How to bypass ChatGPT limit
3/25/26


Nikolai Izoitko
Content Manager, Octo Browser
ChatGPT has become a go-to solution for work, learning, and creativity. However, many active users regularly run into restrictions: the service reports that the message limit has been reached and suggests waiting or switching to another model.
These limitations are especially disruptive when you are working. That is why users look for ways to increase the duration of their access to ChatGPT, work around these restrictions, or at least reduce their impact.
In this article, we discuss what limits exist in ChatGPT in 2026, why they exist, and what methods can be used to work around them.
Contents
Stay anonymous, take advantage of multi-accounting, and achieve your goals with the highest-quality anti-detect browser on the market.
ChatGPT limits
ChatGPT limits depend on the subscription, the selected model, and the current system load. It is important to understand that most limits are not fixed and may change.
1. Message limits (rate limits)
Free users can send a limited number of messages to more powerful models within a few hours. After that, access is either temporarily restricted or users are prompted to switch to a lighter model.
Paid subscriptions offer higher limits, but they are still capped: dozens or hundreds of messages over several hours.
2. Model limits
More advanced models (especially those with enhanced reasoning) have stricter limits than lighter versions. Lightweight models are usually available with minimal restrictions.
3. Tool limits
Image generation, file handling, and other features have separate quotas that are not directly tied to text messages.
4. Context limits (tokens)
Each model has a maximum context length, usually up to hundreds of thousands of tokens. When this limit is exceeded, older messages are truncated or an error occurs.
Why ChatGPT limits exist
ChatGPT limits are not arbitrary, as they are part of the service architecture. They are necessary for stable operation of ChatGPT and are driven by several factors.
1. Computational constraints
Modern large language models require significant computing resources. Even a single request may involve complex infrastructure (GPU/TPU, distributed systems). Without limits, this would overload servers and increase latency.
2. Load balancing
Limits help distribute resources evenly among users. Without them, the most active users or automated systems could consume a disproportionate share of computing capacity.
3. Economic model
ChatGPT operates on a freemium model: basic access is limited, while paid subscriptions offer higher limits and priority access.
4. Security
Rate limits help prevent automated attacks, mass generation of harmful content, and API abuse.
5. Additional factors
In some cases, indirect factors such as energy consumption and infrastructure efficiency are also considered.
Ways to work around ChatGPT limits
It is not possible to completely bypass ChatGPT limits. Even paid subscriptions include restrictions on request frequency and access to more powerful models. However, in practice, there are several effective approaches that either temporarily bypass limits or significantly reduce their impact, allowing you to continue working without long pauses.
Telegram bots and apps
The most obvious option users turn to after hitting limits is third-party services. These include Telegram bots as well as standalone AI platforms like Poe, Perplexity, Grok, and You.com.
However, it is important to be realistic. Full-featured platforms like Poe or Perplexity are stable and provide access to multiple models, sometimes with more flexible limits or their own quota systems. This is a legitimate and sustainable way to continue working, just not within ChatGPT itself.
Telegram bots, however, are much less predictable. Most operate via API or proxies, often using shared request pools, and may restrict users at any time. In addition, claims about access to top-tier models or “thinking” modes are often unreliable, as the user typically cannot verify which model is actually being used.
Another important aspect to consider is data security. With bots, you are almost always sending requests through third-party infrastructure, which may log or analyze your input. For sensitive tasks, this is a serious risk.
Thus, these services can help when you urgently need to continue a conversation after hitting a limit. But as a primary workflow, they are unstable and hard to control.
Free trials
Another approach is to use trial periods in services that integrate large language models. In this case, you are not bypassing limits directly, but temporarily gaining access to another system with its own limits.
For example, Cursor periodically offers trial access to its AI features and is widely used by developers. Replit provides built-in AI assistants with limits, while Codeium and Tabnine are alternative tools for working with code.
Technically, this is not removing ChatGPT limits, but switching to another service with a free trial or better conditions for new users. Eventually, restrictions return, either as limits or as a requirement to pay.
Still, as a temporary strategy, this works well, especially if tasks are distributed across different solutions: text generation, coding, search, and analysis.
Octo Browser
Keep in mind that ChatGPT limits are tied to the account, not the device. One account means one limit set. Multiple accounts mean combined limits. Octo Browser, an anti-detect browser for multi-accounting, allows you to manage such accounts by creating separate browser profiles with real digital fingerprints for each one.
This solves the core issue: the system does not link accounts together if they appear as independent users. As a result, you can work in parallel sessions and distribute the load.
How to use Octo Browser to work around ChatGPT limits:
Create a separate Octo Browser profile for each OpenAI account.
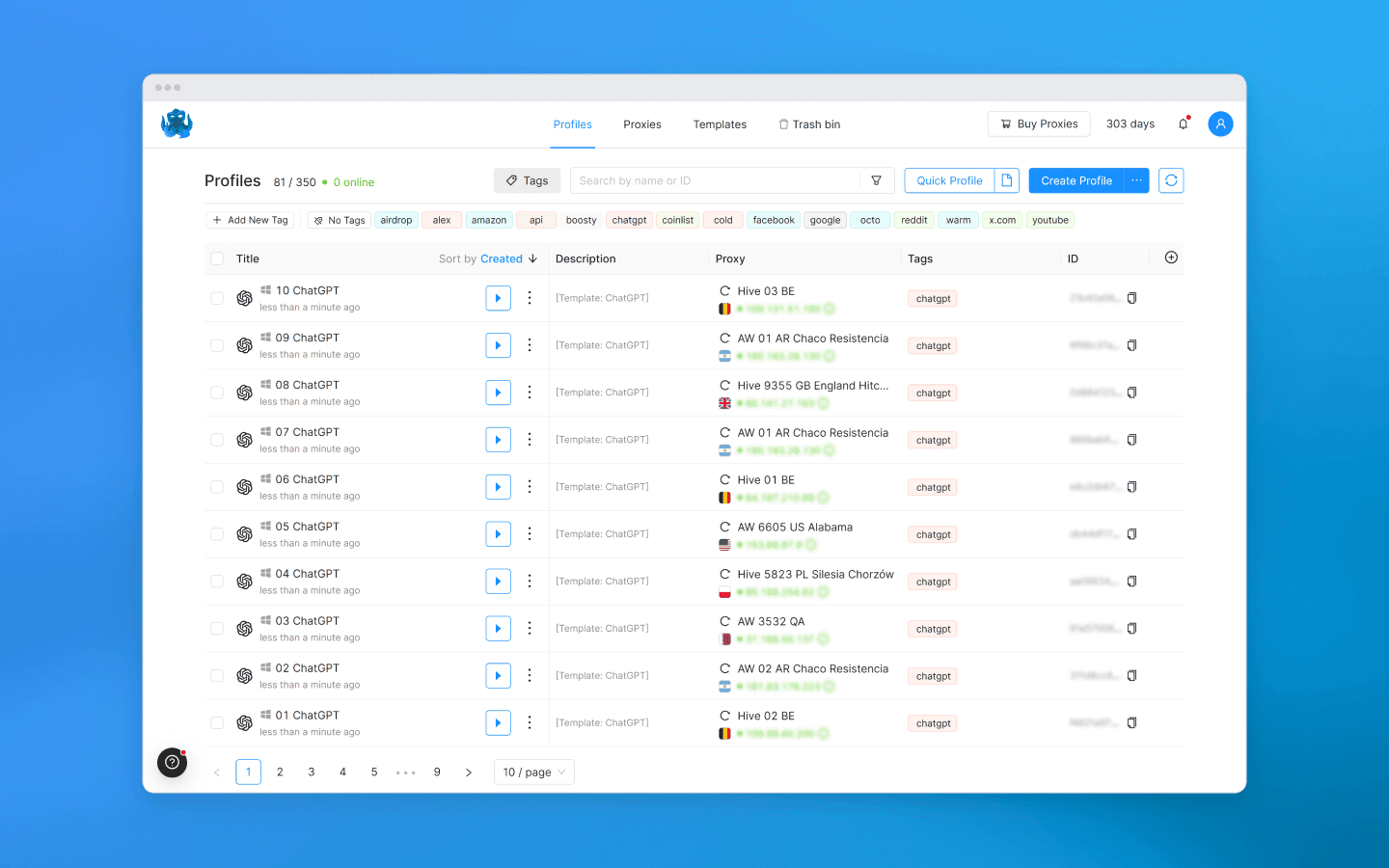
Each profile gets its own digital fingerprint: different Canvas, WebGL, fonts, User-Agent, geolocation, time zone, WebRTC, and so on. If you are unsure what to choose, you can leave the default settings.
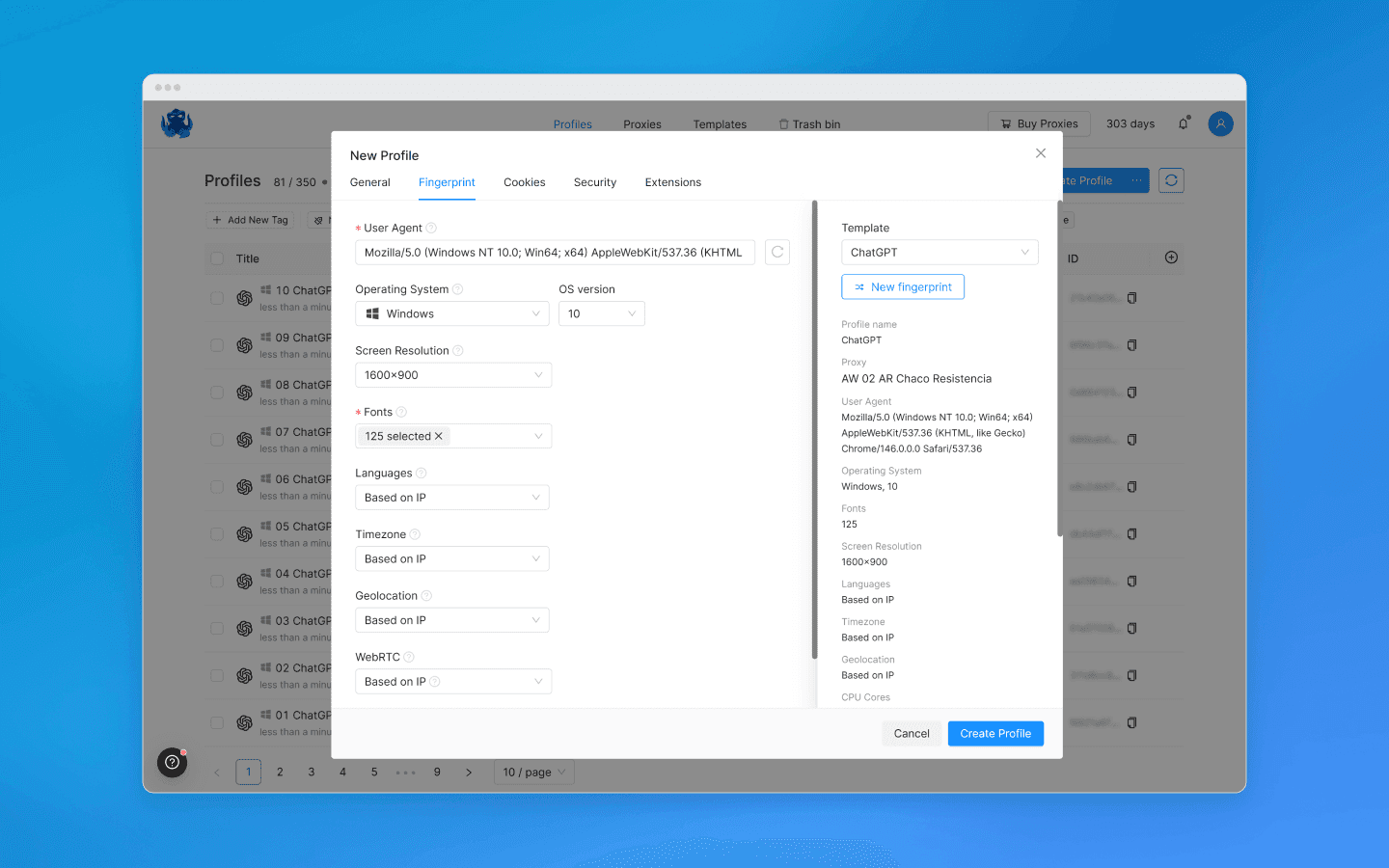
Assign different proxies to each profile.
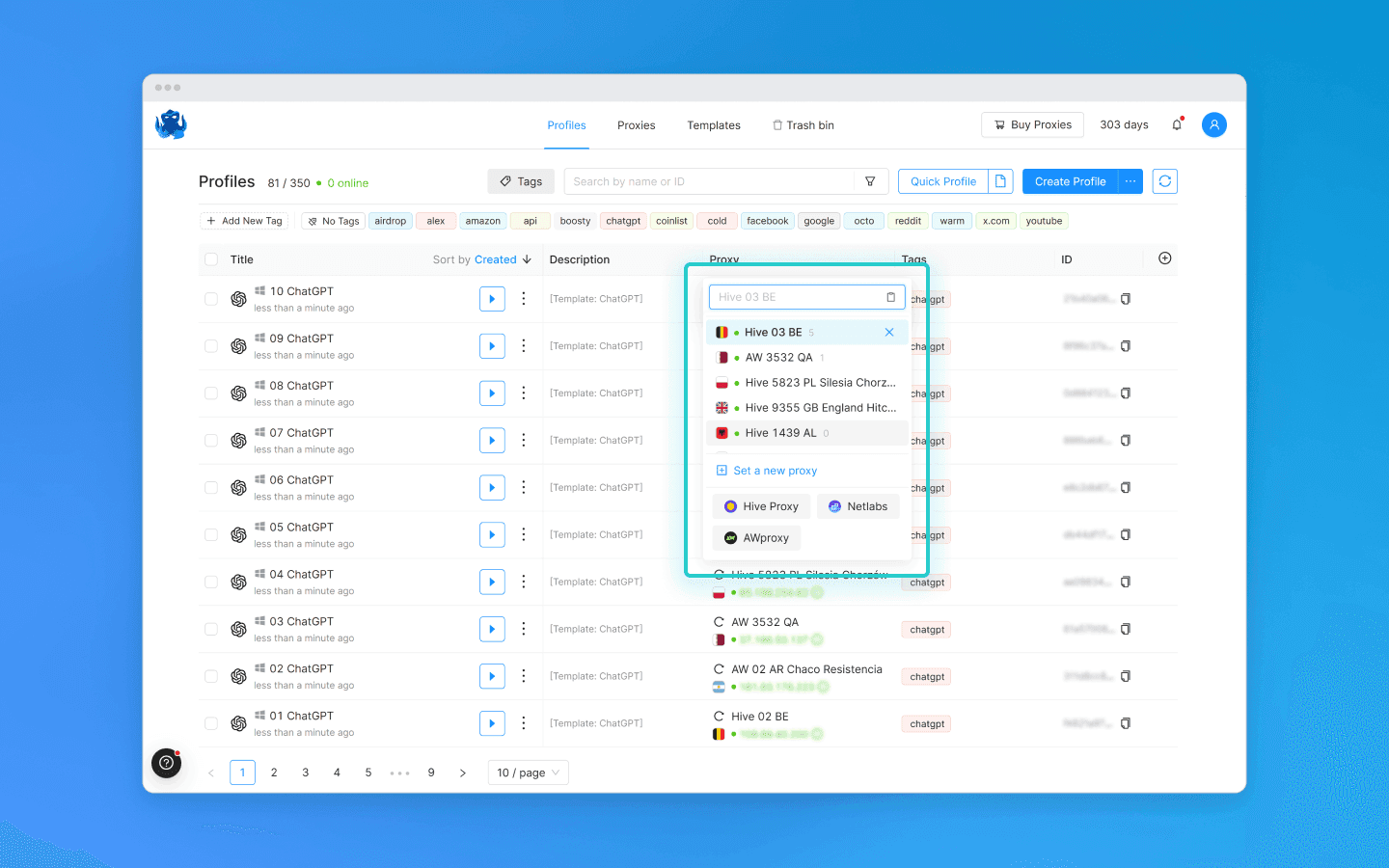
Register, purchase, or rent multiple ChatGPT accounts.
Switch between profiles as needed. ChatGPT limits are calculated separately for each account.
Keep in mind: aggressive behavior (mass registrations, identical actions, suspicious activity) still carries a risk of bans.
Tips for managing sessions and tokens
Even within a single account, you can significantly improve efficiency by working smarter with chats and requests. These methods do not bypass ChatGPT limits directly, but help reduce unnecessary messages.
Reuse context whenever possible
Continuing the same conversation means you do not need to re-enter instructions, style, or data. ChatGPT considers only the current context (up to hundreds of thousands of tokens depending on the model), so longer, structured chats help reduce redundant messages.
Do not start a new chat on the same topic unless strictly necessary.
Give chats clear names for easier navigation.
Split long conversations into logical blocks only when needed.
Clearing the context to manage performance
Very long chats can reduce answer quality and make work harder. To avoid this:
Use built-in features like clearing or branching a chat.
Start a new chat for completely different topics, carrying over only the key instructions.
Monitor context size to avoid overloading the model.
Important: clearing the context does not reset message limits, it only helps manage response quality.
Breaking a large request into several smaller ones
Very large prompts often lead to errors and unnecessary clarifications. It is better to split tasks into steps:
planning;
writing individual parts;
review and refinement.
This approach helps you get better results faster while staying within your ChatGPT message limits.
Prompt optimization methods
A good prompt is the main way to stay within your ChatGPT limit. A clear and complete request produces an accurate answer on the first try, without unnecessary follow-ups.
For example, if you need to analyze and debug Python code, a kind of task where limits are often quickly exhausted, use the following approach:
1. Assign a role to the model
Clearly define the model’s role. This helps produce expert-level answers and reduces follow-up questions.
Example: “You are a senior Python developer with 12 years of experience. Write clean, idiomatic code and explain changes line by line.”
This approach turns the prompt into a compact set of instructions for the model, reducing the need for repeated corrections.
2. Provide full context upfront
Do not send half the information in one message and then add clarifications later. If you are working with code, provide all relevant data upfront:
the code, identified errors, programming language and its version, and the task the code is supposed to perform;
sample data or the desired output format.
Example: instead of “Why doesn’t this code work?” — provide the code, the error, the Python version, and the expected result right away.
3. Break the task into steps
Use an iterative approach so the model handles each stage separately, while you can monitor the results and fix issues early.
Example:
Analyze the Python code and identify potential errors or vulnerabilities.
Fix the issues and suggest function optimizations.
Add test cases to validate the corrected code.
This way, you stay in control of the process, reduce the risk of incorrect solutions, and save messages because each follow-up is tied to a specific step.
4. Specify the exact output format
If you need a structured response, define the format in advance, as this reduces the number of revisions and clarifications.
Example: “Divide the response into four parts: problem analysis, proposed changes, corrected code, and test cases.”
5. Use examples
Show the model what kind of result you expect. This is especially useful when working with code, tables, or formatting.
Example:
Before:
response.json()
response.json()
After:
response.raise_for_status() data = response.json()
response.raise_for_status() data = response.json()
Why: raise_for_status() throws an exception on HTTP errors, while response.json() returns data only if the request succeeds.
6. Cut unnecessary wording
The simpler and more precise the prompt, the fewer tokens and messages it uses.
Example:
Bad: “Please help me with the code, it doesn’t work, I don’t understand why, help me right now.”
Good: “Analyze and fix the code below. Error: JSONDecodeError on empty response. Add network and HTTP error handling.”
7. Use separators for blocks
If your prompt contains multiple parts, separators like ### help the model distinguish between instructions, improving accuracy and saving messages.
Using the API to manage limits
The OpenAI API is the most flexible way to work with ChatGPT without the limitations of the web interface. Through the API, you get direct access to models (gpt-5.3, gpt-5.4, thinking modes) and manage your own quotas and tokens.
1. Getting your API key and setup
To use the API:
Go to platform.openai.com and log in.
Open the API Keys section in the left menu.
Click Create new secret key.
In the pop-up window, enter a project name if needed, set permissions, and click Create new secret key.
Copy the key and store it securely, as it provides full access to your API account.
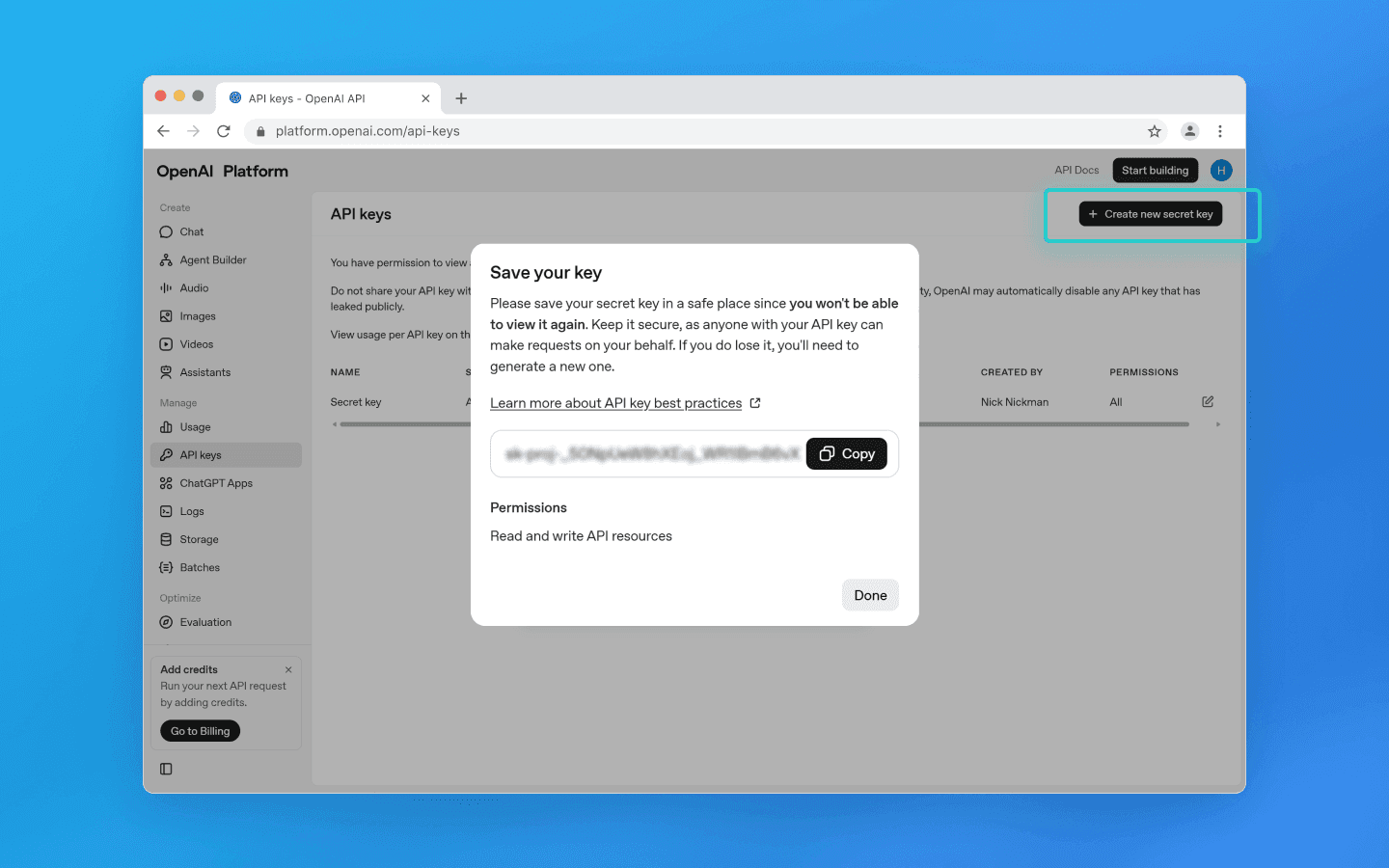
Important: API keys are not tied to ChatGPT web limits. These limits depend only on your API quota.
2. API quotas and limits
OpenAI uses a quota system tied to your account and billing:
Tier 0 (new account): small quotas, e.g., 500–1,000 requests per minute and 10k tokens per minute for lightweight models.
Tier 1+ (after spending more than $5): thousands of requests per minute (RPM) and hundreds of thousands of tokens per minute (TPM).
Tier 5 (Enterprise): near-unlimited quotas with custom limits by agreement.
Quotas increase automatically with consistent payment, provided there are no violations.
Difference from the web interface: API limits are not based on chat messages, but on RPM/TPM.
3. Efficient API usage
To save quota and improve stability, use these best practices:
Reasonable parameters:
temperature— 0.2–0.5 for precise code, 0.7–1.0 for creative tasks.max_tokens— limit response length to avoid unnecessary token usage.top_p— usually 0.9–1.0.
Cache responses: store repeated prompts locally (files, Redis) to avoid sending them again.
Batch requests: send multiple prompts in one request to save time and tokens.
Use lightweight models for drafts: use
gpt-4o-miniorgpt-5.3-instantfor drafts, then finalize with a top-tier model.Streaming mode:
stream=truelets you receive responses in chunks, saving tokens if sessions are interrupted.Compact system prompts: shorter role and core instructions reduce token usage in every request.
4. Python example
A simple way to call the ChatGPT API:
import requests api_key = "sk-..." url = "https://api.openai.com/v1/chat/completions" headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "gpt-5.3", "messages": [ {"role": "system", "content": "You are a senior Python developer. Write clean, idiomatic code."}, {"role": "user", "content": "Please review this code and fix any errors: ..."} ], "temperature": 0.3, "max_tokens": 800 } response = requests.post(url, headers=headers, json=data) print(response.json())
import requests api_key = "sk-..." url = "https://api.openai.com/v1/chat/completions" headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "gpt-5.3", "messages": [ {"role": "system", "content": "You are a senior Python developer. Write clean, idiomatic code."}, {"role": "user", "content": "Please review this code and fix any errors: ..."} ], "temperature": 0.3, "max_tokens": 800 } response = requests.post(url, headers=headers, json=data) print(response.json())
Strategies for handling rate limits
A rate limit in ChatGPT is a restriction on how many messages you can send within a certain period. It operates using the rolling window principle.
What the rolling window principle means:
Instead of resetting at a fixed time (for example, exactly at 3:00), the system tracks a time window based on when each message was sent.
Example: if your Plus plan allows 160 messages per 3 hours and you send the first message at 10:00, it will only stop counting toward the limit at 13:00. The same applies to every message—the window continuously shifts based on send time.
This means the limit restores gradually, not all at once.
To manage your rate limit efficiently, follow these guidelines:
1. Use lightweight models for simple tasks
Mini or instant versions have separate limits and are suitable for quick checks, drafts, or simple clarifications.
2. Watch ChatGPT notifications
The web interface shows warnings as you approach your limit.
3. Break large tasks into blocks
Instead of one long prompt, split the task into multiple messages with clear instructions. This helps save your quota, improves control, and increases answer quality.
Conclusion
ChatGPT limits in 2026 are not a temporary issue but a permanent part of working with the service. For users, they often become a bottleneck: work stops, deadlines slip, and you have to wait for limits to reset.
In this article, we covered current restrictions, the reasons behind them (technical, economic, and security-related), and practical ways to reduce their impact. The most effective approach is to combine methods: multiple ChatGPT accounts created with an anti-detect browser, proper prompt optimization and context management, working through the API with tier-based quotas, and reasonable alternation of pauses and lightweight models.
It is impossible to completely remove ChatGPT limits without an expensive Pro subscription, but applying these strategies consistently and correctly allows you to work longer and more efficiently.
FAQ
How long does the rate limit in ChatGPT last?
ChatGPT uses the rolling window principle. This means the limit does not reset at a fixed moment but is calculated individually for each message. After 3-5 hours, a specific message no longer counts toward the current window.
Do different ChatGPT models have different limits?
Yes. Limits depend on your subscription. On the Free plan, access to advanced models is limited (often around 10 messages over several hours), after which the system may switch to a lightweight (mini) model. Paid plans (such as Plus) offer significantly higher quotas within the same time window.
Can API limits be changed?
Yes, but not manually. OpenAI API limits are managed through quotas (rate limits and spending limits) and increase automatically with usage and payments. Stable billing and higher usage lead to higher available limits (RPM/TPM). In some cases, limits for large clients can be increased through support.
Do ChatGPT limits reset if I use different browsers?
No. Limits are tied to your account, not the browser. Using different browsers or tabs does not change the message counter.
Are ChatGPT limits tied to the account or the device?
ChatGPT limits are tied to the account. Device, browser, and IP address do not affect the number of available messages. One account equals one shared limit.
What is the difference between token limits and rate limits?
These are different systems. Token limits define how much text (input and output) can be processed in a single request or within a conversation context. Rate limits define how often you can send requests over a period of time. You can hit one limit without reaching the other.
Stay anonymous, take advantage of multi-accounting, and achieve your goals with the highest-quality anti-detect browser on the market.
ChatGPT limits
ChatGPT limits depend on the subscription, the selected model, and the current system load. It is important to understand that most limits are not fixed and may change.
1. Message limits (rate limits)
Free users can send a limited number of messages to more powerful models within a few hours. After that, access is either temporarily restricted or users are prompted to switch to a lighter model.
Paid subscriptions offer higher limits, but they are still capped: dozens or hundreds of messages over several hours.
2. Model limits
More advanced models (especially those with enhanced reasoning) have stricter limits than lighter versions. Lightweight models are usually available with minimal restrictions.
3. Tool limits
Image generation, file handling, and other features have separate quotas that are not directly tied to text messages.
4. Context limits (tokens)
Each model has a maximum context length, usually up to hundreds of thousands of tokens. When this limit is exceeded, older messages are truncated or an error occurs.
Why ChatGPT limits exist
ChatGPT limits are not arbitrary, as they are part of the service architecture. They are necessary for stable operation of ChatGPT and are driven by several factors.
1. Computational constraints
Modern large language models require significant computing resources. Even a single request may involve complex infrastructure (GPU/TPU, distributed systems). Without limits, this would overload servers and increase latency.
2. Load balancing
Limits help distribute resources evenly among users. Without them, the most active users or automated systems could consume a disproportionate share of computing capacity.
3. Economic model
ChatGPT operates on a freemium model: basic access is limited, while paid subscriptions offer higher limits and priority access.
4. Security
Rate limits help prevent automated attacks, mass generation of harmful content, and API abuse.
5. Additional factors
In some cases, indirect factors such as energy consumption and infrastructure efficiency are also considered.
Ways to work around ChatGPT limits
It is not possible to completely bypass ChatGPT limits. Even paid subscriptions include restrictions on request frequency and access to more powerful models. However, in practice, there are several effective approaches that either temporarily bypass limits or significantly reduce their impact, allowing you to continue working without long pauses.
Telegram bots and apps
The most obvious option users turn to after hitting limits is third-party services. These include Telegram bots as well as standalone AI platforms like Poe, Perplexity, Grok, and You.com.
However, it is important to be realistic. Full-featured platforms like Poe or Perplexity are stable and provide access to multiple models, sometimes with more flexible limits or their own quota systems. This is a legitimate and sustainable way to continue working, just not within ChatGPT itself.
Telegram bots, however, are much less predictable. Most operate via API or proxies, often using shared request pools, and may restrict users at any time. In addition, claims about access to top-tier models or “thinking” modes are often unreliable, as the user typically cannot verify which model is actually being used.
Another important aspect to consider is data security. With bots, you are almost always sending requests through third-party infrastructure, which may log or analyze your input. For sensitive tasks, this is a serious risk.
Thus, these services can help when you urgently need to continue a conversation after hitting a limit. But as a primary workflow, they are unstable and hard to control.
Free trials
Another approach is to use trial periods in services that integrate large language models. In this case, you are not bypassing limits directly, but temporarily gaining access to another system with its own limits.
For example, Cursor periodically offers trial access to its AI features and is widely used by developers. Replit provides built-in AI assistants with limits, while Codeium and Tabnine are alternative tools for working with code.
Technically, this is not removing ChatGPT limits, but switching to another service with a free trial or better conditions for new users. Eventually, restrictions return, either as limits or as a requirement to pay.
Still, as a temporary strategy, this works well, especially if tasks are distributed across different solutions: text generation, coding, search, and analysis.
Octo Browser
Keep in mind that ChatGPT limits are tied to the account, not the device. One account means one limit set. Multiple accounts mean combined limits. Octo Browser, an anti-detect browser for multi-accounting, allows you to manage such accounts by creating separate browser profiles with real digital fingerprints for each one.
This solves the core issue: the system does not link accounts together if they appear as independent users. As a result, you can work in parallel sessions and distribute the load.
How to use Octo Browser to work around ChatGPT limits:
Create a separate Octo Browser profile for each OpenAI account.
Each profile gets its own digital fingerprint: different Canvas, WebGL, fonts, User-Agent, geolocation, time zone, WebRTC, and so on. If you are unsure what to choose, you can leave the default settings.
Assign different proxies to each profile.
Register, purchase, or rent multiple ChatGPT accounts.
Switch between profiles as needed. ChatGPT limits are calculated separately for each account.
Keep in mind: aggressive behavior (mass registrations, identical actions, suspicious activity) still carries a risk of bans.
Tips for managing sessions and tokens
Even within a single account, you can significantly improve efficiency by working smarter with chats and requests. These methods do not bypass ChatGPT limits directly, but help reduce unnecessary messages.
Reuse context whenever possible
Continuing the same conversation means you do not need to re-enter instructions, style, or data. ChatGPT considers only the current context (up to hundreds of thousands of tokens depending on the model), so longer, structured chats help reduce redundant messages.
Do not start a new chat on the same topic unless strictly necessary.
Give chats clear names for easier navigation.
Split long conversations into logical blocks only when needed.
Clearing the context to manage performance
Very long chats can reduce answer quality and make work harder. To avoid this:
Use built-in features like clearing or branching a chat.
Start a new chat for completely different topics, carrying over only the key instructions.
Monitor context size to avoid overloading the model.
Important: clearing the context does not reset message limits, it only helps manage response quality.
Breaking a large request into several smaller ones
Very large prompts often lead to errors and unnecessary clarifications. It is better to split tasks into steps:
planning;
writing individual parts;
review and refinement.
This approach helps you get better results faster while staying within your ChatGPT message limits.
Prompt optimization methods
A good prompt is the main way to stay within your ChatGPT limit. A clear and complete request produces an accurate answer on the first try, without unnecessary follow-ups.
For example, if you need to analyze and debug Python code, a kind of task where limits are often quickly exhausted, use the following approach:
1. Assign a role to the model
Clearly define the model’s role. This helps produce expert-level answers and reduces follow-up questions.
Example: “You are a senior Python developer with 12 years of experience. Write clean, idiomatic code and explain changes line by line.”
This approach turns the prompt into a compact set of instructions for the model, reducing the need for repeated corrections.
2. Provide full context upfront
Do not send half the information in one message and then add clarifications later. If you are working with code, provide all relevant data upfront:
the code, identified errors, programming language and its version, and the task the code is supposed to perform;
sample data or the desired output format.
Example: instead of “Why doesn’t this code work?” — provide the code, the error, the Python version, and the expected result right away.
3. Break the task into steps
Use an iterative approach so the model handles each stage separately, while you can monitor the results and fix issues early.
Example:
Analyze the Python code and identify potential errors or vulnerabilities.
Fix the issues and suggest function optimizations.
Add test cases to validate the corrected code.
This way, you stay in control of the process, reduce the risk of incorrect solutions, and save messages because each follow-up is tied to a specific step.
4. Specify the exact output format
If you need a structured response, define the format in advance, as this reduces the number of revisions and clarifications.
Example: “Divide the response into four parts: problem analysis, proposed changes, corrected code, and test cases.”
5. Use examples
Show the model what kind of result you expect. This is especially useful when working with code, tables, or formatting.
Example:
Before:
response.json()
After:
response.raise_for_status() data = response.json()
Why: raise_for_status() throws an exception on HTTP errors, while response.json() returns data only if the request succeeds.
6. Cut unnecessary wording
The simpler and more precise the prompt, the fewer tokens and messages it uses.
Example:
Bad: “Please help me with the code, it doesn’t work, I don’t understand why, help me right now.”
Good: “Analyze and fix the code below. Error: JSONDecodeError on empty response. Add network and HTTP error handling.”
7. Use separators for blocks
If your prompt contains multiple parts, separators like ### help the model distinguish between instructions, improving accuracy and saving messages.
Using the API to manage limits
The OpenAI API is the most flexible way to work with ChatGPT without the limitations of the web interface. Through the API, you get direct access to models (gpt-5.3, gpt-5.4, thinking modes) and manage your own quotas and tokens.
1. Getting your API key and setup
To use the API:
Go to platform.openai.com and log in.
Open the API Keys section in the left menu.
Click Create new secret key.
In the pop-up window, enter a project name if needed, set permissions, and click Create new secret key.
Copy the key and store it securely, as it provides full access to your API account.
Important: API keys are not tied to ChatGPT web limits. These limits depend only on your API quota.
2. API quotas and limits
OpenAI uses a quota system tied to your account and billing:
Tier 0 (new account): small quotas, e.g., 500–1,000 requests per minute and 10k tokens per minute for lightweight models.
Tier 1+ (after spending more than $5): thousands of requests per minute (RPM) and hundreds of thousands of tokens per minute (TPM).
Tier 5 (Enterprise): near-unlimited quotas with custom limits by agreement.
Quotas increase automatically with consistent payment, provided there are no violations.
Difference from the web interface: API limits are not based on chat messages, but on RPM/TPM.
3. Efficient API usage
To save quota and improve stability, use these best practices:
Reasonable parameters:
temperature— 0.2–0.5 for precise code, 0.7–1.0 for creative tasks.max_tokens— limit response length to avoid unnecessary token usage.top_p— usually 0.9–1.0.
Cache responses: store repeated prompts locally (files, Redis) to avoid sending them again.
Batch requests: send multiple prompts in one request to save time and tokens.
Use lightweight models for drafts: use
gpt-4o-miniorgpt-5.3-instantfor drafts, then finalize with a top-tier model.Streaming mode:
stream=truelets you receive responses in chunks, saving tokens if sessions are interrupted.Compact system prompts: shorter role and core instructions reduce token usage in every request.
4. Python example
A simple way to call the ChatGPT API:
import requests api_key = "sk-..." url = "https://api.openai.com/v1/chat/completions" headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } data = { "model": "gpt-5.3", "messages": [ {"role": "system", "content": "You are a senior Python developer. Write clean, idiomatic code."}, {"role": "user", "content": "Please review this code and fix any errors: ..."} ], "temperature": 0.3, "max_tokens": 800 } response = requests.post(url, headers=headers, json=data) print(response.json())
Strategies for handling rate limits
A rate limit in ChatGPT is a restriction on how many messages you can send within a certain period. It operates using the rolling window principle.
What the rolling window principle means:
Instead of resetting at a fixed time (for example, exactly at 3:00), the system tracks a time window based on when each message was sent.
Example: if your Plus plan allows 160 messages per 3 hours and you send the first message at 10:00, it will only stop counting toward the limit at 13:00. The same applies to every message—the window continuously shifts based on send time.
This means the limit restores gradually, not all at once.
To manage your rate limit efficiently, follow these guidelines:
1. Use lightweight models for simple tasks
Mini or instant versions have separate limits and are suitable for quick checks, drafts, or simple clarifications.
2. Watch ChatGPT notifications
The web interface shows warnings as you approach your limit.
3. Break large tasks into blocks
Instead of one long prompt, split the task into multiple messages with clear instructions. This helps save your quota, improves control, and increases answer quality.
Conclusion
ChatGPT limits in 2026 are not a temporary issue but a permanent part of working with the service. For users, they often become a bottleneck: work stops, deadlines slip, and you have to wait for limits to reset.
In this article, we covered current restrictions, the reasons behind them (technical, economic, and security-related), and practical ways to reduce their impact. The most effective approach is to combine methods: multiple ChatGPT accounts created with an anti-detect browser, proper prompt optimization and context management, working through the API with tier-based quotas, and reasonable alternation of pauses and lightweight models.
It is impossible to completely remove ChatGPT limits without an expensive Pro subscription, but applying these strategies consistently and correctly allows you to work longer and more efficiently.
FAQ
How long does the rate limit in ChatGPT last?
ChatGPT uses the rolling window principle. This means the limit does not reset at a fixed moment but is calculated individually for each message. After 3-5 hours, a specific message no longer counts toward the current window.
Do different ChatGPT models have different limits?
Yes. Limits depend on your subscription. On the Free plan, access to advanced models is limited (often around 10 messages over several hours), after which the system may switch to a lightweight (mini) model. Paid plans (such as Plus) offer significantly higher quotas within the same time window.
Can API limits be changed?
Yes, but not manually. OpenAI API limits are managed through quotas (rate limits and spending limits) and increase automatically with usage and payments. Stable billing and higher usage lead to higher available limits (RPM/TPM). In some cases, limits for large clients can be increased through support.
Do ChatGPT limits reset if I use different browsers?
No. Limits are tied to your account, not the browser. Using different browsers or tabs does not change the message counter.
Are ChatGPT limits tied to the account or the device?
ChatGPT limits are tied to the account. Device, browser, and IP address do not affect the number of available messages. One account equals one shared limit.
What is the difference between token limits and rate limits?
These are different systems. Token limits define how much text (input and output) can be processed in a single request or within a conversation context. Rate limits define how often you can send requests over a period of time. You can hit one limit without reaching the other.
Stay up to date with the latest Octo Browser news
By clicking the button you agree to our Privacy Policy.
Stay up to date with the latest Octo Browser news
By clicking the button you agree to our Privacy Policy.
Stay up to date with the latest Octo Browser news
By clicking the button you agree to our Privacy Policy.

Join Octo Browser now
Or contact Customer Service at any time with any questions you might have.
Join Octo Browser now
Or contact Customer Service at any time with any questions you might have.
Join Octo Browser now
Or contact Customer Service at any time with any questions you might have.