Behavioral analysis: what it is and how automation specialists can bypass it
5/22/26


Markus_automation
Expert in data parsing and automation
Not long ago, anti-fraud systems relied primarily on technical attributes—IP addresses, cookies, and browser fingerprints. However, as developers of scripts and scrapers learned to effectively spoof these parameters, the focus of protection shifted toward behavioral analysis.
Behavioral biometrics evaluates how exactly a user interacts with an interface and is gradually becoming a key component of modern automation detection systems.
In this article, we discuss how this approach works and explain how to realistically reproduce human behavior in automated scenarios.
Contents
Stay anonymous, take advantage of multi-accounting, and achieve your goals with the highest-quality anti-detect browser on the market.
Would you like to try Octo Browser at discount?
Use the promo code OCTOSCRAPER to get 30% off any subscription. This offer is valid only for new users.
Why CAPTCHAs are giving way to behavioral analysis
Previously, CAPTCHA was the primary defense mechanism against bots. CAPTCHAs still exist today, though they have changed significantly. They have become more sophisticated, and some modern invisible versions (such as reCAPTCHA v3) have incorporated the very behavioral biometrics we are discussing.
Why is this necessary? Traditional CAPTCHAs (traffic lights and distorted characters) worsen the user experience and are increasingly being solved effortlessly by trained neural networks. The new approach, which works without visible elements, removes much of the burden from users and avoids annoying them.
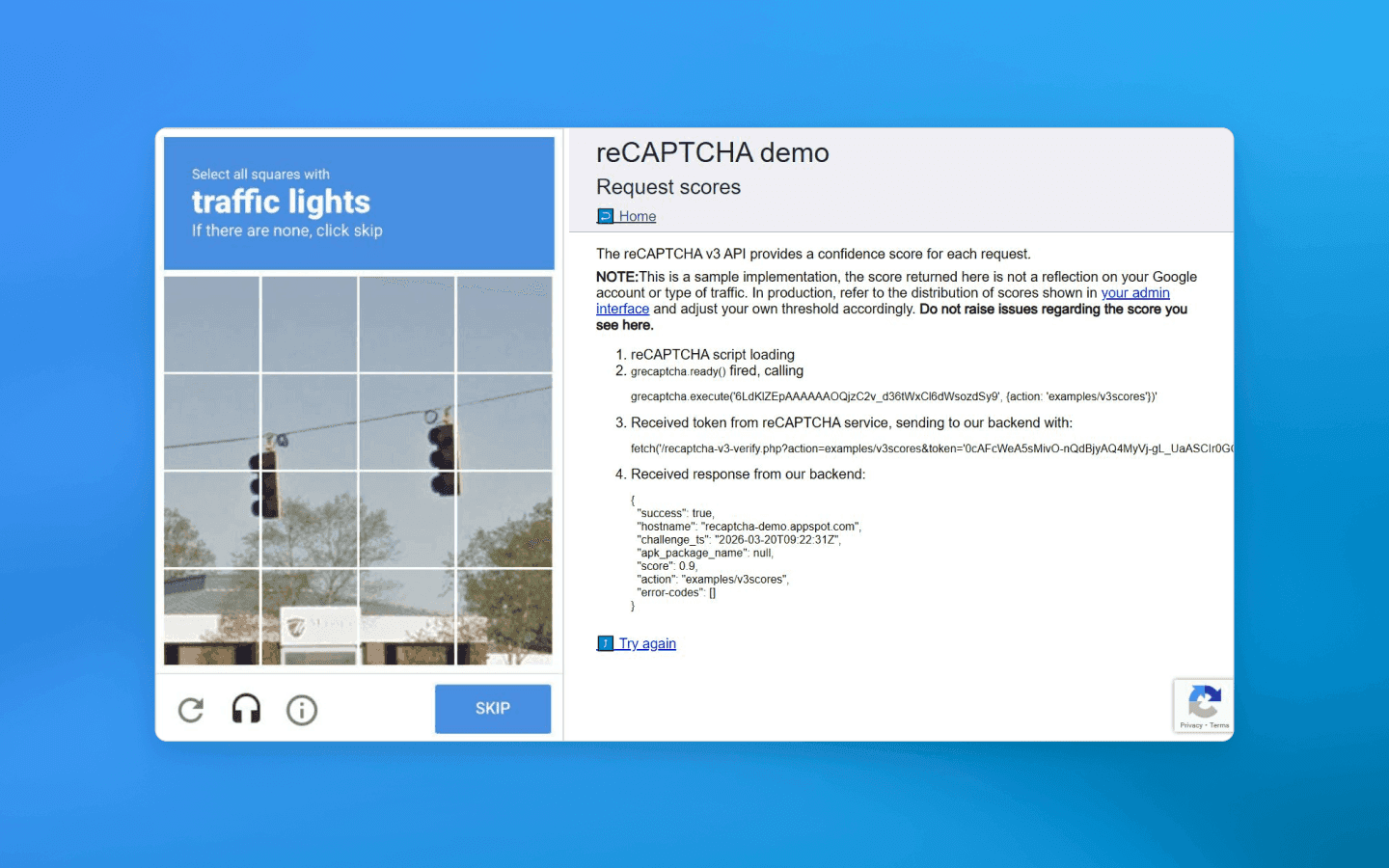
Behavioral biometrics, as the core of this invisible verification process, offers continuous authentication. It works by analyzing how exactly a user interacts with a device while scrolling a page or filling out a form, without requiring any additional input.
However, an important clarification should be made: behavioral biometrics is not used as a standalone verification method. It always works alongside other checks. In addition to biometrics, anti-fraud systems still analyze digital fingerprints, IP reputation, and cookies.
Types of behavioral biometrics
Let’s dive deeper into the theory. Behavioral patterns are essentially a digital fingerprint of your nervous system transferred onto a device. Advanced anti-fraud systems do not analyze parameters separately. Instead, they build a comprehensive multidimensional profile that can be divided into the following categories:
Device interaction (kinesthetics)
This is the largest layer of data for the traditional web and mobile applications. Here, systems analyze the physics of user movements.
Keyboard: it’s not about which letters or numbers you type. Anti-fraud systems evaluate two main parameters: how long a key is held down (
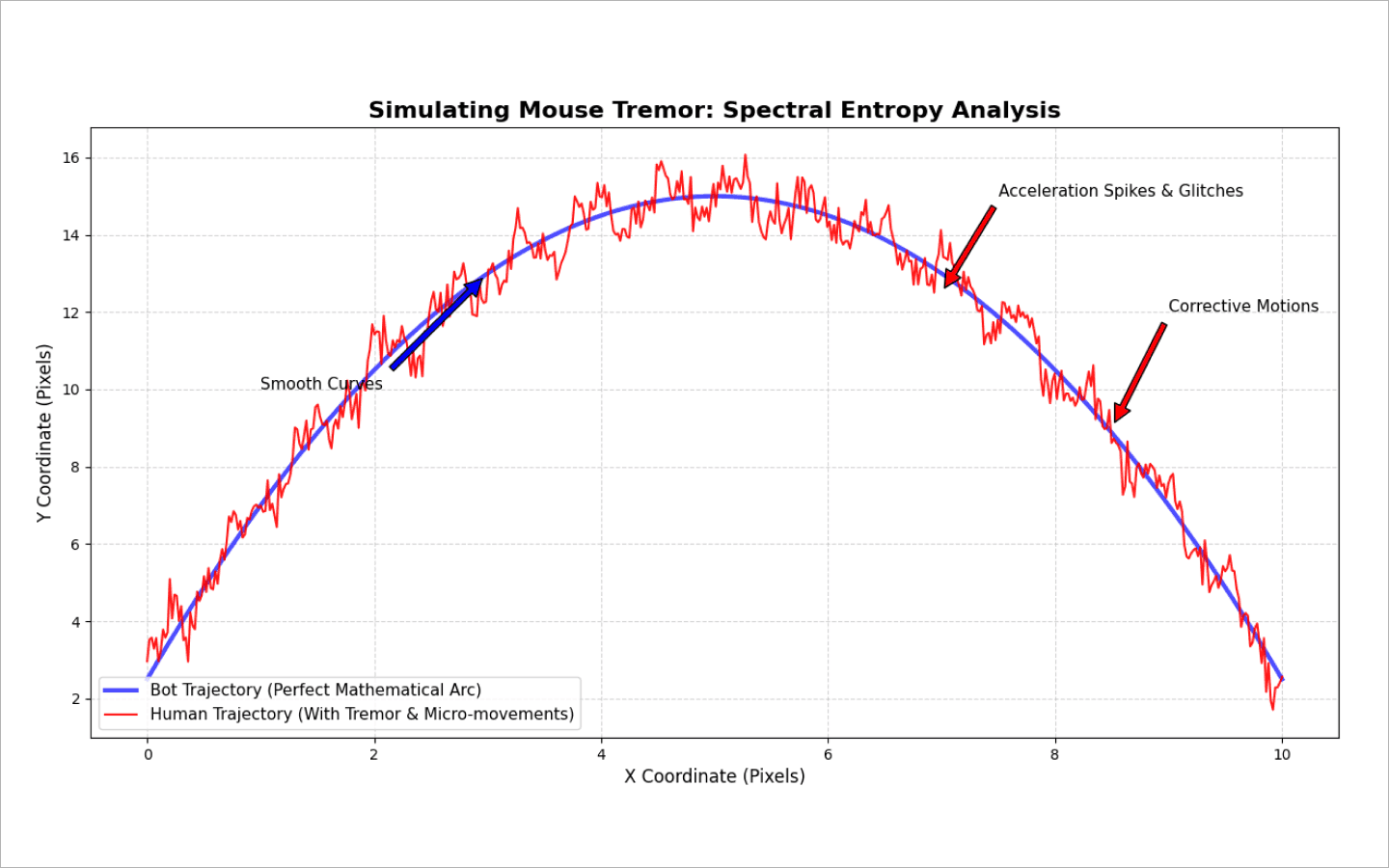
dwell time) and how long it takes to move between keys (flight time). Humans have muscle memory — familiar key combinations (for example, common word endings) are typed in micro-bursts. Bots, meanwhile, either inject entire strings at once or imitate typing using simplistictime.sleep(random)logic. This creates a flat, unnatural delay distribution. Randomness itself becomes suspicious.Mouse: cursor analytics. The system records coordinates and calculates speed, acceleration, trajectory curvature, and jerks. Humans do not move a mouse in perfectly straight lines. We aim for a button, miss by a few pixels, make tiny corrective movements, and briefly pause before clicking.
Touchscreen: specific for mobile web and native applications. A human swipe is an arc with uneven speed, specific pressure (if the API allows pressure detection), and a changing finger contact area. Bots that emulate touch events through Appium or JavaScript scripts often simply “teleport” focus coordinates. Writing the proper math for a realistic swipe is more difficult, so bot operators often cut corners.
Physical patterns (biomechanics)
When a user accesses a platform from a mobile device, hardware sensors come into play. And since we now live in the era of mobile users, this matters a lot.
Walking patterns and micromovements. Are you scrolling your feed while walking, sitting in a chair, or lying on a couch? A smartphone’s accelerometer and gyroscope constantly capture tiny device vibrations. A real user’s phone always slightly trembles in their hands, even when they try to hold it perfectly still. Bot farms and emulators running on servers usually have zero sensor background noise by default, giving anti-fraud systems something to think about and increasing the risk score.
Cognitive patterns (interaction psychology)
This is where systems analyze how a user’s brain works while interacting with a UI.
Navigation and decision-making speed. How quickly does a user find the required button? Do they read the text before checking a checkbox? People often move the cursor across text while reading, similar to tracing lines in a book with a finger, or pause on complicated forms. Some users even highlight the text. A scraper script, on the other hand, has no doubts— t knows the DOM structure perfectly and triggers the required event exactly after a predefined timeout, completely ignoring the logic of visual search.
Together, these three levels create such a complex profile that fully replicating it by simply adding random delays to Selenium or Puppeteer code becomes mathematically impossible.
Data collection and preprocessing
The primary sources for collecting biometric data are mousemove, keydown, keyup, touchstart, and touchend events, as well as the DeviceOrientation API for capturing accelerometer and gyroscope readings.
The most difficult part at this stage is handling the enormous volume of fragmented and asynchronous data. A single mousemove event alone can fire hundreds of times per second. If every cursor movement triggered backend processing or heavy computations directly on the client side, the anti-fraud system would instantly freeze the UI and cause noticeable lag on the client’s website. No business would accept that.
That is why client-side collection scripts are designed to be as lightweight and primitive as possible. Their only task is to quickly capture coordinates, attach precise timestamps, store everything in a local buffer, and send the data to the server in a batch.
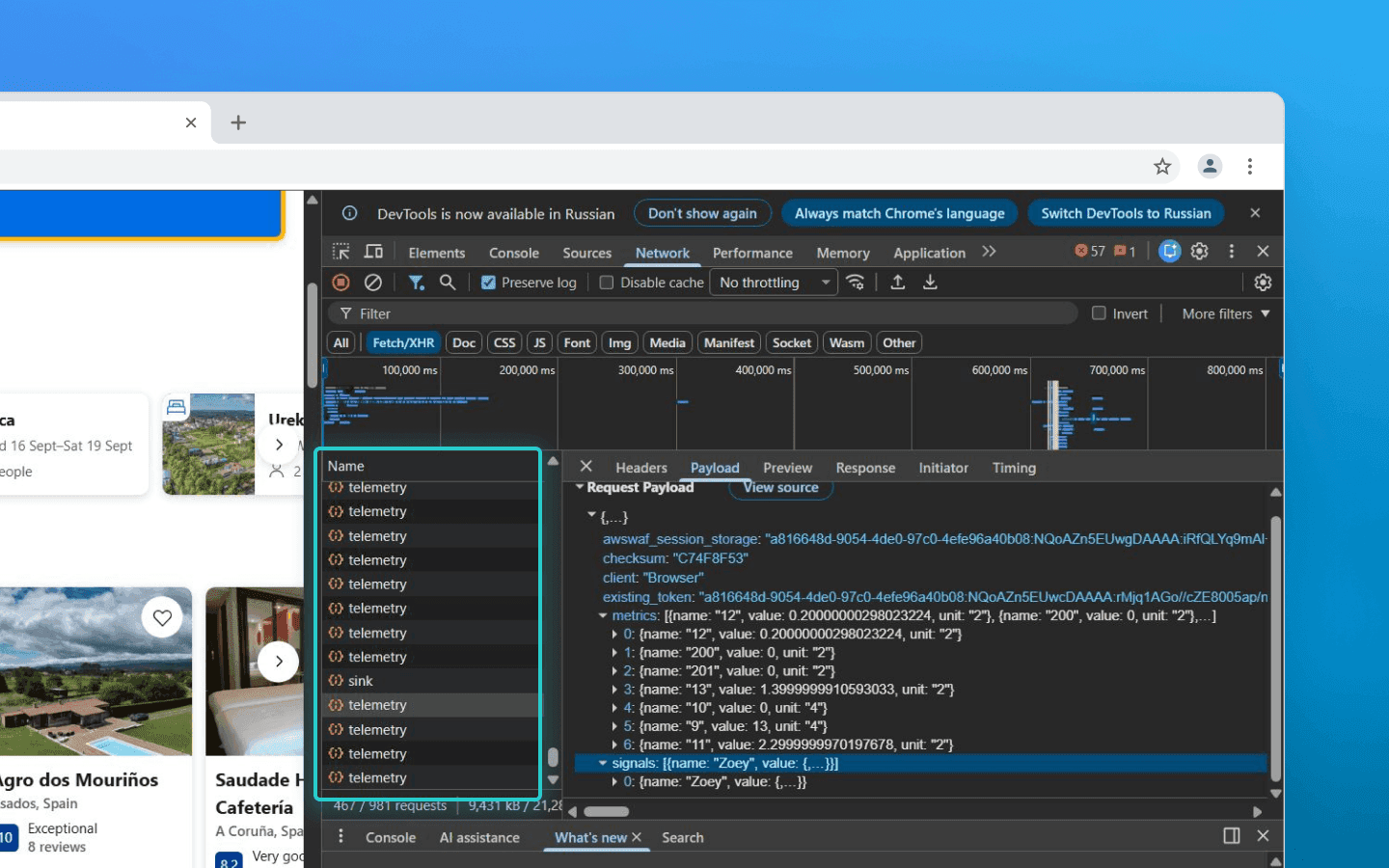
These batches of JSON objects are then transmitted to the backend. In high-load systems, they are not written directly into databases or immediately passed to ML models. First, they are routed through message brokers such as Kafka or RabbitMQ. This is necessary to smooth out traffic spikes, for example, during large-scale bot attacks or natural surges of real users during sales or promotions. At this point, the client-side responsibility ends.
Feature engineering and ML models
So, the raw batches have reached the server. What happens next?
If you simply feed this array of pixels into an ML model, it will not learn to distinguish humans from bots. It will merely memorize where the buttons are located on your website and break as soon as the layout changes slightly. Machine learning models do not need screen geography, they need behavioral abstractions.
That is why there is a dedicated microservice layer called feature engineering located between the message queue and the neural networks. These are usually pipelines built on Pandas and NumPy that aggregate logs and transform them into data suitable for ML models. They calculate:
Euclidean distances between points;
time deltas;
instantaneous velocities;
trajectory turning angles.
Based on these calculations, the anti-fraud system builds a complex behavioral feature profile:
Keyboard: delay vectors (
dwell timeandflight time), along with their median, variance, and standard deviation. In other words, how consistent the typing rhythm is.Mouse: statistics on speed and acceleration, the number of micro-pauses, and the spectral entropy of the trajectory. This metric shows whether movement appears chaotic (like a human) or mathematically perfect (like a script).
Touchscreen: gradients of pressure and contact-area changes during a swipe (in cases where the browser or OS API shares such data).
Cognitive features:
idle timeand delays before focusing on target elements. For example, a pause before clicking the “Pay” button while a user mentally double-checks the amount.
Hundreds of such parameters are extracted from a single session, stripped of layout-specific context, and then passed to ML models.
Classical ML algorithms (Random Forest, SVM, Gradient Boosting)
These perform exceptionally well with aggregated statistical features. They operate quickly, consume minimal server resources, and are typically used as the first and fastest line of defense.
Essentially, they run the entire vector of session statistics (action speed, timing variance, entropy, and so on) through a system of carefully calibrated mathematical thresholds, instantly filtering out obvious anomalies such as zero variance in cursor acceleration or unnaturally consistent click intervals.
Neural networks (LSTM, GRU, and 1D-CNN)
While classical algorithms focus on the overall statistical picture, recurrent neural networks analyze the actual sequence of cursor movements over time.
Recurrent networks are designed for processing sequential data (text, speech, time series), where the context of previous elements matters. Unlike traditional networks, recurrent architectures have “memory” through feedback loops, allowing them to account for information from previous steps. As a result, they can detect unnatural patterns and rhythms that are hidden by ordinary statistical averaging.
Autoencoders and anomaly detection
The biggest challenge for anti-fraud systems is that bot developers constantly invent new spoofing techniques. Training a model on every existing bot is impossible, but there are millions of sessions generated by real humans. That is why unsupervised learning, particularly autoencoders, is widely used.
An autoencoder is a neural network trained exclusively on human behavior. It works like a specialized filter: it takes session parameters as input, mathematically compresses them into a compact representation, and then attempts to reconstruct the original data.
Because such a network has only seen genuine human sessions, it has learned the physics of human movement with near-perfect accuracy and can reconstruct such data almost flawlessly. But if the behavior of a previously unseen bot—no matter how sophisticated—is fed into the model, the network will attempt to apply human compression rules to it. As a result, the reconstruction stage will produce inaccurate output.
When there is a large discrepancy between the original data and what the network managed to reconstruct, this becomes a reconstruction error. The greater the error, the higher the risk score, signaling anomalous behavior.
Single-method checks vs. hybrid systems
Relying on only one type of verification is ineffective, which is why no one uses a single model. In most cases, the architecture is built as a cascade: lightweight ML algorithms can instantly filter out up to 90% of simple scripts and bots, while heavier neural networks are activated only for borderline cases in which earlier checks have yielded uncertain results. This approach significantly reduces computational costs.
Feature drift and adaptation
Real human behavior can change over time, just like their device’s digital fingerprint. A user may buy a new mouse with different DPI settings, switch from a desktop computer to a laptop with a touchpad, injure their hand, drink a double espresso, or simply become exhausted by the end of the workday. All of this instantly changes their typing rhythm, fine motor control, and reaction speed.
If an anti-fraud model is static and relies on a reference profile collected years ago, it will inevitably start blocking legitimate users. The percentage of false positives will rise, conversion rates will fall, and businesses will lose both revenue and customer loyalty.
As a result, anti-fraud systems must continuously evolve alongside users and adapt to changing conditions.
Real-time neural network training
Unlike traditional batch training, where a model is retrained once a month on a massive accumulated dataset, online learning allows the algorithm to adjust its weights continuously in real time. As soon as a valid session ends—confirmed, for example, by a purchase or successful 2FA verification—its features slightly shift the model’s decision thresholds. This perfectly accounts for gradual changes in user habits.
Sliding memory window
Algorithms also rely on the sliding memory window principle: fresh session data is constantly added to the reference behavioral profile and assigned the highest mathematical weight. Older records gradually lose influence until their contribution approaches zero. The system always compares current behavior against how the user has behaved over recent weeks, not against the moment the account was created years ago.
Statistical monitoring
But how does the system distinguish between a legitimate change, such as buying a new mouse, and a sudden session spoofing by a sophisticated bot? For this purpose, strict statistical monitoring is applied, including:
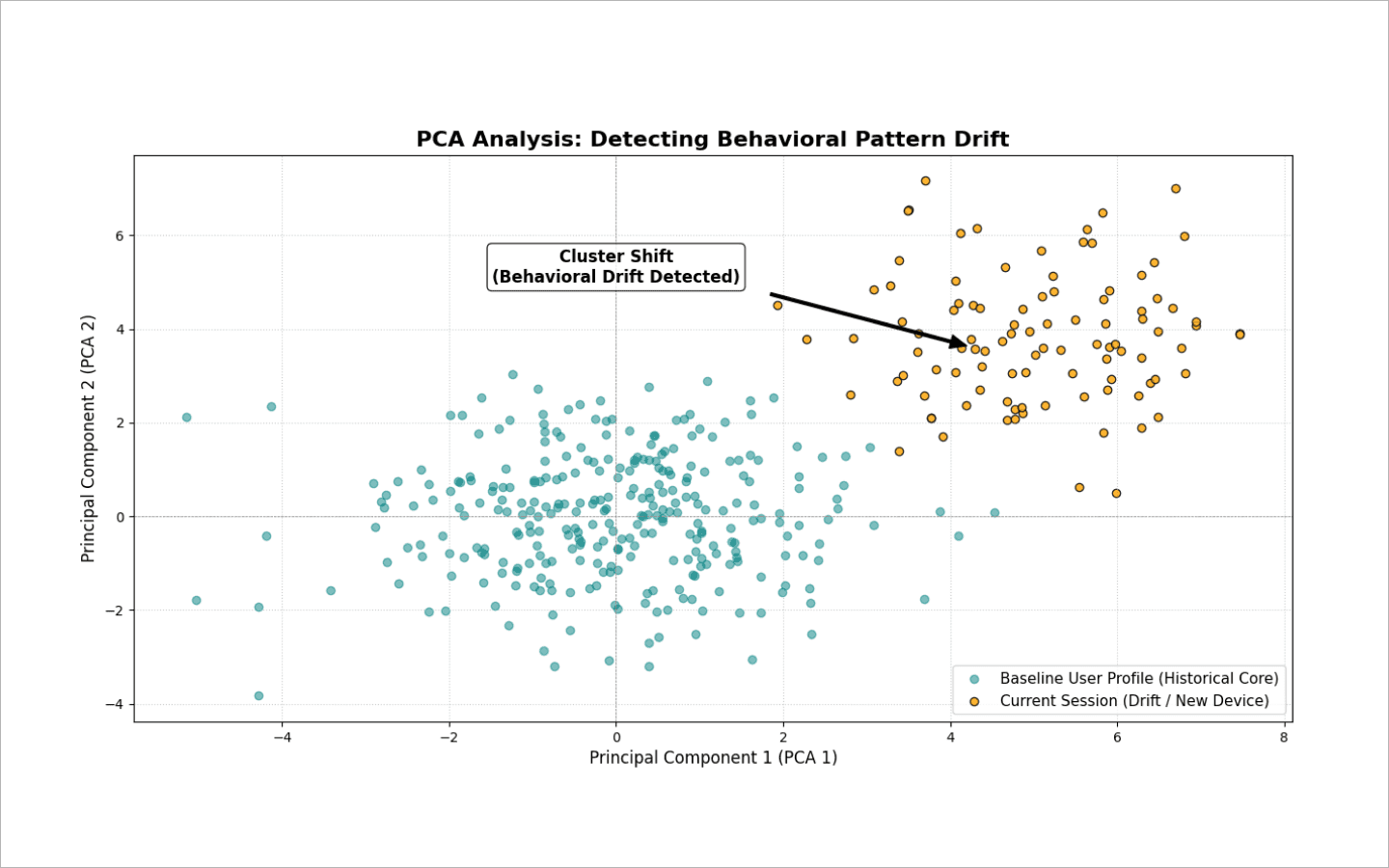
Principal Component Analysis (PCA). This method projects dozens of features into a 2D or 3D space and tracks cluster drift. If fresh sessions suddenly deviate from the user’s historical behavioral core, the system detects the drift.
Statistical tests (such as the Kolmogorov–Smirnov test). The algorithm continuously compares the distribution of new data against the reference distribution. If divergence between the two samples is detected, the system temporarily lowers trust in the profile. At this stage, the user is not banned but instead prompted to complete a CAPTCHA. If the verification is passed successfully, the model interprets the deviation as legitimate—for example, a switch to a new device—and updates the reference profile accordingly.
Human behavior emulation
Now that we understand how anti-fraud algorithms work, let’s figure out how to train a bot to behave like a human.
Simply smoothing cursor movement with Bézier curves or adding time.sleep() calls is no longer enough: ML models can detect automation within just a few clicks. To make an emulator truly resemble a human, it must incorporate the laws of physiology and biomechanics.
Jitter injection
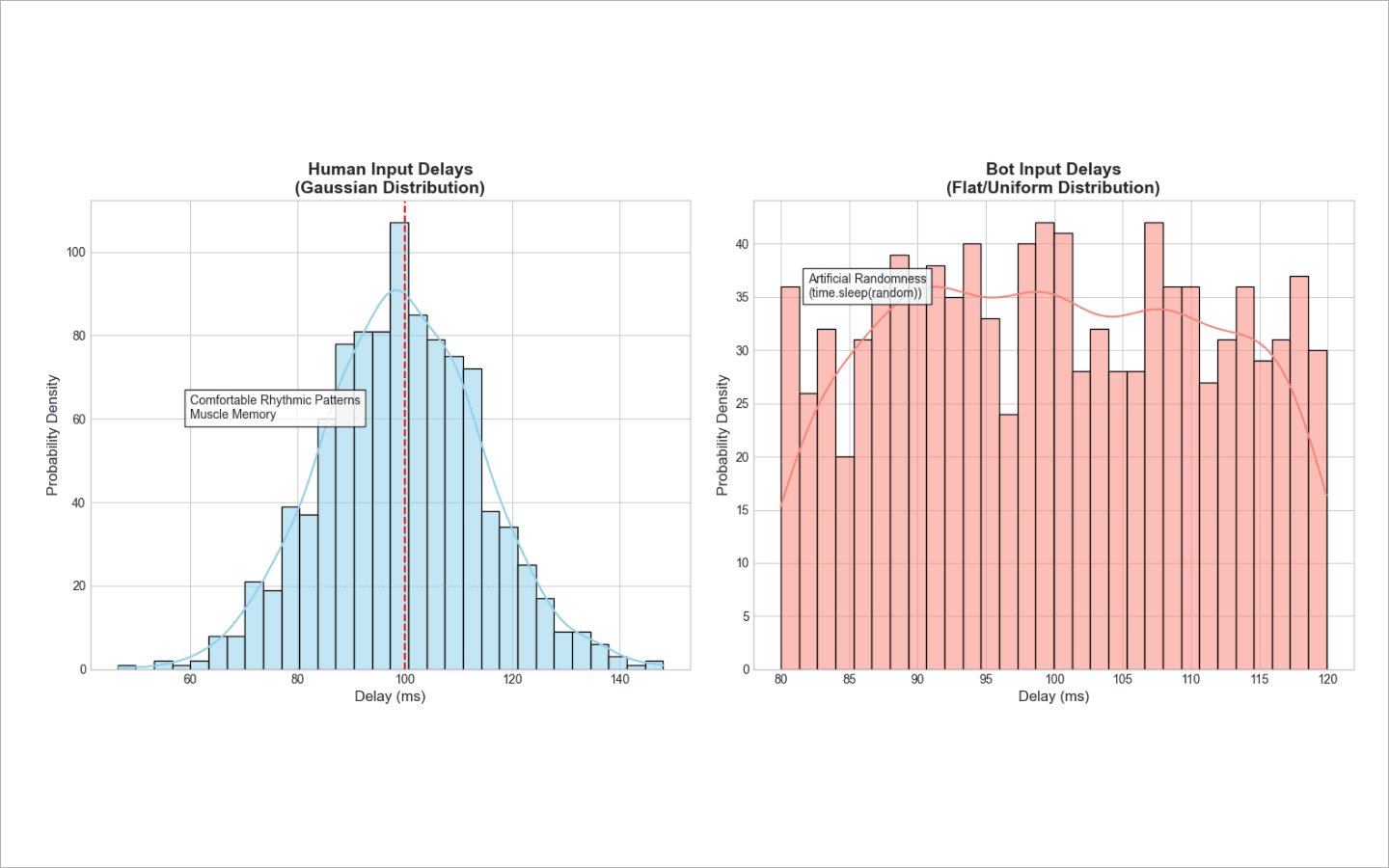
If you instruct a script to make random pauses lasting 80 to 120 milliseconds, it will generate 80 ms, 120 ms, and 95 ms delays with roughly the same frequency.
Humans do not type like that. We each have a natural, comfortable rhythm that we fall into most of the time. Occasionally, our fingers speed up or slow down slightly. That is why delays should be generated according to a Gaussian distribution (a bell curve). The overwhelming majority of a bot’s pauses should cluster around a single baseline speed, while only a few deviations should significantly differ in either direction.
Tremor emulation
Imagine trying to quickly click a tiny checkbox. You move the mouse abruptly, overshoot the target by a couple of pixels, notice the mistake, and pull the cursor back.
To imitate this effect and the natural shakiness of the human hand, developers blend mathematical functions (sine and cosine waves) into the ideal cursor trajectory. This creates realistic micro-noise capable of deceiving anti-fraud systems.
Macro-pauses
One of the most advanced and rarely implemented techniques is the introduction of macro-pauses that imitate physiological cycles. Humans do not work continuously at a computer. We blink, temporarily losing visual contact with the screen, breathe in and out, glance down at the keyboard, or get distracted by our phones.
An emulator must therefore include a “loss of focus” logic—periodic artificial delays of 1–3 seconds before important actions, breaking the machine-like monotony.
Behavior copying
Why write complicated mathematical models from scratch to generate the perfect scroll motion with natural deceleration and micro-jerks when you can simply use a real one? This approach is called blending, and it takes emulation to an entirely new level.
Advanced bot developers build their own databases or purchase ready-made ones. These datasets contain real sessions from live users: how people scroll through feeds, move their cursor while reading text, or unconsciously shift the mouse while thinking. These recordings are stored as arrays containing movement vectors and micro-timing data.
When a script built on this technology needs to scroll a page or move a cursor toward a complex form, it does not use window.scrollBy() or Bézier curves. Instead, it retrieves a suitable fragment of a real human interaction log from the database. The trajectory is then morphed: the script mathematically deforms this “snapshot” so it fits the browser’s current coordinates. The vectors are shifted just enough for the cursor to end up over the required button, after which control is seamlessly handed back to the bot for the final click.
Anti-fraud ML models perceive these movements as perfect high-frequency noise, fully natural tremor, and realistic micro-pauses. As a result, they allow the script to work because the underlying data genuinely originated from a live human.
What’s the catch? For this method to work at scale, the bot developer needs a truly massive library of behavioral “snapshots.” If the same scroll fragment is reused across multiple bots, server-side anti-fraud systems will quickly detect the mathematical duplicate (triggering basic replay-attack protection) and ban the entire farm.
The vulnerability of loops
However much you randomize timings and shake the cursor, every bot suffers from one congenital weakness: it lives inside a programmatic loop (while or for).
Protection systems take your script’s timings and run them through spectral analysis (Fourier transform). This filters out the artificial random noise and reveals the hidden carrier frequency of the loop. Humans are naturally arrhythmic; bots are not.
Can you defeat Fourier analysis and convince the server that your script is a living human with no detectable base frequency? Yes, but doing so requires rewriting the entire architecture of your scraper. A simple Math.random() is nowhere near enough for this.
Abandoning loops in favor of State Machines. Do not use linear
whileorforloops combined with nestedsleep()calls. Your bot should function as a finite-state machine driven by events. It should have multiple states, e.g., reading, hesitation or idling, movement, clicking. Transitions between these states should not be rigidly hardcoded but determined probabilistically. Only then will the overall rhythm of the session become unpredictable, like a human who may suddenly change their mind before clicking a button.The mathematics of “heavy tails.” Forget uniform randomness or even Gaussian distributions. Most of your pauses should be short and tightly clustered, but the bot should occasionally stop for an abnormally long time with a certain probability. These rare but extreme outliers are precisely what disrupt Fourier frequency analysis, smearing the spectrum and hiding the machine rhythm.
Using OS entropy. The built-in pseudorandom number generators in JavaScript or Python have predictable patterns of their own. Instead, you can draw true entropy directly from the operating system, which gathers chaotic hardware noise, from CPU temperature fluctuations to network interrupts.
Conclusion: the economics of scraping and the endless game
Behavioral biometrics has not become a silver bullet against bots. However, it has fundamentally changed both the rules of the game and the economics of automation.
Previously, building a successful scraper required little more than purchasing a batch of proxies and understanding browser headers. Today, automation developers need expertise that extends into biomechanics and Fourier transforms. Of course, this applies to heavyweight projects, not simply scraping photos from Google Maps.
The arms race between anti-fraud systems and bot developers continues, but now on a new battlefield: the imitation of the human nervous system. Anti-fraud solutions will continue introducing increasingly sophisticated verification methods, while scrapers will learn to “breathe” and procrastinate even more convincingly.
Stay anonymous, take advantage of multi-accounting, and achieve your goals with the highest-quality anti-detect browser on the market.
Would you like to try Octo Browser at discount?
Use the promo code OCTOSCRAPER to get 30% off any subscription. This offer is valid only for new users.
Why CAPTCHAs are giving way to behavioral analysis
Previously, CAPTCHA was the primary defense mechanism against bots. CAPTCHAs still exist today, though they have changed significantly. They have become more sophisticated, and some modern invisible versions (such as reCAPTCHA v3) have incorporated the very behavioral biometrics we are discussing.
Why is this necessary? Traditional CAPTCHAs (traffic lights and distorted characters) worsen the user experience and are increasingly being solved effortlessly by trained neural networks. The new approach, which works without visible elements, removes much of the burden from users and avoids annoying them.
Behavioral biometrics, as the core of this invisible verification process, offers continuous authentication. It works by analyzing how exactly a user interacts with a device while scrolling a page or filling out a form, without requiring any additional input.
However, an important clarification should be made: behavioral biometrics is not used as a standalone verification method. It always works alongside other checks. In addition to biometrics, anti-fraud systems still analyze digital fingerprints, IP reputation, and cookies.
Types of behavioral biometrics
Let’s dive deeper into the theory. Behavioral patterns are essentially a digital fingerprint of your nervous system transferred onto a device. Advanced anti-fraud systems do not analyze parameters separately. Instead, they build a comprehensive multidimensional profile that can be divided into the following categories:
Device interaction (kinesthetics)
This is the largest layer of data for the traditional web and mobile applications. Here, systems analyze the physics of user movements.
Keyboard: it’s not about which letters or numbers you type. Anti-fraud systems evaluate two main parameters: how long a key is held down (
dwell time) and how long it takes to move between keys (flight time). Humans have muscle memory — familiar key combinations (for example, common word endings) are typed in micro-bursts. Bots, meanwhile, either inject entire strings at once or imitate typing using simplistictime.sleep(random)logic. This creates a flat, unnatural delay distribution. Randomness itself becomes suspicious.Mouse: cursor analytics. The system records coordinates and calculates speed, acceleration, trajectory curvature, and jerks. Humans do not move a mouse in perfectly straight lines. We aim for a button, miss by a few pixels, make tiny corrective movements, and briefly pause before clicking.
Touchscreen: specific for mobile web and native applications. A human swipe is an arc with uneven speed, specific pressure (if the API allows pressure detection), and a changing finger contact area. Bots that emulate touch events through Appium or JavaScript scripts often simply “teleport” focus coordinates. Writing the proper math for a realistic swipe is more difficult, so bot operators often cut corners.
Physical patterns (biomechanics)
When a user accesses a platform from a mobile device, hardware sensors come into play. And since we now live in the era of mobile users, this matters a lot.
Walking patterns and micromovements. Are you scrolling your feed while walking, sitting in a chair, or lying on a couch? A smartphone’s accelerometer and gyroscope constantly capture tiny device vibrations. A real user’s phone always slightly trembles in their hands, even when they try to hold it perfectly still. Bot farms and emulators running on servers usually have zero sensor background noise by default, giving anti-fraud systems something to think about and increasing the risk score.
Cognitive patterns (interaction psychology)
This is where systems analyze how a user’s brain works while interacting with a UI.
Navigation and decision-making speed. How quickly does a user find the required button? Do they read the text before checking a checkbox? People often move the cursor across text while reading, similar to tracing lines in a book with a finger, or pause on complicated forms. Some users even highlight the text. A scraper script, on the other hand, has no doubts— t knows the DOM structure perfectly and triggers the required event exactly after a predefined timeout, completely ignoring the logic of visual search.
Together, these three levels create such a complex profile that fully replicating it by simply adding random delays to Selenium or Puppeteer code becomes mathematically impossible.
Data collection and preprocessing
The primary sources for collecting biometric data are mousemove, keydown, keyup, touchstart, and touchend events, as well as the DeviceOrientation API for capturing accelerometer and gyroscope readings.
The most difficult part at this stage is handling the enormous volume of fragmented and asynchronous data. A single mousemove event alone can fire hundreds of times per second. If every cursor movement triggered backend processing or heavy computations directly on the client side, the anti-fraud system would instantly freeze the UI and cause noticeable lag on the client’s website. No business would accept that.
That is why client-side collection scripts are designed to be as lightweight and primitive as possible. Their only task is to quickly capture coordinates, attach precise timestamps, store everything in a local buffer, and send the data to the server in a batch.
These batches of JSON objects are then transmitted to the backend. In high-load systems, they are not written directly into databases or immediately passed to ML models. First, they are routed through message brokers such as Kafka or RabbitMQ. This is necessary to smooth out traffic spikes, for example, during large-scale bot attacks or natural surges of real users during sales or promotions. At this point, the client-side responsibility ends.
Feature engineering and ML models
So, the raw batches have reached the server. What happens next?
If you simply feed this array of pixels into an ML model, it will not learn to distinguish humans from bots. It will merely memorize where the buttons are located on your website and break as soon as the layout changes slightly. Machine learning models do not need screen geography, they need behavioral abstractions.
That is why there is a dedicated microservice layer called feature engineering located between the message queue and the neural networks. These are usually pipelines built on Pandas and NumPy that aggregate logs and transform them into data suitable for ML models. They calculate:
Euclidean distances between points;
time deltas;
instantaneous velocities;
trajectory turning angles.
Based on these calculations, the anti-fraud system builds a complex behavioral feature profile:
Keyboard: delay vectors (
dwell timeandflight time), along with their median, variance, and standard deviation. In other words, how consistent the typing rhythm is.Mouse: statistics on speed and acceleration, the number of micro-pauses, and the spectral entropy of the trajectory. This metric shows whether movement appears chaotic (like a human) or mathematically perfect (like a script).
Touchscreen: gradients of pressure and contact-area changes during a swipe (in cases where the browser or OS API shares such data).
Cognitive features:
idle timeand delays before focusing on target elements. For example, a pause before clicking the “Pay” button while a user mentally double-checks the amount.
Hundreds of such parameters are extracted from a single session, stripped of layout-specific context, and then passed to ML models.
Classical ML algorithms (Random Forest, SVM, Gradient Boosting)
These perform exceptionally well with aggregated statistical features. They operate quickly, consume minimal server resources, and are typically used as the first and fastest line of defense.
Essentially, they run the entire vector of session statistics (action speed, timing variance, entropy, and so on) through a system of carefully calibrated mathematical thresholds, instantly filtering out obvious anomalies such as zero variance in cursor acceleration or unnaturally consistent click intervals.
Neural networks (LSTM, GRU, and 1D-CNN)
While classical algorithms focus on the overall statistical picture, recurrent neural networks analyze the actual sequence of cursor movements over time.
Recurrent networks are designed for processing sequential data (text, speech, time series), where the context of previous elements matters. Unlike traditional networks, recurrent architectures have “memory” through feedback loops, allowing them to account for information from previous steps. As a result, they can detect unnatural patterns and rhythms that are hidden by ordinary statistical averaging.
Autoencoders and anomaly detection
The biggest challenge for anti-fraud systems is that bot developers constantly invent new spoofing techniques. Training a model on every existing bot is impossible, but there are millions of sessions generated by real humans. That is why unsupervised learning, particularly autoencoders, is widely used.
An autoencoder is a neural network trained exclusively on human behavior. It works like a specialized filter: it takes session parameters as input, mathematically compresses them into a compact representation, and then attempts to reconstruct the original data.
Because such a network has only seen genuine human sessions, it has learned the physics of human movement with near-perfect accuracy and can reconstruct such data almost flawlessly. But if the behavior of a previously unseen bot—no matter how sophisticated—is fed into the model, the network will attempt to apply human compression rules to it. As a result, the reconstruction stage will produce inaccurate output.
When there is a large discrepancy between the original data and what the network managed to reconstruct, this becomes a reconstruction error. The greater the error, the higher the risk score, signaling anomalous behavior.
Single-method checks vs. hybrid systems
Relying on only one type of verification is ineffective, which is why no one uses a single model. In most cases, the architecture is built as a cascade: lightweight ML algorithms can instantly filter out up to 90% of simple scripts and bots, while heavier neural networks are activated only for borderline cases in which earlier checks have yielded uncertain results. This approach significantly reduces computational costs.
Feature drift and adaptation
Real human behavior can change over time, just like their device’s digital fingerprint. A user may buy a new mouse with different DPI settings, switch from a desktop computer to a laptop with a touchpad, injure their hand, drink a double espresso, or simply become exhausted by the end of the workday. All of this instantly changes their typing rhythm, fine motor control, and reaction speed.
If an anti-fraud model is static and relies on a reference profile collected years ago, it will inevitably start blocking legitimate users. The percentage of false positives will rise, conversion rates will fall, and businesses will lose both revenue and customer loyalty.
As a result, anti-fraud systems must continuously evolve alongside users and adapt to changing conditions.
Real-time neural network training
Unlike traditional batch training, where a model is retrained once a month on a massive accumulated dataset, online learning allows the algorithm to adjust its weights continuously in real time. As soon as a valid session ends—confirmed, for example, by a purchase or successful 2FA verification—its features slightly shift the model’s decision thresholds. This perfectly accounts for gradual changes in user habits.
Sliding memory window
Algorithms also rely on the sliding memory window principle: fresh session data is constantly added to the reference behavioral profile and assigned the highest mathematical weight. Older records gradually lose influence until their contribution approaches zero. The system always compares current behavior against how the user has behaved over recent weeks, not against the moment the account was created years ago.
Statistical monitoring
But how does the system distinguish between a legitimate change, such as buying a new mouse, and a sudden session spoofing by a sophisticated bot? For this purpose, strict statistical monitoring is applied, including:
Principal Component Analysis (PCA). This method projects dozens of features into a 2D or 3D space and tracks cluster drift. If fresh sessions suddenly deviate from the user’s historical behavioral core, the system detects the drift.
Statistical tests (such as the Kolmogorov–Smirnov test). The algorithm continuously compares the distribution of new data against the reference distribution. If divergence between the two samples is detected, the system temporarily lowers trust in the profile. At this stage, the user is not banned but instead prompted to complete a CAPTCHA. If the verification is passed successfully, the model interprets the deviation as legitimate—for example, a switch to a new device—and updates the reference profile accordingly.
Human behavior emulation
Now that we understand how anti-fraud algorithms work, let’s figure out how to train a bot to behave like a human.
Simply smoothing cursor movement with Bézier curves or adding time.sleep() calls is no longer enough: ML models can detect automation within just a few clicks. To make an emulator truly resemble a human, it must incorporate the laws of physiology and biomechanics.
Jitter injection
If you instruct a script to make random pauses lasting 80 to 120 milliseconds, it will generate 80 ms, 120 ms, and 95 ms delays with roughly the same frequency.
Humans do not type like that. We each have a natural, comfortable rhythm that we fall into most of the time. Occasionally, our fingers speed up or slow down slightly. That is why delays should be generated according to a Gaussian distribution (a bell curve). The overwhelming majority of a bot’s pauses should cluster around a single baseline speed, while only a few deviations should significantly differ in either direction.
Tremor emulation
Imagine trying to quickly click a tiny checkbox. You move the mouse abruptly, overshoot the target by a couple of pixels, notice the mistake, and pull the cursor back.
To imitate this effect and the natural shakiness of the human hand, developers blend mathematical functions (sine and cosine waves) into the ideal cursor trajectory. This creates realistic micro-noise capable of deceiving anti-fraud systems.
Macro-pauses
One of the most advanced and rarely implemented techniques is the introduction of macro-pauses that imitate physiological cycles. Humans do not work continuously at a computer. We blink, temporarily losing visual contact with the screen, breathe in and out, glance down at the keyboard, or get distracted by our phones.
An emulator must therefore include a “loss of focus” logic—periodic artificial delays of 1–3 seconds before important actions, breaking the machine-like monotony.
Behavior copying
Why write complicated mathematical models from scratch to generate the perfect scroll motion with natural deceleration and micro-jerks when you can simply use a real one? This approach is called blending, and it takes emulation to an entirely new level.
Advanced bot developers build their own databases or purchase ready-made ones. These datasets contain real sessions from live users: how people scroll through feeds, move their cursor while reading text, or unconsciously shift the mouse while thinking. These recordings are stored as arrays containing movement vectors and micro-timing data.
When a script built on this technology needs to scroll a page or move a cursor toward a complex form, it does not use window.scrollBy() or Bézier curves. Instead, it retrieves a suitable fragment of a real human interaction log from the database. The trajectory is then morphed: the script mathematically deforms this “snapshot” so it fits the browser’s current coordinates. The vectors are shifted just enough for the cursor to end up over the required button, after which control is seamlessly handed back to the bot for the final click.
Anti-fraud ML models perceive these movements as perfect high-frequency noise, fully natural tremor, and realistic micro-pauses. As a result, they allow the script to work because the underlying data genuinely originated from a live human.
What’s the catch? For this method to work at scale, the bot developer needs a truly massive library of behavioral “snapshots.” If the same scroll fragment is reused across multiple bots, server-side anti-fraud systems will quickly detect the mathematical duplicate (triggering basic replay-attack protection) and ban the entire farm.
The vulnerability of loops
However much you randomize timings and shake the cursor, every bot suffers from one congenital weakness: it lives inside a programmatic loop (while or for).
Protection systems take your script’s timings and run them through spectral analysis (Fourier transform). This filters out the artificial random noise and reveals the hidden carrier frequency of the loop. Humans are naturally arrhythmic; bots are not.
Can you defeat Fourier analysis and convince the server that your script is a living human with no detectable base frequency? Yes, but doing so requires rewriting the entire architecture of your scraper. A simple Math.random() is nowhere near enough for this.
Abandoning loops in favor of State Machines. Do not use linear
whileorforloops combined with nestedsleep()calls. Your bot should function as a finite-state machine driven by events. It should have multiple states, e.g., reading, hesitation or idling, movement, clicking. Transitions between these states should not be rigidly hardcoded but determined probabilistically. Only then will the overall rhythm of the session become unpredictable, like a human who may suddenly change their mind before clicking a button.The mathematics of “heavy tails.” Forget uniform randomness or even Gaussian distributions. Most of your pauses should be short and tightly clustered, but the bot should occasionally stop for an abnormally long time with a certain probability. These rare but extreme outliers are precisely what disrupt Fourier frequency analysis, smearing the spectrum and hiding the machine rhythm.
Using OS entropy. The built-in pseudorandom number generators in JavaScript or Python have predictable patterns of their own. Instead, you can draw true entropy directly from the operating system, which gathers chaotic hardware noise, from CPU temperature fluctuations to network interrupts.
Conclusion: the economics of scraping and the endless game
Behavioral biometrics has not become a silver bullet against bots. However, it has fundamentally changed both the rules of the game and the economics of automation.
Previously, building a successful scraper required little more than purchasing a batch of proxies and understanding browser headers. Today, automation developers need expertise that extends into biomechanics and Fourier transforms. Of course, this applies to heavyweight projects, not simply scraping photos from Google Maps.
The arms race between anti-fraud systems and bot developers continues, but now on a new battlefield: the imitation of the human nervous system. Anti-fraud solutions will continue introducing increasingly sophisticated verification methods, while scrapers will learn to “breathe” and procrastinate even more convincingly.
Stay up to date with the latest Octo Browser news
By clicking the button you agree to our Privacy Policy.
Stay up to date with the latest Octo Browser news
By clicking the button you agree to our Privacy Policy.
Stay up to date with the latest Octo Browser news
By clicking the button you agree to our Privacy Policy.

Join Octo Browser now
Or contact Customer Service at any time with any questions you might have.
Join Octo Browser now
Or contact Customer Service at any time with any questions you might have.
Join Octo Browser now
Or contact Customer Service at any time with any questions you might have.