антидетектах есть менеджер профилей и автосинхронизация данных профиля.Увеличению стоимости в основном способствует покупка лицензии на необходимое количество профилей.
При прочих равных условиях на длинной дистанции использование антидетект-браузера способствует экономии бюджета и снижению себестоимости скрейпинга.
Стоит ли веб-скрейпинг усилий по автоматизации
Веб-скрейпинг — это мощный инструмент для автоматического сбора и анализа данных. Компании используют его для получения необходимой информации и принятия обоснованных решений в сфере электронной коммерции.
Воспользуйтесь Python для эффективного поиска товаров, отзывов, описаний и цен на Amazon. Написание кода может потребовать некоторого времени и усилий, но результаты превзойдут все ожидания. Для того, чтобы избежать внимания систем безопасности, необходимо имитировать естественное поведение пользователя, использовать сторонние IP-адреса и регулярно менять цифровой отпечаток. Специализированные инструменты, такие как антидетект-браузеры и прокси-серверы, позволят вам ротировать отпечатки браузера и IP-адреса, чтобы преодолеть ограничения и увеличить скорость скрейпинга.
Часто задаваемые вопросы
Какие данные можно извлекать с помощью веб-скрейпинга?
С помощью веб-скрейпинга можно извлекать текст, изображения, таблицы, метаданные и многое другое.
Можно ли обнаружить скрейпинг?
Да, парсинг данных может быть обнаружен антибот-системой, которая может проверить ваш IP-адрес, совпадение параметров цифрового отпечатка и поведенческие шаблоны. При провале проверки доступ к страницам сайта с вашего IP и устройства будет заблокирован.
Как избежать блокировок при веб-скрейпинге?
Используйте прокси-серверы, имитируйте действия пользователя и добавляйте задержки между запросами.
Какие правовые аспекты веб-скрейпинга нужно учитывать?
Юридические аспекты веб-скрейпинга регулируются законодательством в области защиты персональных данных и права интеллектуальной собственности. Скраппинг общедоступных данных, содержащихся на сайтах, не считается незаконным, если ваши действия не нарушают их ToS. Соблюдайте правила использования сайтов и учитывайте правовые аспекты веб-скрейпинга.
Разрешает ли Amazon скрейпинг?
Скрейпинг общедоступных данных, содержащихся на сайте Amazon, не считается незаконным, если ваши действия не нарушают его ToS.
Каковы основные ошибки, которые могут возникнуть при веб-скрейпинге, и как их избежать?
Типичные ошибки включают проблемы с разбором HTML, отслеживанием изменений в структуре сайта и превышением ограничения скорости запросов. Чтобы их избежать, регулярно проверяйте и обновляйте свой код.
Как минимизировать появление CAPTCHA при скрейпинге Amazon?
Используйте надежные прокси-серверы и чередуйте IP-адреса. Снижайте скорость скрейпинга, добавляя случайные паузы между запросами и действиями. Убедитесь, что параметры цифровых отпечатков соответствуют реальным устройствам и не вызывают подозрений у антибот-системы.
Сохраняйте анонимность, используйте преимущества мультиаккаунтинга и добивайтесь своих целей с самым качественным решением на рынке антидетект-браузеров.
Хотите попробовать Octo Browser со скидкой?
По промокоду OCTOSCRAPER получите 30% скидку на любую подписку. Предложение действительно только для новых пользователей.
Что такое веб-скрейпинг
Веб-скрейпинг (web scraping) — это процесс автоматизированного сбора данных с сайтов. Специальные программы или скрипты, называемые скрейперами, извлекают информацию из веб-страниц и преобразуют ее в структурированный формат данных, удобный для дальнейшего анализа и использования. Наиболее распространенные форматы для хранения и последующей обработки данных — CSV, JSON, SQL или Excel.
В настоящее время веб-скрейпинг широко применяется в области Data Science, маркетинге и электронной коммерции. Веб-скрейперы собирают огромные объемы информации для личных и профессиональных целей. Более того, современные технологические гиганты полагаются на методы веб-скрейпинга, чтобы отслеживать и анализировать тренды.
Инструменты и технологии для веб-скрейпинга
Python и библиотеки
Python является одним из наиболее популярных языков программирования для веб-скрейпинга. Он известен своей простой и понятной синтаксической структурой, что делает его идеальным выбором как для начинающих, так и для опытных программистов. Еще одним преимуществом является широкий выбор библиотек для работы с веб-скрейпингом, таких как Beautiful Soup, Scrapy, Requests и Selenium. Эти библиотеки позволяют легко отправлять HTTP-запросы, обрабатывать HTML-документы и взаимодействовать с веб-страницами.
API-интерфейсы
Amazon предоставляет API для доступа к своим данным, такие как Amazon Product Advertising API. Это позволяет запрашивать определенные сведения в структурированном формате без необходимости парсинга всей HTML-страницы.
Облачные сервисы
Облачные платформы, такие как AWS Lambda и Google Cloud Functions, могут использоваться для автоматизации и масштабирования процессов веб-скрейпинга. Они обеспечивают высокую производительность и возможность обработки больших объемов данных.
Специализированные инструменты
Существуют дополнительные инструменты для веб-скрейпинга, такие как антидетект-браузеры и прокси. Их роль состоит в подмене цифрового отпечатка для обхода ограничений систем безопасности сайтов. Эти инструменты ускоряют сбор данных.
Применение веб-скрейпинга для Amazon
Анализ рынка и конкурентов
Веб-скрейпинг позволяет собирать данные о товарах и ценах конкурентов, анализировать их ассортимент и выявлять тренды. Это помогает компаниям адаптировать свои стратегии и оставаться конкурентоспособными.
Мониторинг цен
Сбор данных о ценах на аналогичные товары помогает компаниям устанавливать конкурентные цены и оперативно реагировать на изменения рынка. Это особенно важно в условиях динамичных цен и промоакций.
Сбор отзывов и рейтингов
Отзывы и рейтинги являются важным источником информации о восприятии товаров потребителями. Анализ этих данных позволяет выявлять сильные и слабые стороны продуктов, а также получать идеи для их улучшения.
Исследование ассортимента
С помощью веб-скрейпинга можно анализировать ассортимент товаров на Amazon, выявлять популярные категории и на основе этого принимать решения о расширении или изменении товарного портфеля.
Отслеживание новых товаров
Веб-скрейпинг помогает оперативно узнавать о появлении новых товаров на платформе, что может быть полезно для производителей, дистрибьюторов и аналитиков рынка.
Навигация по элементам интерфейса Amazon
Перед тем, как начать скрейпинг, важно понять, как структурированы веб-страницы. Большинство веб-страниц написаны на HTML и содержат элементы, такие как теги, атрибуты и классы. Знание HTML поможет вам правильно идентифицировать и извлекать нужные данные.
На домашней странице Amazon покупатели используют поисковую строку для ввода ключевых слов, связанных с желаемым продуктом. В результате они получают список с названиями товаров, ценами, рейтингами и другими существенными атрибутами. Дополнительно товары могут быть отфильтрованы по различным параметрам, таким как ценовой диапазон, категория товара и отзывы покупателей. Навигация по этим компонентам помогает пользователям легко находить интересующие их товары, сравнивать альтернативные варианты, просматривать дополнительную информацию и удобно осуществлять покупки на платформе Amazon.
Главная страница Amazon с запросом Octopus
Для получения более обширного списка результатов вы можете воспользоваться кнопками пагинации, расположенными в нижней части страницы. На каждой странице обычно размещается большое количество объявлений, что позволяет вам просматривать дополнительные товары. Фильтры, находящиеся в верхней части страницы, позволяют уточнить поиск в соответствии с вашими требованиями.
Чтобы получить представление об HTML-структуре Amazon, выполните следующие действия:
Зайдите на сайт.
Введите нужный товар в строку поиска или выберите категорию из списка товаров.
Откройте инструменты разработчика браузера, нажав правой кнопкой мыши на товаре и выбрав пункт «Посмотреть код» из выпадающего меню.
Изучите HTML-макет, чтобы определить теги и атрибуты данных, которые вы собираетесь извлечь.
Основные шаги для начала скрейпинга
Веб-скрейпинг сводится к двум основным этапам: поиску необходимых сведений и их структурированию. После изучения структуры сайта переходим к установке компонентов для автоматизации скрейпинга.
Итак, для работы мы используем Python и библиотеки:
HTTPX: это полностью асинхронная HTTP-библиотека для Python, которая поддерживает синхронное выполнение запросов. Библиотека HTTPX предоставляет стандартный интерфейс для HTTP, аналогичный популярной библиотеке requests, но также поддерживает асинхронность, протоколы HTTP/1.1, HTTP/2, HTTP/3 и подключение через SOCKS.
BeautifulSoup: библиотека разработана для удобного и быстрого парсинга HTML- и XML-документов. Она предоставляет простой интерфейс для навигации, поиска и модификации дерева документа, что делает процесс веб-скрейпинга более интуитивным. Это позволяет извлекать информацию со страницы путем поиска тегов, атрибутов или определенного текста.
Selenium: для взаимодействия с динамическими веб-страницами.
Pandas: это мощная и надежная библиотека для обработки и очистки данных. Например, после извлечения данных с веб-страниц вы можете использовать Pandas для устранения пропусков, преобразования данных в нужный формат и удаления дубликатов.
Playwright: позволяет эффективно взаимодействовать с веб-страницами, которые используют JavaScript для динамического обновления контента. Это делает его особенно полезным для скрейпинга таких сайтов, как Amazon, где многие элементы загружаются асинхронно.
Scrapy: для более сложных задач веб-скрейпинга.
После того, как вы подготовили Python, откройте терминал или оболочку и создайте новый каталог проекта с помощью следующих команд:
mkdir scraping-amazon-python cd scraping-amazon-python
Чтобы установить библиотеки, откройте терминал или оболочку и выполните следующие команды:
pip install httpx pip3 install pandas pip3 install playwright playwright install
Обратите внимание: последняя команда (playwright install) имеет решающее значение, поскольку она обеспечивает правильную установку необходимых файлов браузера.
Убедитесь, что процесс установки завершился без каких-либо проблем, прежде чем переходить к следующему шагу. Если у вас возникают трудности при настройке окружения, вы можете обратиться к ИИ-сервисам, таким как ChatGPT, Mistral AI и другим. Эти сервисы могут помочь с запросами о возникших ошибках и предоставить пошаговые инструкции для их устранения.
Использование Python и библиотек для веб-скрейпинга
В каталоге вашего проекта создайте новый Python-скрипт amazon_scraper.py и добавьте код, приведенный в версии статьи на сайте.
import httpx from playwright.async_api import async_playwright import asyncio import pandas as pd # Profile's uuid from Octo PROFILE_UUID = "UUID_SHOULD_BE_HERE" # searching request SEARCH_REQUEST = "fashion" async def main(): async with async_playwright() as p: async with httpx.AsyncClient() as client: response = await client.post( 'http://127.0.0.1:58888/api/profiles/start', json={ 'uuid': PROFILE_UUID, 'headless': False, 'debug_port': True } ) if not response.is_success: print(f'Start response is not successful: {response.json()}') return start_response = response.json() ws_endpoint = start_response.get('ws_endpoint') browser = await p.chromium.connect_over_cdp(ws_endpoint) page = browser.contexts[0].pages[0] # Opening Amazon await page.goto(f'https://www.amazon.com/s?k={SEARCH_REQUEST}') # Extract information results = [] listings = await page.query_selector_all('div.a-section.a-spacing-small') for listing in listings: result = {} # Product name name_element = await listing.query_selector('h2.a-size-mini > a > span') result['product_name'] = await name_element.inner_text() if name_element else 'N/A' # Rating rating_element = await listing.query_selector('span[aria-label*="out of 5 stars"] > span.a-size-base') result['rating'] = (await rating_element.inner_text())[0:3] if rating_element else 'N/A' # Number of reviews reviews_element = await listing.query_selector('span[aria-label*="stars"] + span > a > span') result['number_of_reviews'] = await reviews_element.inner_text() if reviews_element else 'N/A' # Price price_element = await listing.query_selector('span.a-price > span.a-offscreen') result['price'] = await price_element.inner_text() if price_element else 'N/A' if(result['product_name']=='N/A' and result['rating']=='N/A' and result['number_of_reviews']=='N/A' and result['price']=='N/A'): pass else: results.append(result) # Close browser await browser.close() return results # Run the scraper and save results to a CSV file results = asyncio.run(main()) df = pd.DataFrame(results) df.to_csv('amazon_products_listings.csv', index=False)
В этом коде мы используем асинхронные возможности Python с библиотекой Playwright, чтобы извлечь списки товаров с определенной страницы Amazon. Мы запускаем профиль в Octo Browser, и далее происходит подключение к нему через библиотеку Playwright. После открывается URL c определенным поисковым запросом, который можно отредактировать вверху скрипта в переменной «SEARCH_REQUEST».
Запустив браузер и перейдя на целевой URL-адрес Amazon, вы извлечете информацию о товаре: его название, рейтинг, количество отзывов и цену. После итераций по каждому объявлению на странице вы можете отфильтровать объявления, в которых нет данных. Скрипт пометит их как «N/A». Результаты поиска сохраняются в Pandas DataFrame, а затем экспортируются в CSV-файл amazon_products_listings.csv.
Что еще нужно для эффективного веб-скрейпинга
Веб-скрейпинг Amazon без прокси-серверов и специальных инструментов для скрейпинга сопряжен со множеством препятствий. Как и на многих других популярных платформах, на Amazon действует ограничение частоты запросов, то есть он может заблокировать ваш IP-адрес, если вы превысите установленный лимит. Кроме того, Amazon использует алгоритмы обнаружения ботов, которые идентифицируют ваш цифровой отпечаток при обращении к страницам сайта.
Учитывая эти факторы, рекомендуется следовать некоторым общепринятым практикам, чтобы избежать обнаружения и блокировки со стороны Amazon. Вот некоторые из наиболее полезных советов:
Имитация естественного поведения
Amazon может блокировать или временно приостанавливать деятельность, которую он сочтет роботизированной или подозрительной. Очень важно, чтобы ваш парсер выглядел как можно более человекоподобным.
Чтобы разработать успешный шаблон краулинга, подумайте о том, как будет вести себя обычный пользователь при изучении страницы, и добавьте клики, прокрутки и движения мыши в соответствии с этим. Чтобы избежать блокировки, нужно вводить задержки или случайные интервалы между запросами с помощью функций вроде asyncio.sleep(random.uniform(1, 5)). Так ваш шаблон будет выглядеть менее роботизированным.
Правдоподобный фингерпринт
Используйте антидетект-браузер, чтобы имитировать цифровой отпечаток реального устройства. Такие платформы, как Amazon, собирают различные параметры фингерпринта для обнаружения ботов. Чтобы не попасть впросак, необходимо следить за тем, чтобы параметры фингерпринта всегда были правдоподобными.
Кроме того, для снижения риска обнаружения следует чередовать IP-адреса. Очень важную роль при работе с антидетект-браузером играют качественные прокси. Нужно выбирать провайдеров с хорошей репутацией и самой низкой ценой. Прокси следует подбирать в соответствии со стратегией скрейпинга и учитывать ГЕО, так как платформа предоставляет разный контент для разных регионов, и проверять прокси на низкий spam/abuse/fraud score. Также следует учитывать скорость прокси. Например, резидентные прокси могут иметь высокую задержку, что скажется на скорости скрейпинга.
Сервисы для решения CAPTCHA
Кроме антидетекта, качественных прокси и продуманного скрипта с имитацией человеческого поведения, также может быть полезным авторешатель CAPTCHA. Для этого подойдут OSS-решения, сервисы по ручному решению вроде 2captcha и anti-captcha и автоматические солверы, такие как Capmonster.
Как антидетект-браузеры помогают в веб-скрейпинге
Для идентификации пользователей многие сайты и сервисы используют информацию об устройстве, браузере и подключении. Набор таких сведений называется цифровым фингерпринтом. На основе информации о фингерпринте системы защиты сайтов определяют, является ли пользователь подозрительным.
Конкретный набор анализируемых параметров может отличаться в зависимости от системы защиты сайта. Для подключения и правильного отображения контента браузер предоставляет более 50 различных параметров, связанных с вашим устройством, каждый из которых может быть частью цифрового отпечатка.
Также можно дать браузеру задачу на создание примитивного 2D- или 3D-изображения и на основе информации о том, как устройство выполняло эту задачу, сформировать хэш. Он будет отличать это устройство от других посетителей сайта. Так работает аппаратный фингерпринтинг по Canvas и WebGL.
Незначительные изменения некоторых признаков, информацию о которых браузер передает системе безопасности сайта, не помешают опознать уже знакомого пользователя. Можно сменить браузер, часовой пояс или разрешение экрана, но даже если сделать все это одновременно, вероятность идентификации останется высокой.
Фингерпринтинг, наряду с другими техниками анти-скрейпинга, такими как рейт-лимитинг, геолокация, WAF, челленджи и капчи, существует для защиты сайтов от автоматизированного взаимодействия с ними. Антидетект-браузер с качественной системой подмены фингерпринтов помогает обходить системы защиты сайтов. В результате повышается эффективность веб-скрейпинга: сбор данных становится более быстрым и надежным.
Как работают антидетект-браузеры
Роль антидетект-браузеров в обходе систем безопасности сайтов состоит в подмене цифрового отпечатка. С помощью антидетекта можно создавать множество браузерных профилей — виртуальных копий браузера, изолированных друг от друга и обладающих своим собственным набором характеристик и настроек: куки, историей браузера, расширениями, прокси, параметрами фингерпринта. Каждый браузерный профиль выглядит для систем безопасности сайтов как отдельный пользователь.
Как заниматься скрейпингом с помощью антидетект-браузера
В антидетект-браузерах обычно есть возможность автоматизации с помощью протокола Chrome Dev Tools. Он позволяет автоматизировать необходимые для скрейпинга действия через программные интерфейсы. Для удобной работы существуют OSS-библиотеки, такие как Puppeteer, Playwright, Selenium и т.п.
В Octo Browser вся необходимая документация для начала работы находится здесь, а подробные инструкции по работе с API можно найти здесь.
Поможет ли антидетект-браузер снизить стоимость скрейпинга
Антидетект-браузеры могут как увеличивать, так и уменьшать расходы на скрейпинг в зависимости от ресурса и условий.
Снижению расходов может способствовать уменьшение риска блокировок и автоматизация ручных задач. Для этого в антидетектах есть менеджер профилей и автосинхронизация данных профиля.Увеличению стоимости в основном способствует покупка лицензии на необходимое количество профилей.
При прочих равных условиях на длинной дистанции использование антидетект-браузера способствует экономии бюджета и снижению себестоимости скрейпинга.
Стоит ли веб-скрейпинг усилий по автоматизации
Веб-скрейпинг — это мощный инструмент для автоматического сбора и анализа данных. Компании используют его для получения необходимой информации и принятия обоснованных решений в сфере электронной коммерции.
Воспользуйтесь Python для эффективного поиска товаров, отзывов, описаний и цен на Amazon. Написание кода может потребовать некоторого времени и усилий, но результаты превзойдут все ожидания. Для того, чтобы избежать внимания систем безопасности, необходимо имитировать естественное поведение пользователя, использовать сторонние IP-адреса и регулярно менять цифровой отпечаток. Специализированные инструменты, такие как антидетект-браузеры и прокси-серверы, позволят вам ротировать отпечатки браузера и IP-адреса, чтобы преодолеть ограничения и увеличить скорость скрейпинга.
Часто задаваемые вопросы
Какие данные можно извлекать с помощью веб-скрейпинга?
С помощью веб-скрейпинга можно извлекать текст, изображения, таблицы, метаданные и многое другое.
Можно ли обнаружить скрейпинг?
Да, парсинг данных может быть обнаружен антибот-системой, которая может проверить ваш IP-адрес, совпадение параметров цифрового отпечатка и поведенческие шаблоны. При провале проверки доступ к страницам сайта с вашего IP и устройства будет заблокирован.
Как избежать блокировок при веб-скрейпинге?
Используйте прокси-серверы, имитируйте действия пользователя и добавляйте задержки между запросами.
Какие правовые аспекты веб-скрейпинга нужно учитывать?
Юридические аспекты веб-скрейпинга регулируются законодательством в области защиты персональных данных и права интеллектуальной собственности. Скраппинг общедоступных данных, содержащихся на сайтах, не считается незаконным, если ваши действия не нарушают их ToS. Соблюдайте правила использования сайтов и учитывайте правовые аспекты веб-скрейпинга.
Разрешает ли Amazon скрейпинг?
Скрейпинг общедоступных данных, содержащихся на сайте Amazon, не считается незаконным, если ваши действия не нарушают его ToS.
Каковы основные ошибки, которые могут возникнуть при веб-скрейпинге, и как их избежать?
Типичные ошибки включают проблемы с разбором HTML, отслеживанием изменений в структуре сайта и превышением ограничения скорости запросов. Чтобы их избежать, регулярно проверяйте и обновляйте свой код.
Как минимизировать появление CAPTCHA при скрейпинге Amazon?
Используйте надежные прокси-серверы и чередуйте IP-адреса. Снижайте скорость скрейпинга, добавляя случайные паузы между запросами и действиями. Убедитесь, что параметры цифровых отпечатков соответствуют реальным устройствам и не вызывают подозрений у антибот-системы.
Следите за последними новостями Octo Browser
Нажимая кнопку, вы соглашаетесь с нашей политикой конфиденциальности.
Следите за последними новостями Octo Browser
Нажимая кнопку, вы соглашаетесь с нашей политикой конфиденциальности.
Следите за последними новостями Octo Browser
Нажимая кнопку, вы соглашаетесь с нашей политикой конфиденциальности.

Присоединяйтесь к Octo Browser сейчас
Вы можете обращаться за помощью к нашим специалистам службы поддержки в чате в любое время.
Присоединяйтесь к Octo Browser сейчас
Вы можете обращаться за помощью к нашим специалистам службы поддержки в чате в любое время.
Присоединяйтесь к Octo Browser сейчас
Вы можете обращаться за помощью к нашим специалистам службы поддержки в чате в любое время.